为什么数据有各种各样的编码格式
因为每个数据库下存储的表的类型都可能不一样,比如图片,超链接.因此数据库就要有各种编码格式.
两种校验码格式
collate_utf8_general_ci和 collate utf8_bin
collate_utf8_general_ci的校验码方式是不区分大小写的.
collate utf8_bin校验码格式是区分大小写的.
例如下图,我们创建一个 collate_utf8_general_ci 校验码格式的数据库test1
创建一个collate utf8_bin校验码格式的数据库test2:

两种校验码格式查询结果的不同:
在test1数据库下创建一个person表,向person表中插入数据,然后进行查询:
 我们发现查询'a'是查询出了'a','A'的.由此可见,collate_utf8_general_ci的校验码方式是不区分大小写的.
我们发现查询'a'是查询出了'a','A'的.由此可见,collate_utf8_general_ci的校验码方式是不区分大小写的.
我们使用test2数据库,在其下创建man 表,向man表中插入数据进行查询,查询结果如下:

我们发现查询'a'只查询出了'a',因此说明collate utf8_bin校验码格式是区分大小写的.
两种校验码格式排序结果的不同:
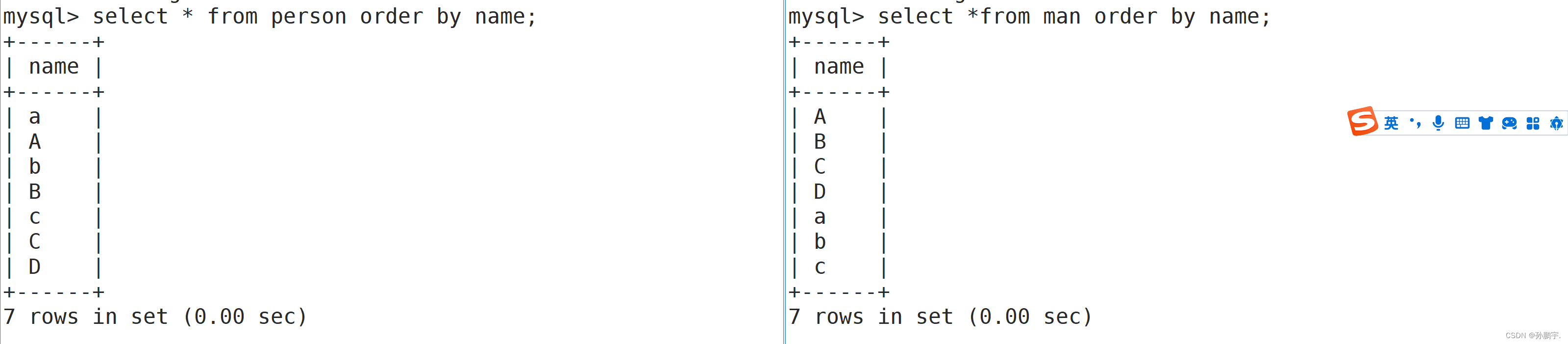 由上图可以看见, collate_utf8_general_ci因为不区分大小写,所以在排序上小写a和大写A放在一起.collate utf8_bin因为区分大小写,所以大写字母和小写字母各自按照ASCII从小到大1排.
由上图可以看见, collate_utf8_general_ci因为不区分大小写,所以在排序上小写a和大写A放在一起.collate utf8_bin因为区分大小写,所以大写字母和小写字母各自按照ASCII从小到大1排.
数据库的备份与还原
备份数据库的命令为:mysqldump;
方式为: -u -p
-B 指定要备份的数据库名 > 备份目标数据库名字
我们把数据库test1备份一下,备份数据库命名为test1.sql.
命令行如下:
 此时数据库就有了test1,sql这个备份数据库.我们打开test1.sql:
此时数据库就有了test1,sql这个备份数据库.我们打开test1.sql:
 我们发现test1.sql备份test1数据库的过程实际上就是把我们创建test1数据库包括增删查改的语句都存储了下来,后面还原的时候就是通过执行这些语句来进行还原的.
我们发现test1.sql备份test1数据库的过程实际上就是把我们创建test1数据库包括增删查改的语句都存储了下来,后面还原的时候就是通过执行这些语句来进行还原的.
还原数据库的命令是:source.
方式为 source+备份数据库的所在位置
如下图所示,我们先删除数据库test1,再通过test1.sql还原test1:

建表
建表的格式为:

其中编码格式,校验码格式,存储引擎不写用创建数据库时数据库配置里(/etc/my.cnf)默认的:
改
向表中新增字段的语句:
alert table 表名 add 字段名 数据类型
修改表的字段的语句:
alert table 表名 Modify 字段名 字段属性
删除表
drop table 表名
数据类型
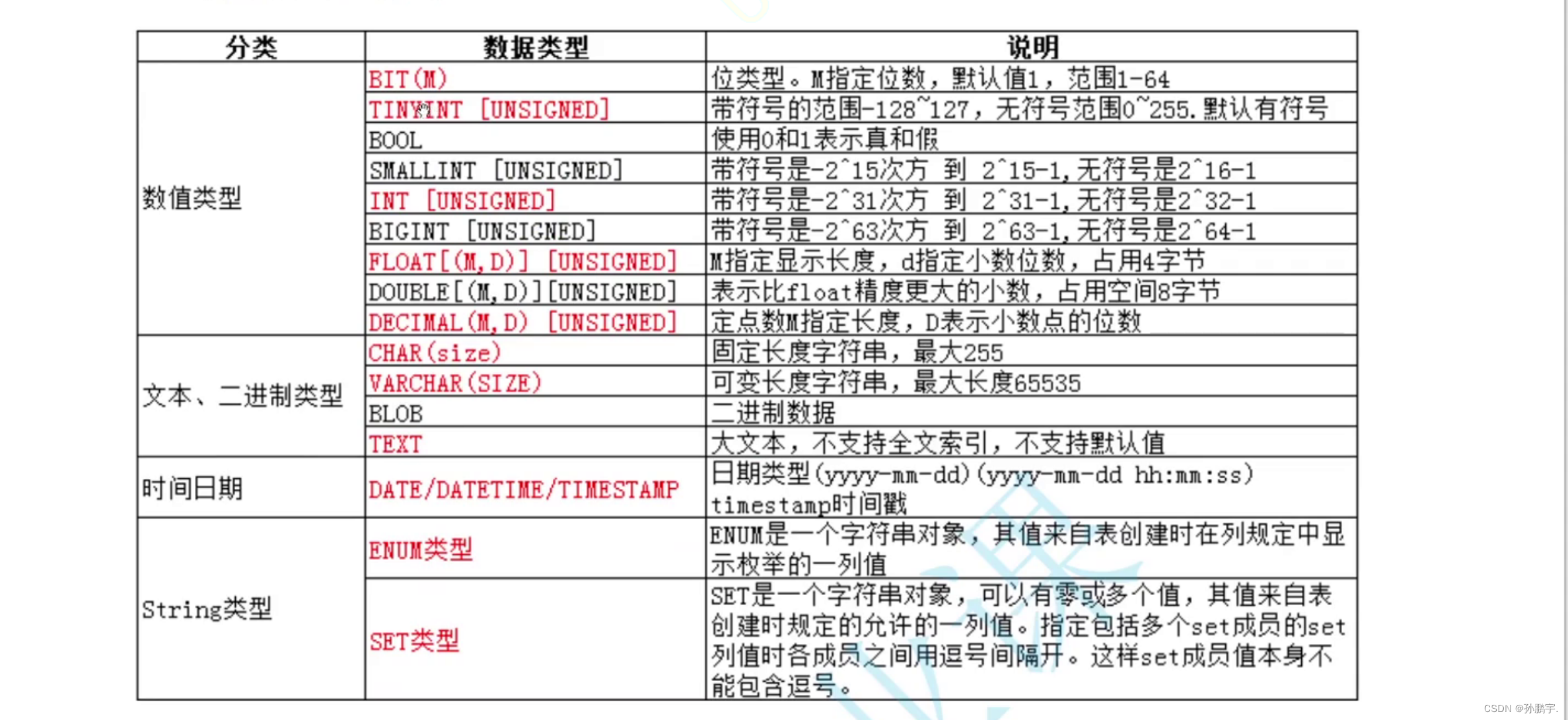
创建一个ceshi1 表,添加一个num字段,设置字段类型为tinyint.
建表完成后向表里插入**'-129','128**'发现都会被拦截,提示越界.
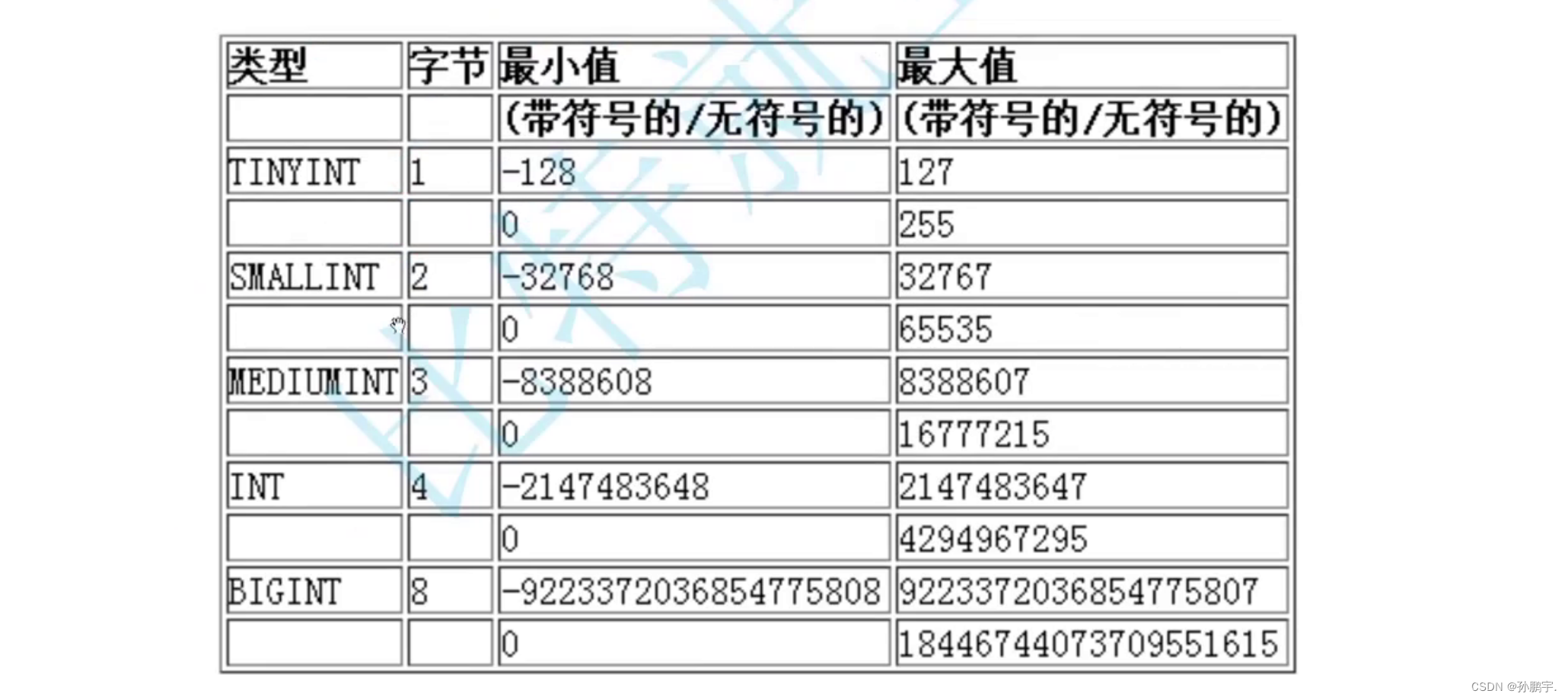
这是因为tinyint的数据范围是**-128~127** 
我们再创建一个ceshi2 表,添加一个num字段,数据类型为tinyint unsigned.
向num 字段插入值'256',会提示越界:

其他数据类型都是如此,不带unsigned默认创建的都是有符号类型的.
经过上面的测试我们可以发现数据类型是一种约束,约束程序员插入正确的数据.
bit数据类型

我们创建一个t1表,第一个字段id为int类型,第二个字段online为bit类型,默认为1个bit位,1表示在线,0表示不在线.

在向表里插入两条语句之后我们进行查询:
我们发现onlie字段没有显示任何内容.
这是因为bit类型存储的数据会以16进制的形式显示,我们用hex()函数将其转化为16进制之后就可以显示出来了: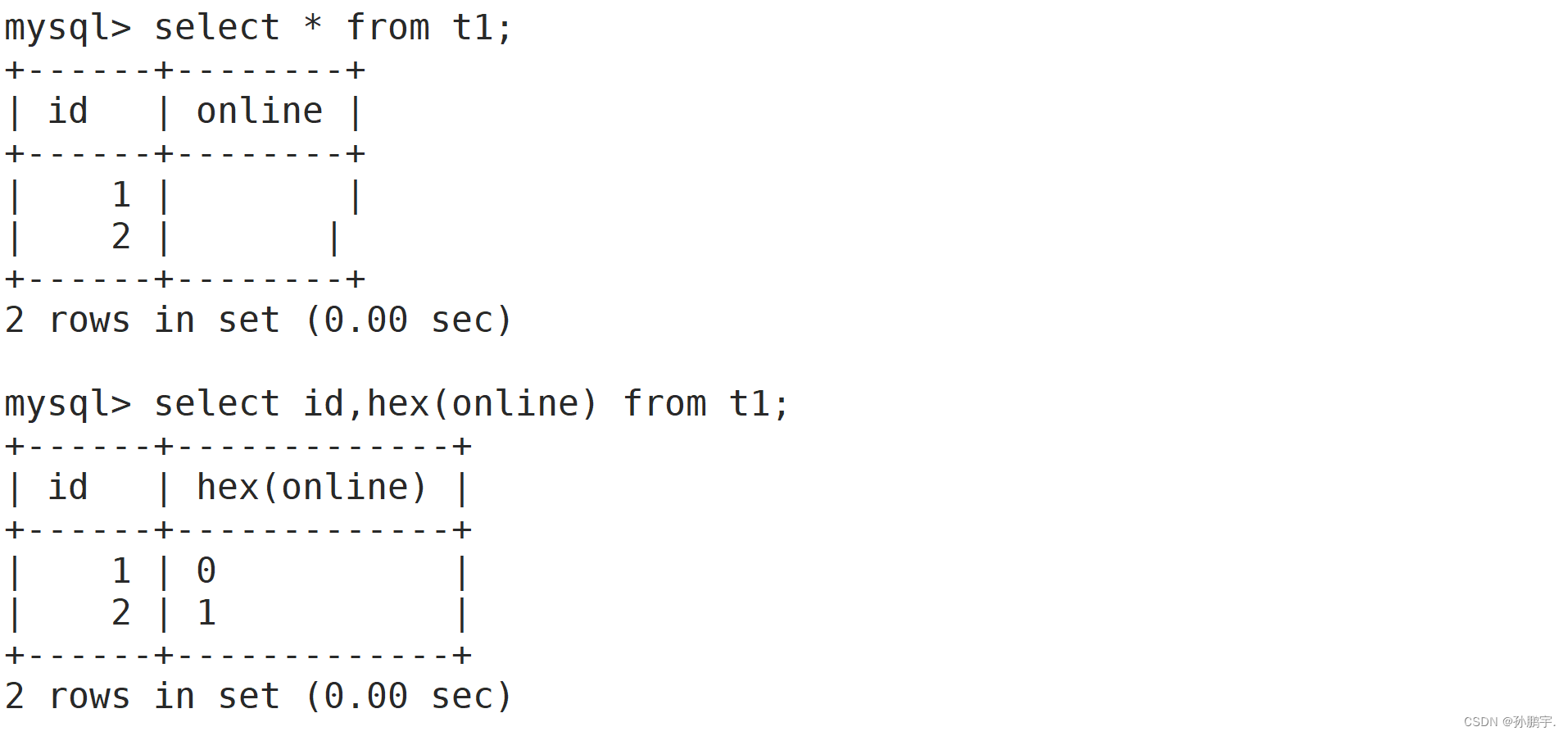
浮点类型

我们创建一个t2表,表中两个字段如下,其中 cj float(4,2)表示我们要插入的cj数据为总共4位长度,小数部分占两位的数据:

我们 发现我们插入的数据只要最终数据在-99.99 ~ 99.99之间就会按照四舍五入进行:
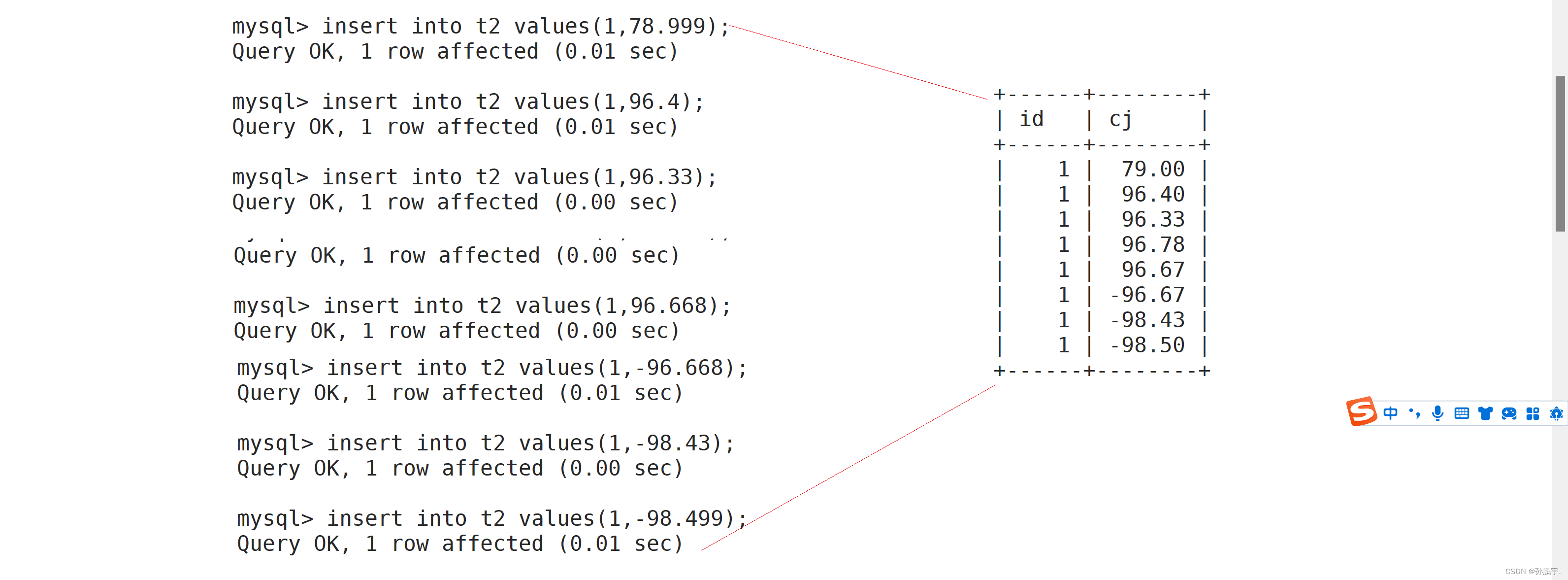
我们插入一个条数据,虽然99.998会按照四舍五入往前进,但是往前进位就变为100.00了,此时就变为5位数了,不符合(4,2)的约数,因为Mysql会对我们这条语句视为非法语句进行拦截:

字符串类型
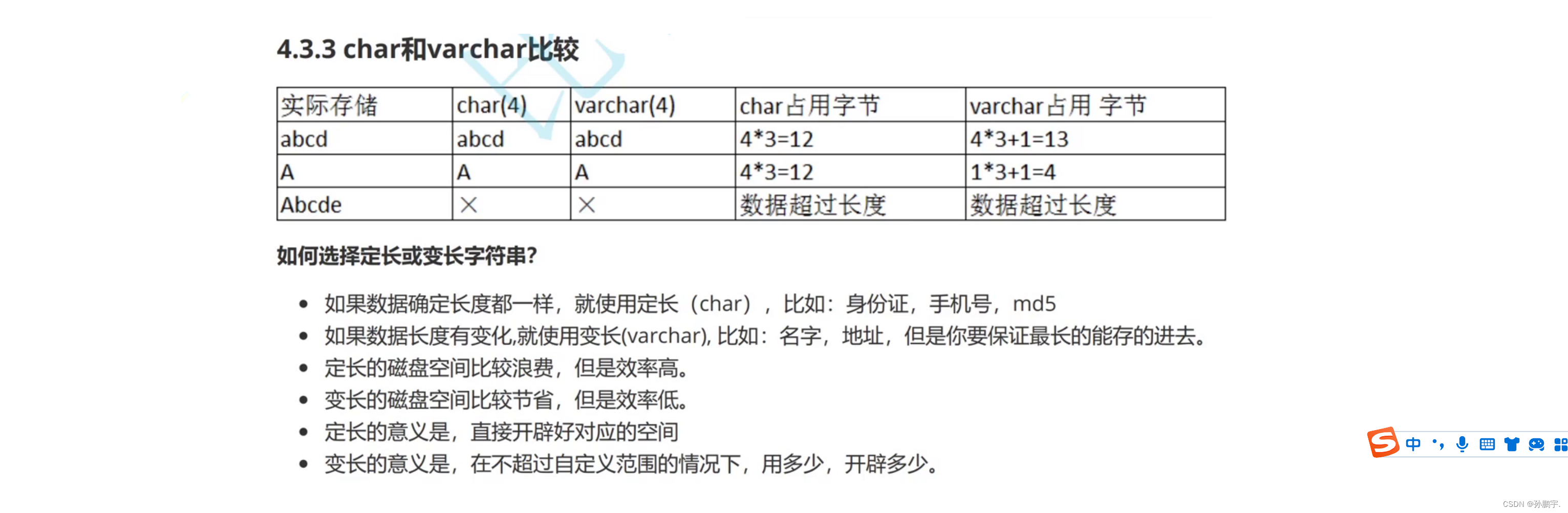
定长字符串类型char
MYSQL里的一个char占一个字符.
注意,这里不同于c语言里面的一个char占一个字节,一个汉字占两个字节.
这里说的占一个字符就真的是占一个字符,比如一个符号,一个字母,一个汉字.
如下,我创建一个大小为2字符的char类型字段name,向里面插入 '中','中国','中国人'三个语句,只有前两个语句插入成功,第三个语句则是超出范围了:

变长字符串类型varchar


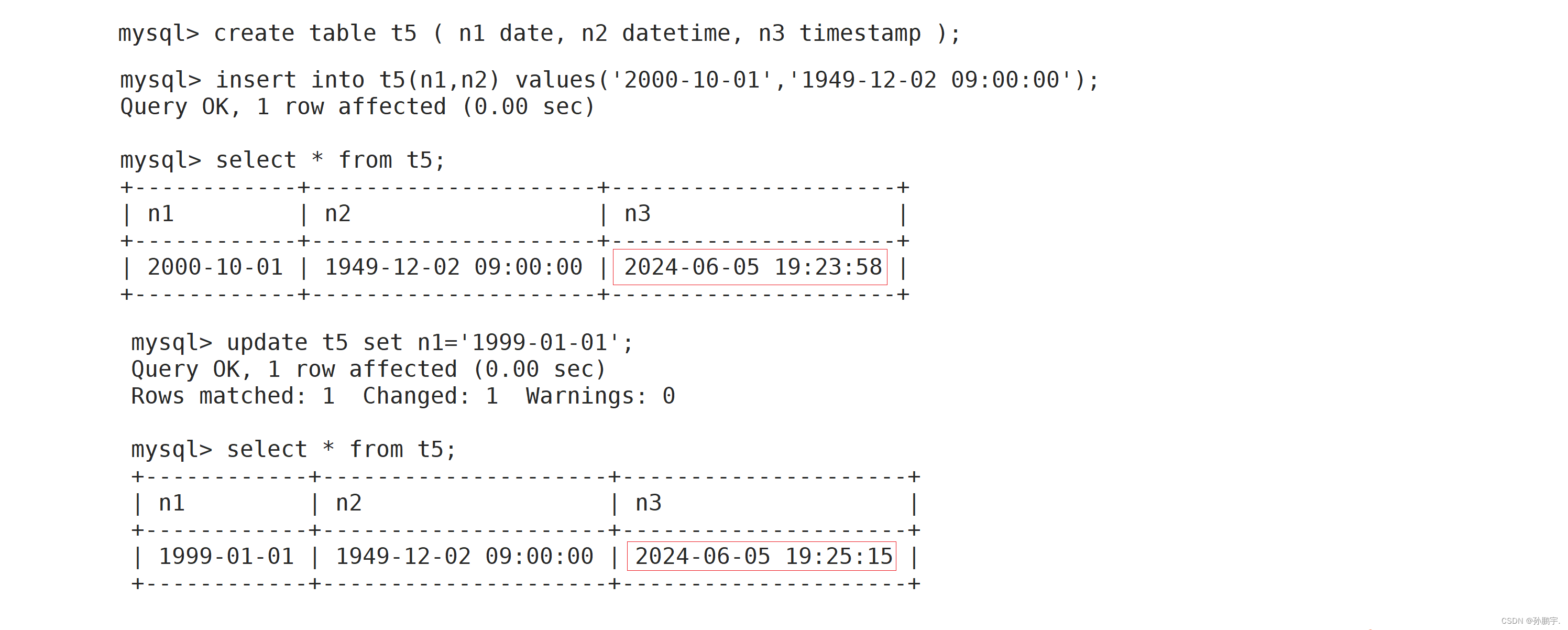
日期和时间类型数据

我们只要对表进行添加,修改字段,timestamp的时间戳都为自动变化:
enum和set
enum用来多选1,set用来多选.
如下所示:
我们可发现,xb字段只能在男,女之间选一个,也可以用下标的方式来选择,下标从1开始.
set集合可以进行多选,也可以单选.
