简介
在AWS概述一文中简单介绍过AWS EMR, 它是AWS提供的云端大数据平台。借助EMR可以设置集群以便在几分钟内使用大数据框架处理和分析数据。创建集群可参考官方文档:Amazon EMR 入门。但集群创建之后需要一直运行,用户需要管理集群的生命周期,包括启动、配置、监控和终止集群。因此EMR集群模式适用于需要长时间运行作业或者需要直接访问底层基础设施进行调试和运维的场景。
相比之下,EMR Serverless模式是一种无需管理集群的无服务器模式。用户只需提交作业,EMR Serverless会自动处理资源的部署、扩展和管理,按需提供计算资源。好处是无需管理集群,用户只需为实际使用的计算和存储资源付费,计算资源在作业完成之后会自动释放。下文将介绍如何创建EMR Serverless并提交作业。
创建EMR Serverless
首先需要一个Studio工作台,直接搜索EMR进入控制台,选择左侧EMR Serverless菜单,导航到landing页,点击"Get started"后会弹出提示窗口:
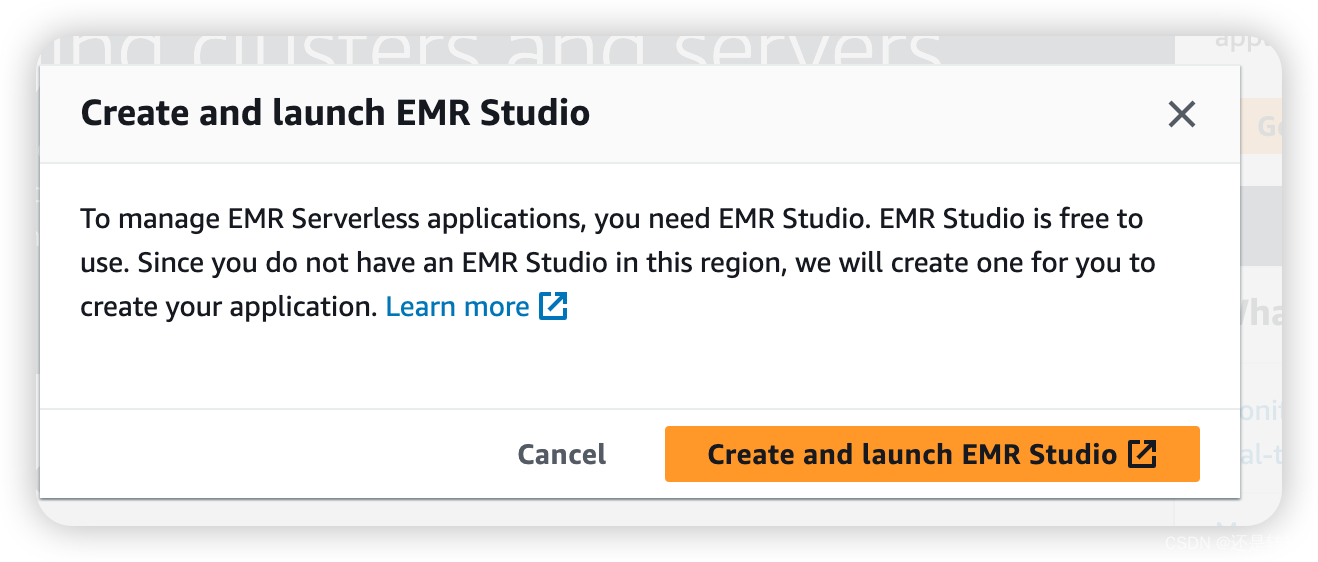
确认后AWS会创建一个默认的Studio和关联的Workspace,接下来会让你继续创建Application。这一步可以先停止,回退到工作台的dashboard也可以创建Application。创建Application时需要注意初始化选项,如果使用默认值,则应用的硬件资源基本是没有限制的。因此推荐使用自定义设置,将初始化资源容量和Application limit按照需要进行限制,防止使用过多资源:
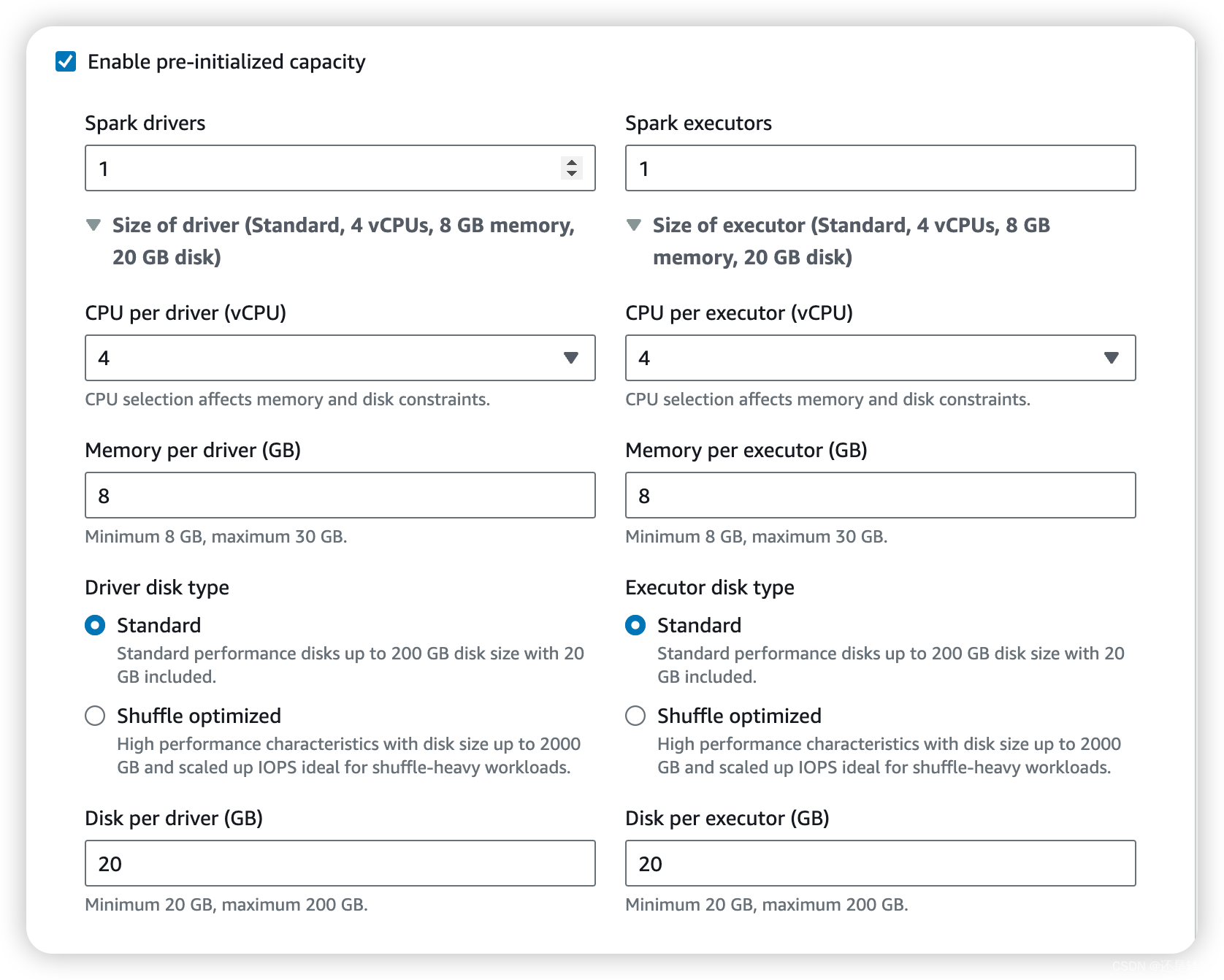
Application创建完成之后,AWS会自动创建一个role,但这个role是aws管理的,不能做任何修改。
我们还需要创建一个新的role,用于执行job。步骤如下:
-
先创建一个信任策略,如trust-policy.json
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "emr-serverless.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
该策略允许EMR Serverless服务(emr-serverless.amazonaws.com) 承担(assume)该角色。
-
创建role
aws iam create-role --role-name EMRServerlessJobRole --assume-role-policy-document file://trust-policy.json
执行成功会返回角色的详细信息,包括ARN。
-
创建角色策略1
aws iam create-policy --policy-name EMRServerlessS3AndGlueAccessPolicy --policy-document file://emr-custom-polocy.json
策略文件内容
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "ReadAccessForEMRSamples",
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:ListBucket"
],
"Resource": [
""
]
},
{
"Sid": "FullAccessToOutputBucket",
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:GetObject",
"s3:ListBucket",
"s3:DeleteObject"
],
"Resource": [
""
]
},
{
"Sid": "GlueCreateAndReadDataCatalog",
"Effect": "Allow",
"Action": [
"glue:GetDatabase",
"glue:CreateDatabase",
"glue:GetDataBases",
"glue:CreateTable",
"glue:GetTable",
"glue:UpdateTable",
"glue:DeleteTable",
"glue:GetTables",
"glue:GetPartition",
"glue:GetPartitions",
"glue:CreatePartition",
"glue:BatchCreatePartition",
"glue:GetUserDefinedFunctions"
],
"Resource": ["*"]
}
]
} -
将角色策略附加给角色
aws iam attach-role-policy --role-name EMRServerlessJobRole --policy-arn arn:aws:iam::123456789:policy/EMRServerlessS3AndGlueAccessPolicy
创建S3桶
创建S3桶以便存储任务的输入和输出文件。下载官方文档Amazon EMR 入门提供的数据集和任务脚本,将其上传到所创建的S3 bucket中:
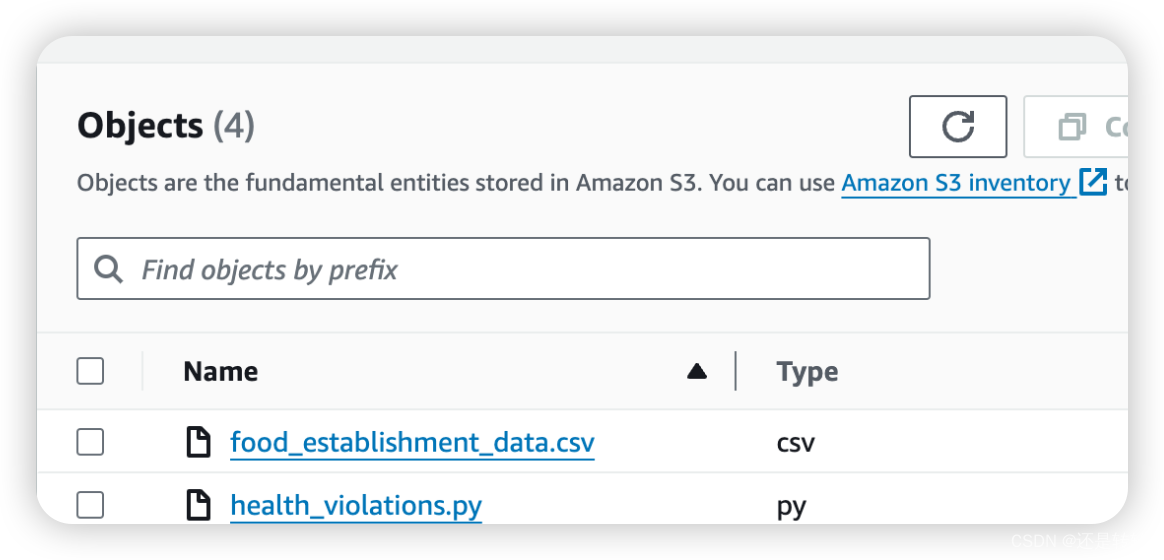
运行任务
现在Application和所需的role与S3资源都已经准备好了,可以运行任务了。
点击提交任务按钮,在任务界面输入Job的名称,选择上文创建好的角色,并从S3中选中任务脚本,指定脚本参数如下:
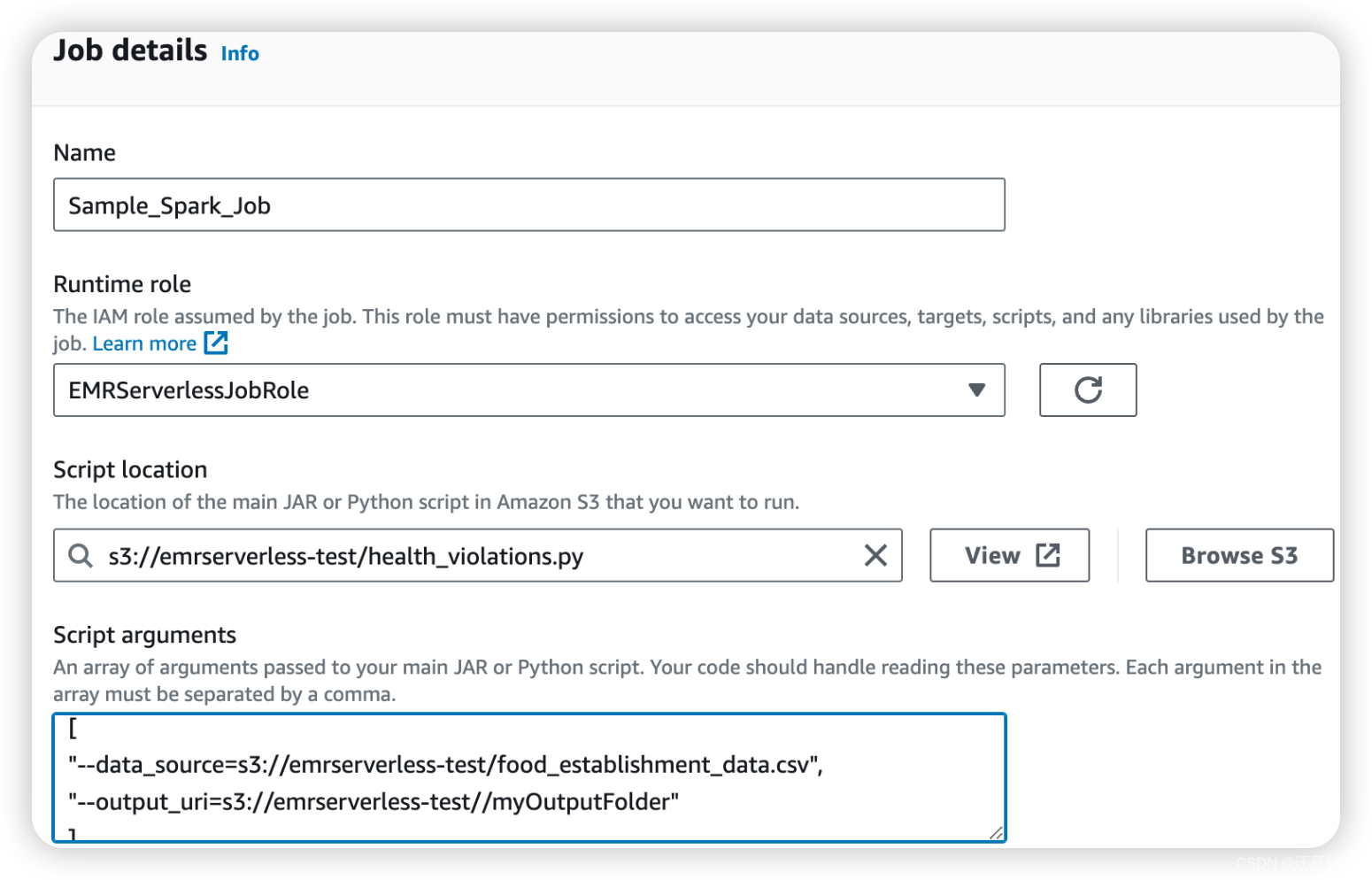
提交任务,稍等几分钟后即可看到运行结果。打开S3的输出文件夹可以看到具体处理后的结果信息。
提交任务时还可以选择demo任务,这是Spark自带的job示例。该job会输出Pi的值,无需S3和任务参数。
参考资料
1.https://docs.aws.amazon.com/zh_cn/emr/latest/EMR-Serverless-UserGuide/getting-started.html