@Toc(elasticsearch hanlp插件自定义分词配置(停用词))
既然可以自定义关键词,那么自然也是可以自定义停用词的。
背景
由于在使用elasticsearch hanlp(以下简称es hanlp)的过程中,分词会出现一些无用的词,比如各种标点符号或者没有意义的单词,导致查询的效果不是很理想,比如

这个时候就会想到是否可以增加停用词来排除这些无效的分词从而提高查询的准确率。
停用词
配置停用词之后,es hanlp在分词时可以排除掉一下无用或者无业务意义的词从而提高查询效率,停用词路径 ES_HOME/plugins/analysis-hanlp/data/dictionary
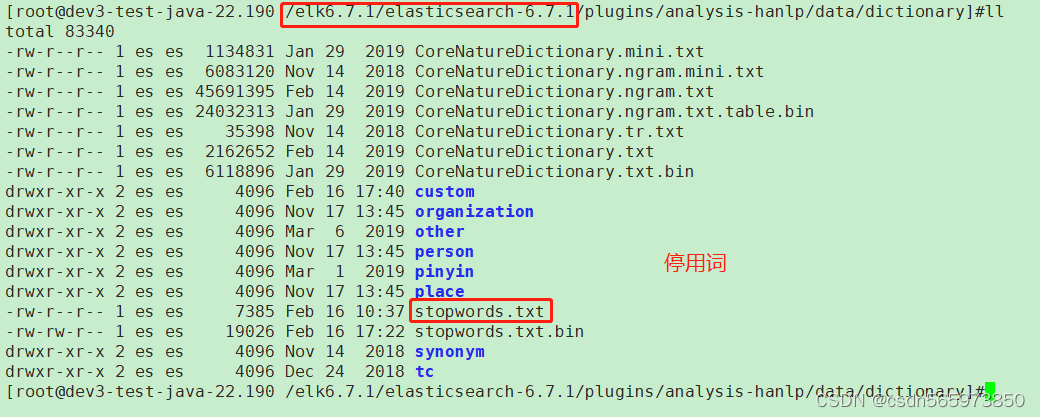
这里需要注意的是停用词没有自动加载功能,因此也需要提前准备好停用词内容按正确的格式写入stopwords.txt文件中,同时删除文件stopwords.txt.bin,然后启动es。
hanlp分词方式
es hanlp插件提供的分词方式有以下几种,但是需要注意的是不同版本的es hanlp插件对hanlp分词方式的适应性也不同,有的版本可能不是完全支持es hanlp插件下列的分词方式
hanlp: hanlp默认分词
hanlp_standard: 标准分词
hanlp_index: 索引分词
hanlp_nlp: NLP分词
hanlp_crf: CRF分词
hanlp_n_short: N-最短路分词
hanlp_dijkstra: 最短路分词
hanlp_speed: 极速词典分词自定义分词配置
这里为什么想到要自定义分词配置呢,文章开始已经说了,有些单词是没有业务意义,甚至是没有任何含义的,完全没有存在的必要,因此需要使用停用词,但是停用词默认的hanlp分词方式并不支持,正如文章开始看到的效果一样,因此需要通过自定义分词配置的方式来开启停用词。
hanlp的分词配置主要有
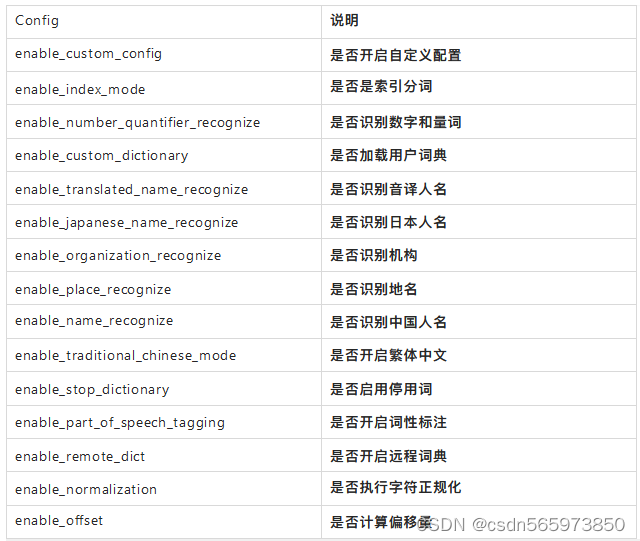
需要注意的是,以上的自定义分词属性不是每个版本都支持的,在使用时建议测试一下你当前的 hanlp版本是否支持后再使用该属性。
如果要采用如上配置配置自定义分词,需要设置 enable_custom_config 为 true
自定义分词
下面我们来自定义一个分词,并且开启停用词
shell
PUT test
{
"settings": {
"analysis": {
"analyzer": {
"hanlp_dongao": {
"tokenizer": "hanlp_analyzer"
}
},
"tokenizer": {
"hanlp_analyzer": {
"type": "hanlp",
"enable_stop_dictionary": true,
"enable_custom_config":true
}
}
}
}
}返回创建成功结果
shell
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "test"
}输入测试语句测试,首先看一下未使用自定义分词的效果
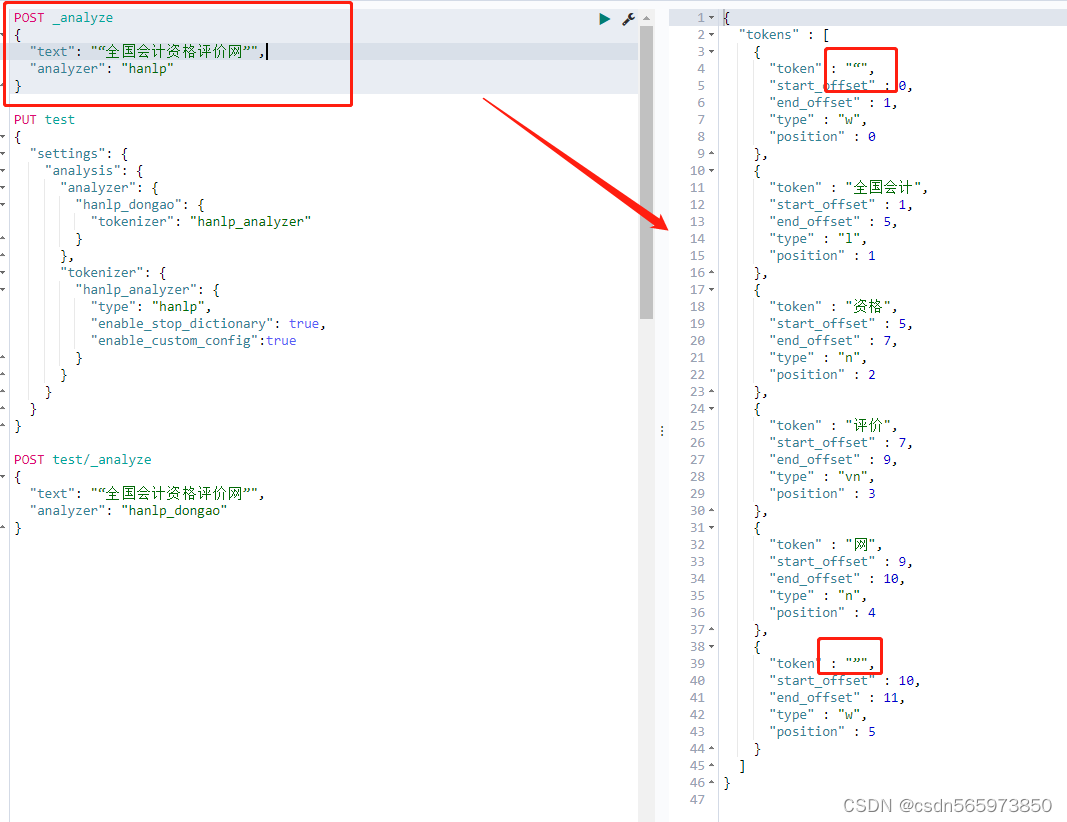
再看一下使用自定义分词之后的效果

可以看到双引号已经被停用了,不会再出现在分词结果里,自定义分词语句
shell
PUT test
{
"settings": {
"analysis": {
"analyzer": {
"hanlp_dongao": {
"tokenizer": "hanlp_analyzer"
}
},
"tokenizer": {
"hanlp_analyzer": {
"type": "hanlp",
"enable_stop_dictionary": true,
"enable_custom_config":true
}
}
}
}
}测试语句
shell
POST test/_analyze
{
"text": ""全国会计资格评价网"",
"analyzer": "hanlp_dongao"
}以上就完成了自定义分词的配置,这里需要注意的是在上一篇博文: https://blog.csdn.net/csdn565973850/article/details/139492520 中出现的自定义词典1分钟后词典自动加载仍然没有生效的情况,通过自定义分词的方式也可以得到解决,大家有兴趣的可以自行测试一下。