1、JVM栈的数据存储
通过前面的学习,我们知道,将源代码编译成字节码文件后,JVM会对其中的字节码指令解释执行,在解释执行的过程中,又利用到了栈区的操作数栈和局部变量表两部分。
而局部变量表又分为一个个的槽位,通常第0个槽位存放实例方法的this。而每个槽位的空间大小是根据不同虚拟机决定的:
- 32位虚拟机:32位,4个字节。
- 64位虚拟机:64位,8个字节。
在Java中有八大基本数据类型,它们在堆中占用的字节数都是不同的,如下表所示:
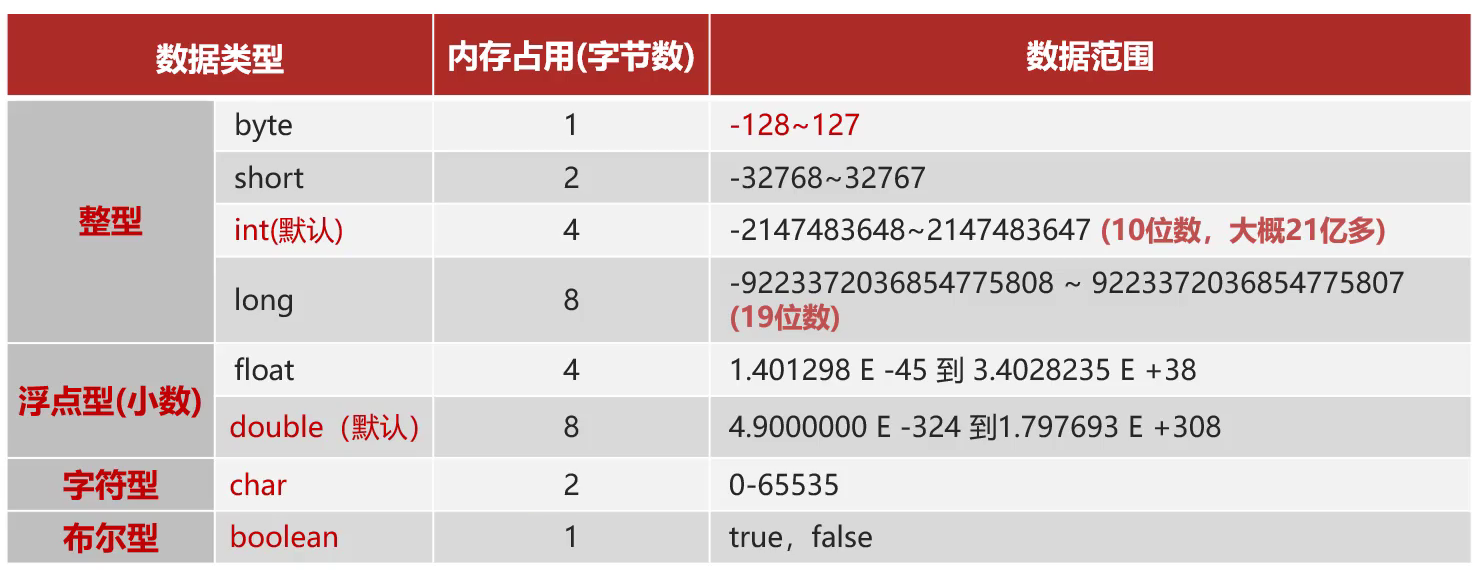
其中内存占用最多的是long和double类型,8个字节。
它们在局部变量表中,需要占用两个槽位。如果这样说,很多人会有疑问,"每个槽位的空间大小是根据不同虚拟机决定的",如果是32位虚拟机,每个槽位只有4个字节,占用两个槽位是没有问题的。但是如果是64位虚拟机呢?每个槽位有8个字节,按理说一个槽位就可以放下了,为什么还是需要占用两个槽位?
原因在于,Java语言的跨平台特性。局部变量表是在编译期间就确定下来的,无法得知将来JVM会在何种环境下解释执行字节码指令。所以为了保证通用性,统一按照64位虚拟机进行考虑。并且虽然long和double类型占用了两个槽位共16个字节,实际上它的高8字节是没有被使用的。
栈中的数据要保存到堆上&堆中加载到栈上需要如何实现?
在编译成的字节码文件中,所有占用了一个槽位的数据类型都是被当做了int执行(iconst),int默认占有4个字节,也就是在栈上这些都默认占有了4个字节。

但是在堆上,它们实际有的只占有了1个字节,有的占有了2个字节。所以栈中的数据要保存在堆上,需要进行截取,堆中的数据加载到栈上则反之。
在进行过程分析之前,首先要明白两个概念,符号位和高(低)位
- 符号位:符号位是在计算机中用来表示数值的正负的特殊位。通常情况下,一个整数的符号位是用来表示该整数是正数还是负数的。在计算机中,符号位通常是由整数类型的最高位(最左侧的位)来表示的,其中 0 表示正数,1 表示负数。例如,在一个有符号的 8 位整数中,如果最高位是 0,则该整数被解释为正数;如果最高位是 1,则该整数被解释为负数。
- 高低位:通常是指在计算机中用于表示数字的二进制位的位置。在一个多字节的数据类型(比如整数或者浮点数)中,位被分为高位和低位两部分。高位是数据中权值最高的位,通常位于数据的最左侧。在有符号整数中,高位通常用于表示符号位(0 表示正数,1 表示负数)。在无符号整数中,高位用于表示最大的数值。低位是数据中权值最低的位,通常位于数据的最右侧。低位存储着数据的最小的权值。
堆中的数据加载到栈上时,也要考虑符号位的问题。boolean和char类型没有符号位,直接高位补0即可,byte和short有符号位,低位直接复制,高位负则补1,非负补0:

栈中的数据要保存在堆上 ,需要将高位截取掉。而boolean类型只取低位的最后一位。
2、JVM对象在堆上的存储
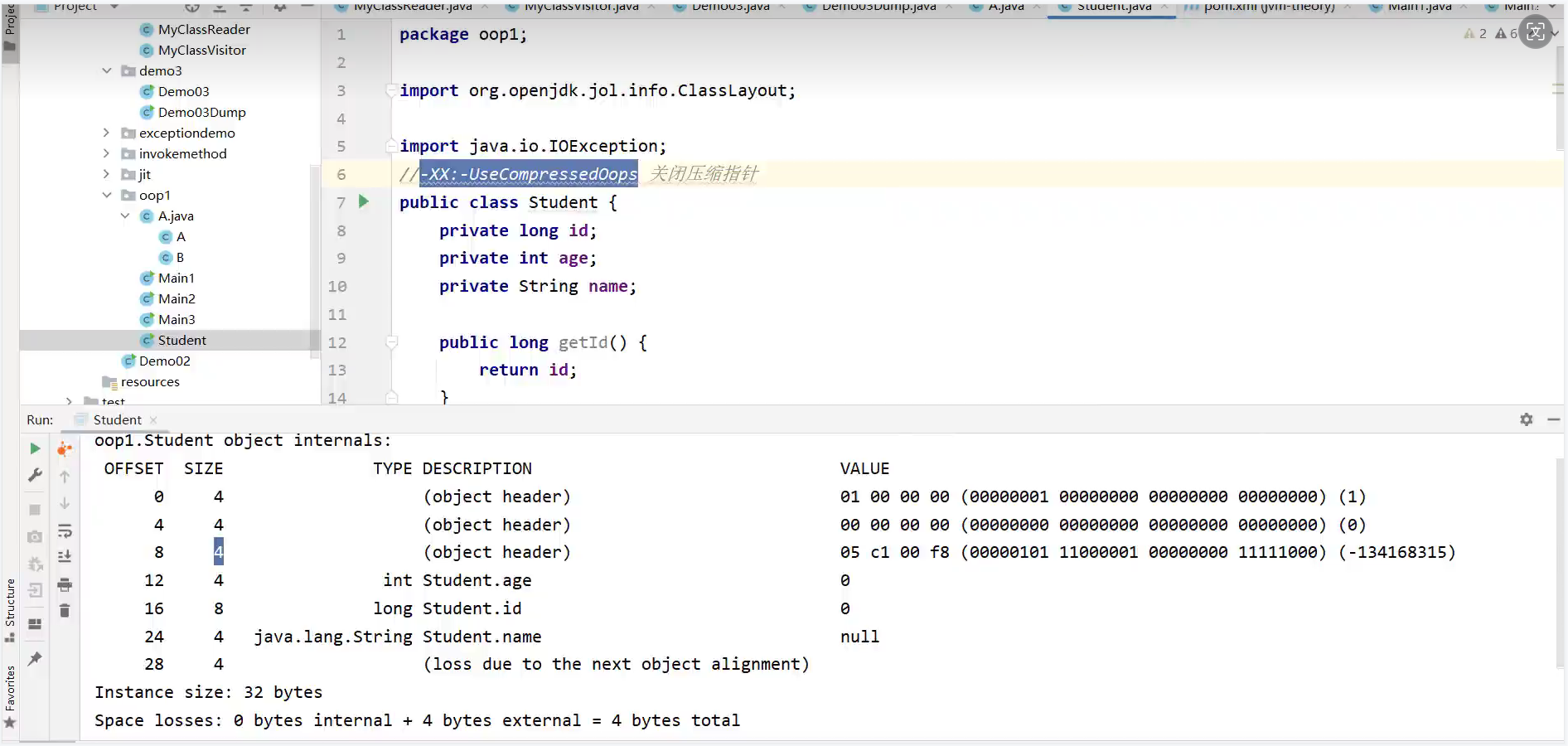
对象在堆中的内存布局,分为对象头和对象数据两部分,对象头中又有标记字和类型指针。如果是数组对象类型,对象头中额外保存了数组的容量。
其中标记字 的结构,在64位和32位虚拟机中都不一样,其中64位虚拟机又分为是否进行了指针压缩:

我们也可以通过JoL jar包中提供的方法打印出这一块的信息:

在打印出的信息中,我们可以发现,引用数据类型是排在最后的,并且在类的定义中,是long变量在前,int变量在后。但是打印出的对象头信息中,两者的顺序发生了交换,原因在于,每个属性的偏移量必须是字段长度的整数倍。在这个案例中,假如long变量在前,那么它的OFFSET和SIZE 就会变成12和8,不满足整数倍的条件,所以会做出调整。这就是内存对齐。
而内存对齐的主要目的是为了解决在并发环境下cpu缓存失效的情况。
简单来说,在一个缓存行中,可能存在多个实例的缓存。当其中一个实例的缓存失效需要更新时,会让整个缓存行都失效。从而影响到缓存行中的其他对象。

内存对齐后,可以理解成同一个缓存行不会存有不同类型的对象,即使某个对象的缓存失效,也不会影响其他的对象:

上面也提到过指针压缩的概念。什么是指针压缩?
指针压缩是一种优化技术,用于减小程序中指针所占用的内存空间。
在64位系统中,一个指针通常需要8个字节。但在许多情况下,指针实际指向的地址并不需要使用那么多的位来表示,因为程序的内存地址空间可能不会达到8字节指针所能表示的范围。
指针压缩技术利用这一点,通过降低指针所占用的位数来节省内存空间。这通常是通过将指针存储为较小的数据类型(比如32位系统中的4字节)来实现的,因为在大多数情况下,程序的内存地址空间并不会达到需要用到更多位表示的程度。
指针压缩的一个常见实现方式是使用对象偏移量(Object Offset)来表示指针。在这种情况下,指针不再直接存储对象的内存地址,而是存储对象相对于某个基准地址(如堆的起始地址)的偏移量。通过这种方式,可以使用较少的位数来表示指针,从而节省内存空间。
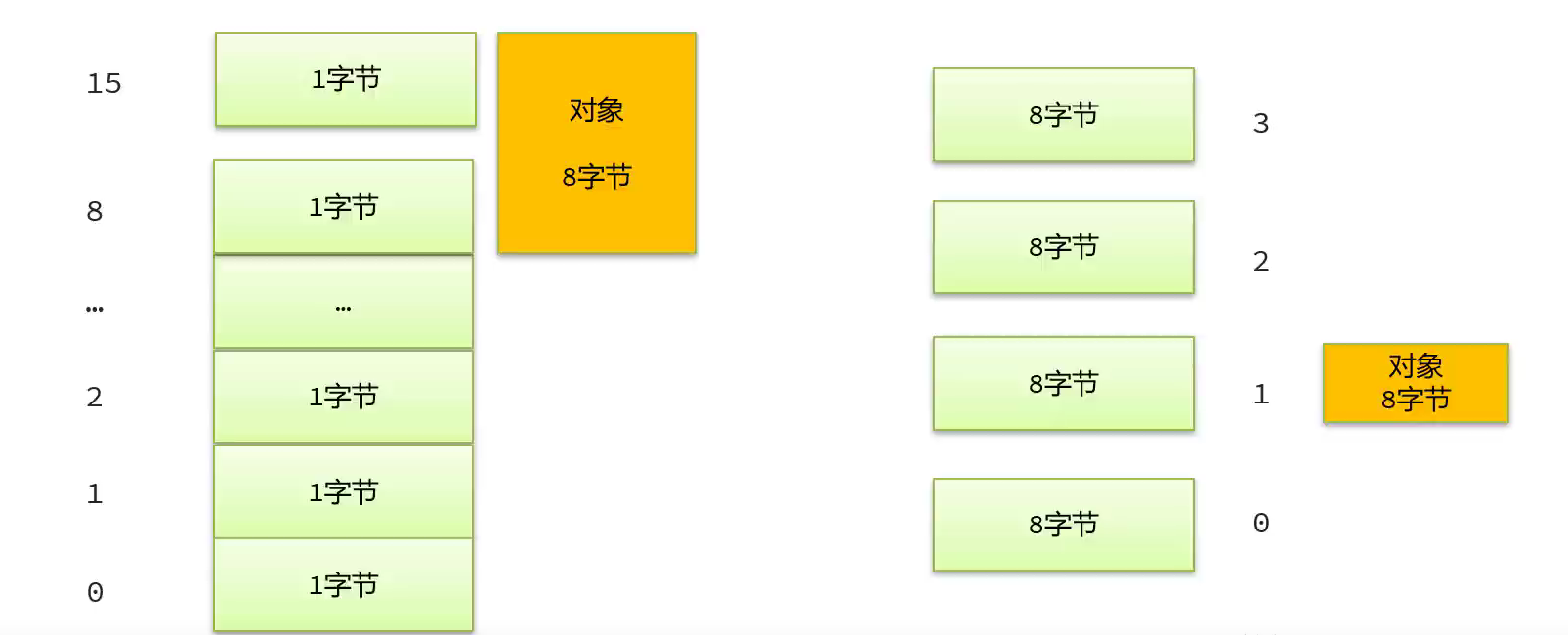
例如下图,左边的部分没有进行指针压缩,右边的部分进行了指针压缩。
没有进行指针压缩时,当前对象的内存地址是8,并且占用了8个字节。进行了内存压缩后,指针中不存放真实的地址,而是存放编号(偏移量)。