数据和代码获取:请查看主页个人信息!!!
上期我们介绍了原核生物分类单元功能注释的R语言操作方法:FAPROTAX:微生物群落功能注释分析及可视化(附R语言代码)。
本期我们介绍Tax4Fun2:**** 基于16S rRNA基因序列的功能预测工具,可以用于预测特定生境中的功能概况和功能冗余。
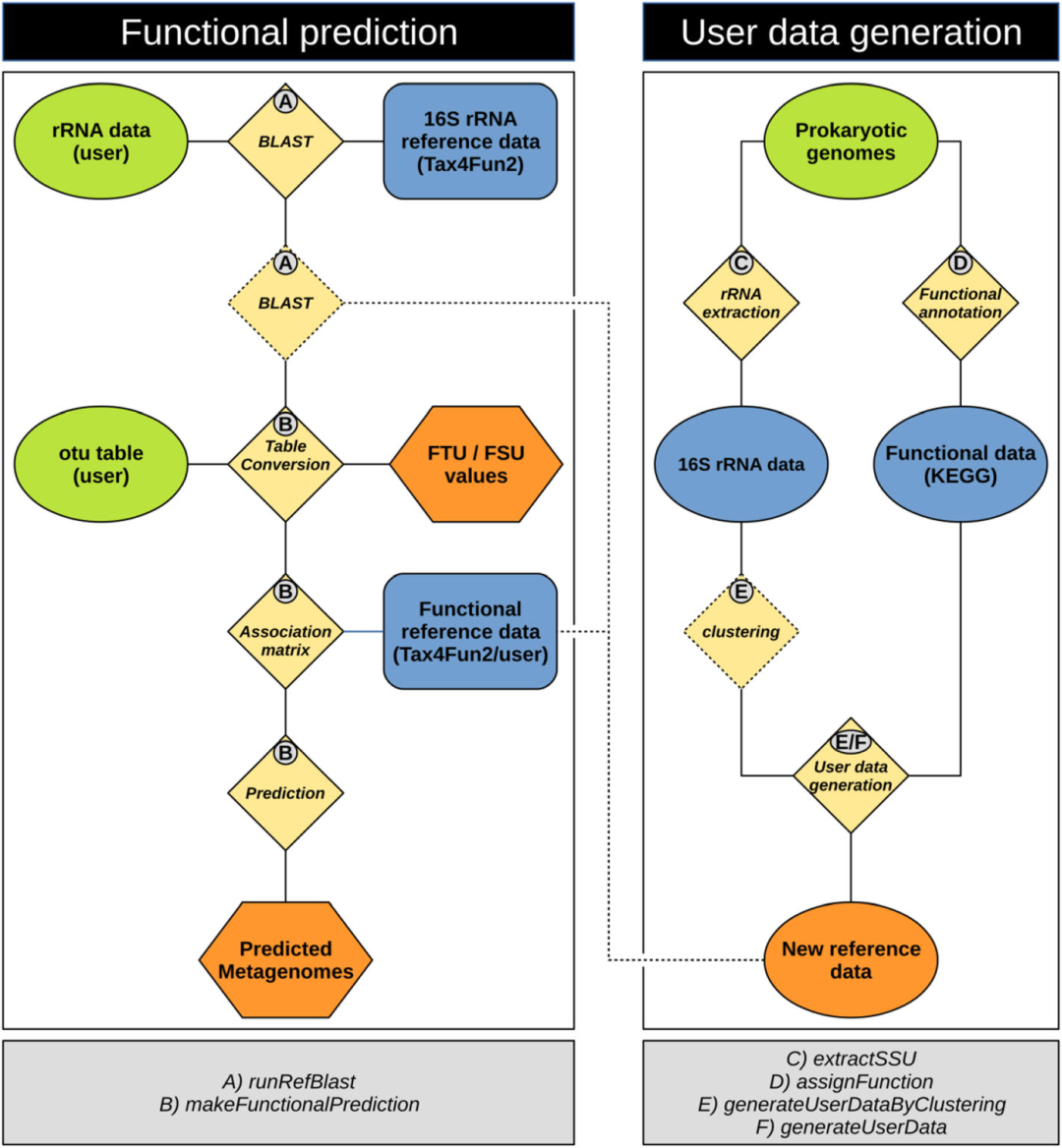
Tax4Fun2的工作流程如下:首先,16S rRNA基因序列将与Tax4Fun2提供的参考序列进行比对,以找到最近的近缘序列。如果用户提供了自定义数据,还将额外将16S rRNA基因序列与用户添加的序列进行比对。如果两次搜索结果都有显著的匹配,将优先选择用户数据中的最近近缘序列。然后,根据最近近缘序列的搜索结果,对每个样本的OTU(操作分类单元)丰度进行总结。
生成包含16S rRNA搜索中确定的那些参考序列的功能概况的关联矩阵(AM)。将总结的OTU丰度和存储在AM中的功能概况合并,为每个样本预测一个宏基因组。生成的FTU(功能丰度单元)和FSU(功能丰度样本)值将作为日志文件提供。
Tax4Fun2: prediction of habitat-specific functional profiles and functional redundancy based on 16S rRNA gene sequences
https://doi.org/10.1186/s40793-020-00358-7
接下来我们来进行分析和可视化展示:
Step1:数据准备
rm(list=ls())pacman::p_load(tidyverse,microeco,aplot,ggsci,seqinr)rep_fasta <- read.fasta('rep.fna')otu <- read.csv("otu_table.csv", row.names = 1)otu_table_16S <- otu %>% filter(rownames(.) %in% names(rep_fasta)) %>% select(1:10)dataset <- microtable$new(otu_table = otu_table_16S, rep_fasta = rep_fasta)t1 <- trans_func$new(dataset)t1使用Tax4Fun2分析前需要提前下载blast工具和Ref99NR或Ref100NR数据集:
blast下载路径:
https://ftp.ncbi.nlm.nih.gov/blast/executables/blast+/
Ref99NR下载路径 :
https://cloudstor.aarnet.edu.au/plus/s/DkoZIyZpMNbrzSw/download
Ref100NR下载路径 :
https://cloudstor.aarnet.edu.au/plus/s/jIByczak9ZAFUB4/download
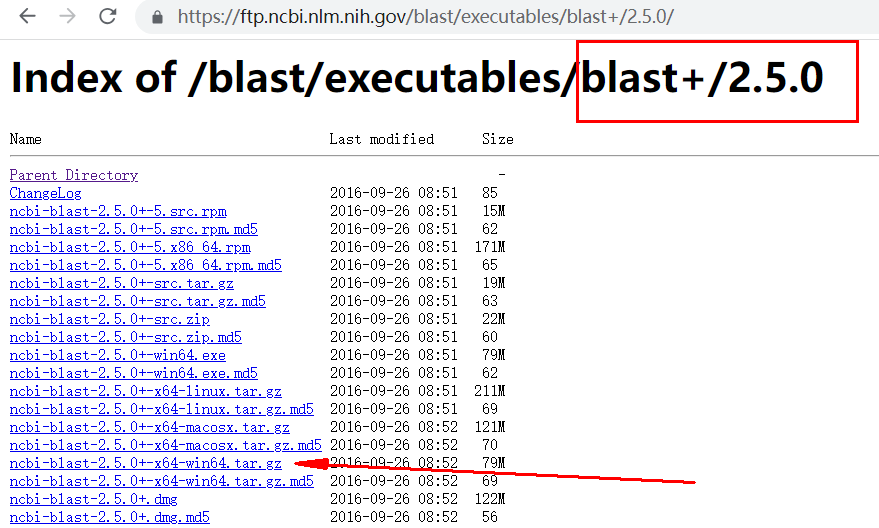
1 推荐使用2.5.0版本的blast,高版本的blast可能会报错

2 将Ref99NR或Ref100NR文件减压后放到Tax4Fun2_ReferenceData_v2目录中
Step2:执行Tax4Fun2分析
t1$cal_tax4fun2(blast_tool_path = "ncbi-blast-2.5.0+/bin", path_to_reference_data = "Tax4Fun2_ReferenceData_v2", database_mode = "Ref99NR", path_to_temp_folder = "results")t1$res_tax4fun2_pathway注释结果文件:
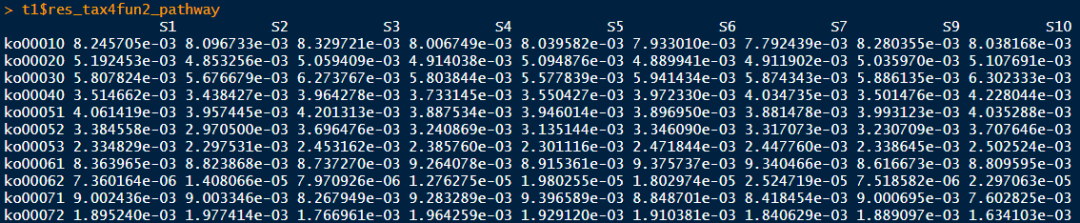
Step3:整理分析结果
data(Tax4Fun2_KEGG)func2 <- microtable$new(otu_table = t1$res_tax4fun2_pathway, tax_table = Tax4Fun2_KEGG$ptw_desc)func2$tidy_dataset()func2$cal_abund()func2$taxa_abund$Level.1func2$taxa_abund$Level.2func2$taxa_abund$Level.3

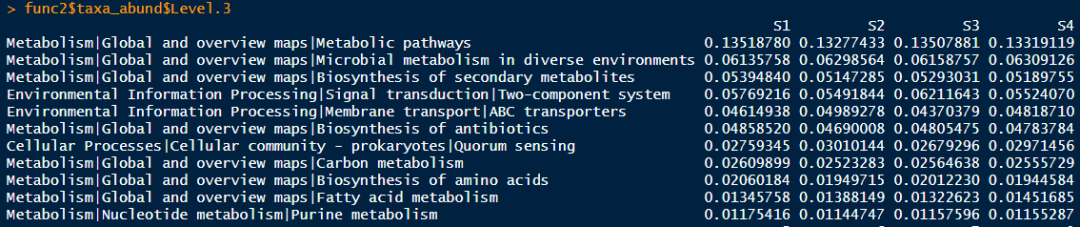
Step4:计算功能冗余性
t1$cal_tax4fun2_FRI()t1$res_tax4fun2_aFRIt1$res_tax4fun2_rFRI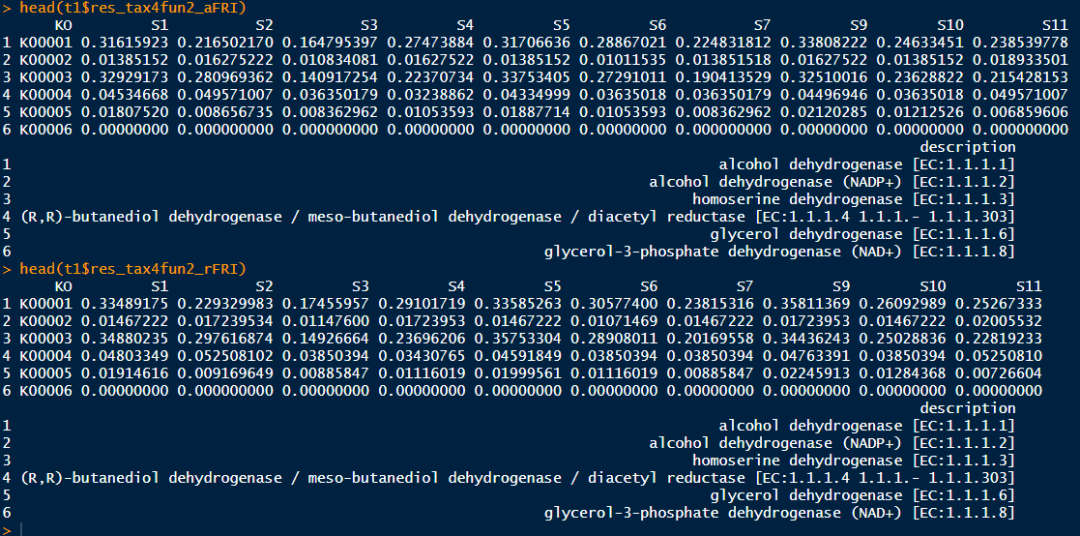
Step5:可视化小案例
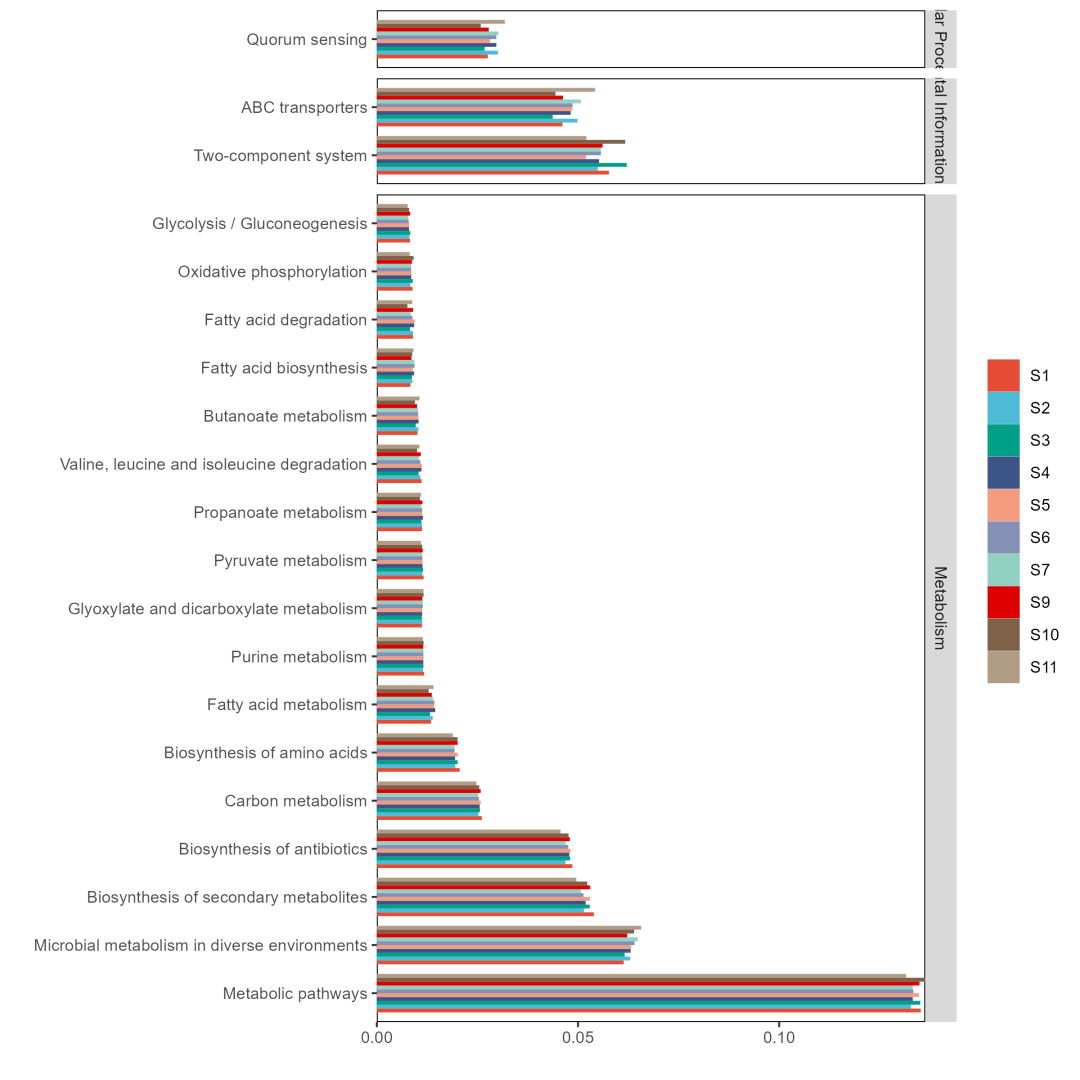
df1 <- func2$taxa_abund$Level.3 %>% rownames_to_column('taxa_abund') %>% mutate(KO1 = stringr::str_split(taxa_abund, pattern = "\\|", simplify = T)[,1], KO2 = stringr::str_split(taxa_abund, pattern = "\\|", simplify = T)[,2], KO3 = stringr::str_split(taxa_abund, pattern = "\\|", simplify = T)[,3]) %>% select(-taxa_abund)
df2 <- df1 %>% column_to_rownames('KO3') %>% select(-KO1, -KO2) %>% rowSums() %>% as.data.frame() %>% top_n(20)
df1 %>% filter(KO3 %in% rownames(df2)) %>% reshape2::melt() %>% mutate(KO3 = factor(KO3, levels = rownames(df2), ordered = T)) %>% ggplot(aes(x = KO3, y = value, fill = variable)) + geom_col(position = 'dodge', width = 0.8, size = 0.05) + coord_flip() + scale_fill_npg() + facet_grid(KO1~., space = 'free', scale = 'free_y') + theme(panel.grid = element_blank(), panel.background = element_rect(fill = 'transparent', color = 'black'), legend.title = element_blank(), legend.position = 'right') + scale_y_continuous(expand = c(0,0)) + xlab('') + ylab('')ggsave('pic.png', height = 8, width = 8)