文章目录
- 一、修改云主机配置缘由
- 二、修改云主机配置步骤
- [三、使用Spark Shell玩Saprk SQL](#三、使用Spark Shell玩Saprk SQL)
-
- 1、启动HDFS服务
- 2、启动Spark集群
- [3、启动集群模式Spark Shell](#3、启动集群模式Spark Shell)
- 4、读取文件生成单例数据帧
- 5、将单列数据帧转换成多列数据帧
- 6、基于数据帧生成临时视图
- 7、基于临时视图进行SQL查询
一、修改云主机配置缘由
- 在今天的Spark课程中,我们深入学习了数据集和数据帧的操作方法。然而,我注意到云主机的内存几乎被耗尽,这导致了系统运行时的卡顿,有时甚至会导致Spark Shell的强制退出。为了确保课程的顺利进行,我需要对云主机的配置进行调整,特别是增加内存容量,以满足我们学习过程中对计算资源的需求。
二、修改云主机配置步骤
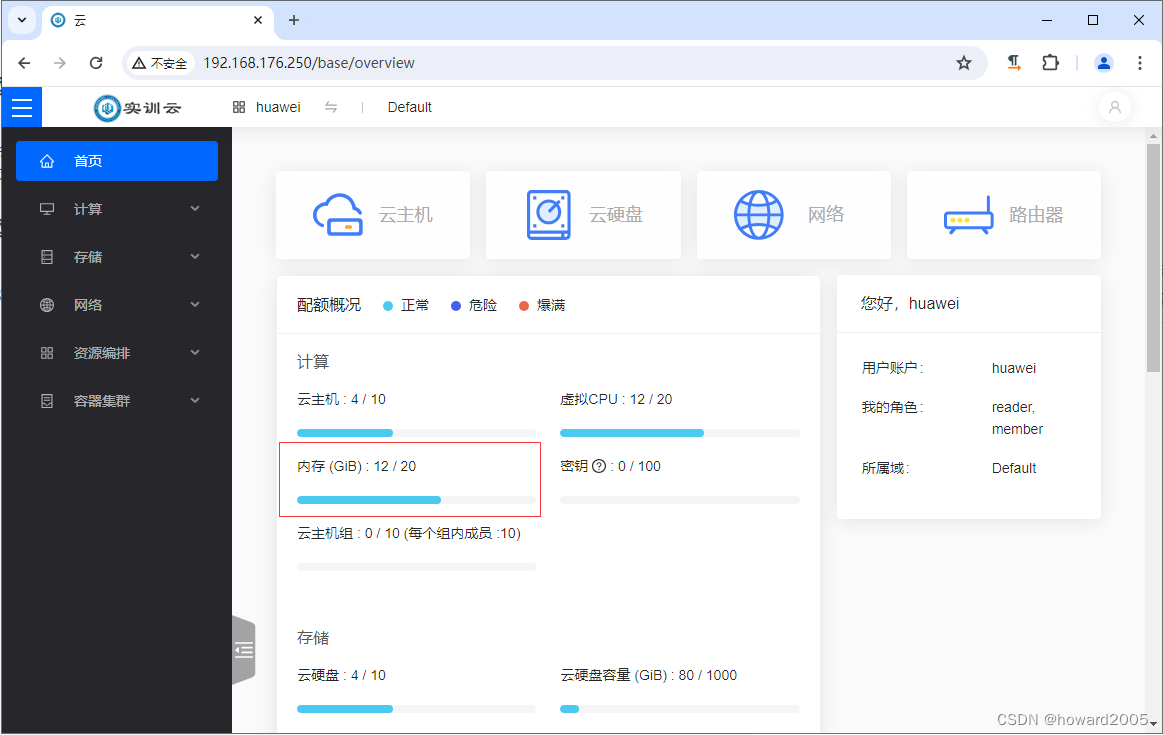
1、查看云主机概述
- 内存使用情况:20GB用了12GB
2、查看master云主机
- 云主机类型 -
m1.medium

3、更改master云主机配置
- 更多 ⟶ \longrightarrow ⟶ 配置变更 ⟶ \longrightarrow ⟶ 修改配置

- 选择云主机类型 -
m1.vlarge- 内存8GB

- 勾选
同意强制关机复选框,单击【确定】按钮,正在修改 - 配置/迁移

- 确认修改配置/迁移

- 弹出消息框要求用户确认

- 单击【确定】按钮

4、查看master云主机
- 云主机类型已成功改成
m1.vlarge,8GB运行内存,正常运行中......

三、使用Spark Shell玩Saprk SQL
1、启动HDFS服务
- 执行命令:
start-dfs.sh

2、启动Spark集群
- 执行命令:
start-all.sh

3、启动集群模式Spark Shell
- 执行命令:
spark-shell --master spark://master:7077

4、读取文件生成单例数据帧
-
执行命令:
val df = spark.read.text("hdfs://master:9000/student/input/student.txt")

-
执行命令:
df.show

5、将单列数据帧转换成多列数据帧
scala
val stuDF = df
.withColumn("id", split(col("value"), ",")(0).cast("int"))
.withColumn("name", split(col("value"), ",")(1))
.withColumn("gender", split(col("value"), ",")(2))
.withColumn("age", split(col("value"), ",")(3).cast("int"))
.drop("value") // 删除原始的 value 列-
执行上述命令

-
执行命令:
stuDF.printSchema

-
执行命令:
stuDF.show

6、基于数据帧生成临时视图
- 执行命令:
stuDF.createOrReplaceTempView("student")

7、基于临时视图进行SQL查询
- 执行命令:
spark.sql("select * from student where gender = '女' and age > 20").show
