作业一
第一个代码使用的方法是出自于1。
框架结构
如下图,不过根据对代码的解读,发现作者在代码中省去了对SSR部件的实现,下文再说。
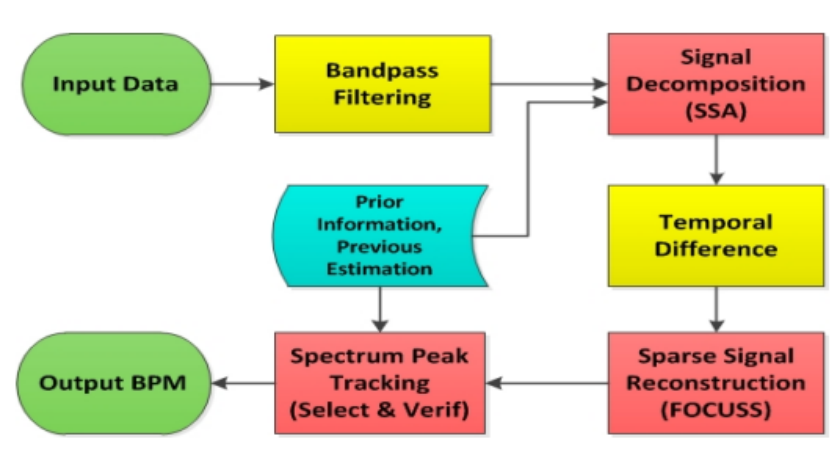
Troika框架由三个关键部件组成:信号分解,SSR和光谱峰值跟踪。(粗体字是关键步骤)
-
先是使用带通滤波过滤了0.4Hz-5Hz之外的噪音(去噪),
-
然后利用稀疏PPG信号光谱的方法进行信号分解用于降噪,
-
时间差异操作可以使心跳基本和谐波谱峰值更加突出,
-
SSR产生高分辨率频谱估计,
-
光谱峰值跟踪部分选择正确的光谱峰值并处理峰的不存在情况。
代码解读
库的引入
前面的引入库,读取数据。因为涉及信号处理(引入scipy.signal),和加载matlab数据,还要在后面使用svd奇异值分析,所以语句编写如下。
from scipy.io import loadmat#信号处理
from scipy.linalg import svd
import scipy.signal as signal#matlab数据数据读取
数据信息分为6 行. 第一行是ECG 数据,2、3行是双通道PPG数据,并且最后三行是加速度仪数据。
(参考Signal processing (scipy.signal) --- SciPy v1.13.1 Manual)
数据之多,如果不压缩间距进行展示,很难看出整体分布。在大多数情况下,我们倾向于压缩有限长度数据集两端数据的幅值来提高功率谱估计的某些特性。截取无线长原始信号的过程可以看做对原始信号乘以一个有限长的数据2。即注释的语句,进行压缩展示。
# 不压缩间距
t = np.linspace(0, num_sample, num_sample)
# 压缩间距
# t = np.linspace(0, num_sample/FREQ_SAMPLE, num_sample)
plt.figure()
plt.plot(t, data[0,:])
plt.title('ECG signal')
plt.xlabel('Time (sec)')
plt.xlim(0, num_sample/FREQ_SAMPLE)
接下来对2、3行的PPG数据进行图形化展示,两个图表展示的是不同的活动方式(如图标题所示,前后各休息30秒,期间进行4个1分钟的不同速度的剧烈运动)
ppg1 = data[1, :]# 第二行数据,对应channel1的图片
ppg2 = data[2, :]# 第三行数据,对应channel2的图片
...
# 原来代码里写的(0,300),我觉得不太严谨,改为num_sample/FREQ_SAMPLE以展示所有数据(虽然数值上差不多)
ax1.set_xlim(0, num_sample/FREQ_SAMPLE)
再看一下没有经过处理的PSD功率谱分析图,这里使用的是重叠平均周期法 (Welch法),调用signal库的函数。
# fs是采样频率,scaling可选功率谱密度density或者功率谱spectrum
f1, density1 = signal.welch(x=ppg1, fs=FREQ_SAMPLE, window='hanning', scaling='density', nperseg = 1024)
plt.figure()
plt.plot(f1, density1)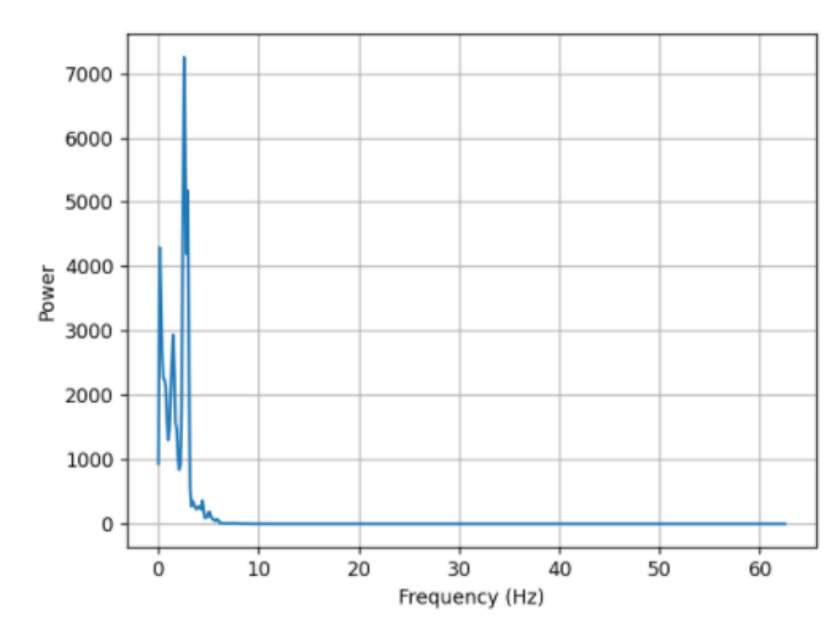
读取由ECG心电图测出来的BPM数据(此数据作为ground truth、实锤、最后比对的依照)。

使用移动窗口的方法来打点作图,保证图像连续。T(在此是window长度)和S的确切值并不重要。选择相对较大的T是增加频谱分辨率,#同时选择小S是在彼此接近的两个连续时间窗口中进行计算的心率。
...
window = 8*FREQ_SAMPLE # 窗口为8个freq
step = 2*FREQ_SAMPLE # 步长为2个freq
window_number = int((num_sample - window)/step + 1) # 计算整体的窗口数目
# 创建一列的数组用来记录预测值
estimate_hr = np.zeros((window_number, 1))
# 在每个移动区间得到相应的功率谱密度
for idx in np.arange(1, window_number):
segment_cur = ppg1[(idx - 1)*step + 1 : (idx - 1)*step + window]
f, Pwelch_spec = signal.welch(segment_cur, FREQ_SAMPLE, window='hanning', scaling='spectrum')
# 取最大的密度值作为当前这一步的预测值
estimate_hr[idx-1] = f[Pwelch_spec.argmax()]
# 最后进行单位转换
estimate_bpm = estimate_hr*60
plt.figure()
# 打印bpm值
plt.plot(np.arange(0, window_number)*2, estimate_bpm)
# 红线打印标准的答案(ECG测出来的bpm)作比对
plt.plot(np.arange(0,len(data_bpm))*2, data_bpm,'r')
...只有前30s休息时是稳定的,后面因为运动产生的运动干扰,数据都变得不准确了

复现框架
运用TROIKA 框架来去除运动干扰,优化PPG信号从而得到较准确的BPM值。(作者对框架组件进行了选择性使用),只分为了以下三部分:
-
去噪:去除运动伪影的影响。
-
稀疏信号重构:对PPG信号进行处理,使其在谱域内稀疏。
-
峰值检测和跟踪:确定光谱峰值并跟踪以估计HR。
带通滤波去噪
w_lower = 0.4# 带通滤波范围下限
w_upper = 5 # 带通滤波范围上限
b2 = signal.firwin(103, [w_lower, w_upper], pass_zero = False, nyq = FREQ_SAMPLE/2) # 按照参数,返回FIR过滤器的系数
ppg1_filtered = signal.convolve(ppg1, b2)# 卷起来
#事实上,周期图是通过将其与适当的窗函数频谱卷积来实现平滑目标的[3]。
f, spectrum_ppg1_filtered = signal.welch(x=ppg1_filtered, fs=FREQ_SAMPLE, \
window='hanning', scaling='density', nperseg = 1024)
plt.figure()
# 将没有限定范围去噪的谱线 以红色打印出来
plt.plot(f1, density1,'-.r')
# 打印当前经过去噪的谱线
plt.plot(f, spectrum_ppg1_filtered)
plt.grid(True)
plt.xlabel('Frequency (Hz)')
plt.ylabel('Power')在0.4Hz之前和5Hz之后的噪音(红色点线)被带通滤波过滤去除

利用矩阵稀疏化SSA去除运动伪影
将原来的数组转换为矩阵,行列安排要得当, K=M-L+1, L<M/2

# 编写的数组转矩阵方法
def trajectory_mat(segment):
M = window # length of each sequence
L = int(M/2)
K = M - L + 1
Y = np.empty((L, K)) # 创建个L*K的矩阵
for k in np.arange(0, K):
Y[:, k] = segment[k:k + L]
# 按列遍历,进行赋值
return Y Y = trajectory_mat(ppg1_filtered[0:window])
U, s, V = svd(Y)# SVD奇异值分解
plt.figure()
plt.plot(s, '.-')- 其中s是对矩阵Y的奇异值分解。s除了对角元素不为0,其他元素都为0,并且对角元素从大到小排列。s中有n个奇异值,一般排在后面的比较接近0,所以仅保留比较大的r个奇异值。 因为s是除了对角元素不为0,其他元素都为0。是稀疏矩阵,所以为了节省空间,返回的时候,作为一维矩阵返回。

作者跳过了SSR
光谱顶点探测和追踪
1论文将此组件分为三个步骤
-
初始化
-
顶点选取
-
验证
初始化
取前期平静状态的PPG最高值作为之后HR预测的度量值
# 创建用于保存心跳预测值的数组
estimate_hr = np.zeros((window_number, 1))
# 按照[1]论文所说,取前2~3s即可,这里取得是第一个窗口的数据
segment_cur = ppg1_filtered[0:window]
f, P_spec = signal.welch(segment_cur, FREQ_SAMPLE, window='hanning', scaling='spectrum')
# 平静状态的最大值作为第一个预测值
estimate_hr[0] = f[P_spec.argmax()]
# 顶点的数值作为后面预测的基础
Nprev = P_spec.argmax()
print(Nprev, estimate_hr[0]*60)
# 输出:2 [58.59375]
# 即第3个时刻是第一个窗口时间段最大值,换算成BMP则为58.59顶点选取
1论文原文

# 以第一个窗口的数据作为初始化数据之后,按着步长依次遍历后面的窗口数据
for idx in np.arange(1, window_number):
segment_cur = ppg1_filtered[(idx - 1)*step + 1 : (idx - 1)*step + window]
f, P_spec = signal.periodogram(segment_cur, fs=FREQ_SAMPLE, window='hanning', scaling='spectrum')
# 对应着[1]中的△s,一个小正数,受取样频率的影响,用来放缩窗口的大小
delta_s = 16
# 通过Nprev表示先前时间窗口中HR的频率位置索引。在当前时间窗口中的HR的基频进行分析预测
search_range_1 = np.arange(0 if (Nprev - delta_s) < 0 else (Nprev - delta_s), Nprev + delta_s)
f_search = f[search_range_1]
P_search = P_spec[search_range_1]
# 在的第一个顺序谐波频率同样进行分析预测
search_range_2 = np.arange(1 if (Nprev - delta_s - 1) < 0 else 2*(Nprev - delta_s - 1) + 1, 2*(Nprev + delta_s - 1) + 1)
f_search_2 = f[search_range_2]
P_search_2 = P_spec[search_range_2]
N1 = search_range_1[0] + P_search.argmax()
N2 = search_range_2[0] + P_search_2.argmax()
# 按理说 Nhat应该是在各个搜索范围,各个搜索场景里面进行比较最后综合得出,
# 但是作者这里编码也不考虑了种种因素的判断了,直接默认第一个搜索区间的值就是最佳,赋值上去
Nhat = N1
# if (N1 == 2*N2):
# Nhat = N0
# else:
# Nhat = Nprev
# 最大值作为预测值
estimate_hr[idx] = f[Nhat]
# 当前点的数值作为后面预测的基础
Nprev = Nhat验证
这里的验证只是将经过处理的数据打印出来,但按照1论文的步骤,应该设计相关的纠错机制,来保证预测可以更加准确。
estimate_bpm = estimate_hr*60
plt.figure()
plt.plot(np.arange(0, window_number)*2, estimate_bpm,'b')# 蓝线表示处理之后的预测值
plt.plot(np.arange(0, window_number)*2, pre_bpm,'-.y')# 黄断点线表示未经处理的PPG信号对应的预测
plt.plot(np.arange(0,len(data_bpm))*2, data_bpm,'r')# 红线表示ECG对应的“正确”的BPM值
plt.xlabel('Time (sec)')
plt.ylabel('Estimated BPM')
plt.ylim((0, 200))
plt.grid(True)可以看到蓝线比黄线和红线更加拟合。

数据保存
Input Data(摘自作业二,项目github说明页)
HRVAS can read inter-beat interval files (.ibi) and text files (.txt), both of which are ASCII files. The expected data format must have one or two columns (comma separated). If one column is used, this column must represent IBI/RR values in units of seconds . If two columns are used, the first column represents time in units of seconds. The second column represents IBI/RR values in units of seconds.
IBI即每秒间隔跳动数,等同老师上讲的RR-interval
# 因为要保存IBI格式,两次跳动间隔数,所以利用estimate_hr进行处理
# IBI值=1秒/每秒跳动次数
ibi=[] # 创建存放ibi值的数组
for i in range(len(estimate_hr)):
num = int(estimate_hr[i]+0.5)# 四舍五入记录需要插入几个IBI值
for j in range(num): # 插入相应的IBI值
ibi.append(1/estimate_hr[i])
# 保存IBI
np.savetxt("C:/Users/abc/Desktop/作业一/HRVAS-master/SampleData/IBI.txt",ibi,fmt='%.3lf',delimiter='\n')作业二
IBI预处理
异位间隔:异位节拍是指基于一个或多个异常节拍的任何 IBI。任何异常的IBI,无论是由于虚假/错过的节拍,假点错位,或心脏异位症可能被视为异位。
异位间歇检测
-
percentage 百分比过滤器可以根据用户的设定,以先后两个节点相差的比例来识别。(e.g.如果设定20,如果第二个点位相较第一个偏移多于20%,则第二个会被标记)
-
standard deviation标准偏差过滤器,该过滤器将离群值标记为用户定义的标准偏差值(总体平均 IBI 的间隔,通常为 3 SD),大于这个数值则会被标记。
-
median 中位数过滤器,具有阈值来标记异位间歇点 。



异位间歇校正
四种校正技术,以取代检测过程中发现的异位间隔。
-
第一个remove技术是简单地删除发现的任何异位间隔。简单的异位间歇去除已证明与其他替换方法 一样有效。
-
另一种方法用以方程为中心以异位区间为中心的 w 相邻 IBI 间隔的平均值替换任何异位间歇。
-
median 中值方法使用方程替换异位间隔,以以异位间歇为中心的 w 相邻 IBI 间隔的中值。
-
cubic spline replacement使用立方夹板插值替换异位间隔。




IBI Detrending
文献中存在消除低频趋势的几种方法,包括:线性趋势、多值趋势、波小变趋势、波小包趋势和平滑趋势趋势。
数据去趋势,就是对数据减去一条最优(最小二乘)的拟合直线、平面或曲面,使去趋势后的数据均值为零。
A. Linear and Polynomial Detrending 线性和多面性趋势
最不拟合的方法

B. Wavelet Detrending 波浪脱潮


C. Wavelet Packet Detrending 波浪包除趋势

D. Smoothing Priors平滑优先次

时域分析

来源(Shaffer & Ginsberg, 2017)
部分解释
SDNN:NN间隔标准偏差
pNN50:百分比连续的RR间隔差异大于50ms
NN间隔,即从中移除了伪影的间隔;RR间隔,所有连续心跳之间的间隔。
频域分析

来源(Shaffer & Ginsberg, 2017)
部分解释
ULF power:超低频带的绝对功率(≤0.003Hz)
VLF power: 绝对功率的极低频带(0.0033-0.04 Hz)
LF peak:峰值频率的低频带(0.04-0.15 Hz)
LF power:低频带的绝对功率(0.04-0.15 Hz)
HF peak:峰值的高频带(0.15-0.4 Hz)
HF power:绝对功率的高频带(0.15-0.4 Hz)
HF power:在正常单元相对功率高 - 的频带(0.15-0.4 Hz)
LF / HF:功率的功率比
非线性分析

来源(Shaffer & Ginsberg, 2017)
下方四行的解释
Sampen:近似熵,用来测量时间序列的规律性和复杂性
DFA α1:受损波动分析,描述了短期波动
DFA α2:受损波动分析,描述了长期波动
D₂:相关维度,可以用来估计构建系统动态模型所需的最小变量数
时间频率分析

window是X的分帧长度,overlap是帧重叠的长度。
参考文献:
1 Zhang, Z. , Pi, Z. , & Liu, B. . (2015). Troika: a general framework for heart rate monitoring using wrist-type photoplethysmographic signals during intensive physical exercise. Biomedical Engineering IEEE Transactions on, 62(2), 522-531. 2飞翔的北极熊, (2018). 功率谱估计. Retrieved from 功率谱估计-CSDN博客 3 Shaffer, F. , & Ginsberg, J. P. . (2017). An overview of heart rate variability metrics and norms. Frontiers in Public Health, 5, 258. 4 Ramshur, J. ,(2015). HRV Analysis and Preprocessing. Retrieved from https://github.com/jramshur/HRVAS/wiki/HRV-Analysis-and-Preprocessing 5 Xu, K. , Jiang, X. , Lin, S. , Dai, C. , & Chen, W. . (2020). Stochastic modeling based nonlinear bayesian filtering for photoplethysmography de-noising in wearable devices. IEEE Transactions on Industrial Informatics, PP(99), 1-1. 6 Galli, A. , Narduzzi, C. , & Giorgi, G. . (2017). Measuring heart rate during physical exercise by subspace decomposition and kalman smoothing. IEEE Transactions on Instrumentation and Measurement, 1-9.