1、索引概述
索引用于帮助快速过滤或搜索数据 。目前,Doris支持两种类型的索引:内置智能索引 和用户创建的二级索引。
内置智能索引
排序键和前缀索引:Apache Doris基于排序键以有序的方式存储数据。它为每1024行数据创建一个前缀索引。索引中的键是当前1024行组的第一行中已排序列的值。如果查询涉及排序的列,系统将找到相关的1024行组的第一行,并从那里开始扫描。ZoneMap索引:ZoneMap索引以基于列的存储格式自动维护每列的索引信息,包括Min/Max值等 。这种类型的索引对用户是透明的。它们是段级索引和页级索引,记录页内每列的最大值和最小值,还记录段内每列的最大值和最小值。因此,在等价查询和范围查询中,可以使用Min/Max索引来缩小过滤范围。
用户创建二级索引
- 布隆过滤器索引
- N-Gram Bloom Filter Index
- 位图索引
- 倒排索引
2、排序键和前缀索引
Doris将数据存储在类似于SSTable (Sorted String Table)的数据结构中,这是一种有序的数据结构,可以按照指定的列对数据进行排序和存储。在这种数据结构中,基于排序的列执行查询是非常高效的。
在Aggregate、Unique和Duplicate这三种数据模型中,底层数据存储根据各自表创建语句的AGGREGATE KEY , UNIQUE KEY , 和 DUPLICATE KEY 中指定的列进行排序和存储。这些键被称为排序键。在Sort Keys的帮助下,Doris可以在查询时通过在排序的列上指定条件来快速找到要处理的数据,从而降低了搜索的复杂性,从而加快了查询的速度,而无需扫描整个表。
在排序键的基础上,引入了前缀索引。前缀索引是一种稀疏索引 。在表中,根据相应的行数形成一个逻辑数据块。每个逻辑数据块在前缀索引表中存储一个索引项 。索引表项的长度不超过36字节,其内容是由数据块中第一行数据的排序列组成的前缀。在搜索Prefix Index表时,它可以帮助确定行数据所在的逻辑数据块的起始行号。由于Prefix Index相对较小,因此可以将其完全缓存在内存中,从而实现快速的数据块本地化,并显著提高查询效率。
数据块中一行数据的前36个字节作为该行的前缀索引。当遇到
VARCHAR类型时,前缀索引将被直接截断。如果第一列是VARCHAR类型,即使长度没有达到36字节,也会发生截断。
2.1 例子
- 如果表的排序键如下:5列,则前缀索引为:user_id(8字节),age(4字节),message(前缀20字节)。
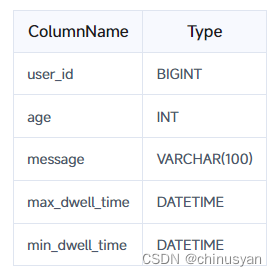
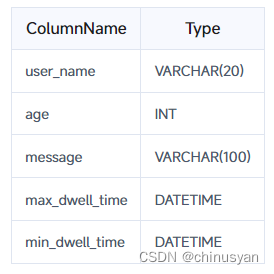
- 如果表的排序键由5列组成,并且第一列是
VARCHAR类型的user_name ,那么前缀索引将是user_name(截断为20字节)。即使前缀索引的总大小没有达到36字节,也会发生截断,因为它遇到一个VARCHAR列,并且不包括其他列 。
- 当我们的查询条件匹配前缀索引时,可以大大加快查询速度。例如,在第一种情况下,执行以下查询:
sql
SELECT * FROM table WHERE user_id=1829239 and age=20;该查询的效率将远远高于以下查询:
sql
SELECT * FROM table WHERE age=20;因此,在创建表时,选择正确的列顺序可以大大提高查询效率。
2.2 多个前缀索引
由于在表创建过程中指定了列顺序,因此表通常只有一种类型的前缀索引 。这可能不满足使用其他列作为条件的查询的效率要求,因为这些列没有命中前缀索引。在这种情况下,可以通过创建具有调整列顺序的单个表的对应的强一致性物化视图来间接实现多个前缀索引 。有关详细信息,请参阅物化视图。
3、BloomFilter 索引
BloomFilter是Bloom于1970年提出的多哈希函数映射的快速搜索算法。通常用于一些需要快速确定某个元素是否属于一个集合,但不严格要求100%正确的场合 ,BloomFilter具有以下特点:
- 一种高空间效率的概率数据结构,用于检查元素是否在集合中。
- 对于检测元素是否存在的调用,BloomFilter将告诉调用者两种结果中的一种:
它可能存在或者它一定不存在。 - 缺点是有一个误判,告诉你它可能存在,不一定是真的。
布隆过滤器实际上是由一个极长的二进制位数组和一系列哈希函数组成的。二进制位数组一开始都是0。当给定要查询的元素时,将通过一系列哈希函数计算该元素以映射出一系列值,并且所有值在位数组的偏移量中都被视为1。
下图显示了m=18, k=3的Bloom Filter示例(m是Bit数组的大小,k是Hash函数的数量)。集合中的x、y和z三个元素通过三个不同的散列函数散列到位数组中。查询元素w时,经过哈希函数计算,因为有一位是0,所以w不在集合中。
类似地,如果一个元素经过哈希函数计算以获得其所有偏移位置,并且如果所有这些位置都设置为1,则确定该元素可能在集合中。
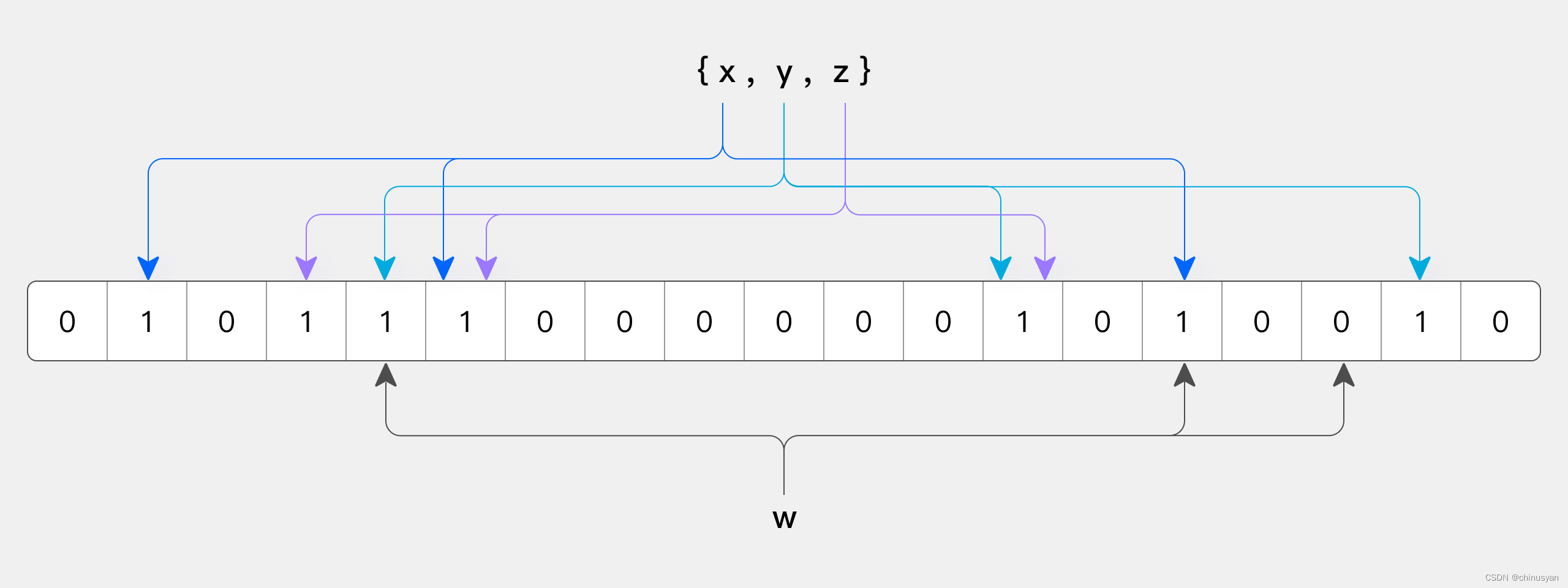
布隆过滤器是一种数据结构,允许对存储在每个数据块中的数据进行反向测试 。当请求特定的行时,Bloom Filter首先检查该行是否不在数据块中。布隆过滤器要么自信地声明该行不存在,要么给出一个不确定的答案。这种不确定性就是为什么它被称为反向测试。然而,布隆过滤器并非没有成本。存储这个额外的索引级别会消耗额外的空间,并且Bloom Filters会随着索引数据的增长而增长。
在Doris中,可以在表创建期间或通过ALTER表操作指定BloomFilter索引。从本质上讲,布隆过滤器是一个位图结构,用于快速确定给定值是否在集合中。这种测定可能导致小概率的假阳性。也就是说,如果返回false,则该值肯定不在集合中。但如果它返回true,则该值可能在集合中。
Doris中的BloomFilter索引是在块级别创建的。在每个Block中,指定列的值被视为一个集合,以生成BloomFilter索引条目。在查询过程中使用此条目来快速过滤掉不符合条件的数据。
现在让我们通过一个例子来看看Doris是如何创建BloomFilter索引的。
3.1 创建BloomFilter索引
Doris BloomFilter索引是通过在表构建语句的PROPERTIES 中添加"bloom_filter_columns"="k1,k2,k3"来创建的,这个属性k1,k2,k3是您想要创建的BloomFilter索引的关键列名称,例如,我们为表中的saler_id和category_id创建BloomFilter索引。
sql
CREATE TABLE IF NOT EXISTS sale_detail_bloom (
sale_date date NOT NULL COMMENT "Sales time",
customer_id int NOT NULL COMMENT "Customer ID",
saler_id int NOT NULL COMMENT "Salesperson",
sku_id int NOT NULL COMMENT "Product ID",
category_id int NOT NULL COMMENT "Product Category",
sale_count int NOT NULL COMMENT "Sales Quantity",
sale_price DECIMAL(12,2) NOT NULL COMMENT "unit price",
sale_amt DECIMAL(20,2) COMMENT "Total sales amount"
)
Duplicate KEY(sale_date, customer_id,saler_id,sku_id,category_id)
PARTITION BY RANGE(sale_date)
(
PARTITION P_202111 VALUES [('2021-11-01'), ('2021-12-01'))
)
DISTRIBUTED BY HASH(saler_id) BUCKETS 10
PROPERTIES (
"replication_num" = "3",
"bloom_filter_columns"="saler_id,category_id",
"dynamic_partition.enable" = "true",
"dynamic_partition.time_unit" = "MONTH",
"dynamic_partition.time_zone" = "Asia/Shanghai",
"dynamic_partition.start" = "-2147483648",
"dynamic_partition.end" = "2",
"dynamic_partition.prefix" = "P_",
"dynamic_partition.replication_num" = "3",
"dynamic_partition.buckets" = "3"
);3.2 查看BloomFilter索引
检查我们在表上建立的BloomFilter索引是否要使用:
sql
SHOW CREATE TABLE <table_name>;3.3 删除BloomFilter索引
删除索引就是从bloom_filter_columns属性中删除索引列:
sql
ALTER TABLE <db.table_name> SET ("bloom_filter_columns" = "");3.4 修改BloomFilter索引
修改索引就是修改表的bloom_filter_columns属性:
sql
ALTER TABLE <db.table_name> SET ("bloom_filter_columns" = "k1,k3");3.5 BloomFilter使用场景
当满足以下条件时,用户可以为列创建BloomFilter索引:
- BloomFilter适用于非前缀过滤。
- 查询将根据列的高频率进行过滤,大多数查询条件都在
in和=中过滤。 - BloomFilter适用于高基数列 。例如UserID。因为如果它是在低基数列(比如
gender列)上创建的,那么每个Block将几乎包含所有值,从而导致BloomFilter索引失去其意义。
3.6 BloomFilter使用注意事项
- 它不支持为
Tinyint、Float和Double列创建BloomFilter索引。 - BloomFilter索引只对
in和=过滤查询有加速作用。 - 如果您想检查查询是否命中BloomFilter索引,您可以检查查询的配置文件信息。
4、N-Gram BloomFilter索引
为了提高like 查询的性能,实现了N-Gram BloomFilter索引。
从Doris 2.0版本开始支持N-Gram BloomFilter索引。
4.1 创建N-Gram BloomFilter索引
在创建表期间:
sql
CREATE TABLE `table3` (
`siteid` int(11) NULL DEFAULT "10" COMMENT "",
`citycode` smallint(6) NULL COMMENT "",
`username` varchar(100) NULL DEFAULT "" COMMENT "",
INDEX idx_ngrambf (`username`) USING NGRAM_BF PROPERTIES("gram_size"="3", "bf_size"="256") COMMENT 'username ngram_bf index'
) ENGINE=OLAP
AGGREGATE KEY(`siteid`, `citycode`, `username`) COMMENT "OLAP"
DISTRIBUTED BY HASH(`siteid`) BUCKETS 10
PROPERTIES (
"replication_num" = "1"
);- PROPERTIES("gram_size"="3", "bf_size"="1024"),分别表示布隆过滤器的gram 数和字节数。
- gram 数与实际查询场景有关,通常设置为大多数查询字符串的长度。Bloom Filter的字节大小可以通过测试确定,通常大小越大过滤效果越好。您可以从256字节开始进行验证测试,以查看结果。但是,较大的字节大小也会增加索引的存储和内存成本。
- 如果数据基数相对较高,则不需要将字节大小设置得太大。如果基数不是很高,可以通过增加字节大小来改善过滤效果
4.2 显示N-Gram BloomFilter索引
sql
show index from example_db.table3;4.3 删除N-Gram BloomFilter索引
sql
alter table example_db.table3 drop index idx_ngrambf;4.4 修改N-Gram BloomFilter索引
为旧列添加N-Gram BloomFilter索引:
sql
alter table example_db.table3 add index idx_ngrambf(username) using NGRAM_BF PROPERTIES("gram_size"="3", "bf_size"="512")comment 'username ngram_bf index' 4.5 关于Doris NGram BloomFilter的一些注意
- NGram BloomFilter只支持CHAR/VARCHAR/String列
- NGram BloomFilter索引和BloomFilter索引在同一列上应该是互斥的
- BloomFilter的 gram 数和字节可以调整和优化。比如如果gram太小,你可以增加BloomFilter的字节数。
- 要查找是否使用NGram BloomFilter索引的查询,可以检查查询配置文件。
5、位图索引
位图索引是由位图表示的索引,其中为列中的每个键值创建位图。与其他索引相比,它占用很少的存储空间,并且创建和使用非常快 。然而,它有一个缺点,即修改操作的锁粒度太大,不适合频繁更新。

5.1 适用的场景
- 重复值高的列,建议在100 ~ 100,000之间,如occupation、city等。如果重复次数过高,则与其他类型的指标相比没有明显的优势;如果重复过低,空间效率和性能将大大降低。
- 特定类型的查询,如
count,or,and只需要位操作的逻辑操作。例如:多个条件组合查询,select count(*) from table where city = 'Nanjing' and job = 'Doctor' and phonetype = 'iphone' and gender = 'Male'.如果在每个查询条件列上建立位图索引,则数据库可以执行高效的位操作,准确定位所需的数据,减少磁盘IO,并且过滤的结果集越小,位图索引的优势越明显。 - 适用于特别查询、多维分析和其他分析场景。如果一个表有100列,用户使用其中的20列作为查询条件(任意使用这20列中的几列),那么在这些列上创建20个位图索引将允许所有查询使用这些索引。
不适用的场景
- 低重复值的列,如身份证、电话号码等
- 重复次数过高的列,如性别。虽然可以建立位图索引,但不建议将它们单独用作查询条件。建议与其他条件一起过滤。
- 经常需要更新的列。
创建位图索引
在名为table_name的表的siteid列上创建位图索引index_name。
sql
CREATE INDEX [IF NOT EXISTS] index_name ON table1 (siteid) USING BITMAP;5.2 查看位图索引
显示指定table_name下的索引:
sql
SHOW INDEX FROM table_name;删除索引
删除指定table_name 下名为index_name的索引。
sql
DROP INDEX [IF EXISTS] index_name ON table_name;说明
- 位图索引只能在单列上创建。
- 位图索引可以应用于Duplicate和Uniq数据模型中的所有列,以及Aggregate模型中的关键列。
- 位图索引支持的数据类型如下:
- TINYINT
- SMALLINT
- INT
- BIGINT
- CHAR
- VARCHAR
- DATE
- DATETIME
- LARGEINT
- DECIMAL
- BOOL
6、倒排索引
从2.0版本开始,Doris实现了倒排索引,以支持文本字段上的全文搜索,文本,数字,日期时间字段上的正常eq和范围过滤器。本文档介绍了反向索引的用法,包括创建、删除和查询。
6.1 术语
倒排索引是信息检索中常用的一种索引技术。它将文本拆分为词项,并构造一个词项以建立文档索引。这种索引称为倒排索引,可用于查找出现特定术语的文档。
6.2 基本原则
在Doris的倒排索引中,表中的一行对应CLucene中的一个doc,列对应doc中的一个字段 。因此,通过使用倒排索引,doris可以获得满足SQL WHERE子句过滤条件的行,然后无需读取其他不相关的行即可快速获得这些行。
Doris使用单独的文件来存储倒排索引。它在逻辑上与段文件相关,但彼此隔离。优点是,创建和删除倒排索引不需要重写tablet 和段文件,这是非常繁重的工作。
6.3 特点
倒排索引的特点如下:
- 添加全文搜索文本(string, varchar, char)字段
MATCH_ALL匹配所有关键字,MATCH_ANY匹配任何关键字- 支持短语查询
MATCH_PHRASE - 支持短语+前缀
MATCH_PHRASE_PREFIX - 支持正则表达式查询
MATCH_REGEXP - 支持文本字段数组上的全文
- 支持英文,中文和混合unicode单词解析器
- 加速普通等值、范围查询,可代替 Bitmap 索引
- 在文本、数字和日期时间类型上支持
=,!=,>,>=,<,<= - 支持
=,!=,>,>=,<,<=对文本,数字,日期时间类型的数组
- 在文本、数字和日期时间类型上支持
- 完全支持逻辑组合
- 新增索引对
ORNOT逻辑的下推 - 支持AND、OR、
NOT的组合
- 新增索引对
- 灵活和快速的索引管理
- 支持在创建表时定义倒排索引
- 支持在已存在的表上添加倒排索引,无需重写数据
- 支持在已存在的表上删除倒排索引,无需重写数据
6.4 语法
表创建时的倒排索引定义语法如下
USING INVERTED是必选的,它指定索引类型为倒排索引PROPERTIES是可选的,它允许用户为索引指定额外的属性。目前,有三种类型的属性可用。-
parser 用于设置tokenizer/parser的类型
- 缺失表示没有解析器,整个字段被认为是一个术语
english代表英语解析器chinese代表中文解析器unicode代表多语言混合分词,适用于中英文混合的情况。可以对邮件的前缀后缀、IP地址、混合字符和数字进行分段,也可以对中文字符进行逐字分段。
-
parser_mode 用于设置中文分词的分词器/解析器(tokenizer/parser)类型
- 在
fine_grained("细粒度")模式下,系统倾向于生成简短的单词,例如:比如 '武汉市长江大桥' 会分成 '武汉', '武汉市', '市长', '长江', '长江大桥', '大桥' 6 个词 - 在
coarse_grained( "粗粒度")模式下,系统倾向于生成长单词,比如 '武汉市长江大桥' 会分成 '武汉市' '长江大桥' 2 个词 - 默认模式为
coarse_grained("粗粒度")。
- 在
-
support_phrase 用于指定索引是否需要支持短语模式查询
MATCH_PHRASEtrue表示需要支持,但需要更多存储空间用于索引。false表示不需要支持,索引存储空间较小。MATCH_ALL可用于无顺序匹配多个单词。- 默认模式为
false
-
char_filter:主要功能是在分词前对字符串进行预处理
char_filter_type:指定不同功能的char_filters(目前只支持char_replace)char_replace:用替换中的字符替换模式中的每个字符char_filter_pattern:要替换的字符数组,char_filter_replacement:替换的字符数组,可以不设置,默认为空格字符
-
ignore_above:控制字符串是否被索引。
- 大于ignore_above设置的字符串将不会被索引。对于字符串数组,ignore_above将分别应用于每个数组元素,并且长度大于ignore_above的字符串元素将不会被索引。
- 缺省值是256字节
-
ower_case:是否将令牌转换为小写,从而实现不区分大小写的匹配。
true:转换为小写false:不转换为小写
-
COMMENT是可选的
sql
CREATE TABLE table_name
(
columns_difinition,
INDEX idx_name1(column_name1) USING INVERTED [PROPERTIES("parser" = "english|chinese|unicode")] [COMMENT 'your comment']
INDEX idx_name2(column_name2) USING INVERTED [PROPERTIES("parser" = "english|chinese|unicode")] [COMMENT 'your comment']
INDEX idx_name3(column_name3) USING INVERTED [PROPERTIES("parser" = "chinese", "parser_mode" = "fine_grained|coarse_grained")] [COMMENT 'your comment']
INDEX idx_name4(column_name4) USING INVERTED [PROPERTIES("parser" = "english|chinese|unicode", "support_phrase" = "true|false")] [COMMENT 'your comment']
INDEX idx_name5(column_name4) USING INVERTED [PROPERTIES("char_filter_type" = "char_replace", "char_filter_pattern" = "._"), "char_filter_replacement" = " "] [COMMENT 'your comment']
INDEX idx_name5(column_name4) USING INVERTED [PROPERTIES("char_filter_type" = "char_replace", "char_filter_pattern" = "._")] [COMMENT 'your comment']
)
table_properties;在不同的数据模型中,倒排索引有不同的限制:
- 聚合模型:只能为Key列创建倒排索引
唯一模型:需要启用写时合并特性。启用后,可以为任何列创建倒排索引。- 复制模型:可以为任何列创建倒排索引
向已存在的表添加倒排索引
0.0版本之前:
sql
-- syntax 1
CREATE INDEX idx_name ON table_name(column_name) USING INVERTED [PROPERTIES("parser" = "english|chinese|unicode")] [COMMENT 'your comment'];
-- syntax 2
ALTER TABLE table_name ADD INDEX idx_name(column_name) USING INVERTED [PROPERTIES("parser" = "english|chinese|unicode")] [COMMENT 'your comment'];- 2.0.0版本之后(包括2.0.0):
- 上面的"创建/添加索引"操作只会为增量数据生成倒排索引。增加BUILD INDEX的语法,为存量数据添加倒排索引:
sql
-- syntax 1, add inverted index to the stock data of the whole table by default
BUILD INDEX index_name ON table_name;
-- syntax 2, partition can be specified, and one or more can be specified
BUILD INDEX index_name ON table_name PARTITIONS(partition_name1, partition_name2);(上面的创建/添加索引操作需要在执行BUILD index之前执行)
要查看BUILD INDEX的进度,可以运行以下语句
sql
SHOW BUILD INDEX [FROM db_name];
-- Example 1: Viewing the progress of all BUILD INDEX tasks
SHOW BUILD INDEX;
-- Example 2: Viewing the progress of the BUILD INDEX task for a specified table
SHOW BUILD INDEX where TableName = "table1";要取消BUILD INDEX,可以运行以下语句
sql
CANCEL BUILD INDEX ON table_name;
CANCEL BUILD INDEX ON table_name (job_id1,jobid_2,...);删除倒排索引
sql
-- syntax 1
DROP INDEX idx_name ON table_name;
-- syntax 2
ALTER TABLE table_name DROP INDEX idx_name;使用倒排索引加速查询
sql
-- 1. fulltext search using MATCH_ANY OR MATCH_ALL
SELECT * FROM table_name WHERE column_name MATCH_ANY | MATCH_ALL 'keyword1 ...';
-- 1.1 find rows that logmsg contains keyword1
SELECT * FROM table_name WHERE logmsg MATCH_ANY 'keyword1';
-- 1.2 find rows that logmsg contains keyword1 or keyword2 or more keywords
SELECT * FROM table_name WHERE logmsg MATCH_ANY 'keyword1 keyword2';
-- 1.3 find rows that logmsg contains both keyword1 and keyword2 and more keywords
SELECT * FROM table_name WHERE logmsg MATCH_ALL 'keyword1 keyword2';
-- 1.4 When not specifying a slop for a phrase query, the default slop is 0, meaning "keyword1 keyword2" must be adjacent. You can specify the slop for a phrase query using the tilde (~) symbol.
SELECT * FROM table_name WHERE logmsg MATCH_PHRASE 'keyword1 keyword2';
SELECT * FROM table_name WHERE logmsg MATCH_PHRASE 'keyword1 keyword2 ~3';
-- 1.5 Under the premise of maintaining word order, perform prefix matching on the last word "keyword2", and default to finding 50 prefix words (controlled by the session variable "inverted_index_max_expansions").
SELECT * FROM table_name WHERE logmsg MATCH_PHRASE_PREFIX 'keyword1 keyword2';
-- 1.6 If only one word is provided, it will revert to a prefix query, and default to finding 50 prefix words (controlled by the session variable "inverted_index_max_expansions").
SELECT * FROM table_name WHERE logmsg MATCH_PHRASE_PREFIX 'keyword1';
-- 1.7 Perform regular expression matching on the segmented words, and default to matching 50 words (controlled by the session variable "inverted_index_max_expansions").
SELECT * FROM table_name WHERE logmsg MATCH_REGEXP 'key*';
-- 2. normal equal, range query
SELECT * FROM table_name WHERE id = 123;
SELECT * FROM table_name WHERE ts > '2023-01-01 00:00:00';
SELECT * FROM table_name WHERE op_type IN ('add', 'delete');Tokenization Function
要评估分词的实际效果或文本块分词,可以使用tokenize 函数。
bash
mysql> SELECT TOKENIZE('武汉长江大桥','"parser"="chinese","parser_mode"="fine_grained");
+-----------------------------------------------------------------------------------+
| tokenize('武汉长江大桥', '"parser"="chinese","parser_mode"="fine_grained"') |
+-----------------------------------------------------------------------------------+
| ["武汉", "武汉长江大桥", "长江", "长江大桥", "大桥"] |
+-----------------------------------------------------------------------------------+
1 row in set (0.02 sec)
mysql> SELECT TOKENIZE('武汉市长江大桥','"parser"="chinese","parser_mode"="fine_grained");
+--------------------------------------------------------------------------------------+
| tokenize('武汉市长江大桥', '"parser"="chinese","parser_mode"="fine_grained"') |
+--------------------------------------------------------------------------------------+
| ["武汉", "武汉市", "市长", "长江", "长江大桥", "大桥"] |
+--------------------------------------------------------------------------------------+
1 row in set (0.02 sec)
mysql> SELECT TOKENIZE('武汉市长江大桥','"parser"="chinese","parser_mode"="coarse_grained");
+----------------------------------------------------------------------------------------+
| tokenize('武汉市长江大桥', '"parser"="chinese","parser_mode"="coarse_grained"') |
+----------------------------------------------------------------------------------------+
| ["武汉市", "长江大桥"] |
+----------------------------------------------------------------------------------------+
1 row in set (0.02 sec)
mysql> SELECT TOKENIZE('I love CHINA','"parser"="english");
+------------------------------------------------+
| tokenize('I love CHINA', '"parser"="english"') |
+------------------------------------------------+
| ["i", "love", "china"] |
+------------------------------------------------+
1 row in set (0.02 sec)
mysql> SELECT TOKENIZE('I love CHINA 我爱我的祖国','"parser"="unicode");
+-------------------------------------------------------------------+
| tokenize('I love CHINA 我爱我的祖国', '"parser"="unicode"') |
+-------------------------------------------------------------------+
| ["i", "love", "china", "我", "爱", "我", "的", "祖", "国"] |
+-------------------------------------------------------------------+
1 row in set (0.02 sec)6.5 Examples
这个示例将演示使用一个有100万行的hackernews数据集创建倒排索引、全文查询和普通查询。还将显示使用和不使用倒排索引之间的性能比较。
创建表
sql
CREATE DATABASE test_inverted_index;
USE test_inverted_index;
-- define inverted index idx_comment for comment column on table creation
-- USING INVERTED specify using inverted index
-- PROPERTIES("parser" = "english") specify english word parser
CREATE TABLE hackernews_1m
(
`id` BIGINT,
`deleted` TINYINT,
`type` String,
`author` String,
`timestamp` DateTimeV2,
`comment` String,
`dead` TINYINT,
`parent` BIGINT,
`poll` BIGINT,
`children` Array<BIGINT>,
`url` String,
`score` INT,
`title` String,
`parts` Array<INT>,
`descendants` INT,
INDEX idx_comment (`comment`) USING INVERTED PROPERTIES("parser" = "english") COMMENT 'inverted index for comment'
)
DUPLICATE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 10
PROPERTIES ("replication_num" = "1");导入数据
通过流加载加载数
sql
wget https://doris-build-1308700295.cos.ap-beijing.myqcloud.com/regression/index/hacknernews_1m.csv.gz
curl --location-trusted -u root: -H "compress_type:gz" -T hacknernews_1m.csv.gz http://127.0.0.1:8030/api/test_inverted_index/hackernews_1m/_stream_load
{
"TxnId": 2,
"Label": "a8a3e802-2329-49e8-912b-04c800a461a6",
"TwoPhaseCommit": "false",
"Status": "Success",
"Message": "OK",
"NumberTotalRows": 1000000,
"NumberLoadedRows": 1000000,
"NumberFilteredRows": 0,
"NumberUnselectedRows": 0,
"LoadBytes": 130618406,
"LoadTimeMs": 8988,
"BeginTxnTimeMs": 23,
"StreamLoadPutTimeMs": 113,
"ReadDataTimeMs": 4788,
"WriteDataTimeMs": 8811,
"CommitAndPublishTimeMs": 38
}通过SQL count()检查加载的数据
bash
mysql> SELECT count() FROM hackernews_1m;
+---------+
| count() |
+---------+
| 1000000 |
+---------+
1 row in set (0.02 sec)查询
- 全文检索查询
使用LIKE计算评论包含'OLAP'的行数,花费0.18秒
bash
mysql> SELECT count() FROM hackernews_1m WHERE comment LIKE '%OLAP%';
+---------+
| count() |
+---------+
| 34 |
+---------+
1 row in set (0.18 sec)- 使用基于倒排索引的
MATCH_ANY全文搜索计算评论包含'OLAP'的行,成本为0.02秒,加速速度为9倍,在更大的数据集上加速速度会更大- 这里结果条数的差异,是因为倒排索引对 comment 分词后,还会对词进行进行统一成小写等归一化处理,因此
MATCH_ANY比LIKE的结果多一些。
- 这里结果条数的差异,是因为倒排索引对 comment 分词后,还会对词进行进行统一成小写等归一化处理,因此
bash
mysql> SELECT count() FROM hackernews_1m WHERE comment MATCH_ANY 'OLAP';
+---------+
| count() |
+---------+
| 35 |
+---------+
1 row in set (0.02 sec)同样,count on"OLTP"显示0.07s vs 0.01s。由于Doris中的缓存,LIKE和MATCH_ANY都更快,但仍然有7倍的加速。
bash
mysql> SELECT count() FROM hackernews_1m WHERE comment LIKE '%OLTP%';
+---------+
| count() |
+---------+
| 48 |
+---------+
1 row in set (0.07 sec)
mysql> SELECT count() FROM hackernews_1m WHERE comment MATCH_ANY 'OLTP';
+---------+
| count() |
+---------+
| 51 |
+---------+
1 row in set (0.01 sec)- 同样,count on"OLTP"显示0.07s vs 0.01s。由于Doris中的缓存,LIKE和MATCH_ANY都更快,但仍然有7倍的加速。
bash
mysql> SELECT count() FROM hackernews_1m WHERE comment LIKE '%OLTP%';
+---------+
| count() |
+---------+
| 48 |
+---------+
1 row in set (0.07 sec)
mysql> SELECT count() FROM hackernews_1m WHERE comment MATCH_ANY 'OLTP';
+---------+
| count() |
+---------+
| 51 |
+---------+
1 row in set (0.01 sec)- 同时搜索"OLAP"和"OLTP",0.13秒vs 0.01秒,加速13倍
- 如果需要显示所有关键字,则使用MATCH_ALL
bash
mysql> SELECT count() FROM hackernews_1m WHERE comment LIKE '%OLAP%' AND comment LIKE '%OLTP%';
+---------+
| count() |
+---------+
| 14 |
+---------+
1 row in set (0.13 sec)
mysql> SELECT count() FROM hackernews_1m WHERE comment MATCH_ALL 'OLAP OLTP';
+---------+
| count() |
+---------+
| 15 |
+---------+
1 row in set (0.01 sec)- 搜索"OLAP"或"OLTP"中的至少一个,0.12秒vs 0.01秒,加速12倍
- 如果只需要出现至少一个关键字,则使用
MATCH_ANY
- 如果只需要出现至少一个关键字,则使用
sql
mysql> SELECT count() FROM hackernews_1m WHERE comment LIKE '%OLAP%' OR comment LIKE '%OLTP%';
+---------+
| count() |
+---------+
| 68 |
+---------+
1 row in set (0.12 sec)
mysql> SELECT count() FROM hackernews_1m WHERE comment MATCH_ANY 'OLAP OLTP';
+---------+
| count() |
+---------+
| 71 |
+---------+
1 row in set (0.01 sec)- 普通相等,范围查询
查询DateTime列
sql
mysql> SELECT count() FROM hackernews_1m WHERE timestamp > '2007-08-23 04:17:00';
+---------+
| count() |
+---------+
| 999081 |
+---------+
1 row in set (0.03 sec)为时间戳列添加倒排索引
sql
-- for timestamp column, there is no need for word parser, so just USING INVERTED without PROPERTIES
-- this is the first syntax for CREATE INDEX
mysql> CREATE INDEX idx_timestamp ON hackernews_1m(timestamp) USING INVERTED;
Query OK, 0 rows affected (0.03 sec)在2.0.0版本(包括2.0.0)之后,你需要执行BUILD INDEX来为存量 数据添加倒排索引:
sql
mysql> BUILD INDEX idx_timestamp ON hackernews_1m;
Query OK, 0 rows affected (0.01 sec)查看索引创建进度,通过 FinishTime 和 CreateTime 的差值,可以看到 100 万条数据对 timestamp 列建倒排索引只用了 1s
bash
mysql> SHOW ALTER TABLE COLUMN;
+-------+---------------+-------------------------+-------------------------+---------------+---------+---------------+---------------+---------------+----------+------+----------+---------+
| JobId | TableName | CreateTime | FinishTime | IndexName | IndexId | OriginIndexId | SchemaVersion | TransactionId | State | Msg | Progress | Timeout |
+-------+---------------+-------------------------+-------------------------+---------------+---------+---------------+---------------+---------------+----------+------+----------+---------+
| 10030 | hackernews_1m | 2023-02-10 19:44:12.929 | 2023-02-10 19:44:13.938 | hackernews_1m | 10031 | 10008 | 1:1994690496 | 3 | FINISHED | | NULL | 2592000 |
+-------+---------------+-------------------------+-------------------------+---------------+---------+---------------+---------------+---------------+----------+------+----------+---------+
1 row in set (0.00 sec)在2.0.0版本之后(包括2.0.0),您可以通过 SHOW BUILD INDEX查看存量数据创建索引的进度:
bash
-- If the table has no partitions, the PartitionName defaults to TableName
mysql> SHOW BUILD INDEX;
+-------+---------------+---------------+----------------------------------------------------------+-------------------------+-------------------------+---------------+----------+------+----------+
| JobId | TableName | PartitionName | AlterInvertedIndexes | CreateTime | FinishTime | TransactionId | State | Msg | Progress |
+-------+---------------+---------------+----------------------------------------------------------+-------------------------+-------------------------+---------------+----------+------+----------+
| 10191 | hackernews_1m | hackernews_1m | [ADD INDEX idx_timestamp (`timestamp`) USING INVERTED], | 2023-06-26 15:32:33.894 | 2023-06-26 15:32:34.847 | 3 | FINISHED | | NULL |
+-------+---------------+---------------+----------------------------------------------------------+-------------------------+-------------------------+---------------+----------+------+----------+
1 row in set (0.04 sec)在建立索引后,Doris会自动使用索引进行范围查询,但性能几乎是一样的,因为它在小数据集上已经很快了
sql
mysql> SELECT count() FROM hackernews_1m WHERE timestamp > '2007-08-23 04:17:00';
+---------+
| count() |
+---------+
| 999081 |
+---------+
1 row in set (0.01 sec)对具有数值类型的parent 列进行类似的测试,使用相等的查询
bash
mysql> SELECT count() FROM hackernews_1m WHERE parent = 11189;
+---------+
| count() |
+---------+
| 2 |
+---------+
1 row in set (0.01 sec)
-- do not use word parser for numeric type USING INVERTED
-- use the second syntax ALTER TABLE
mysql> ALTER TABLE hackernews_1m ADD INDEX idx_parent(parent) USING INVERTED;
Query OK, 0 rows affected (0.01 sec)
-- After version 2.0.0 (including 2.0.0), you need to execute `BUILD INDEX` to add inverted index to the stock data:
mysql> BUILD INDEX idx_parent ON hackernews_1m;
Query OK, 0 rows affected (0.01 sec)
mysql> SHOW ALTER TABLE COLUMN;
+-------+---------------+-------------------------+-------------------------+---------------+---------+---------------+---------------+---------------+----------+------+----------+---------+
| JobId | TableName | CreateTime | FinishTime | IndexName | IndexId | OriginIndexId | SchemaVersion | TransactionId | State | Msg | Progress | Timeout |
+-------+---------------+-------------------------+-------------------------+---------------+---------+---------------+---------------+---------------+----------+------+----------+---------+
| 10030 | hackernews_1m | 2023-02-10 19:44:12.929 | 2023-02-10 19:44:13.938 | hackernews_1m | 10031 | 10008 | 1:1994690496 | 3 | FINISHED | | NULL | 2592000 |
| 10053 | hackernews_1m | 2023-02-10 19:49:32.893 | 2023-02-10 19:49:33.982 | hackernews_1m | 10054 | 10008 | 1:378856428 | 4 | FINISHED | | NULL | 2592000 |
+-------+---------------+-------------------------+-------------------------+---------------+---------+---------------+---------------+---------------+----------+------+----------+---------+
mysql> SHOW BUILD INDEX;
+-------+---------------+---------------+----------------------------------------------------+-------------------------+-------------------------+---------------+----------+------+----------+
| JobId | TableName | PartitionName | AlterInvertedIndexes | CreateTime | FinishTime | TransactionId | State | Msg | Progress |
+-------+---------------+---------------+----------------------------------------------------+-------------------------+-------------------------+---------------+----------+------+----------+
| 11005 | hackernews_1m | hackernews_1m | [ADD INDEX idx_parent (`parent`) USING INVERTED], | 2023-06-26 16:25:10.167 | 2023-06-26 16:25:10.838 | 1002 | FINISHED | | NULL |
+-------+---------------+---------------+----------------------------------------------------+-------------------------+-------------------------+---------------+----------+------+----------+
1 row in set (0.01 sec)
mysql> SELECT count() FROM hackernews_1m WHERE parent = 11189;
+---------+
| count() |
+---------+
| 2 |
+---------+
1 row in set (0.01 sec)- 对字符串类型的
author建立不分词的倒排索引,等值查询也可以利用索引加速
bash
mysql> SELECT count() FROM hackernews_1m WHERE author = 'faster';
+---------+
| count() |
+---------+
| 20 |
+---------+
1 row in set (0.03 sec)
-- do not use any word parser for author to treat it as a whole
mysql> ALTER TABLE hackernews_1m ADD INDEX idx_author(author) USING INVERTED;
Query OK, 0 rows affected (0.01 sec)
-- After version 2.0.0 (including 2.0.0), you need to execute `BUILD INDEX` to add inverted index to the stock data:
mysql> BUILD INDEX idx_author ON hackernews_1m;
Query OK, 0 rows affected (0.01 sec)
-- costs 1.5s to BUILD INDEX for author column with 1 million rows.
mysql> SHOW ALTER TABLE COLUMN;
+-------+---------------+-------------------------+-------------------------+---------------+---------+---------------+---------------+---------------+----------+------+----------+---------+
| JobId | TableName | CreateTime | FinishTime | IndexName | IndexId | OriginIndexId | SchemaVersion | TransactionId | State | Msg | Progress | Timeout |
+-------+---------------+-------------------------+-------------------------+---------------+---------+---------------+---------------+---------------+----------+------+----------+---------+
| 10030 | hackernews_1m | 2023-02-10 19:44:12.929 | 2023-02-10 19:44:13.938 | hackernews_1m | 10031 | 10008 | 1:1994690496 | 3 | FINISHED | | NULL | 2592000 |
| 10053 | hackernews_1m | 2023-02-10 19:49:32.893 | 2023-02-10 19:49:33.982 | hackernews_1m | 10054 | 10008 | 1:378856428 | 4 | FINISHED | | NULL | 2592000 |
| 10076 | hackernews_1m | 2023-02-10 19:54:20.046 | 2023-02-10 19:54:21.521 | hackernews_1m | 10077 | 10008 | 1:1335127701 | 5 | FINISHED | | NULL | 2592000 |
+-------+---------------+-------------------------+-------------------------+---------------+---------+---------------+---------------+---------------+----------+------+----------+---------+
mysql> SHOW BUILD INDEX order by CreateTime desc limit 1;
+-------+---------------+---------------+----------------------------------------------------+-------------------------+-------------------------+---------------+----------+------+----------+
| JobId | TableName | PartitionName | AlterInvertedIndexes | CreateTime | FinishTime | TransactionId | State | Msg | Progress |
+-------+---------------+---------------+----------------------------------------------------+-------------------------+-------------------------+---------------+----------+------+----------+
| 13006 | hackernews_1m | hackernews_1m | [ADD INDEX idx_author (`author`) USING INVERTED], | 2023-06-26 17:23:02.610 | 2023-06-26 17:23:03.755 | 3004 | FINISHED | | NULL |
+-------+---------------+---------------+----------------------------------------------------+-------------------------+-------------------------+---------------+----------+------+----------+
1 row in set (0.01 sec)
-- equal qury on text field autor get 3x speedup
mysql> SELECT count() FROM hackernews_1m WHERE author = 'faster';
+---------+
| count() |
+---------+
| 20 |
+---------+
1 row in set (0.01 sec)