用户可以通过schema Change操作修改现有表的模式。表的模式主要包括对列的修改和对索引的修改。这里我们主要介绍与列相关的Scheme更改。对于与索引相关的更改,可以查看数据表设计/表索引,查看每个索引的更改方法。
1、术语
- 基本表(Base Table):创建每个表时,它对应于一个基表。
- Rollup:基于基表或其他上Rollup创建的上Rollup表。
- Index: 物化索引(materialized index)。汇总(Rollup )表或基表都称为物化索引。
- Transaction:每个导入任务都是一个事务,每个事务都有一个惟一的递增事务ID。
2、介绍
Light Schema Change
在介绍之前,有必要了解Apache Doris 1.2.0版本之前的三个Schema Change实现,它们都是异步的:
- 硬链接模式更改 (
Hard Linked Schema Change) 主要对值列进行加减操作,不需要修改数据文件。 - 直接模式更改 (
Direct Schema Change)主要用于更改值列的类型,需要重写数据,但不涉及键列,也不需要重新排序。 - 排序模式更改 (
Sort schema change)主要用于键列模式更改,因为键列加/减/修改类型等操作会影响现有数据的排序,所以需要将数据再次读出,修改,然后排序。
自Apache Doris 1.2.0以来,对于第一种类型,已经引入了轻量级模式更改(light schema change)的新特性 。新的轻型模式更改允许在毫秒内完成值列的加减。从Apache Doris 2.0.0开始,默认情况下,所有新创建的表都支持轻模式更改。
除了添加和删除value列之外,其他类型的模式更改的主要原则如下 :
执行模式更改的基本过程是从原始表/Index数据中的数据/Index生成新的模式表。数据转换主要有两部分,一部分是对已有历史数据的转换,另一部分是对执行模式更改时新导入的数据进行转换。
sql
+----------+
| Load Job |
+----+-----+
|
| Load job generates both origin and new Index data
|
| +------------------+ +---------------+
| | Origin Index | | Origin Index |
+------> New Incoming Data| | History Data |
| +------------------+ +------+--------+
| |
| | Convert history data
| |
| +------------------+ +------v--------+
| | New Index | | New Index |
+------> New Incoming Data| | History Data |
+------------------+ +---------------+在开始转换历史数据之前,Doris将获取一个最新的事务ID,并等待该事务ID完成之前的所有导入事务。这个事务ID成为一个分水岭。这意味着Doris确保分水岭之后的所有导入任务将同时为原始表/索引和新表/索引生成数据。这样,当历史数据转换完成后,就可以保证新表中的数据是完整的。
创建模式更改的特定语法可以在帮助ALTER TABLE COLUMN的模式更改部分中找到。
3、将位于指定位置的列添加到指定索引
sql
ALTER TABLE table_name ADD COLUMN column_name column_type [KEY | agg_type] [DEFAULT "default_value"]
[AFTER column_name|FIRST]
[TO rollup_index_name]
[PROPERTIES ("key"="value", ...)]- 对于aggregate 模型,如果添加值列,则指定
agg_type。 - 对于非聚合模型(例如,
DUPLICATE KEY),如果添加键列,请指定KEY关键字。 - 不能在 Rollup Index 中增加 Base Index 中已经存在的列(如有需要,可以重新创建一个 Rollup Index)。
Examples
- 在
example_rollup_index的col1之后添加一个键列new_col(非聚合模型)
sql
ALTER TABLE example_db.my_table
ADD COLUMN new_col INT KEY DEFAULT "0" AFTER col1
TO example_rollup_index;- 向
example_rollup_index添加一个值列new_col(非聚合模型),它在col1之后的默认值为0
sql
ALTER TABLE example_db.my_table
ADD COLUMN new_col INT DEFAULT "0" AFTER col1
TO example_rollup_index;- 在
example_rollup_index的col1之后添加一个键列new_col(聚合模型)
sql
ALTER TABLE example_db.my_table
ADD COLUMN new_col INT DEFAULT "0" AFTER col1
TO example_rollup_index;- 向
example_rollup_index添加col1之后具有SUM 聚合类型(聚合模型)的值列new_col
sql
ALTER TABLE example_db.my_table
ADD COLUMN new_col INT SUM DEFAULT "0" AFTER col1
TO example_rollup_index;4、向指定索引添加多个列
sql
ALTER TABLE table_name ADD COLUMN (column_name1 column_type [KEY | agg_type] DEFAULT "default_value", ...)
[TO rollup_index_name]
[PROPERTIES ("key"="value", ...)]- 对于聚合模型,如果添加值列,则指定
agg_type。 - 对于聚合模型,如果添加键列,请指定
KEY关键字。(?) - 不能向基本索引中已经存在的rollup索引添加列(如果需要,可以创建新的rollup索引)。
Example
向example_rollup_index添加多个列(聚合模型):
sql
ALTER TABLE example_db.my_table
ADD COLUMN (col1 INT DEFAULT "1", col2 FLOAT SUM DEFAULT "2.3")
TO example_rollup_index;5、从指定索引中删除列
sql
ALTER TABLE table_name DROP COLUMN column_name
[FROM rollup_index_name]- 不能删除分区列。
- 如果是从 Base Index 中删除列,则如果 Rollup Index 中包含该列,也会被删除
Example
从example_rollup_index中删除col2列:
sql
ALTER TABLE example_db.my_table
DROP COLUMN col2
FROM example_rollup_index;6、修改指定索引的列类型和位置
sql
ALTER TABLE table_name MODIFY COLUMN column_name column_type [KEY | agg_type] [NULL | NOT NULL] [DEFAULT "default_value"]
[AFTER column_name|FIRST]
[FROM rollup_index_name]
[PROPERTIES ("key"="value", ...)]- 对于聚合模型,如果修改值列,则指定
agg_type。 - 对于非聚合模型,如果修改键列,请指定KEY 关键字。
- **只有列类型可以修改,其他列属性保持不变(**即,其他属性需要显式写入语句中,参见例8)。
- 不能修改分区列和桶列。
- 目前支持以下类型转换(用户需要保证精度损失):
- 从TINYINT/SMALLINT/INT/BIGINT/LARGEINT/FLOAT/DOUBLE转换为更大的数字类型。
- 从TINYINT/SMALLINT/INT/BIGINT/LARGEINT/FLOAT/DOUBLE/DECIMAL 到VARCHAR的转换。
- 修改VARCHAR的最大长度
- 从VARCHAR/CHAR 转换为TINYINT/SMALLINT/INT/BIGINT/LARGEINT/FLOAT/DOUBLE。
- 从VARCHAR/CHAR 到DATE 的转换(支持六种格式:
"%Y-%m-%d", "%y-%m-%d", "%Y%m%d", "%y%m%d", "%Y/%m/%d", "%y/%m/%d") - 从DATETIME 转换到DATE (仅保留年-月-日信息,例如:
2019-12-09 21:47:05 <--> 2019-12-09) - 从DATE 到DATETIME 的转换(自动为小时、分钟和秒添加零,例如:
2019-12-09 <--> 2019-12-09 00:00:00) - 从FLOAT 到DOUBLE 的转换
- 从INT 到DATE 的转换(如果INT类型数据无效,转换失败,原始数据保持不变)。
- 除了DATE 和DATETIME 以外的所有类型都可以转换为STRING ,但是STRING不能转换为其他类型。
Examples
- 修改基索引中键列
col1的列类型为BIGINT ,并将其移动到列col2之后
sql
ALTER TABLE example_db.my_table
MODIFY COLUMN col1 BIGINT KEY DEFAULT "1" AFTER col2;注意:无论是修改键列还是值列,都需要声明完整的列信息。
- 修改Base Index中列
val1的最大长度。原来的val1是(val1 VARCHAR(32) REPLACE DEFAULT "abc")
sql
ALTER TABLE example_db.my_table
MODIFY COLUMN val1 VARCHAR(64) REPLACE DEFAULT "abc"注意:在保持列的其他属性不变的情况下,只能修改列的类型。
- 修改duplicate key 表的键列中字段的长度
sql
alter table example_tbl modify column k3 varchar(50) key null comment 'to 50'7、为指定索引重新排序列
sql
ALTER TABLE table_name ORDER BY (column_name1, column_name2, ...)
[FROM rollup_index_name]
[PROPERTIES ("key"="value", ...)]- 应该列出索引中的所有列
- 值列在键列之后。
Example
重新排序索引example_rollup_index中的列(假设原始列顺序为:k1、k2、k3、v1、v2)。
sql
ALTER TABLE example_db.my_table
ORDER BY (k3,k1,k2,v2,v1)
FROM example_rollup_index;8、在一次提交中执行多个更改
模式更改可以在单个作业中修改多个索引。
Example 1
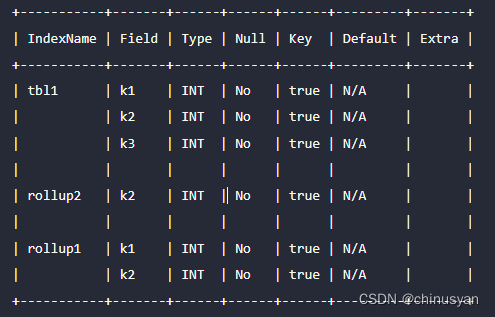
可以使用以下命令将列k4 添加到rollup1和rollup2,并将列k5 添加到rollup2:
sql
ALTER TABLE tbl1
ADD COLUMN k4 INT default "1" to rollup1,
ADD COLUMN k4 INT default "1" to rollup2,
ADD COLUMN k5 INT default "1" to rollup2;完成后,模式变为:
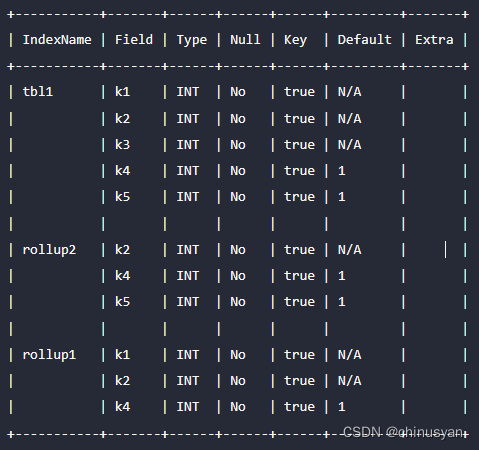
如所见,基表tbl1自动包含列k4和k5。添加到rollup中的任何列都将自动添加到基表中。
此外,不允许向rollup 中添加已经存在于基表中的列。如果用户需要这样做,他们可以使用附加列创建一个新的汇总,然后删除原始的汇总。
Example 2
sql
ALTER TABLE example_db.my_table
ADD COLUMN v2 INT MAX DEFAULT "0" AFTER k2 TO example_rollup_index,
ORDER BY (k3,k1,k2,v2,v1) FROM example_rollup_index;9、修改列名称
sql
ALTER TABLE RENAME COLUMN old_column_name new_column_name; 10、检查作业状态
模式更改的创建是一个异步过程 。作业提交成功后,用户需要使用SHOW ALTER TABLE COLUMN命令查看作业的进度。
SHOW ALTER TABLE COLUMN允许您查看当前正在执行或已完成的模式更改作业。当模式更改作业涉及多个索引时,该命令将显示多行,每行对应一个索引。例如:
sql
mysql SHOW ALTER TABLE COLUMN\G;
*************************** 1. row ***************************
JobId: 20021
TableName: tbl1
CreateTime: 2019-08-05 23:03:13
FinishTime: 2019-08-05 23:03:42
IndexName: tbl1
IndexId: 20022
OriginIndexId: 20017
SchemaVersion: 2:792557838
TransactionId: 10023
State: FINISHED
Msg:
Progress: NULL
Timeout: 86400
1 row in set (0.00 sec)-
JobId:每个模式修改作业的唯一ID。
-
TableName:与模式更改相关联的基表的名称。
-
CreateTime:作业创建时间。
-
FinishTime :任务完成时间。如果未完成,则显示"N/A"。
-
IndexName:要修改的索引的名称。
-
IndexId:新索引的唯一ID。
-
OriginIndexId:旧索引的唯一ID。
-
SchemaVersion:以M:N的格式显示,其中M表示schema change 变更的版本,N表示对应的哈希值。版本随着每次模式更改而增加。
-
TransactionId: 转换历史数据的分水岭 Transaction ID。
-
State:当前工作的状态。
PENDING:该作业正在等待调度队列中。WAITING_TXN:等待边界事务ID完成前的导入任务。RUNNING:正在进行历史数据转换。FINISHED:工作成功完成。CANCELLED:作业被取消。
-
Msg:如果任务失败,该字段显示失败消息。
-
Progress : 工作进展。只有状态为RUNNING 时才会显示。进度以M/N的格式显示,其中N是模式更改中涉及的副本总数,M是完成历史数据转换的副本数量。
-
Timeout:作业超时(以秒为单位)。
11、取消作业
当任务状态不是FINISHED 或CANCELLED时,可以使用以下命令取消模式修改任务:
sql
CANCEL ALTER TABLE COLUMN FROM tbl_name;说明
- 一次只能在一个表上运行一个模式更改作业。
- 模式更改操作不会阻塞导入和查询操作。
- 不能修改分区列和桶列。
- 如果模式包含使用
REPLACE方法聚合的值列,则不允许删除键列。 - 如果键列被删除,Doris无法确定
REPLACE列的值。 - Unique 数据模型表的所有非 Key 列都是 REPLACE 聚合方式。
- 在添加聚合类型为
SUM或REPLACE的值列时,该列的默认值对于历史数据没有任何意义。 - 由于历史数据丢失了详细信息,默认值不能反映实际的聚合值。
- 修改列类型时,除type外的所有字段都需要根据原列的信息填写。
- 例如,要将列k1 从
INT SUM NULL DEFAULT "1"修改为BIGINT,命令如下:ALTER TABLE tbl1 MODIFY COLUMN k1 BIGINT SUM NULL DEFAULT "1"; - 请注意,除了新的列类型之外,聚合方法、可空属性和默认值等其他属性都应该根据原始信息完成。
- 不支持修改聚合类型、可空属性、默认值或列注释。
FAQs
模式更改的执行速度
对于轻型模式更改(例如添加或删除Value列),执行速度可以在毫秒范围内。对于其他类型的Schema Change,在最坏的情况下,执行速度估计在10MB/s左右。作为保守的度量,用户可以根据这个速度设置作业超时。
错误:提交作业时提示"Table xxx is not stable"
只有当表数据完成且处于平衡状态时,才能启动Schema Change。如果表的某些数据分片副本不完整,或者某些副本正在进行平衡操作,则提交将被拒绝。使用命令查看数据分片副本是否完成。
sql
SHOW REPLICA STATUS FROM tbl WHERE STATUS != "OK";如果返回任何结果,则表明副本存在问题。通常,系统将自动修复这些问题,但用户可以使用以下命令优先修复特定表:
sql
ADMIN REPAIR TABLE tbl1;使用实例查询是否有正在运行的均衡任务。
sql
SHOW PROC "/cluster_balance/pending_tablets";等待均衡任务完成或暂时停止均衡操作。
sql
ADMIN SET FRONTEND CONFIG ("disable_balance" = "true");配置
FE 配置
alter_table_timeout_second:作业的默认超时时间,设置为86400秒。
BE 配置
alter_tablet_worker_count:BE端用于执行历史数据转换的线程数。默认值是3。如果希望加速Schema Change作业,可以增大此参数并重新启动BE。然而,拥有太多的转换线程可能会增加IO压力并影响其他操作。该线程与Rollup作业共享。alter_index_worker_count:BE端用于在历史数据上构建索引的线程数(目前只支持倒排索引)。默认值是3。如果要加速Index Change作业,可以增大此参数并重新启动BE。但是,线程太多可能会增加IO压力并影响其他操作。
更多细节
有关Schema Change的更详细语法和最佳实践,请参阅ALTER TABLE COLUMN命令手册。您也可以在MySQL客户端命令行中输入HELP ALTER TABLE COLUMN获取更多帮助信息。