1. Elasticsearch
1.1 安装ES
- 启动Docker:
service docker restart / systemctl restart docker - 基于Docker创建网络
docker network create hm-net - 向云服务器上传elasticsearch以及kibana的tar包,并使用
docker load -i xxx.tar进行加载 - 使用如下命令启动es:
bash
docker run -d \
--name es \
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \
-e "discovery.type=single-node" \
-v es-data:/usr/share/elasticsearch/data \
-v es-plugins:/usr/share/elasticsearch/plugins \
--privileged \
--network hm-net \
-p 9200:9200 \
-p 9300:9300 \
elasticsearch:7.12.1- 使用如下命令启动kibana:
bash
docker run -d \
--name kibana \
-e ELASTICSEARCH_HOSTS=http://es:9200 \
--network=hm-net \
-p 5601:5601 \
kibana:7.12.1- 使用
docker logs -f es / kibana可查看运行日志:

- 验证在浏览器中访问:9200以及5601端口能观察到如下现象证明启动成功:

1.2 初识Elasticsearch
1.2.1 简介
**Elasticsearch:**是一个高性能的搜索引擎,它是ELK技术栈的一部分:
- Logstash / Beats:用于数据收集
- Elasticsearch:用于数据的存储、搜索、计算
- Kibana:用于数据可视化(内置Devtools等高效工具)
**应用场景:**搜索引擎技术在日常生活中非常常见,例如:
- github等网站的高亮搜索关键词
- 百度/搜狗等搜索引擎
- 各大网站支持的模糊查询(关键字匹配)
- 打车软件地理位置搜索
1.2.2 倒排索引
ES的高性能得益于其底层实现的倒排索引 !
倒排索引中有两个重要概念:
- 文档(Document):一条数据就是一个文档,例如商品记录、用户记录都是一个文档
- 词条(Item):对于一个文档中的内容或者用户搜索句使用某种算法,基于语义划分得到的一组词就是词条,例如我喜欢学习Java,就可以分成:"我"、"喜欢"、"学习"、"Java"这些词条
倒排索引构建流程:
假设此时正向索引为:
| id | title | price |
|---|---|---|
| 1 | 小米手机 | 4999 |
| 2 | 华为手机 | 3999 |
| 3 | 华为手表 | 2999 |
| 4 | 小米汽车 | 199999 |
此时每一条数据就是一个文档,我们可以对文档中的title内容构建倒排索引:
- 使用某种分词算法将title进行分词,例如"小米手机"就可以得到"小米"、"手机"两个词条
- 以词条作为键,文档id列表作为值
- 如果词条已经出现过,那么就在文档列表末尾追加当前文档,如果该词条没有出现过,则构建一个新的键值对,键为当前词条,值为当前文档id
当对上述四条数据分词结束后倒排索引为:
| 词条 | 文档id列表 |
|---|---|
| 小米 | 1, 4 |
| 手机 | 1, 2 |
| 华为 | 2, 3 |
| 手表 | 3 |
| 汽车 | 4 |
倒排索引工作流程:
- 此时当用户搜索关键词为"小米手表",使用相同的分词算法得出词条"小米"、"手表"
- 然后就会查询倒排索引,小米对应的文档id有1、4, 手表对应的文档有3
- 然后再根据正排索引查询id对应的具体文档内容
1.2.3 IK分词器
1.2.3.1 基本使用
我们已经了解到ES工作原理需要借助一定的分词算法进行分词匹配,那么就需要一个字典(dict)来保存一些常用的词语,分词算法才可以判断某一个序列是否可以作为一个词条。
而ES标准的分词器对于中文分词支持力度不大!例如我们尝试在devtools发起如下分词请求:
http
POST /_analyze
{
"analyzer": "standard",
"text": "我喜欢学习Java"
}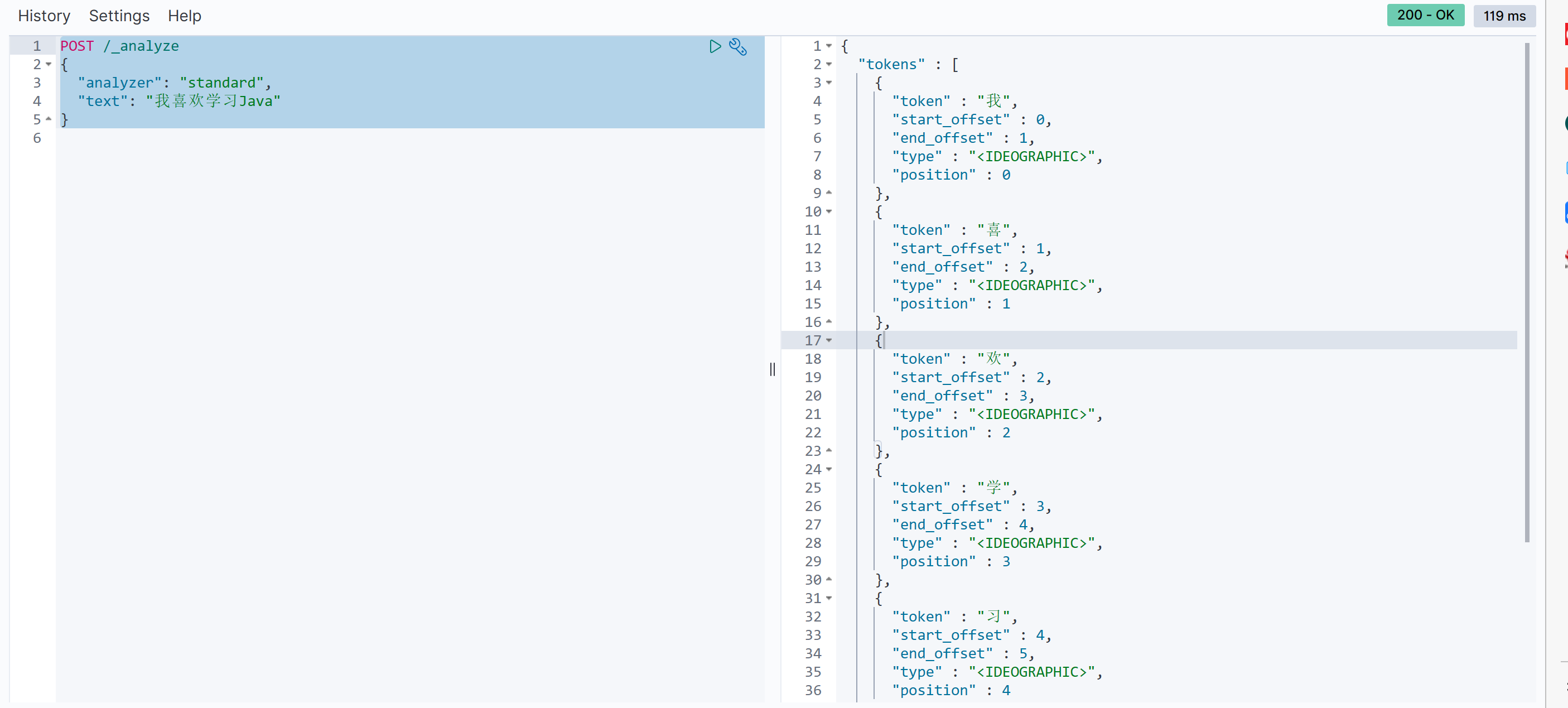
可以观察到"standard"模式下的响应结果并非是我们想得到的!这个时候我们就需要使用到IK分词器了
安装步骤:
- 方式一:使用在线安装的方式,输入以下命令:
bash
# 在线安装
docker exec -it es ./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.12.1/elasticsearch-analysis-ik-7.12.1.zip
# 重启docker es服务
docker restart es- 方式二:离线安装,将下载好的ik分词压缩包挂载在数据卷中
bash
# 查看所有的数据卷位置
docker volume ls
# 查看docker es-plugins数据卷位置
docker volume inspect es-plugins
# cd xxx
# 上传ik压缩包
# 重启docker es服务
docker restart es此时再次发起请求,结果如下:
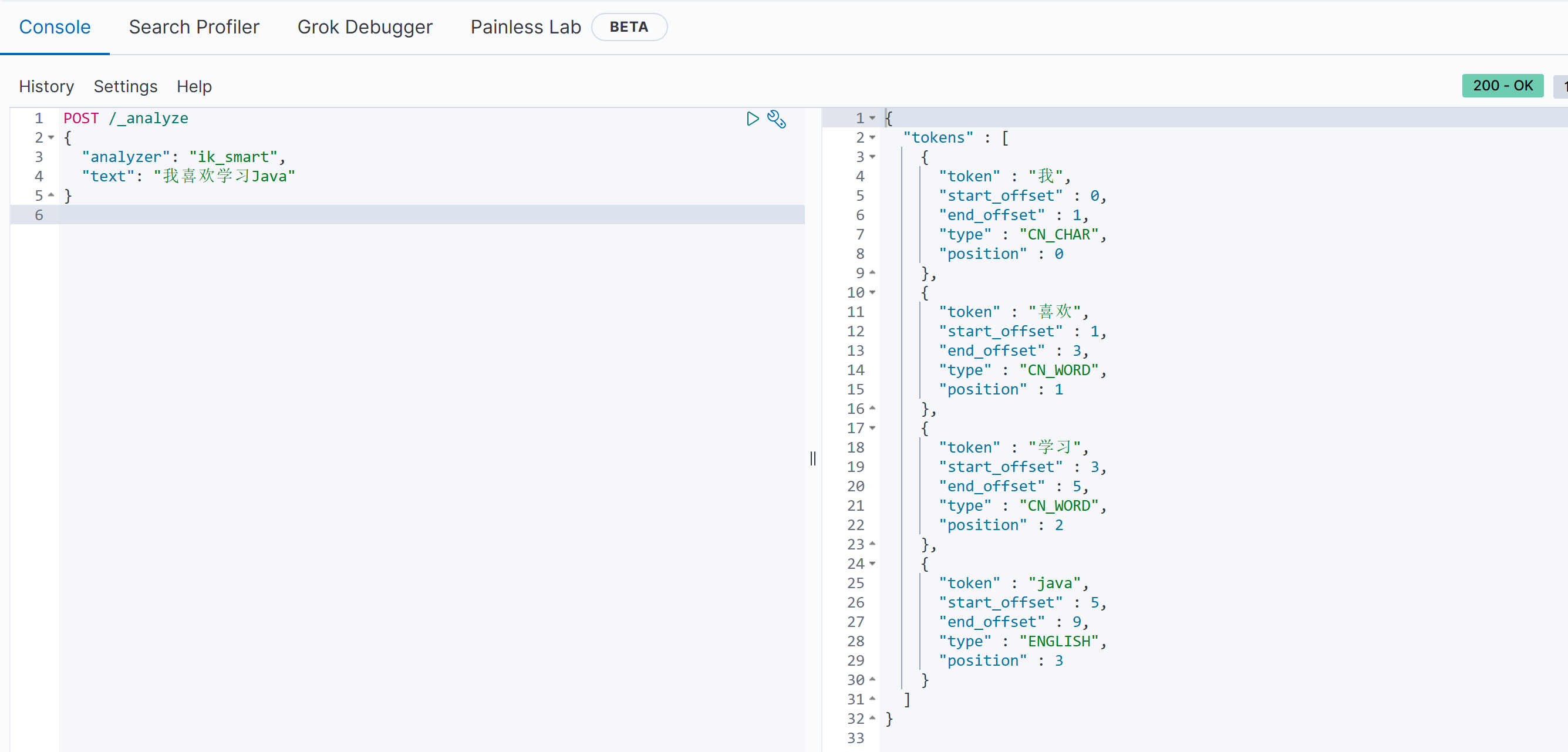
1.2.3.2 设置扩展词以及停用词
**扩展词:**我们需要自定义一些单词放在字典当中,例如"白嫖"、"米饭论坛"
**停用词:**在中文中一些语气词比如啊、哦、了是不需要进行分词的,可以剔除
前面我们提到IK分词器需要依赖字典,该配置文件就可以在ik文件夹目录中的/config/IKAnalyzer.cfg.xml进行配置扩展词以及暂停词的文件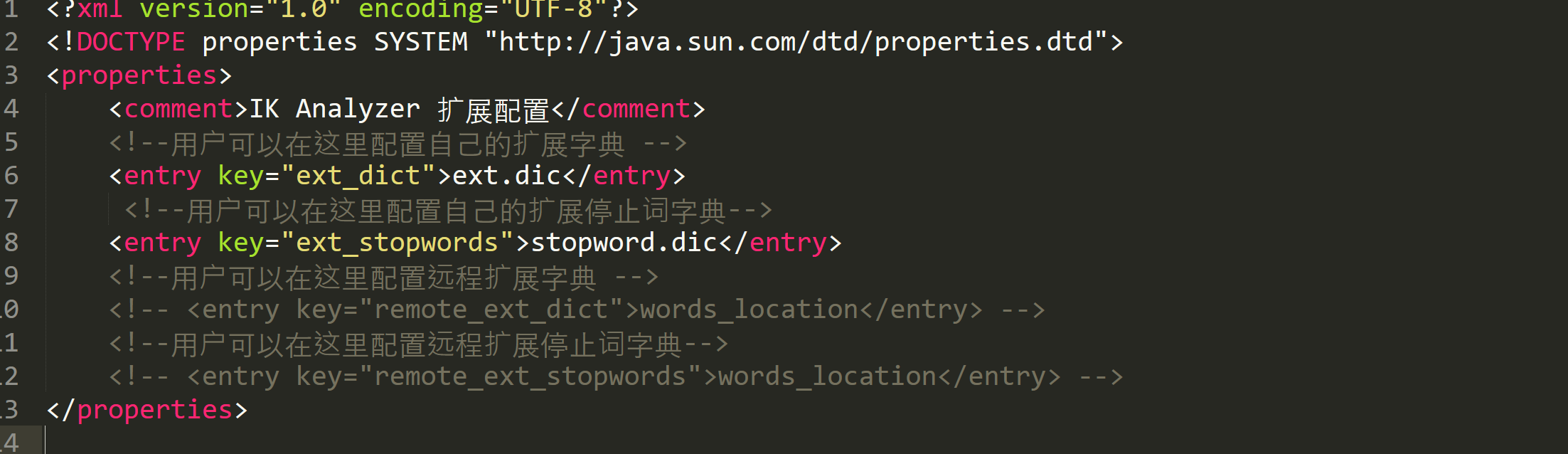
我们进行上述配置:然后重启es: docker restart es此后es就会读取同级目录下的ext.dic获取扩展字典当中的内容,读取stopwords.dic获取停用词列表
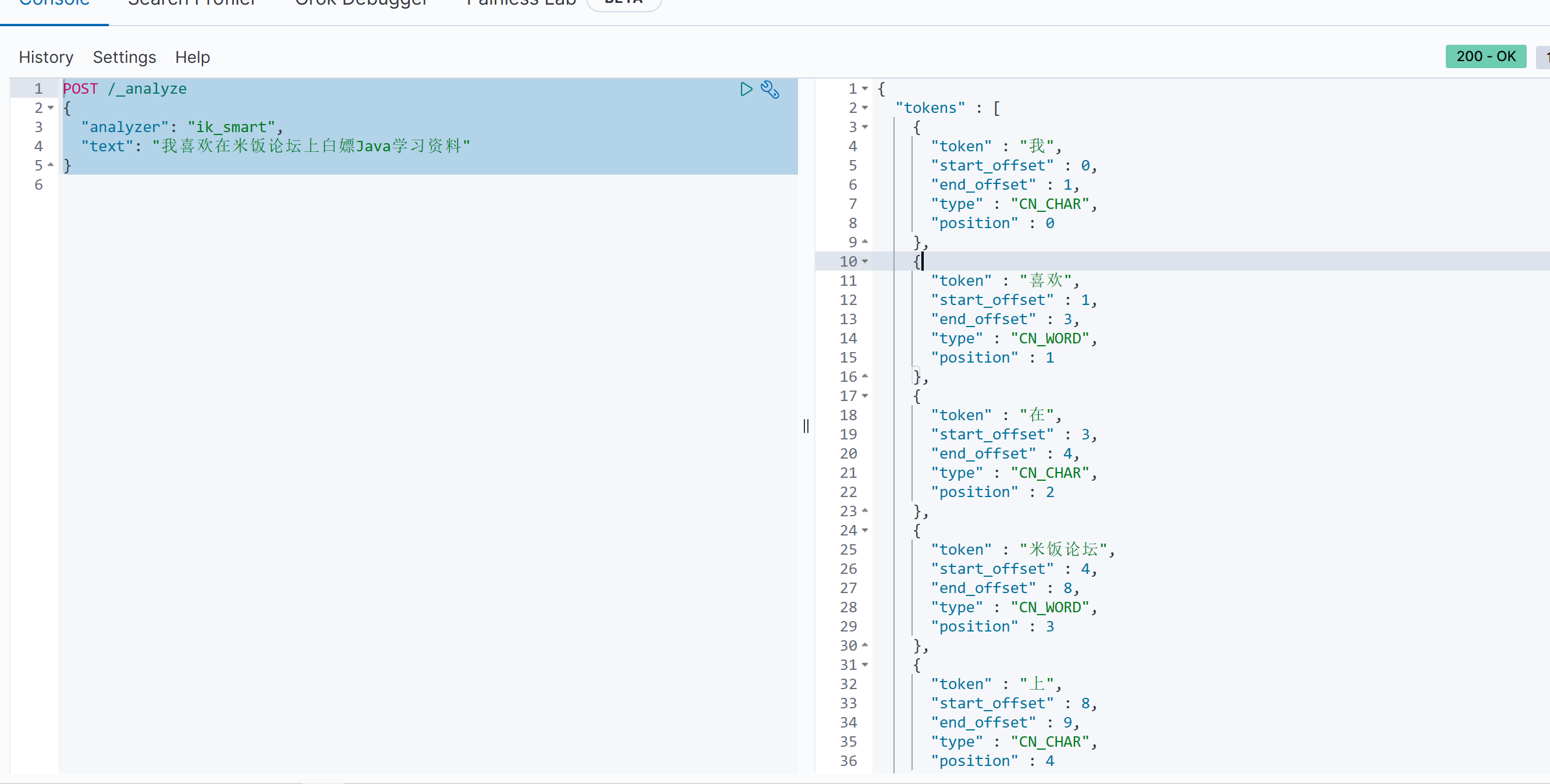
证明拓展词以及停用词配置成功!
1.2.4 索引库操作
- 创建索引库和映射:
请求方式:PUT
请求路径:/索引库名(自己定义)
请求参数:mapping映射
json
PUT /索引库名
{
"mappings": {
"properties": {
"字段名": {
"type": "text",
"index": true,
"analyzer": "ik_smart"
},
"字段名": {
"type": object,
"properties": {
"字段名": {
"type": boolean
}
}
}
}
}
}- 查询索引库:
请求方式:GET
请求路径:/索引库名
请求参数:无
json
GET /索引库名- 删除索引库:
请求方式:DELETE
请求路径:/索引库名
请求参数:无
json
DELETE /索引库名- 修改索引库
修改索引结构在es中是不被允许的,因此如果修改了字段结构会导致倒排索引重建,开销巨大,但是我们可以新增字段
请求方式:PUT
请求路径:/索引库名/_mapping
json
PUT /索引库名/_mapping
{
"properties": {
"新字段名": {}
}
}索引库操作总结:
- 新增:PUT /索引库名
- 查询:GET /索引库名
- 修改 PUT /索引库名/_mapping
- 删除:DELETE /索引库名
1.2.5 文档操作
1.3 Java客户端
1.3.1 Java客户端初始化
上述我们实践了借助Kibana发送请求,但是我们还是需要学习使用Java客户端编程的方式实现:
- 在pom文件中引入
RestHignLevelClient依赖
xml
<!-- 引入es依赖 -->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.12.1</version>
</dependency>- 初始化RestHignLevelClient对象
java
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestClientBuilder;
import org.elasticsearch.client.RestHighLevelClient;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
@SpringBootTest
class EsDemoApplicationTests {
private RestHighLevelClient client;
@BeforeEach
public void init() {
client = new RestHighLevelClient(RestClient.builder(HttpHost.create("http://129.211.6.176:9200")));
}
@Test
public void testClient() {
System.out.println(client);
}
}1.3.2 创建映射以及索引库
原先我们在Kibana中使用如下HTTP请求配置映射信息以及索引库:
http
PUT /user
{
"mappings": {
"properties": {
"desc": {
"type": "text",
"index": "true",
"analyzer": "ik_smart"
},
"name": {
"type": "text",
"index": "false"
},
"age": {
"type": "integer",
"index": "false"
}
}
}
}而在Java代码中我们需要通过以下的方式来创建:
java
/**
* 测试创建索引库
*/
@Test
public void testCreateIndex() throws IOException {
// 1. 创建Request对象
CreateIndexRequest request = new CreateIndexRequest("user");
// 2. 配置携带参数
request.source(MAPPING_TEMPLATE, XContentType.JSON);
// 3. 发起请求
client.indices().create(request, RequestOptions.DEFAULT);
}1.3.3 查看索引库
原先我们在Kibana中使用如下HTTP请求查看索引库:
http
GET /user
java
/**
* 测试获取索引库信息
*/
@Test
public void testGetIndex() throws IOException {
// 1. 创建request对象
GetIndexRequest request = new GetIndexRequest("user");
// 2. 发起请求
boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);
System.out.println("exists: " + exists);
}1.3.4 删除索引库
原先我们在Kibana中使用如下HTTP请求删除索引库:
http
DELETE /user
java
/**
* 测试删除索引库
*/
@Test
public void testDeleteIndex() throws IOException {
// 1. 创建request对象
DeleteIndexRequest request = new DeleteIndexRequest("user");
// 2. 发起请求
client.indices().delete(request, RequestOptions.DEFAULT);
}1.3.5 新增文档
原先我们在Kibana中使用如下HTTP请求增加文档:
http
# 插入文档
POST /user/_doc/1
{
"desc": "测试描述",
"name": "ricejson",
"age": 20
}
java
/**
* 新增文档
*/
@Test
public void testCreateDocument() throws IOException {
// 1. 创建request
IndexRequest request = new IndexRequest("user").id("1");
// 创建用户对象
User user1 = new User("测试描述", "ricejson", 20);
Gson gson = new Gson();
String userStr = gson.toJson(user1);
// 2. 填写内容
request.source(userStr, XContentType.JSON);
// 3. 发起请求
client.index(request, RequestOptions.DEFAULT);
}1.3.6 查看文档
原先我们在Kibana中使用如下HTTP请求查看文档:
http
GET /user/_doc/1
java
/**
* 获取文档
*/
@Test
public void testGetDocument() throws IOException {
// 1. 创建request
GetRequest request = new GetRequest("user", "1");
// 2. 发起请求
GetResponse resp = client.get(request, RequestOptions.DEFAULT);
// 3. 获取返回内容
String source = resp.getSourceAsString();
System.out.println(source);
}1.3.7 删除文档
原先我们在Kibana中使用如下HTTP请求删除文档:
http
DELETE /user/_doc/1
java
/**
* 删除文档
*/
@Test
public void deleteDocument() throws IOException {
// 1. 创建request对象
DeleteRequest request = new DeleteRequest("user", "1");
// 2. 发起删除文档请求
client.delete(request, RequestOptions.DEFAULT);
}1.3.8 修改文档
全量修改:与新增文档一致
局部修改:
http
POST /user/_update/1
{
"doc": {
"name": "米饭好好吃"
}
}
java
/**
* 局部更新文档
*/
@Test
public void updateDocument() throws IOException {
// 1. 创建request对象
UpdateRequest request = new UpdateRequest("user", "1");
// 2. 设置更新内容
request.doc("name", "米饭好好吃");
// 3. 发起请求
client.update(request, RequestOptions.DEFAULT);
}1.3.9 批处理
java
/**
* 测试批处理操作
*/
@Test
public void testBatch() throws IOException {
// 1. 创建request对象
BulkRequest bulkRequest = new BulkRequest();
// 2. 添加多个request操作
// 创建用户对象
User user = new User("测试描述", "ricejson", 20);
Gson gson = new Gson();
String userStr = gson.toJson(user);
bulkRequest.add(new IndexRequest("user").id("1").source(userStr, XContentType.JSON));
bulkRequest.add(new IndexRequest("user").id("2").source(userStr, XContentType.JSON));
// 3. 发起批处理请求
client.bulk(bulkRequest, RequestOptions.DEFAULT);
}1.4 DSL语句
1.4.1 快速入门
现在我们需要设计一个商品表,其中MySQL存储如下字段内容:
id: int 编号
name: varchar(20) 名称
brand:varchar(20) 品牌
price: int 价格
desc: varchar(100) 描述内容
http
# 定义以及新增商品索引库
PUT /goods
{
"mappings": {
"properties": {
"id": {
"type": "integer"
},
"name": {
"type": "text",
"analyzer": "ik_smart"
},
"brand": {
"type": "keyword"
},
"price": {
"type": "integer"
},
"desc": {
"type": "text",
"analyzer": "ik_smart"
}
}
}
}现在插入几条模拟数据:
http
POST /goods/_doc/1
{
"id": 1,
"name": "超级智能手表",
"brand": "FutureTech",
"price": 1299,
"desc": "这款超级智能手表拥有最新的健康监测功能,能够实时追踪您的心率和睡眠质量。"
}
POST /goods/_doc/2
{
"id": 2,
"name": "无线蓝牙耳机",
"brand": "AudioMaster",
"price": 499,
"desc": "享受无线自由,这款无线蓝牙耳机提供卓越的音质和长达24小时的续航能力。"
}
POST /goods/_doc/3
{
"id": 3,
"name": "便携式咖啡机",
"brand": "CoffeeCraft",
"price": 699,
"desc": "随时随地享受新鲜咖啡,这款便携式咖啡机设计精巧,操作简便,是咖啡爱好者的理想选择。"
}
POST /goods/_doc/4
{
"id": 4,
"name": "智能扫地机器人",
"brand": "CleanRobotics",
"price": 2999,
"desc": "智能扫地机器人,自动导航,高效清洁,为您节省宝贵的时间。"
}
POST /goods/_doc/5
{
"id": 5,
"name": "多功能运动相机",
"brand": "ActionCam",
"price": 1499,
"desc": "这款多功能运动相机防水防尘,适合各种极限运动场景,记录您的每一个精彩瞬间。"
}搜索索引库中全部的文档内容语法如下:
http
GET /goods/_search
{
"query": {
"match_all": {}
}
}1.4.2 叶子查询
常见的叶子查询主要有如下两类:
- 全量查询:要求查询条件必须是可以分词的
- 精确查询
1.4.2.1 全量查询
其中全量查询语法格式如下:
http
# 全量查询
GET /goods/_search
{
"query": {
"match": {
"name": "智能"
}
}
}除此以外我们还可以指定查询多个字段:
http
# 全量查询(查询多个字段)
GET /goods/_search
{
"query": {
"multi_match": {
"query": "您",
"fields": ["name", "desc"]
}
}
}1.4.2.2 精确查询
精确查询有如下两种常见方式:
- term:词条完全匹配
- range:范围查询,比如price >= 1000 以及 price <= 1999
http
# 精确查询(词条查询)
GET /goods/_search
{
"query": {
"term": {
"brand": "ActionCam"
}
}
}
http
# 精确查询(范围查询)
GET /goods/_search
{
"query": {
"range": {
"price": {
"gte": 1499,
"lte": 2999
}
}
}
}1.4.3 复合查询
bool查询:
将多个叶子查询经过must,should、must_not、filter等与或非操作合并成一个复杂查询:
http
# 复合查询(查询name中包含机器人并且价格在1499-2999之间)
GET /goods/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "机器人"
}
}
],
"filter": [
{
"range": {
"price": {
"gte": 1499,
"lte": 2999
}
}
}
]
}
}
}1.4.4 排序+分页
排序:
我们还可以在query的同级目录下加入order: {"排序字段": "asc|desc"}
- ASC:表示正序
- DESC:表示倒序
http
# 排序
GET /goods/_search
{
"query": {
"match_all": {}
},
"sort": {
"price": "asc"
}
}分页:
我们还可以在query的同级目录下加入"from": x, "size": x
- from:表示从哪一条数据开始
- size:表示单页的数量
http
# 分页
GET /goods/_search
{
"query": {
"match_all": {}
},
"from": 0,
"size": 3
}1.4.5 高亮显示
想必大家都遇到过以下场景:
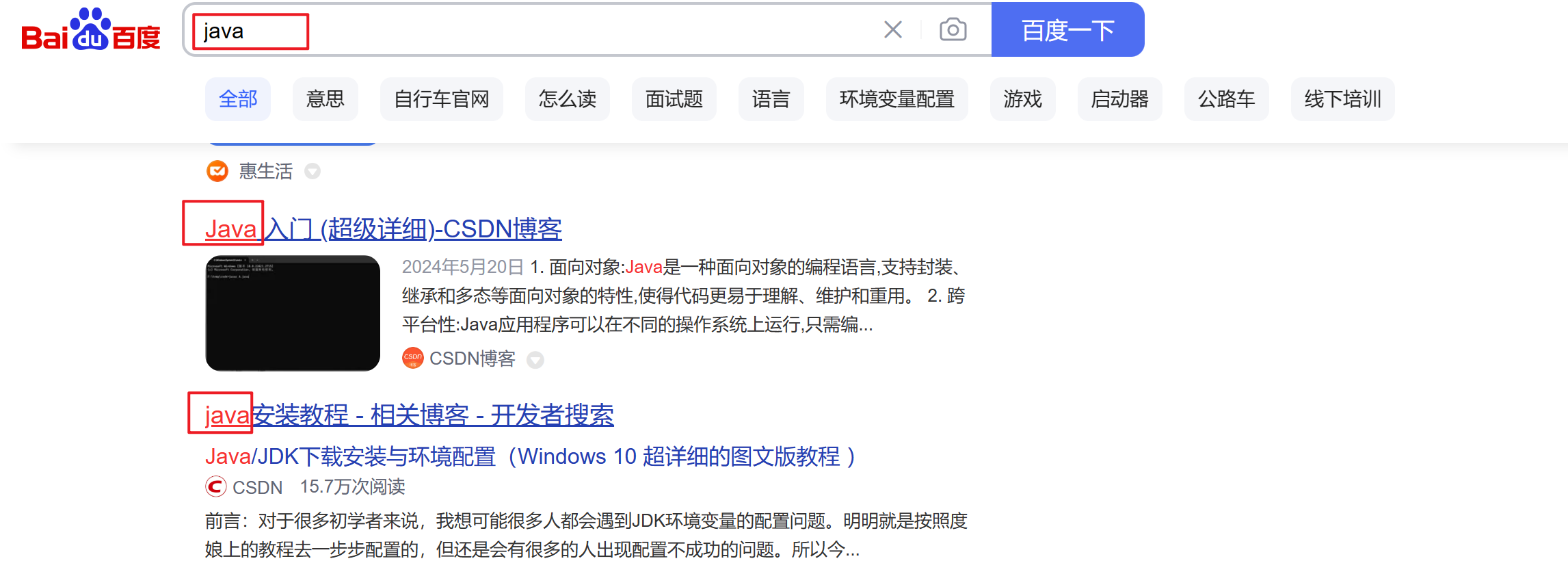
即百度搜索返回的结果中,与关键字匹配的结果都会高亮(红色)显示,打开开发者工具能够发现被高亮的部分由标签进行包括并使用CSS语法标红醒目。
那么问题就出现了,这个标签到底是由前端分析生成的还是由后端返回的?
- 前端:如果让前端进行处理,都需要对查询内容进行分词,然后在内容中进行匹配,但是这样一来性能开销就非常大,前端一般只做数据展示,数据处理一般让后端处理
- 后端:事实上ES在进行倒排索引的构建过程中,会保存查询分词在文档中的位置,然后在查询词前后加上等标签返回给前端。✔
DSL添加高亮显示:
http
# 高亮显示
GET /goods/_search
{
"query": {
"match": {
"name": "智能"
}
},
"highlight": {
"fields": {
"name": {
"pre_tags": "<em>",
"post_tags": "</em>"
}
}
}
}1.5 Java客户端操作DSL
1.5.1 快速入门
我们现在想要查询出索引库为goods下全部的文档内容,与之匹配的DSL语句如下:
http
GET /goods/_search
{
"query": {
"match_all": {}
}
}相对应的java代码如下:
java
/**
* 测试查询全部文档
*/
@Test
public void testMatchAll() throws IOException {
// 1. 创建request
SearchRequest request = new SearchRequest("goods");
// 2. 添加query查询条件
request.source()
.query(QueryBuilders.matchAllQuery());
// 3. 发起请求获取响应
SearchResponse resp = client.search(request, RequestOptions.DEFAULT);
// 4. 解析响应
// 4.1 获取到hits
SearchHits searchHits = resp.getHits();
// 4.2 获取到数据条数
TotalHits hitsCount = searchHits.getTotalHits();
// 4.3 获取到数据数组
SearchHit[] hitsHits = searchHits.getHits();
// 4.3 逐个解析
for (SearchHit searchHit : hitsHits) {
// 4.4 获取source数据
String source = searchHit.getSourceAsString();
System.out.println(source);
}
}1.5.2 叶子查询
前面我们已经介绍过叶子查询主要有如下几类:
- 全量查询
- match:单字段匹配
- match_all:多字段匹配
- 精确查询
- term:根据词条内容匹配
- range:根据范围匹配
需求1:现在我们需要找出desc中包含"这款"的文档
对应的DSL语句如下:
http
GET /goods/_search
{
"query": {
"match": {
"desc": "这款"
}
}
}对应的Java代码如下:
java
/**
* 查询desc中包含"这款"的内容
*/
@Test
public void testMatch() throws IOException {
// 1. 创建request对象
SearchRequest request = new SearchRequest("goods");
// 2. 设置查询条件
request.source()
.query(QueryBuilders.matchQuery("desc", "这款"));
// 3. 发起请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4.1 获取到hits
SearchHits hits = response.getHits();
// 4.2 获取到数据总条数
TotalHits totalHits = hits.getTotalHits();
// 4.3 获取到数据集合
SearchHit[] searchHits = hits.getHits();
// 4.4 逐条解析
for (SearchHit searchHit : searchHits) {
String source = searchHit.getSourceAsString();
System.out.println(source);
}
}需求2:现在我们需要查询desc中包含"相机"并且name中包含"相机"的文档
对应的DSL语句如下:
http
GET /goods/_search
{
"query": {
"multi_match": {
"query": "相机",
"fields": ["name", "desc"]
}
}
}对应的Java代码如下:
java
/**
* 查询desc并且name中都包含"相机"的文档
*/
@Test
public void testMultiMatch() throws IOException {
// 1. 创建request
SearchRequest request = new SearchRequest("goods");
// 2. 添加查询条件
request.source()
.query(QueryBuilders.multiMatchQuery("相机", "name", "desc"));
// 3. 发起请求获取响应
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4.1 获取到hits
SearchHits hits = response.getHits();
// 4.2 获取到数据总数
TotalHits totalHits = hits.getTotalHits();
// 4.3 获取全部查询文档
SearchHit[] searchHits = hits.getHits();
// 4.4 解析每条数据
for (SearchHit searchHit : searchHits) {
// 4.5 获取source数据
String source = searchHit.getSourceAsString();
System.out.println(source);
}需求3:现在我们需要精确查找手机品牌为"ActionCam"的文档
对应的DSL语句如下:
http
GET /goods/_search
{
"query": {
"term": {
"brand": "ActionCam"
}
}
}对应的Java代码如下:
java
/**
* 查询手机品牌为"ActionCam"的文档
*/
@Test
public void testTerm() throws IOException {
// 1. 创建request对象
SearchRequest request = new SearchRequest("goods");
// 2. 设置查询条件
request.source()
.query(QueryBuilders.termQuery("brand", "ActionCam"));
// 3. 发起请求获取响应
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4.1 获取hits
SearchHits hits = response.getHits();
// 4.2 获取数据总数
TotalHits totalHits = hits.getTotalHits();
// 4.3 获取全部匹配文档
SearchHit[] searchHits = hits.getHits();
// 4.4 解析出每一条数据
for (SearchHit searchHit : searchHits) {
// 4.5 获取source
String source = searchHit.getSourceAsString();
System.out.println(source);
}需求4:现在我们需要查询价格高于1999的文档
对应的DSL语句如下:
http
GET /goods/_search
{
"query": {
"range": {
"price": {
"gt": 1999
}
}
}
}对应的Java代码如下:
java
/**
* 查询价格高于1499的文档
*/
@Test
public void testRange() throws IOException {
// 1. 创建request
SearchRequest request = new SearchRequest("goods");
// 2. 设置查询条件
request.source()
.query(QueryBuilders.rangeQuery("price").gt(1499));
// 3. 发起请求,获取响应
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4.1 获取hits
SearchHits hits = response.getHits();
// 4.2 获取数据总数
TotalHits totalHits = hits.getTotalHits();
// 4.3 获取数据全集
SearchHit[] searchHits = hits.getHits();
// 4.4 解析每条数据
for (SearchHit searchHit : searchHits) {
// 4.5 获取source
String source = searchHit.getSourceAsString();
System.out.println(source);
}
}1.5.3 复合查询
需求:查询价格低于2999并且name中包含"耳机"并且品牌为"AudioMaster"的文档
http
GET /goods/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "耳机"
}
}
],
"filter": [
{
"term": {
"brand": "AudioMaster"
}
},
{
"range": {
"price": {
"lt": 2999
}
}
}
]
}
}
}对应的Java代码如下:
java
/**
* 查询价格低于2999并且name中包含"耳机"并且品牌为"AudioMaster"的文档
*/
@Test
public void testBool() throws IOException {
// 1. 创建request
SearchRequest request = new SearchRequest("goods");
// 2. 设置查询条件
request.source()
.query(QueryBuilders.boolQuery()
.must(QueryBuilders.matchQuery("name", "耳机"))
.filter(QueryBuilders.termQuery("brand", "AudioMaster"))
.filter(QueryBuilders.rangeQuery("price").lt(2999)));
// 3. 发起请求,获取响应
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
process(response);
}1.5.4 分页+排序查询
需求:查询全部文档,按照价格从低到高,分页为第一页,三条数据
http
GET /goods/_search
{
"query": {
"match_all": {}
},
"sort": {
"price": "ASC"
},
"from": 1,
"size": 3
}对应的Java代码如下:
java
/**
* 查询全部文档,按照价格从低到高,分页为第一页,三条数据
*/
@Test
public void testPageAndSort() throws IOException {
// 1. 创建request
SearchRequest request = new SearchRequest("goods");
// 2. 设置查询条件
request.source()
.query(QueryBuilders.matchAllQuery())
.sort("price", SortOrder.ASC)
.from(0)
.size(3);
// 3. 发起请求,获取响应
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
process(response);
}1.5.5 高亮显示
DSL高亮语法:
http
GET /goods/_search
{
"query": {
"match": {
"name": "相机"
}
},
"highlight": {
"fields": {
"name": {
"pre_tags": "<em>",
"post_tags": "</em>"
}
}
}
}Java客户端实现:
java
/**
* 测试高亮
*/
@Test
public void testHighlight() throws IOException {
// 1. 创建request
SearchRequest request = new SearchRequest("goods");
// 2. 设置查询条件
request.source()
.query(QueryBuilders.matchQuery("name", "相机"));
// 3. 设置高亮条件
request.source().highlighter(new HighlightBuilder()
.field("name")
.preTags("<em>")
.postTags("</em>"));
// 4. 进行查询
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 5. 进行解析
SearchHits hits = response.getHits();
SearchHit[] searchHits = hits.getHits();
for (SearchHit searchHit : searchHits) {
Map<String, HighlightField> hlfs = searchHit.getHighlightFields();
HighlightField hlf = hlfs.get("name");
String value = hlf.getFragments()[0].string();
System.out.println(value);
}
}1.5.6 聚合
1.5.6.1 聚合分类
在DSL中,聚合可以分为如下几类:
- 桶(Buckets)聚合
- Terms Aggregation: 词条聚合
- Date 日期时间聚合
- 度量(Metric)聚合
- min:最小值
- max:最大值
- avg:平均值
- stats:统计最小值、最大值、平均值
- 管道(Pipeline)聚合
基于别的聚合再次聚合
1.5.6.2 聚合DSL语句
聚合三要素:
- 聚合名称
- 聚合类型
- 聚合字段
聚合DSL语法:
bash
GET /goods/_search
{
"size": 0,
"aggs": {
"brand_agg": {
"terms": {
"field": "brand",
"size": 5
}
}
}
}1.5.6.3 Java客户端操作聚合DSL语句
java
/**
* 测试聚合DSL
*/
@Test
public void testAggregation() throws IOException {
// 1. 创建request对象
SearchRequest request = new SearchRequest("goods");
// 2. 编写查询条件
request.source().query(QueryBuilders.matchAllQuery());
// 2.1 设置分页
request.source().size(0);
// 2.2 设置聚合三要素
request.source()
.aggregation(AggregationBuilders
.terms("brand_agg")
.field("brand")
.size(5));
// 3. 查询结果
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4. 解析结果
Aggregations aggregations = response.getAggregations();
Terms terms = aggregations.get("brand_agg");
List<? extends Terms.Bucket> buckets = terms.getBuckets();
for (Terms.Bucket bucket : buckets) {
System.out.println("key: " + bucket.getKeyAsString());
System.out.println("count: " + bucket.getDocCount());
}
}