1. RabbitMQ简介
RabbitMQ是一个可靠、高效的开源消息代理服务器,基于AMQP协议。它具备以下特点:
- 可以支持多种消息协议,如AMQP、STOMP和MQTT等。
- 提供了持久化、可靠性和灵活的路由等功能。
- 支持消息的发布和订阅模式。
- 具备高可用性和可扩展性。
RabbiMQ的核心概念包括生产者、消费者、队列、交换机和绑定。生产者将消息发送到交换机,交换机根据其类型和绑定规则将消息路由到队列,然后消费者从队列中获取消息进行处理。
RabbitMQ相关概念
- Broker:接收和分发消息的应用,RabbitMQ Server就是Message Broker。
- Virtual host:出于多租户和安全因素的设计,把AMQP的基本组件划分到一个虚拟的分组中,类似于网络中的namespace概念,当多个不同的用户使用同一个RabbitMQ Server提供的服务时,可以划分出多个vhost,每个用户在自己的vhost创建exchange/queue等。
- Connection:publisher/consumer和broker之间的TCP连接。
- Channel:如果每一次访问RabbitMQ都建立一个Connection,在消息量大的时候建立TCP Connection的开销都将是巨大的,效率也是非常低的。Channel是在Connection内部建立的逻辑连接,如果应用程序支持多线程,通常每个thread会创建单独的Channel进行通信,AMQP的method包含了channel id帮助客户端和message broker识别channel,所以channel之间是完全隔离的。Channel作为轻量级的Connection,极大减少了操作系统建立TCP连接的开销。
相关术语
- producer:生产者,向队列中发送消息的程序。(在图表中通常使用P表示)
- queue:队列,用于存储消息,定义在RabbitMQ内部,queue本质上是一个消息缓存buffer,生产者可以往里发送消息,消费者也可以从里面获取消息。(在图表中通常使用Q表示)
- consumer:消费者,等待并从消息队列中获取消息的程序。(在图表中通常使用C表示)
- exchange:交换机,用于将producer发送来的消息发送到queue,事实上,producer是不能直接将message发送到queue,必须先发送到exchange,再由exchange发送到queue。
注:生产者和消费者可能在不同的程序或主机中,当然也有可能一个程序有可能既是生产者,也是消费者。
2. pika简介
在Python中,pika是一个用于处理RabbitMQ消息队列的第三方库,它允许开发者在Python应用程序中发送和接收消息,实现应用程序之间的异步通信。
主要功能
- 连接管理:pika提供了与RabbitMQ服务器建立连接的功能。
- 通道管理:通过连接,可以创建多个通道(channel),每个通道代表一个独立的通信流。
- 消息发送与接收:开发者可以使用pika发送消息到指定的队列(queue),并从队列中接收消息。
- 交换机与队列声明:支持声明交换机(exchange)、队列,以及它们之间的绑定(binding)关系。
- 消息确认:支持消息的自动确认(auto-ack)或手动确认(manual ack),以确保消息的可靠传递。
使用流程
- 创建连接:使用pika.BlockingConnection或pika.SelectConnection等类创建与RabbitMQ服务器的连接。
- 创建通道:通过连接对象的channel()方法创建通道。
- 声明交换机与队列:使用通道对象的exchange_declare()和queue_declare()方法声明交换机和队列。
- 绑定交换机与队列:使用通道对象的queue_bind()方法将队列绑定到交换机。
- 发送消息:使用通道对象的basic_publish()方法发送消息到指定的交换机和路由键(routing key)。
- 接收消息:使用通道对象的basic_consume()方法开始消费队列中的消息,并通过回调函数处理接收到的消息。
- 关闭连接:在不再需要时,使用连接对象的close()方法关闭连接。
安装pika
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pika
3. pika应用入门
3.1. 生产者
python
import pika
# 1.连接rabbit
credentials = pika.PlainCredentials('rabbit', '*****') # rabbit用户名和密码
connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.17.61',port = 5671,virtual_host = '/typc-fpd-dev',credentials = credentials))
channel = connection.channel()
# 2.创建持久化队列
# 注意:非持久化队列不能变持久化队列,反之也是这样的,所有创建队列中不能创建和非持久化队列重名的队列
channel.queue_declare(queue='hello_world', durable=True)
# 3.向指定队列插入数据
poiid = 'xxxxxx'
channel.basic_publish(exchange='', # 简单模式
routing_key='hello_world', # 指定队列
body=poiid, # 向队列中添加的数据
properties=pika.BasicProperties(
delivery_mode=2, # make message persistent
)
)
print(" [x] Sent 'Hello World!'") 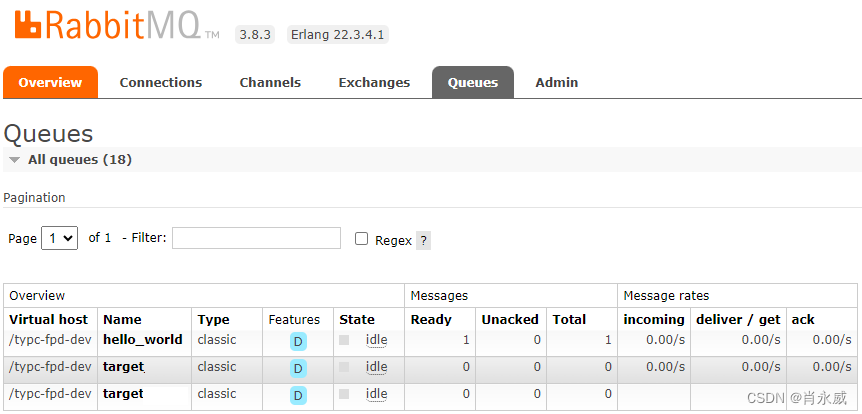
查看虚拟主机virtual-host: /typc-fpd-dev下队列hello_world。
3.2. 侦听消费者
python
import pika
# 1.连接rabbit
credentials = pika.PlainCredentials('rabbit', '*****') # rabbit用户名和密码
connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.17.61',port = 5671,virtual_host = '/typc-fpd-dev',credentials = credentials))
# 2.创建持久化队列
# 注意:非持久化队列不能变持久化队列,反之也是这样的,所有创建队列中不能创建和非持久化队列重名的队列
# 注意:这一步不是必须的,但是如果消费者先启动而不是生成者先启动时,这时队列中还没有hello_world队列,这时就会报错
channel.queue_declare(queue='hello_world', durable=True)
# 3.确定回调函数
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
# 手动应答
poiid = body.decode('utf-8') # 将 bytes 转换为字符串
Core.setPIO(poiid) # 输入数据
Core.task_process() # 处理数据
ch.basic_ack(delivery_tag=method.delivery_tag)
# 4.确定监听队列参数
channel.basic_consume(queue='hello_world', # 指定队列
auto_ack=False, # 手动应答方式
on_message_callback=callback)
print(' [*] Waiting for messages. To exit press CTRL+C')
# 5.正式监听
channel.start_consuming()3.3. 主动处理消费消息
在Pika中,basic_get方法确实可以用于从队列中直接获取消息,但通常不推荐在生产环境中使用,因为它不是高效的消息处理方式。不过,如果你确实需要这种方法,以下是如何使用basic_get的示例:
python
# 1.连接rabbit
credentials = pika.PlainCredentials('rabbit', '*****') # rabbit用户名和密码
connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.17.61',port = 5671,virtual_host = '/typc-fpd-dev',credentials = credentials))
channel = connection.channel()
time.sleep(1)
# 2.创建持久化队列
# 注意:非持久化队列不能变持久化队列,反之也是这样的,所有创建队列中不能创建和非持久化队列重名的队列
# 注意:这一步不是必须的,但是如果消费者先启动而不是生成者先启动时,这时队列中还没有hello2队列,这时就会报错
channel.queue_declare(queue='hello_world', durable=True)
count = 5
for i in range(count):
print('取消息开始时间')
method_frame, header_frame, body = channel.basic_get(queue='hello_world', auto_ack=False)
if method_frame:
# 处理消息体
print('body:',body)
poiid = body.decode('utf-8') # 将 bytes 转换为字符串
Core.setPIO(poiid)
Core.task_process()
time.sleep(2)
# 如果你设置了auto_ack=False,则需要手动确认消息
channel.basic_ack(delivery_tag=method_frame.delivery_tag)
else:
print("没有消息可以获取,", str(i))
time.sleep(1)
print('取消息完成时间')
connection.close()#来关闭连接 参考:
三只松鼠. python 操作RabbitMq详解. 博客园. 2019.03
卫玠_juncheng. Python三方库:Pika(RabbitMQ基础使用). CSDN博客. 2024.03