文章目录
前言
相比较于存储引擎的精妙设计,ClickHouse的计算引擎一直是一个争议非常大的话题。对ClickHouse计算引擎的各种评价都有,两极分化很严重。有人认为ClickHouse计算引擎的向量化设计得巧夺天工,也有很多人认为ClickHouse的计算引擎缺乏优化和对分布式的支持,就是个半成品。这些对ClickHouse计算引擎的评价都在一定程度上反映了ClickHouse计算引擎的某些方面,如果从这些方面来看待ClickHouse的计算引擎,难免陷入盲人摸象的状态。
本文将介绍ClickHouse计算引擎的架构,以及ClickHouse的向量化计算引擎与传统事务数据库的火山引擎之间的区别。整体了解ClickHouse计算引擎后,我们将客观地得出自己对ClickHouse计算引擎的评价。
ClickHouse计算引擎的架构简介与设计思想
传统计算引擎会将 SQL 转换为物理计划,Clickhouse 也一样, Clickhouse 将物理计划叫做查询流水线(QueryPipeline)。
架构简介
整体架构
ClickHouse计算引擎整体架构如下图所示,由三部分组成:SQL解析器(Parser)、解释器(Interpreter)、执行器(PipelineExecutor)。
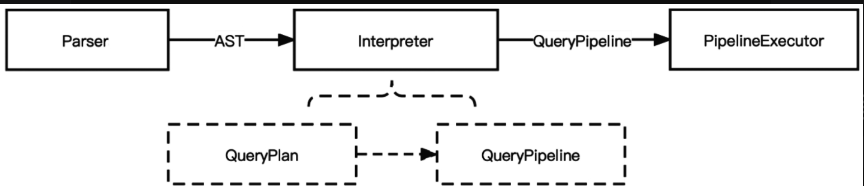
ClickHouse计算引擎整体架构是按照火山引擎的模式进行设计的,将SQL语句转化为可以被执行的处理单元(Processor)的集合,由执行器执行。向量化引擎和火山引擎最大的不同点在于ClickHouse的处理单元的设计是面向向量的,而传统事务数据库是面向行的。构成QueryPipeline的处理单元不同,导致ClickHouse计算引擎和传统的火山模型的不同。这也是ClickHouse向量化引擎的由来。
SQL解析器
- Clickhouse 中的 SQL 解析器并没有使用传统的开源方案,而是自己手写的,但是 SQL 解析在整个查询中的耗时可以忽略不计。
解释器
- Clickhouse 解释器会根据 AST 树生成查询流水线,该阶段会对SQL 进行逻辑优化,ClickHouse中实现的逻辑优化主要是基于规则进行优化,常用的手段有谓词下推、count优化、消除重复字段等。
执行器
- ClickHouse通过执行器对查询流水线进行处理,最终获得结果即为用户提交的SQL语句的执行结果。
- ClickHouse的高性能来自向量化引擎。向量化引擎的核心在于查询流水线的编排方式,火山模型和向量化模型的本质区别在于SQL语句的编排方式。
设计思想
Clickhouse 的所有架构设计都是为了一个目标:充分发挥单机能力的OLAP引擎
充分利用现代CPU特性
- 向量化引擎利用了现代CPU提供的SIMD能力,提供的硬件加速能力。
充分发挥单机优势
-
Clickhouse 中的表都是对单机表的操作,Clickhouse 中的集群表并不是真正意义上类似于 Hadoopz 中的分布式表,而是单机表的映射。
因此 Clickhouse 中的 SQL 对大表 JOIN 操作,经常由于内存不足导致失败,Clickhouse 的更多架构设计放在了向量化引擎上。
-
我们在使用 Clickhouse 查询时应该尽量避免 JOIN 操作,充分发挥向量化引擎的特性。
火山模型
ClickHouse的向量化引擎是基于标准火山模型进行的调整。
火山模型执行示意图如下,一般经历三个过程,扫描,过滤,投影 ,每一个过程都会返回一个元组 ,执行完毕后调用 next() 方法,进入下一过程计算。
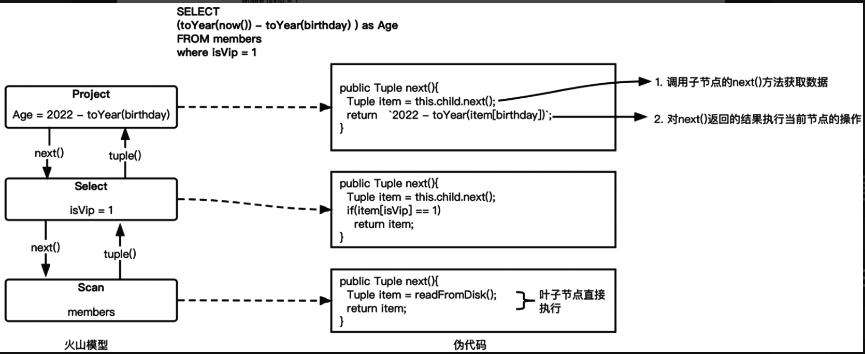
- 扫描(Scan)节点负责从磁盘中读取所有member表的数据并交给过滤(Select)节点。
- 过滤节点负责过滤出满足过滤条件的数据并交给投影(Project)节点。
- 投影节点负责将表中birthday列的数据筛选出来,再按照用户提供的计算公式计算出Age并返回给用户。
- 过滤指的是按行筛选,投影指的是按列筛选。
火山模型的核心是有很多独立的算子,每个算子计算出一个元组,然后每个算子又是一个迭代器,通过 next() 方法调用下一个算子。例如Join操作,在火山引擎中表现为一个Join迭代器,在其next方法中实现Join操作的各种算法,返回元组,供上层进一步操作。再如OrderBy操作,在火山引擎中也会表现为一个OrderBy迭代器,在其next方法中将输入的数据按照规则进行排序,并向上输出元组供上层使用。
优点
- 通过堆叠不同节点的方式实现能力,因此在实现火山引擎时只需要实现有限数量的计算节点,且每个节点只需要实现单一的简单功能,即可完成模型的构建。
缺点
- 可能导致堆叠的层数过多,甚至出现大量的递归操作,从而降低查询性能。
向量化引擎
向量化引擎是在火山引擎的基础上实现的,火山引擎每一个算子返回的是元组,由不同的列组成,而向量化引擎返回的是单独列组成的数组,也被称为列向量 。
向量化引擎的实现方式
火山引擎和向量化引擎的物理计划执行对比如下图:
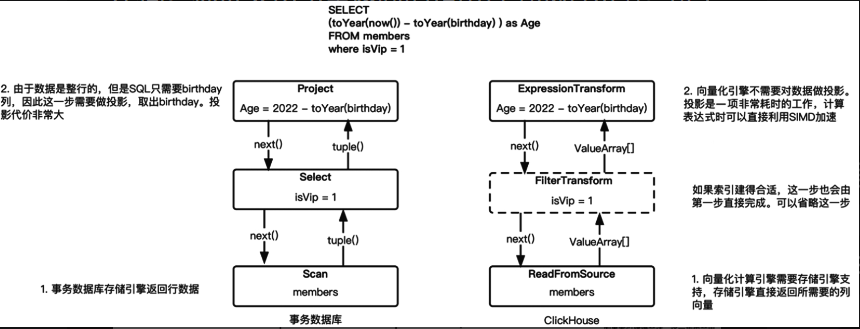
向量化引擎列向量的设计,可以使投影操作将下推至扫描阶段,在第一步扫描阶段直接返回birthday列。最终,该SQL语句的执行顺序如下:
- 通过读取数据源(ReadFromSource)节点直接获得birthday列向量。
- 通过过滤转换(FilterTransform)节点筛选出满足isVip=1的数据。
- 通过表达式转换(ExpressionTransform)节点计算出Age。
将投影操作下推至底层阶段,可以在表中列的数量比较多的场景下获得很高的性能。
另外,向量化引擎可以使用向量化的算法进行计算,充分利用CPU并行计算的特性,实现计算加速。
向量化引擎的前提
既然向量化计算可以并行计算,提升查询性能,为何传统的事物数据库不使用向量化计算呢?
下边让我们看下向量化引擎的前提。
存储引擎支持
- 向量化引擎产生效果的前提是存储引擎返回的数据是按列聚集的,而事物数据库一般是行存,对于行存的存储引擎来说,设计向量化的计算引擎没有必要。除非事务数据库能够抛弃传统的行存存储引擎,改用列存储引擎。
- 即使改为列存,事物数据库的核心是事物性,列存的存储引擎在应对事务时会带来更多的额外工作,导致事务的性能急剧下降,得不偿失。
硬件支持
- 需要 CPU 支持 SIMD 向量化计算,软件只是将组织好的数据交给硬件,真正执行向量化计算的还是 CPU。
软件支持
- 这里的软件特指编译器和向量化算法。编译器会自动将符合向量化优化的操作编译为特殊的SIMD指令。
计算引擎如何影响查询速度
Clickhouse 的向量化引擎可以利用向量化计算大大加速查询速度,但是凡事有利有弊,Clickhouse 在解释器阶段生成物理计划的时候,并没有进行 CBO(代价优化器)优化物理计划,只有逻辑计划的优化,导致对于有些 SQL 场景反而查询速度很慢,甚至失败。
因此在使用 Clickhouse 进行查询时,我们也需要注意一些事项,充分发挥向量化计算的优势。
大量使用向量化运算
- 尽可能使用ClickHouse提供的内置函数进行计算,而不是自己写SQL 计算语句。
查询语句中没有使用Join子句,或尽可能少地使用Join操作
- 在使用ClickHouse时,应当尽可能避免Join操作。
- ClickHouse在设计良好的DW层上运行向量化查询的性能最高,尽可能避免将ClickHouse用于ODS层的建模工作中。当数据量大时,这类建模工作还是尽可能下推到Spark上进行。
总结
作为用户,我们应该了解ClickHouse速度快的前提,有意识地避开ClickHouse的雷区,不要将ClickHouse用于其不擅长的场景。正如此时此刻,大家都意识到了MySQL无法解决大数据量的OLAP问题,这类问题要通过专业的OLAP引擎解决。
开源社区要的并不是什么能力都有、但都不强的平庸的软件,而是百花齐放、各自有着各自擅长的领域的产品,通过组合实现架构上的合力。