本篇内容为发表在Nature Methods上的scGPT的部分实验内容
来自:scGPT: toward building a foundation model for single-cell multi-omics using generative AI, Nature Methods, 2024
目录
scGPT揭示特定细胞状态的基因网络
GRN的转录因子、辅因子、增强子和靶基因之间的相互作用介导了重要的生物学过程。现有的GRN推断方法通常依赖于静态基因表达的相关性或伪时间估计作为因果图的代理。scGPT通过基因表达的生成建模进行了优化,在其基因嵌入和注意图中隐式地编码了这种关系。因此,通过探测来自预训练或微调模型的scGPT嵌入和注意图,提出了GRN推理工作流程。基因嵌入构建了一个相似性网络,该网络在数据集级别上模拟基因-基因相互作用。注意图谱进一步捕获了不同细胞状态下独特的基因网络激活模式。
在这个研究中,作者验证了scGPT提取的gene网络,并讨论其在基因程序发现中的重要性。scGPT证明了其通过学习基因token嵌入对功能相关基因进行分组和区分功能不同基因的能力。在图5a中,作者使用来自预训练的scGPT模型的基因embedding,通过可视化人类白细胞抗原(HLA, human leukocyte antigen)蛋白的相似性网络进行了检查。在这种zero shot设置中,scGPT模型成功地突出了两个与已被明确表征的HLA类别相对应的簇:HLA I类和HLA II类基因。
这些类别编码抗原呈递蛋白,在免疫环境中发挥不同的作用。例如,HLA I类蛋白(由HLA- a、HLA- c和HLA- e等基因编码)被CD8+ T cells识别并介导细胞毒性作用,而HLA II类蛋白(由HLA- drb1、HLA- dra和HLA- dpa1编码)被CD4+ T cells识别并触发更广泛的辅助功能。

- 图5a:预训练scGPT推断的HLA基因网络
此外,作者在"immune human"数据集上对scGPT模型进行了微调,并探索了该数据集中存在的免疫细胞类型特有的CD基因网络。为了进行GRN分析,作者使用了与整合任务相同的微调策略。
预训练的scGPT模型成功地识别出编码T细胞活化的T3复合物(CD3E、CD3D和CD3G)以及编码B细胞信号传导的CD79A和CD79B,以及作为HLA-I类分子共受体的CD8A和CD8B(见图5b)。此外,微调后的scGPT模型突出了CD36和CD14之间的关联(见图5b)。
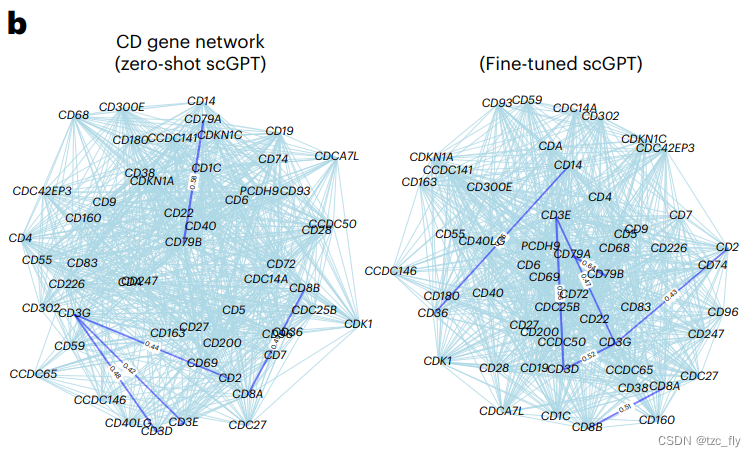
- 图5b:预训练scGPT和微调scGPT(immune human数据集)推断的CD基因网络
更多的GRN相关分析
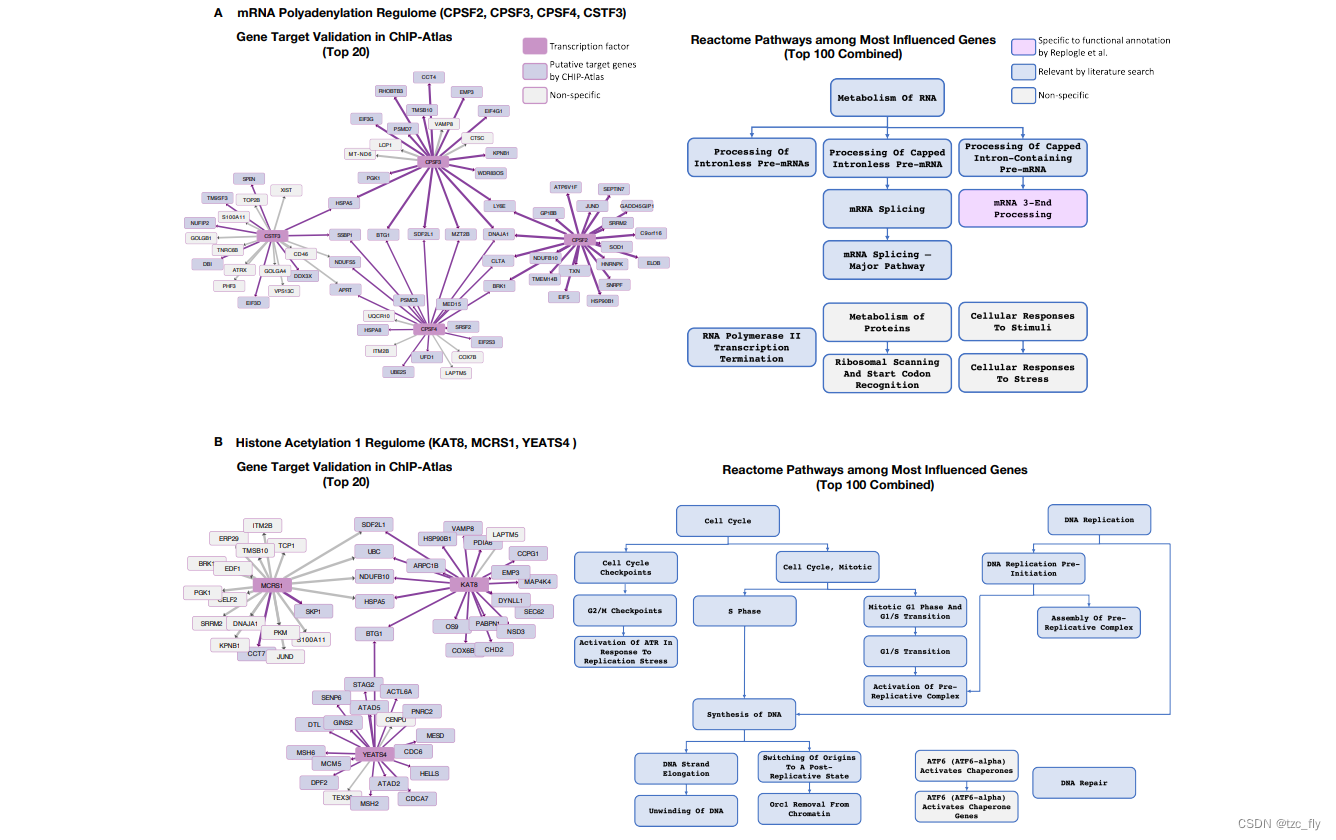
- 补充图9:scGPT基于注意力的基因调控网络(GRN)分析预测了与功能相关的转录因子在Replogle CRISPRi扰动数据集中的基因相互作用。
对于A,转录因子CPSF2、CPSF3、CPSF4和CSTF3参与mRNA多聚腺苷酸化调控的GRN分析。基因目标网络图展示了scGPT识别的每个转录因子的前20个最受影响基因。由CHIP-Atlas数据库验证的目标基因以紫色突出显示。边强度反映了来自scGPT的重要性评分。
通路图展示了这些转录因子中前100个最受影响基因在Reactome数据库中富集的功能通路分组。Replogle等人注释的特定术语(即mRNA多聚腺苷酸化)以紫色突出显示。通过文献搜索与这些转录因子或mRNA多聚腺苷酸化相关的术语以蓝色突出显示。非特异性通路以灰色着色。
对于B,转录因子KAT8、MCRS1和YEATS4参与组蛋白乙酰化调控的GRN分析。
缩放法则和迁移学习中的上下文效应
scGPT通过迁移学习方式的微调展示了巨大的潜力。作者进一步确认了使用基础模型的好处,将其与为每个下游任务从头开始训练的类似Transformer模型(表示为scGPT(from scratch))进行比较。其中经过微调的scGPT一致地显示了整合和细胞类型注释等任务的性能增益。考虑到基础模型对下游任务的贡献,作者进一步探索影响迁移学习过程的因素。
首先,作者深入探讨了预训练数据规模与微调模型性能之间的关系:对于某个分析任务,通过将进一步的测序数据添加到预训练图谱中,可以获得多大程度的改进?
作者预训练了一系列具有相同参数数量但使用不同数量数据的scGPT模型,从30,000到3300万个测序的正常人类细胞。补充图13展示了使用这些不同预训练模型进行各种应用的微调结果性能。观察到,随着预训练数据量的增加,微调模型的性能也有所提高。这些结果表明了一个规模效应,表明更大的预训练数据规模会导致更好的预训练嵌入和在下游任务中的性能改进。值得注意的是,该发现也与自然语言模型中报道的scaling law一致,突显了数据规模在模型性能中的重要作用。预训练数据规模在微调结果中的关键作用预示了单细胞领域预训练模型未来的前景。随着更大规模和更多样化的数据集的出现,我们可以期待模型性能的进一步提升,推动我们对细胞过程的理解。
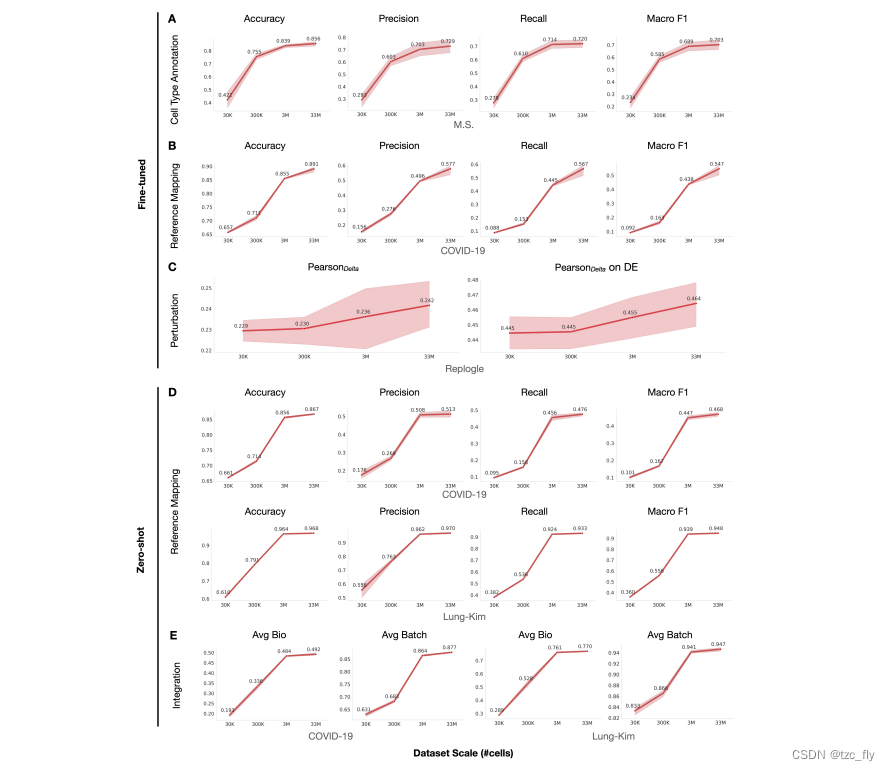
- 补充图13:预训练数据集大小对各种应用在微调和零样本设置中的影响。实验采用COVID-19、Lung-Kim、M.S.和Replogle数据集。测试集上的平均指标(n=5个随机训练验证分割)在每个预训练设置的每个任务中呈现。
作者探索的第二个因素是情境特定预训练的影响。这里,上下文使用是指在特定细胞类型上进行预训练,然后在类似细胞类型上对下游任务进行微调的scGPT模型。为了探索这一因素的影响,作者对来自单个主要器官的正常人类细胞进行了七个器官特异性模型的预训练(图1d),并对另一个泛癌细胞模型进行了预训练 (分别是两个模型 )。通过可视化预训练数据的细胞嵌入验证了预训练的有效性:泛癌症模型细胞嵌入准确地分离了不同的癌症类型(补充图2)。器官特异性模型能够揭示相应器官的细胞异质性(补充图3)。
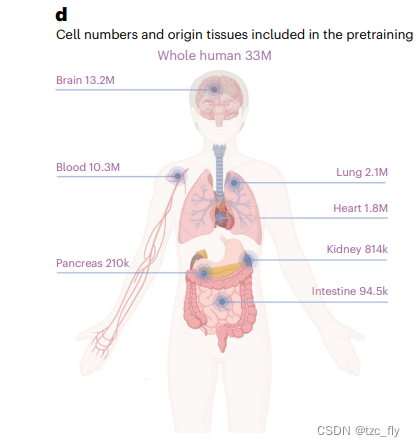
- 图1d:人体器官数据
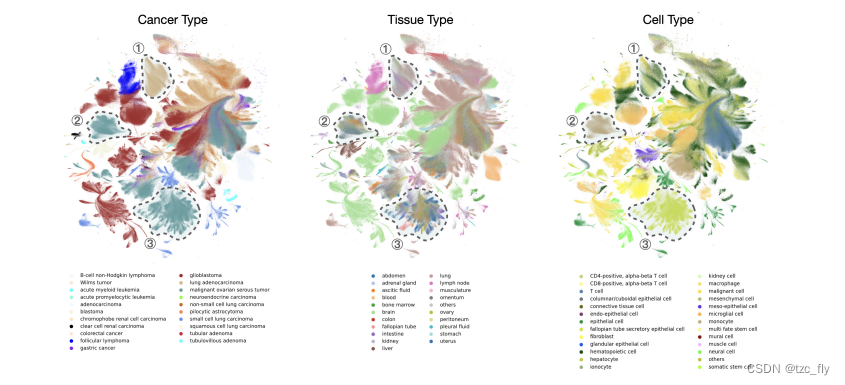
- 补充图2:使用预训练的全癌症模型生成的细胞嵌入的UMAP图,包括300万个癌细胞。从左到右,颜色表示癌症类型、组织类型和细胞类型。观察到,该模型能够生成细胞嵌入,主要展示了癌症和细胞类型的差异,以三个示例区域为例。
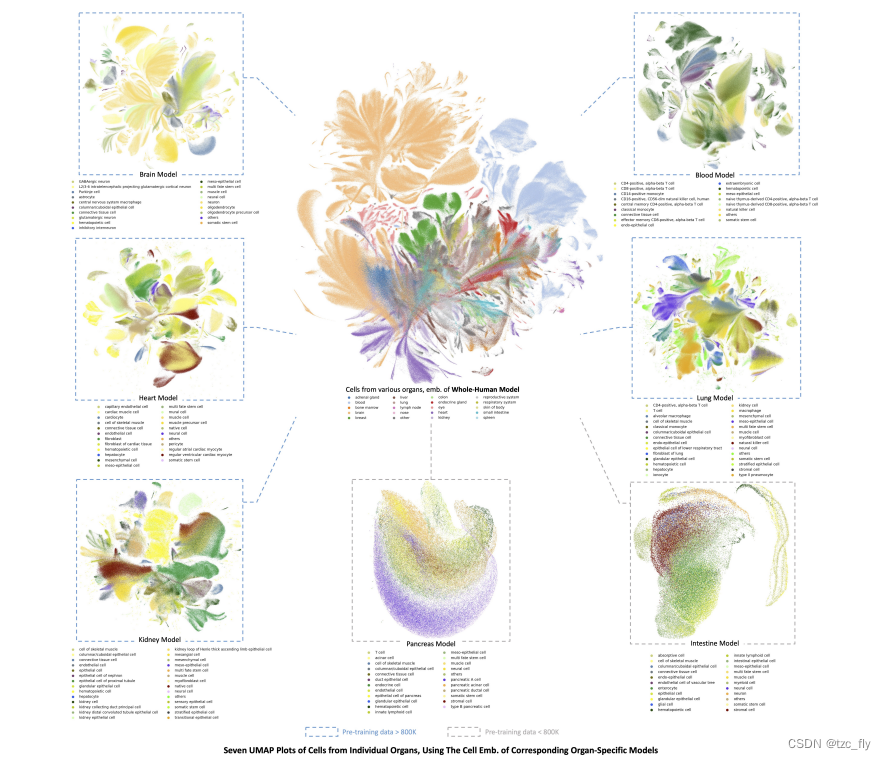
- 补充图3:器官特异性模型。(中心)使用来自预训练的scGPT全人类模型的细胞嵌入,对选定的300万个采集的正常人类细胞进行UMAP可视化。细胞按其来源器官着色。(周围)使用来自相应器官特异性模型的细胞嵌入对每个器官的细胞进行UMAP可视化。
每个图像中的颜色表示主要细胞类型。例如,左上方的UMAP可视化了来自专门预训练于脑细胞的scGPT模型的脑细胞嵌入。每个UMAP图的轮廓颜色表示器官特异性训练数据集的大小是否大于800,000个细胞(蓝色)或不是(灰色)。观察到,对于训练数据足够的模型(即,> 800,000个细胞),可以生成能够区分主要细胞类型的良好细胞嵌入。
接下来,作者在COVID-19数据集上微调模型,以检查预训练背景的影响。分析显示,在预训练中模型上下文的相关性与其随后整合数据的性能之间存在明显的相关性。在数据整合任务中表现最好的是在整个人体、血液和肺部数据集上进行预训练的模型,这些模型与COVID-19数据集中存在的细胞类型密切相关。值得注意的是,即使是大脑预训练模型,尽管在1300万个细胞的大量数据集上进行了训练,但与具有相似数据集大小的血液预训练模型相比,其性能也落后8%。这强调了将预训练中的细胞上下文与目标数据集对齐的重要性,以便在下游任务中获得更好的结果。
考虑到细胞上下文是必不可少的,因此整个人体预训练模型作为广泛应用的通用和可靠的选择而出现。