异常说明
使用Spark 3.5.1 升级到Java17的时候会有一个异常,异常如下
bash
SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder".
SLF4J: Defaulting to no-operation (NOP) logger implementation
SLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details.
Exception in thread "main" java.lang.IllegalAccessError: class org.apache.spark.storage.StorageUtils$ (in unnamed module @0x1c88c82d) cannot access class sun.nio.ch.DirectBuffer (in module java.base) because module java.base does not export sun.nio.ch to unnamed module @0x1c88c82d
at org.apache.spark.storage.StorageUtils$.<clinit>(StorageUtils.scala:213)
at org.apache.spark.storage.BlockManagerMasterEndpoint.<init>(BlockManagerMasterEndpoint.scala:121)
at org.apache.spark.SparkEnv$.$anonfun$create$9(SparkEnv.scala:358)
at org.apache.spark.SparkEnv$.registerOrLookupEndpoint$1(SparkEnv.scala:295)
at org.apache.spark.SparkEnv$.create(SparkEnv.scala:344)
at org.apache.spark.SparkEnv$.createDriverEnv(SparkEnv.scala:196)
at org.apache.spark.SparkContext.createSparkEnv(SparkContext.scala:284)
at org.apache.spark.SparkContext.<init>(SparkContext.scala:483)
at org.apache.spark.SparkContext$.getOrCreate(SparkContext.scala:2888)
at org.apache.spark.sql.SparkSession$Builder.$anonfun$getOrCreate$2(SparkSession.scala:1099)
at scala.Option.getOrElse(Option.scala:201)
at org.apache.spark.sql.SparkSession$Builder.getOrCreate(SparkSession.scala:1093)
at org.apache.spark.examples.JavaStatusTrackerDemo.main(JavaStatusTrackerDemo.java:55)原因分析
分析下来是因为新版本的jdk是引入了模块的概念,在常规的包引入的时候是都有模块定义的
最关键的信息
bash
cannot access class sun.nio.ch.DirectBuffer (in module java.base)按照这个信息分析了一把,在Java9以上的版本里面会有module-info.class这部分信息,这个是对模块的定义,当然我们没有主动去引入,这部分就是jdk默认帮我们引入的模块信息。
在这部分我们可以找到sun.nio.ch的引入范围,其实可以发现 sun.nio.ch.DirectBuffer的类并不在引入的范围内
java
module java.base {
exports java.io;
exports java.lang;
exports java.lang.annotation;
exports java.lang.constant;
...
exports sun.nio.ch to
java.management,
jdk.crypto.cryptoki,
jdk.incubator.foreign,
jdk.net,
jdk.sctp;
}这个其实就是一种兼容性的需求了,为了解决这种问题,jdk提供了一些启动的参数,可以强制引入,类似下面这样,其实含义就是主动开发一些内部的模块对外部使用
bash
--add-opens=java.base/java.lang=ALL-UNNAMED
--add-opens=java.base/java.lang.invoke=ALL-UNNAMED
--add-opens=java.base/java.lang.reflect=ALL-UNNAMED
--add-opens=java.base/java.io=ALL-UNNAMED
--add-opens=java.base/java.net=ALL-UNNAMED参数是怎么来的
另外一个问题是,怎么知道Spark启动的时候都开放哪些参数呢,陆陆续续查询到资料,这个参数信息其实是在
org.apache.spark.launcher.JavaModuleOptions 中定义的
Spark启动的时候会追加
java
private static final String[] DEFAULT_MODULE_OPTIONS = {
"-XX:+IgnoreUnrecognizedVMOptions",
"--add-opens=java.base/java.lang=ALL-UNNAMED",
"--add-opens=java.base/java.lang.invoke=ALL-UNNAMED",
"--add-opens=java.base/java.lang.reflect=ALL-UNNAMED",
"--add-opens=java.base/java.io=ALL-UNNAMED",
"--add-opens=java.base/java.net=ALL-UNNAMED",
"--add-opens=java.base/java.nio=ALL-UNNAMED",
"--add-opens=java.base/java.util=ALL-UNNAMED",
"--add-opens=java.base/java.util.concurrent=ALL-UNNAMED",
"--add-opens=java.base/java.util.concurrent.atomic=ALL-UNNAMED",
"--add-opens=java.base/sun.nio.ch=ALL-UNNAMED",
"--add-opens=java.base/sun.nio.cs=ALL-UNNAMED",
"--add-opens=java.base/sun.security.action=ALL-UNNAMED",
"--add-opens=java.base/sun.util.calendar=ALL-UNNAMED",
"--add-opens=java.security.jgss/sun.security.krb5=ALL-UNNAMED"};解决方案
在java启动的时候追加参数,问题可以解决
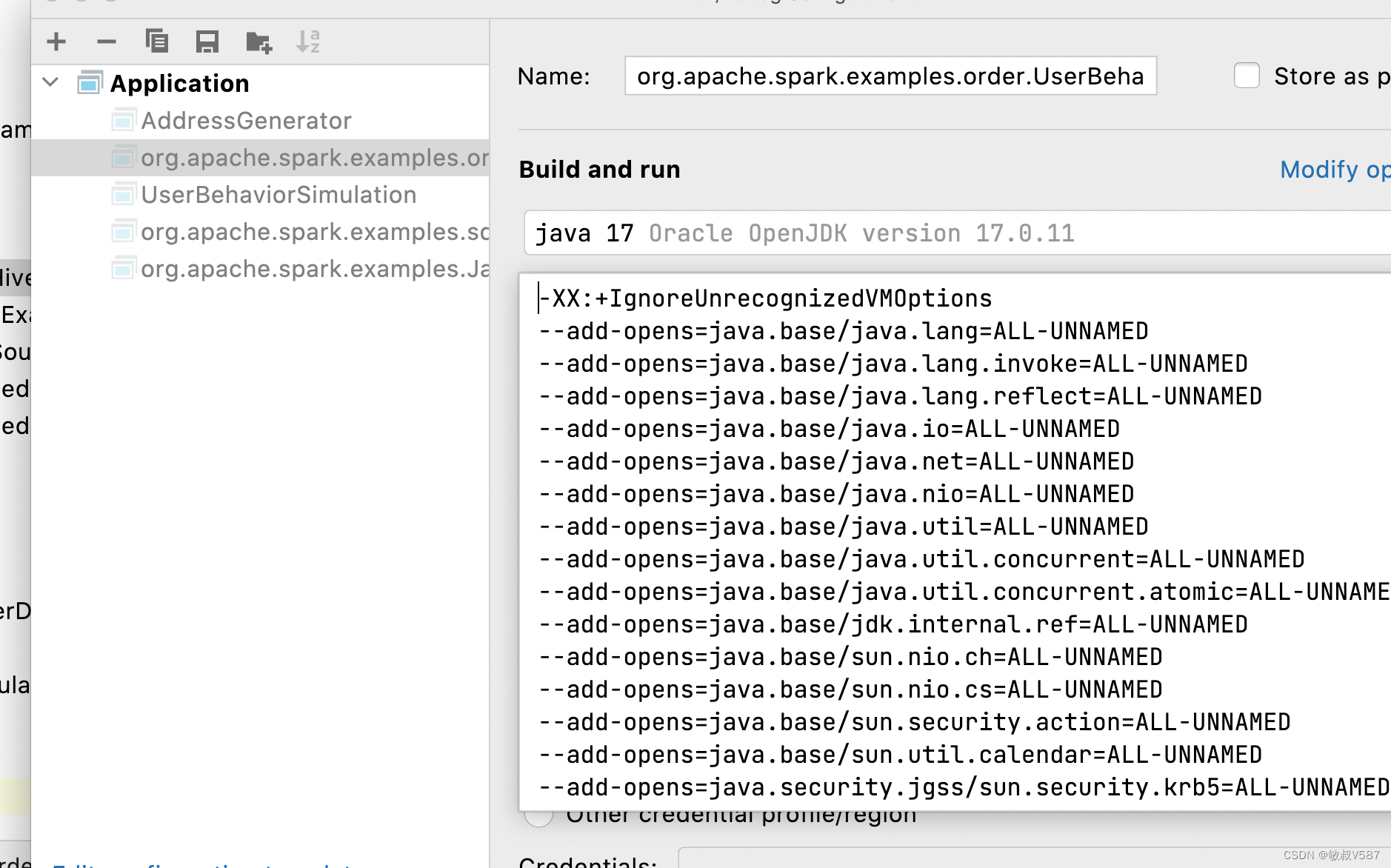
进一步追问
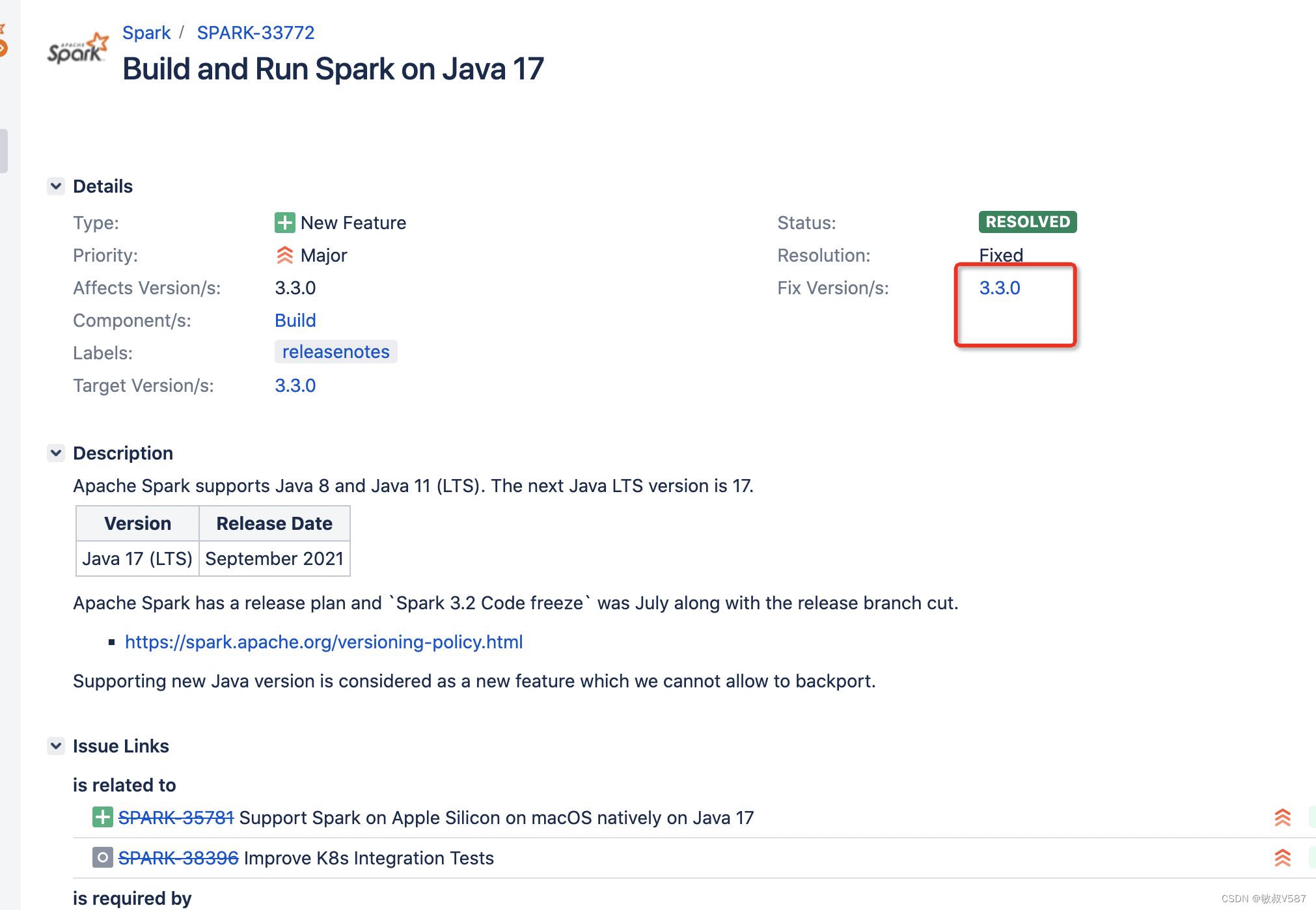
这个问题其实是在jira中间有记录的
可以看链接 https://issues.apache.org/jira/browse/SPARK-33772
我依旧纠结的情况是这个其实是在3.3.0版本就解决了,我这个可是3.5.1不应该出这个问题啊。
我找到了引用这段代码的地方,是在类
org.apache.spark.launcher.SparkSubmitCommandBuilder.java里面
java
private List<String> buildSparkSubmitCommand(Map<String, String> env)
//这里构造启动参数
...
if (isClientMode) {
//这里构造客户端参数
...
}
//追加参数
addOptionString(cmd, JavaModuleOptions.defaultModuleOptions());
cmd.add("org.apache.spark.deploy.SparkSubmit");
cmd.addAll(buildSparkSubmitArgs());
return cmd;
}其实上游就是构造参数的地方。
悟了
看到这里,我终于联系起来了。咋回事呢
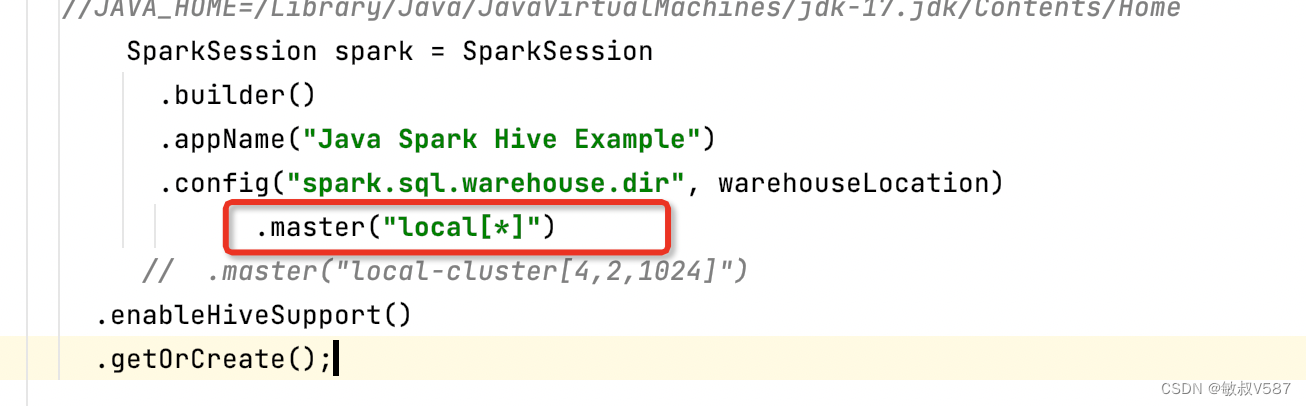
我自己写的程序其实就是在main函数上面执行,所以需要添加参数什么的需要自己去指定。
这种其实就是单机模式。我们日常在启动spark程序从控制台上启动,spark-submit这种,其实是SparkSubmit这个程序去帮我们拼接里面的参数,其实我们可以改变这种local模式,我们可以启动一种叫做本地的集群模式,需要改变master参数,完整代码如下:
java
public final class JavaSparkPi {
public static void main(String[] args) throws Exception {
System.out.println(JavaModuleOptions.defaultModuleOptions());
SparkSession spark = SparkSession
.builder()
.appName("JavaSparkPi")
.master("local-cluster[8,2,1024]")
.getOrCreate();
System.out.println(spark.sparkContext().uiWebUrl());
spark.sparkContext().addJar("/Users/zhuxuemin/spark-examples-3.5.1/target/spark-examples-3.5.1-0.1-SNAPSHOT.jar"); //集群模式需要添加jar路径
JavaSparkContext jsc = new JavaSparkContext(spark.sparkContext());
jsc.setLogLevel("INFO");
...//这里是代码逻辑
}
}启动之后从控制台里面java命令可以看到参数:
bash
前面这部分参数是我们自己加的
/Library/Java/JavaVirtualMachines/jdk-17.jdk/Contents/Home/bin/java --add-exports java.base/sun.nio.ch=ALL-UNNAMED -Dfile.encoding=UTF-8 -classpath
这里中间很多jar包,下面找到参数,这部分就是spark代码自己加的
"--add-opens=java.base/sun.nio.cs=ALL-UNNAMED" "--add-opens=java.base/sun.security.action=ALL-UNNAMED" "--add-opens=java.base/sun.util.calendar=ALL-UNNAMED" "--add-opens=java.security.jgss/sun.security.krb5=ALL-UNNAMED" "-Djdk.reflect.useDirectMethodHandle=false" "org.apache.spark.executor.CoarseGrainedExecutorBackend" "--driver-url" "spark://CoarseGrainedScheduler@www.kube.com:50404" "--executor-id" "57" "--hostname" "192.168.31.89" "--cores" "2" "--app-id" "app-20240602104758-0000" "--worker-url" "spark://Worker@192.168.31.89:50411" "--resourceProfileId" "0"这里面的逻辑就是我们启动的main函数,会按照分布式的模式去启动worker,启动之前会生成命令行,就是我们看到的样子。
好了,死磕到这里了,算是可以睡着了,zzzz~~~
参考资料
翻了很多资料,贴上
https://cloud.tencent.com/developer/ask/sof/107234786
https://issues.apache.org/jira/browse/SPARK-33772