一、流程图
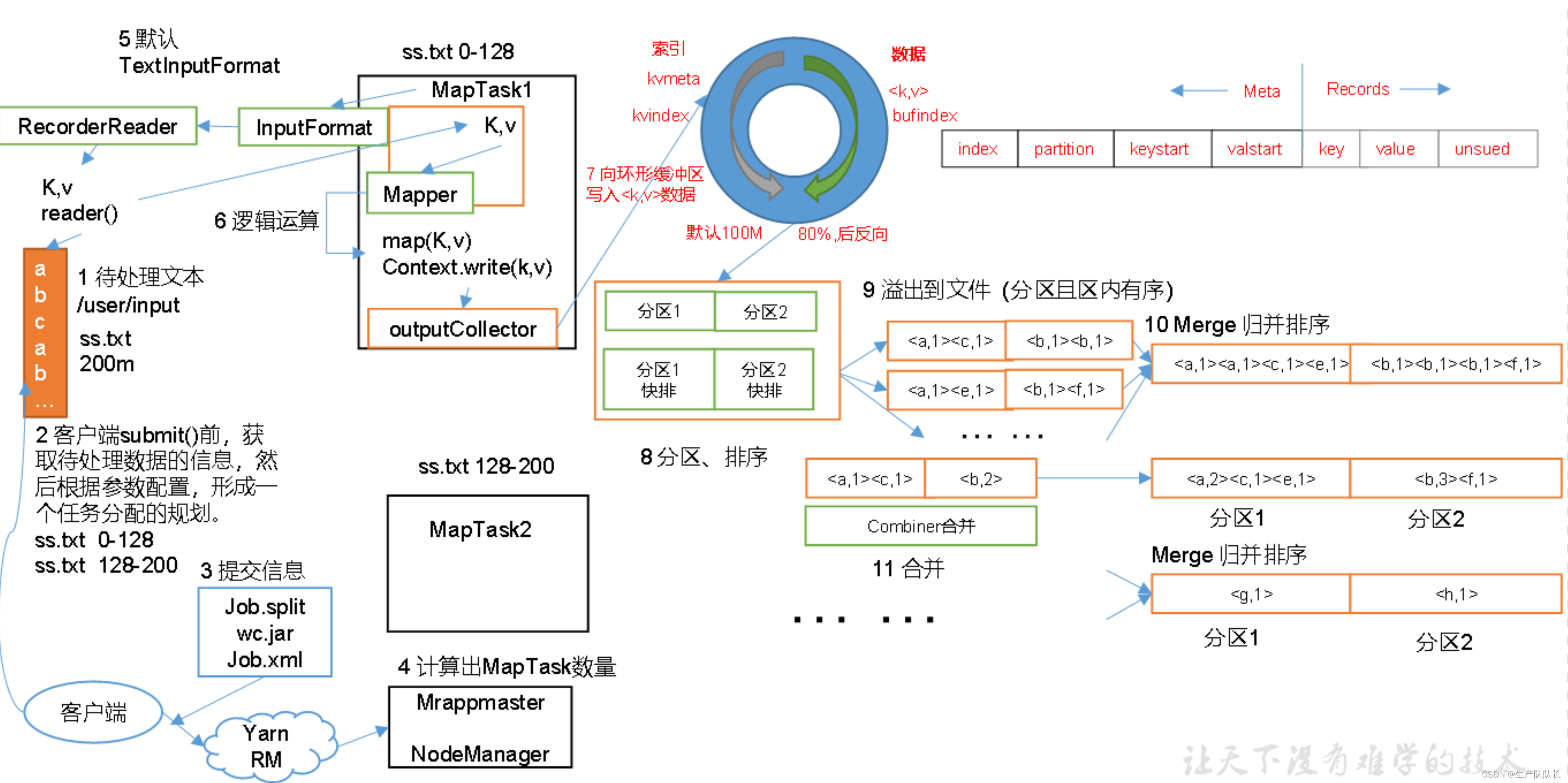
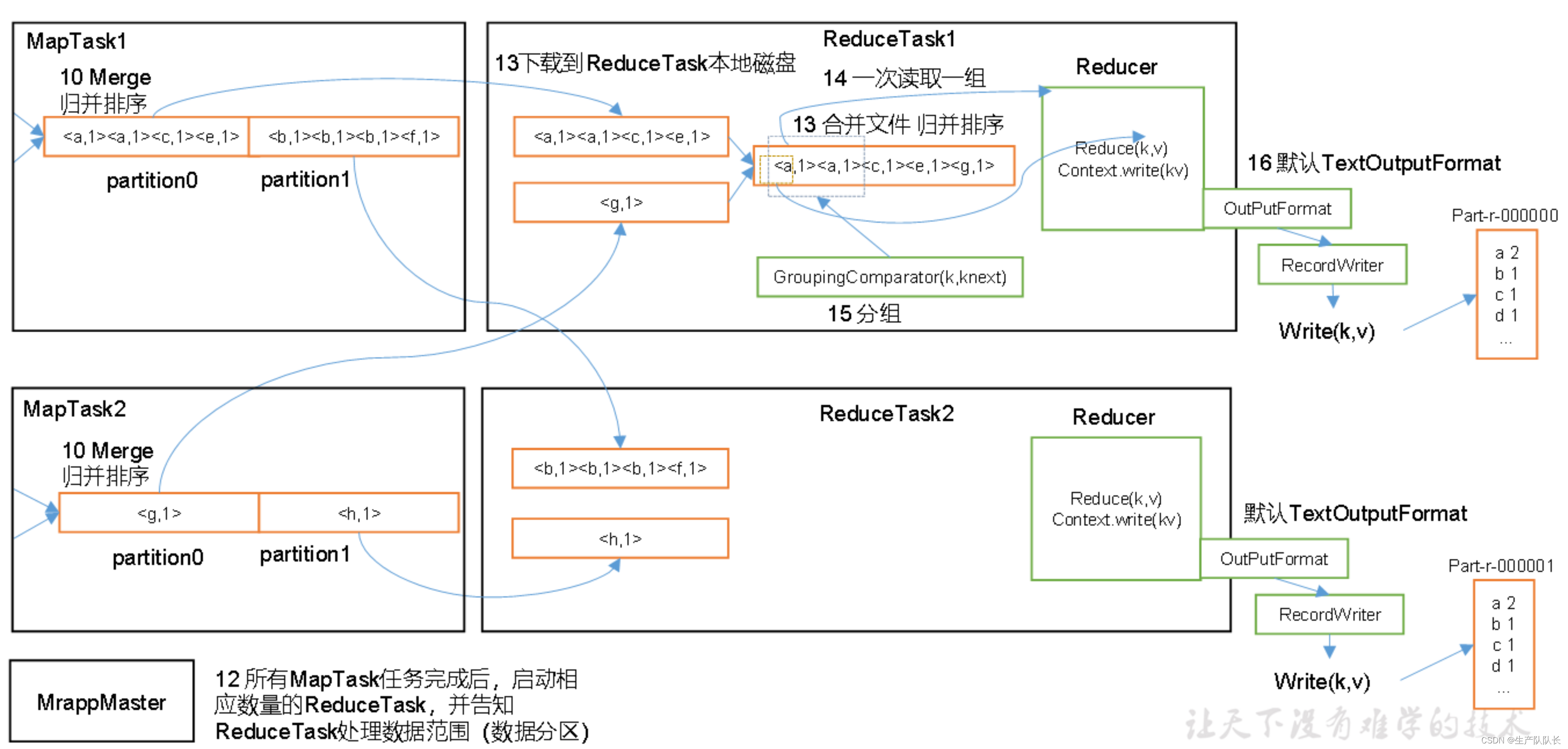
二、流程说明
上面的流程是整个MapReduce最全工作流程,但是Shuffle过程只是从第7步开始到第16步结束,具体Shuffle过程详解,如下:
(1)MapTask收集我们的map()方法输出的kv对,放到内存缓冲区中
(2)从内存缓冲区不断溢出本地磁盘文件,可能会溢出多个文件
(3)多个溢出文件会被合并成大的溢出文件
(4)在溢出过程及合并的过程中,都要调用Partitioner进行分区和针对key进行排序
(5)ReduceTask根据自己的分区号,去各个MapTask机器上取相应的结果分区数据
(6)ReduceTask会抓取到同一个分区的来自不同MapTask的结果文件,ReduceTask会将这些文件再进行合并(归并排序)
(7)合并成大文件后,Shuffle的过程也就结束了,后面进入ReduceTask的逻辑运算过程(从文件中取出一个一个的键值对Group,调用用户自定义的reduce()方法)
注意:
(1)Shuffle中的缓冲区大小会影响到MapReduce程序的执行效率,原则上说,缓冲区越大,磁盘io的次数越少,执行速度就越快。
(2)缓冲区的大小可以通过参数调整,参数:mapreduce.task.io.sort.mb默认100M。
mapred-default.xml
xml
<property>
<name>mapreduce.task.io.sort.mb</name>
<value>100</value>
<description>The total amount of buffer memory to use while sorting
files, in megabytes. By default, gives each merge stream 1MB, which
should minimize seeks.</description>
</property>三、注意点
1、对于第3步,提交信息,如果是Local本地模式,则不会提交wc.jar
2、第7步的环形缓冲区,在80%后,反向写入。
怎么理解反向写入?为什么要反向写入?
达到80%后,从尾部向头部写入,为了提高性能,这样做后,就可以同时将内存的数据写入到磁盘分区中,从头部开始写入到磁盘,从尾部写入到缓冲区,可以并发进行。当然,如果写入速度,大于写出速度,则依然会等待写出完,在进行写入。
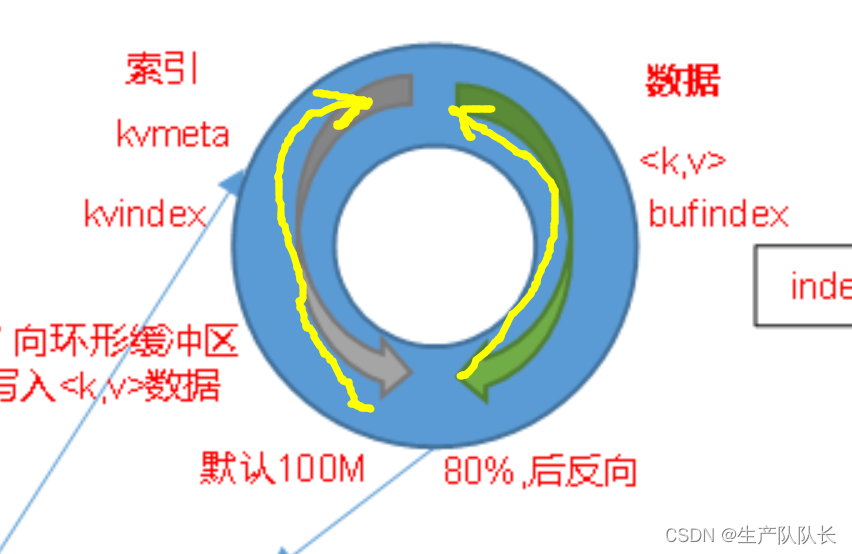
3、第8步的分区内排序,采用的是快速排序算法,排序对象是环形缓冲区的索引排序。这样,效率更高。此时排序的数据依然在内存中。
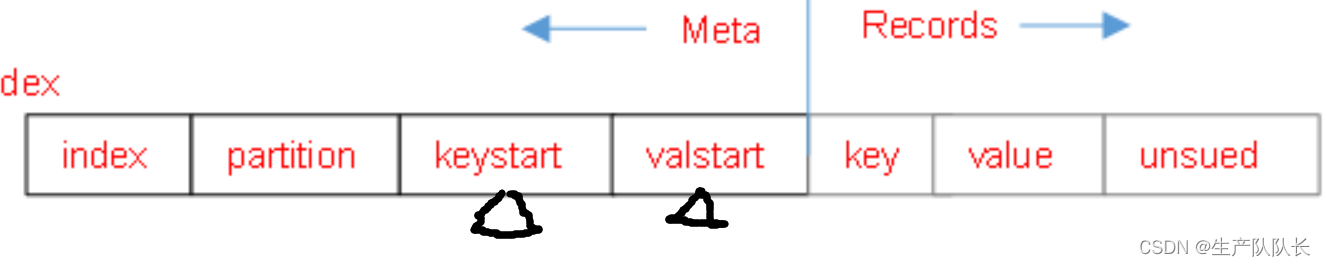
4、第10步的分区合并,采用的是归并排序,此时,数据已经写入磁盘。
5、第12步的ReduceTask不一定需要等到所有的MapTask结束再开始。ReduceTask会主动去MapTask里拉取自己负责的分区数据,进行归并排序处理。
一个ReduceTask会生成一个结果文件,我们之前的WC案例中,没有设定ReduceTask数量,默认是1,所以,生成的结果文件就是1个。