目录
[问题: 传统Javaweb开发的困惑?](#问题: 传统Javaweb开发的困惑?)
[问题: IOC、DI和AOP的思想提出](#问题: IOC、DI和AOP的思想提出)
[问题: Spring框架的诞生](#问题: Spring框架的诞生)
[1. BeanFactory快速入门](#1. BeanFactory快速入门)
[2. ApplicationContext快速入门](#2. ApplicationContext快速入门)
[3. BeanFactory和ApplicationContext的关系](#3. BeanFactory和ApplicationContext的关系)
[1. SpringBean的配置详解](#1. SpringBean的配置详解)
[1.1 Bean的基本配置](#1.1 Bean的基本配置)
[1.2 Bean的实例化方式](#1.2 Bean的实例化方式)
[(1) 构造方法实例化](#(1) 构造方法实例化)
[(2) 工厂方式实例化Bean](#(2) 工厂方式实例化Bean)
[a. 静态工厂方法实例化Bean](#a. 静态工厂方法实例化Bean)
[b. 实例工厂方法实例化Bean](#b. 实例工厂方法实例化Bean)
[c. 实现FactoryBean规范延迟实例化Bean](#c. 实现FactoryBean规范延迟实例化Bean)
[1.3 Bean的依赖注入配置](#1.3 Bean的依赖注入配置)
[(1) 基本数据类型和引用数据类型](#(1) 基本数据类型和引用数据类型)
[(2) List类型数据](#(2) List类型数据)
[(3) Set类型数据](#(3) Set类型数据)
[(4) Map类型数据](#(4) Map类型数据)
[2. Spring的get方法](#2. Spring的get方法)
[3. Spring配置非自定义Bean](#3. Spring配置非自定义Bean)
[3.1 配置Druid交给Spring管理](#3.1 配置Druid交给Spring管理)
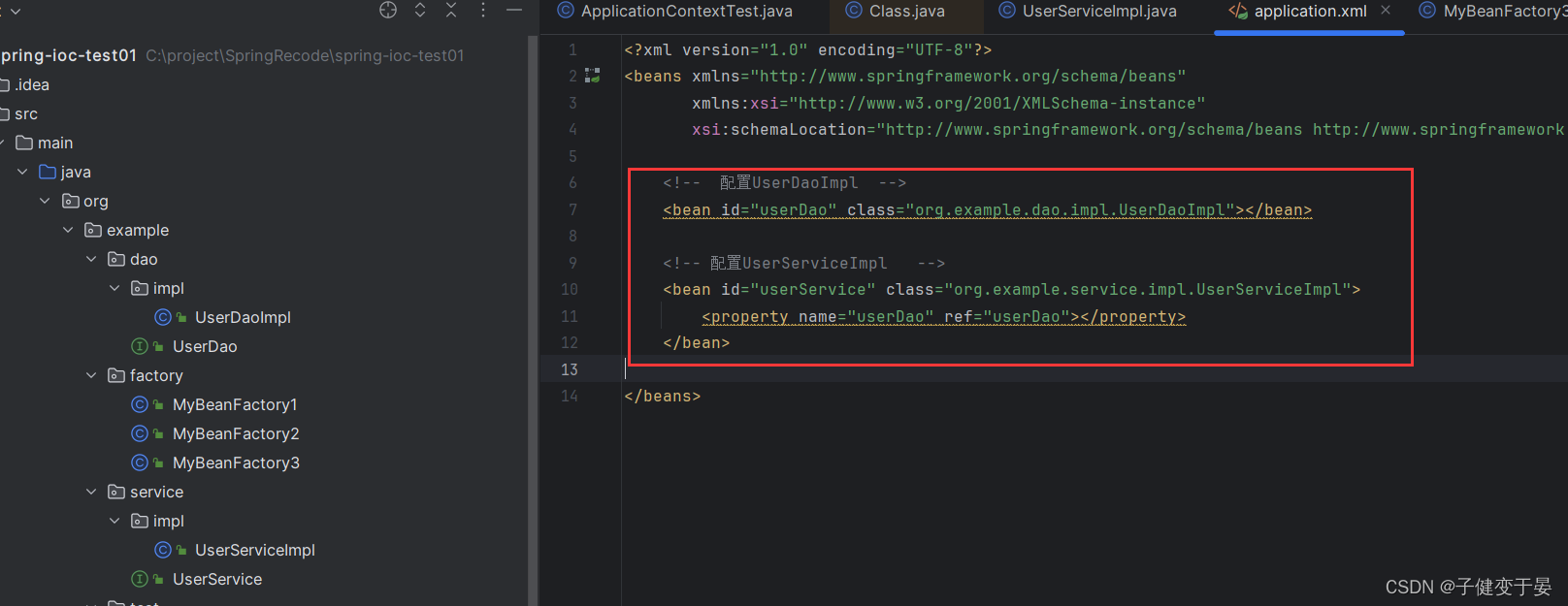
[3.2 配置Connection交给Spring管理](#3.2 配置Connection交给Spring管理)
[4. Bean实例化的基本流程(关键)](#4. Bean实例化的基本流程(关键))
[5. Spring的后处理器入门](#5. Spring的后处理器入门)
[5.1 BeanFactoryPostProcessor](#5.1 BeanFactoryPostProcessor)
[5.2 自定义@Component](#5.2 自定义@Component)
[5.3 BeanPostProcessor](#5.3 BeanPostProcessor)
[5.4 对Bean方法进行执行时间日志增强](#5.4 对Bean方法进行执行时间日志增强)
[6. Spring Bean的生命周期(高频面试题!)](#6. Spring Bean的生命周期(高频面试题!))
[6.1 Bean实例的属性填充](#6.1 Bean实例的属性填充)
[6.1.1 单向属性注入](#6.1.1 单向属性注入)
[6.1.2 双向属性注入(循环依赖问题)!!!](#6.1.2 双向属性注入(循环依赖问题)!!!)
[7. Spring整合第三方框架](#7. Spring整合第三方框架)
[7.1 Spring整合MyBatis](#7.1 Spring整合MyBatis)
[7.2 加载外部properties文件](#7.2 加载外部properties文件)
首先说一下为什么我还写一篇关于Spring的知识博客,因为在早早学习过Spring后的我,发现我对Spring的机制,耦合、注解自动注入等还是有太多的不熟悉,不知道原理写项目的时候使用就会似懂非懂,所以我决定再系统的学习一次Spring。
注:这里看的是黑马的Spring课程
问题: 传统Javaweb开发的困惑?
在Javaweb开发中,我们可以发现我们的业务代码有着很强的耦合,如下图代码我们可以看到层与层之间紧密联系,接口与具体实现紧密联系。
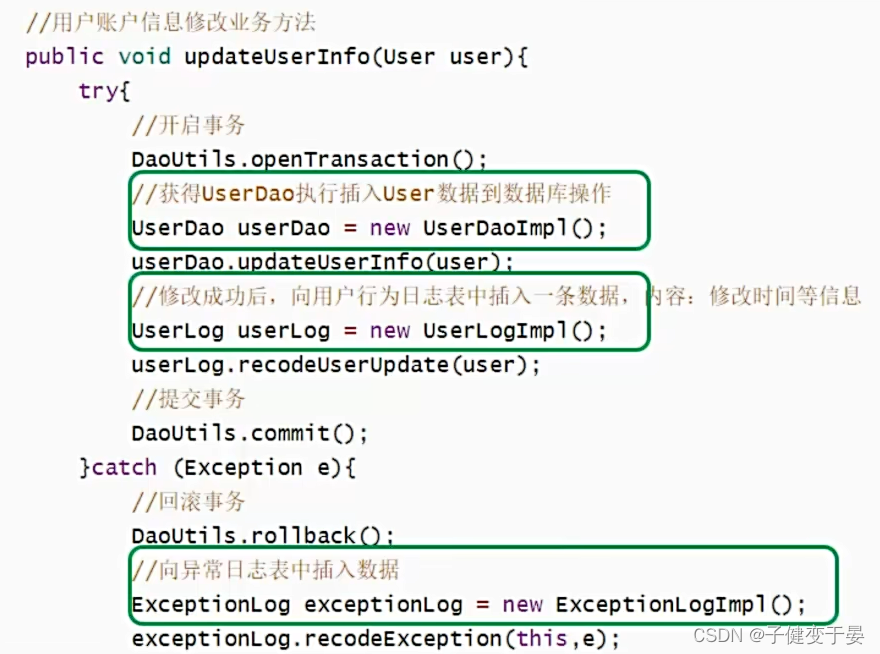
我们对这种耦合性极强的代码的解决方式是不要手动new对象,而是第三方根据程序的要求提供Bean对象。
在这块代码中我们还能看到哪些问题?我们发现日志和事务也是紧密耦合在业务代码中的。

那么我们的解决办法也是不要手动new对象,而是第三方根据程序的要求提供Bean对象的代理对象。

问题: IOC、DI和AOP的思想提出
IOC:Inversion Of Control,控制反转,强调的是由原来在程序中new对象(创建Bean)的权利,给第三方。
DI:Dependency Injection,依赖注入,强调Bean之间的关系(比如Bean1需要Bean2才能实现对应的操作,那么依赖注入就是在第三方完成将Bean2给Bean1的操作,然后只需获得Bean1即可)。
AOP:Aspect Oriented Programming,面向切面编程,功能的横向抽取,主要的实现方式的Proxy(对某个Bean进行增强的)。
问题: Spring框架的诞生
基于上述的三大思想,Spring框架诞生了。
Spring是一个开源的轻量级Java开发应用框架,可以简化企业级应用的开发。
SpringFramework技术栈: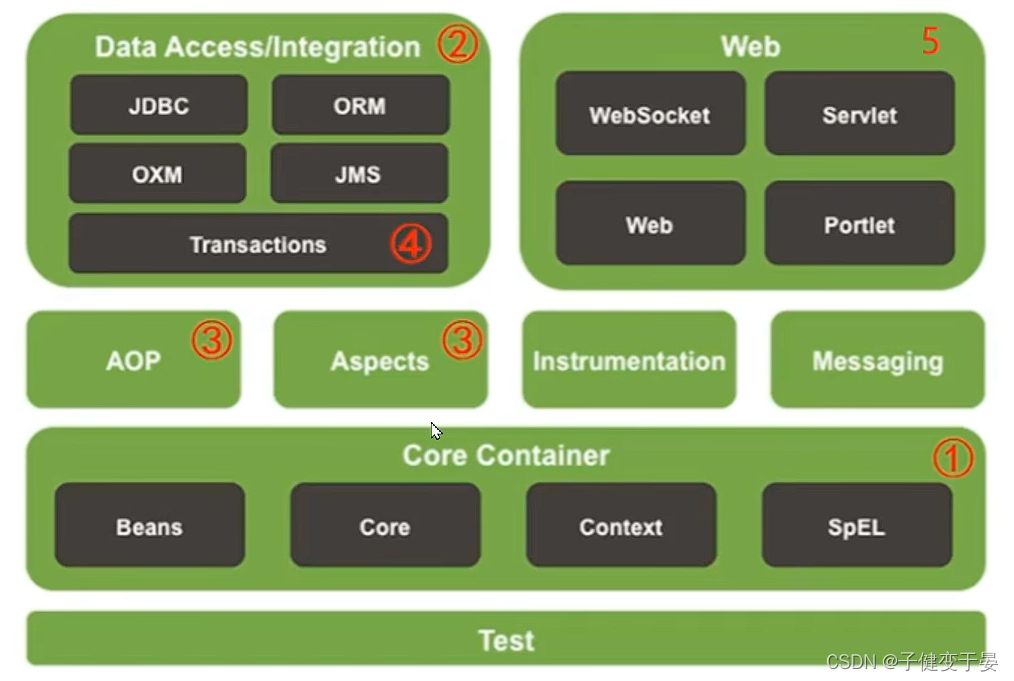
1. BeanFactory快速入门
首先BeanFactory的开发步骤是如下图所示
<1> 导入Spring的jar包
<2> 定义UserService接口及其UserServiceImpl实现类
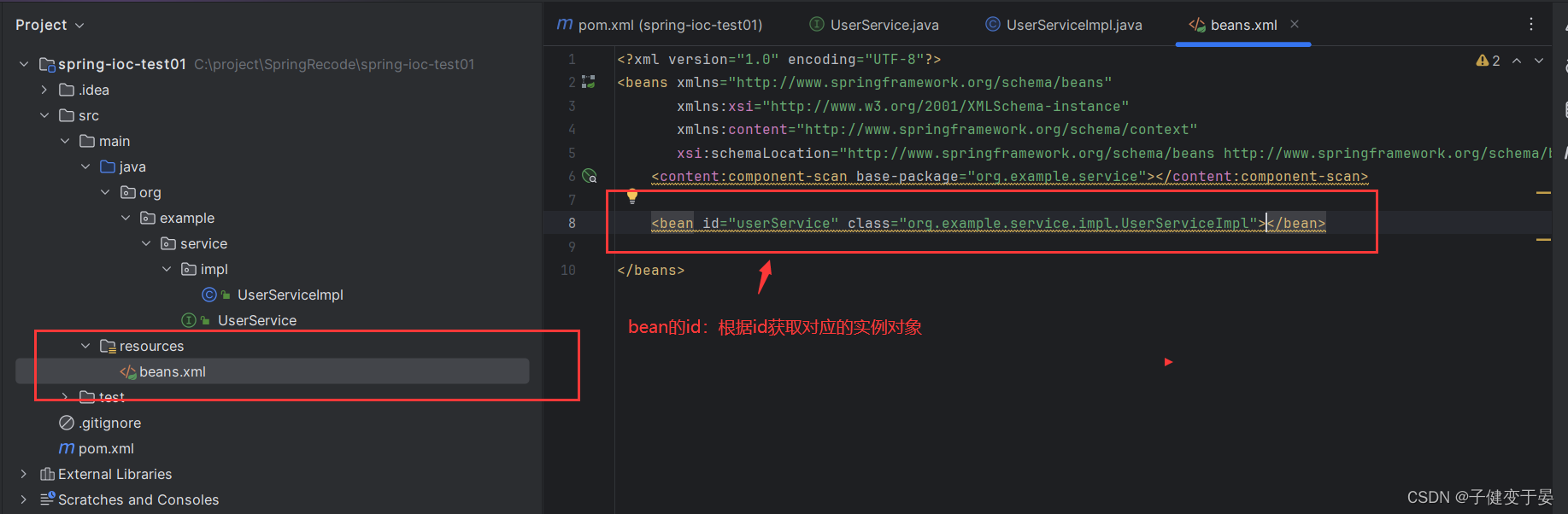
<3> 创建beans.xml配置文件,将UserServiceImpl的信息配置到xml中
<4> 编写测试代码,创建BeanFactory,加载配置文件,获取UserServiceImpl实例对象
分别编写UserService接口及其实现类
编写beans.xml
最后编写测试类看看是否可以获取到UserServiceImpl实例对象
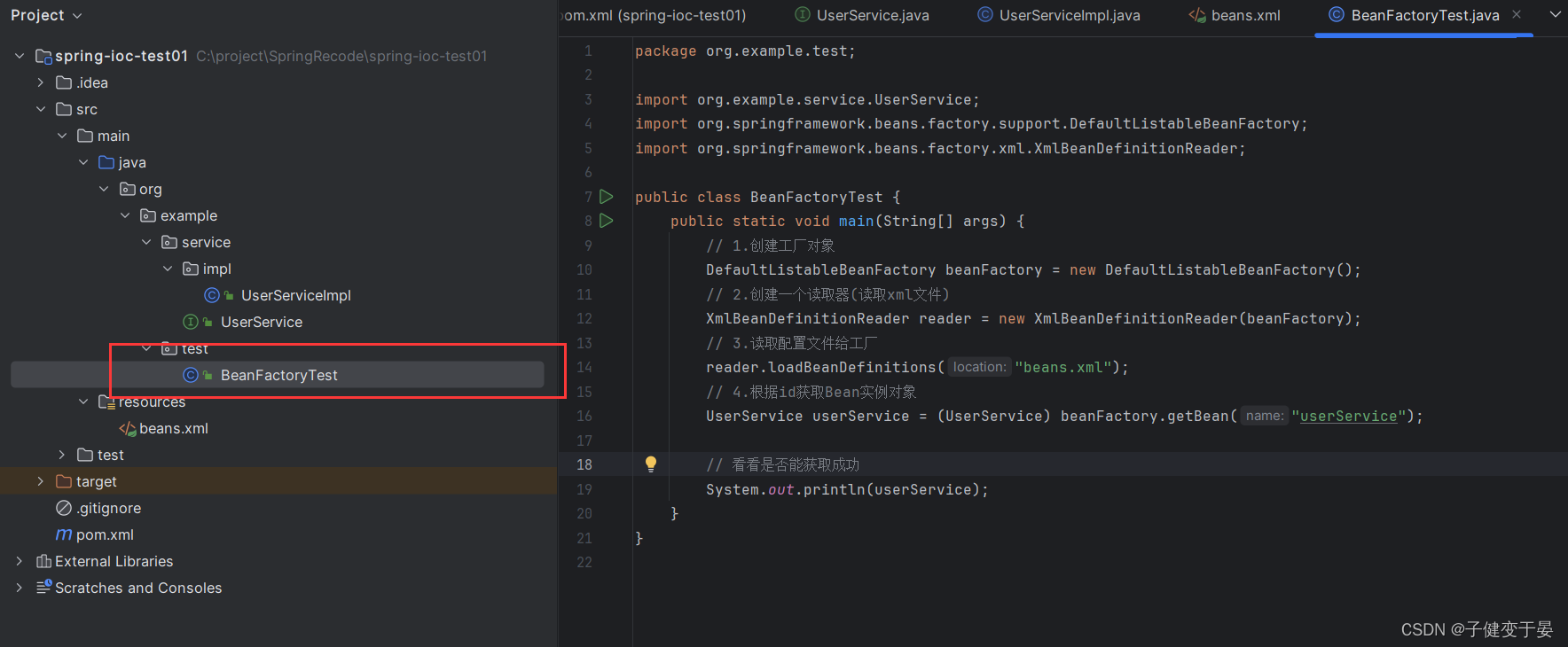
运行发现可以获取到

接下来我们用同样的方法配置UserDaoImpl

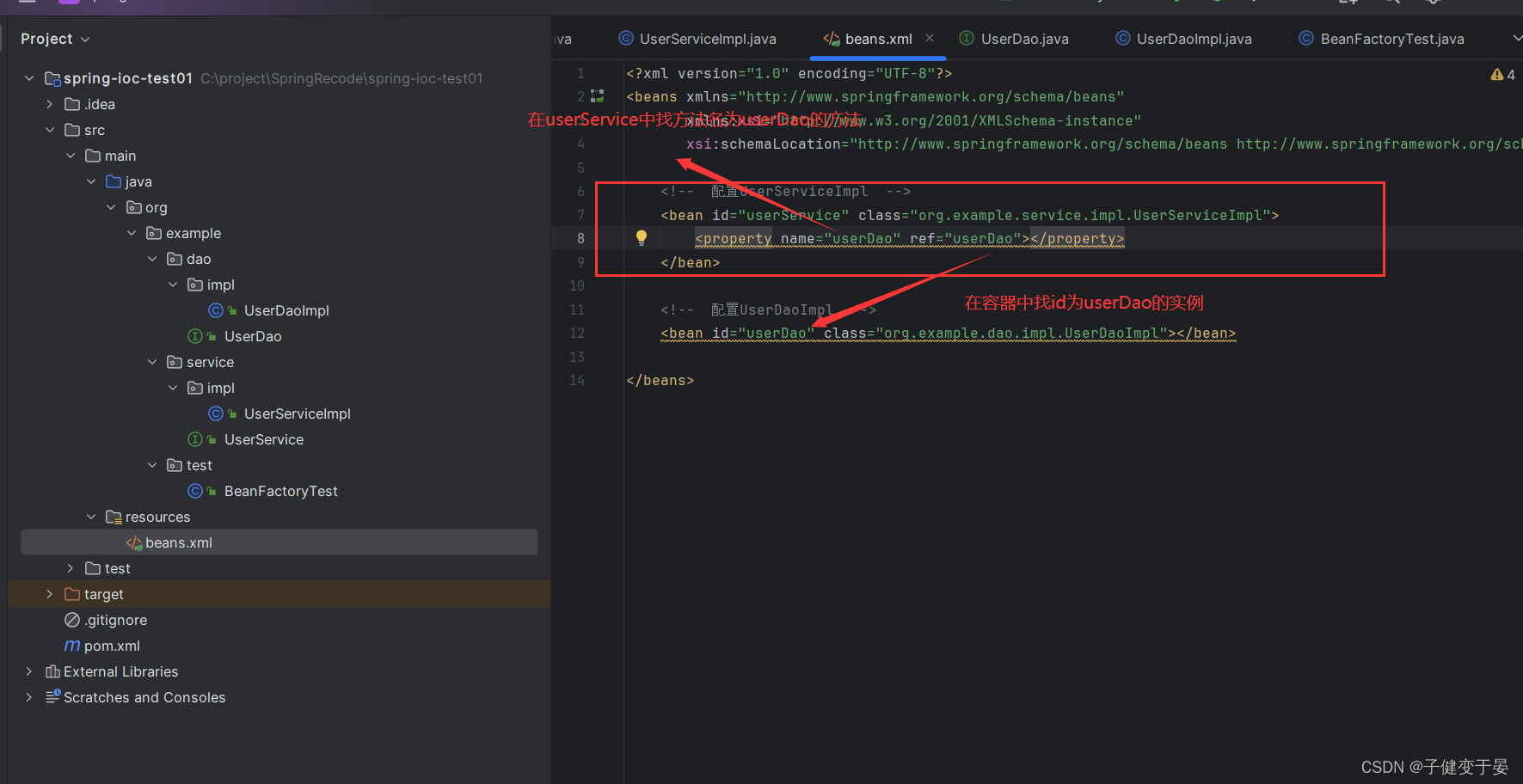
这个时候我们就可以学习DI思想了,我们知道在开发时,应该严格遵守JavaEE三层架构,就是说Service应该依赖于Dao,而在Spring中我们有DI(依赖注入)这个思想,那么我们就可以直接在Bean工厂内部把Dao注给Service。
首先我们先在UserServiceImpl中提供一个set方法

接着光写个方法没有,我们需要告诉配置工厂

2. ApplicationContext快速入门
ApplicationContext称为Spring容器,内部封装了BeanFactory,比BeanFactory功能更加强大。
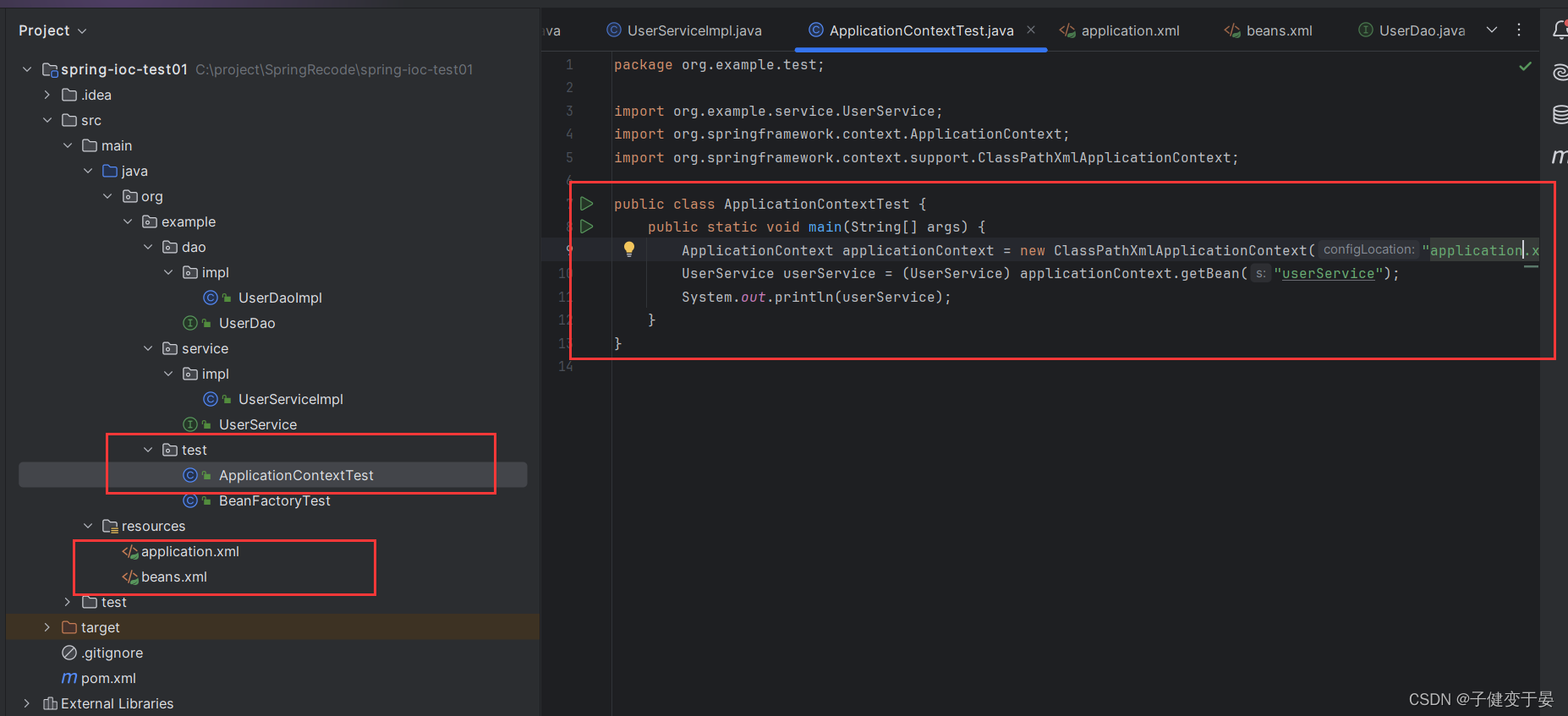

我们可以发现ApplicationContext实现起来比BeanFactory简单,并且还具有更强大的功能,所以后期主要使用这个进行开发。
3. BeanFactory和ApplicationContext的关系
<1> BeanFactory是Spring的早期接口,称为Spring的Bean工厂,ApplicationContext是后期更高级的接口,称为Spring容器。
<2> ApplicationContext在BeanFactory基础上对功能进行了扩展:监听功能、国际化功能等。BeanFactory API更偏向底层,ApplicationContext的API大多数是对这些底层API的封装。
<3> Bean创建的主要逻辑和功能都被封装在BeanFactory中,ApplicationContext不仅继承了BeanFactory,而且内部还维护着BeanFactory的引用。
<4> Bean的初始化时机不同,原始BeanFactory是在首次调用getBean时才进行Bean创建,而ApplicationContext是配置文件加载,容器一创建就将Bean都实例化并初始化好。
基于xml的Spring应用
1. SpringBean的配置详解
1.1 Bean的基本配置
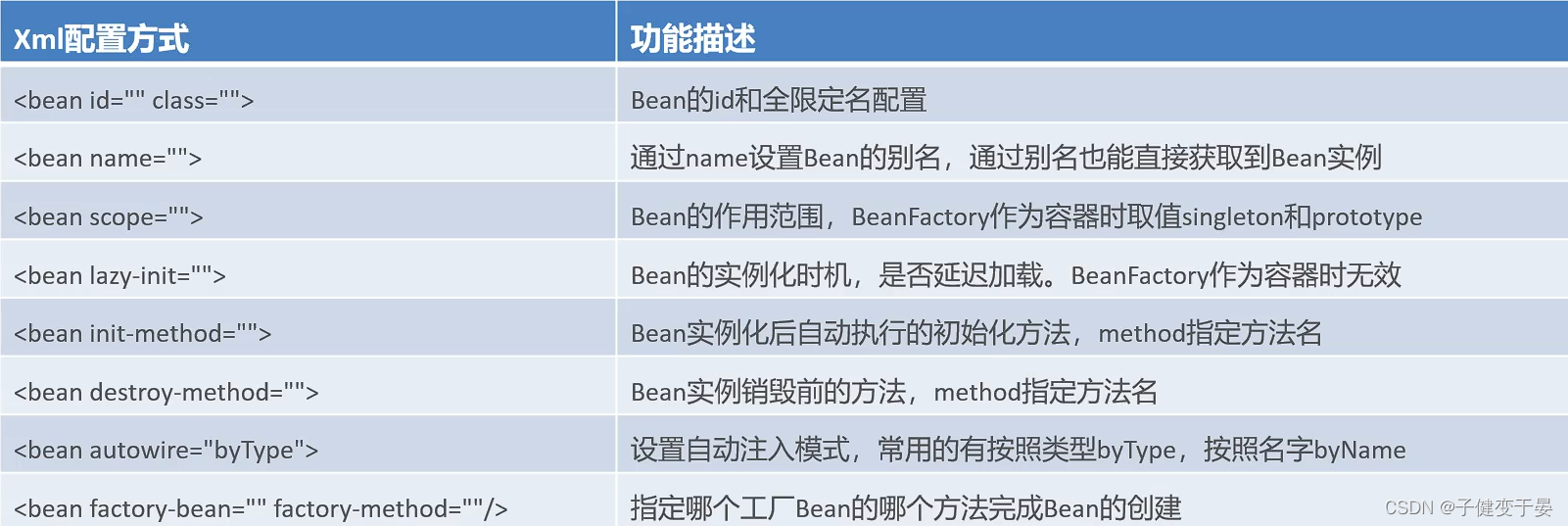
<1> <bean id="" class="">这个是最基本的配置,表示Bean的id和全限定名配置,但是这里有需要注意的点:这个id其实是beanName,而我们在getBean的时候也是使用beanName进行寻找的,那么这里就有一个疑问,能不能没有id?答案其实是可以的,如果没有id的话beanName默认是全限定名,这里的id是为了让我们更好的进行代码编写和管理。
接下来我们可以debug看看。
如果我们有配置id那么beanName就是id。
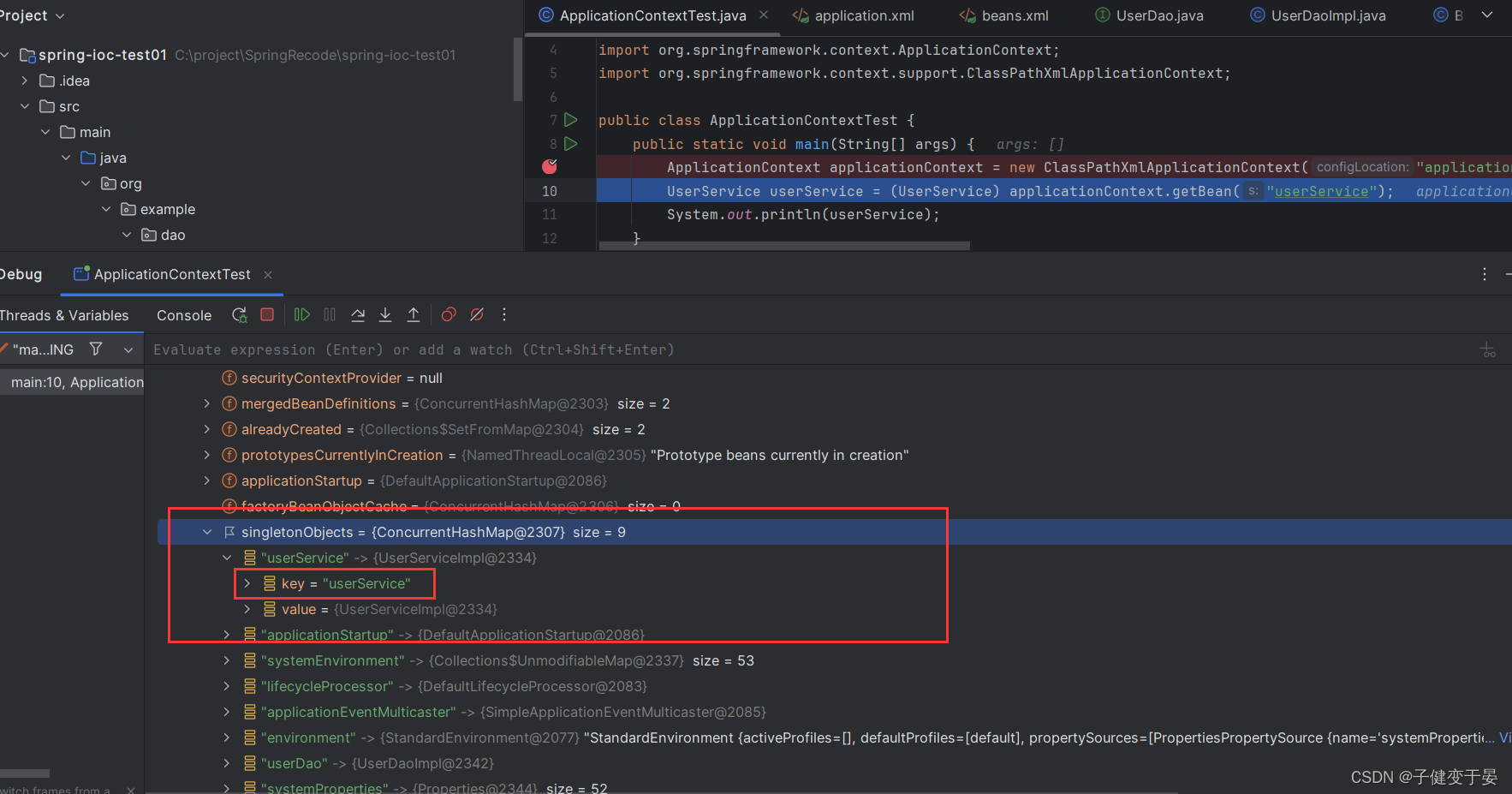
而如果我们没有配置id,那么beanName是全限定名。
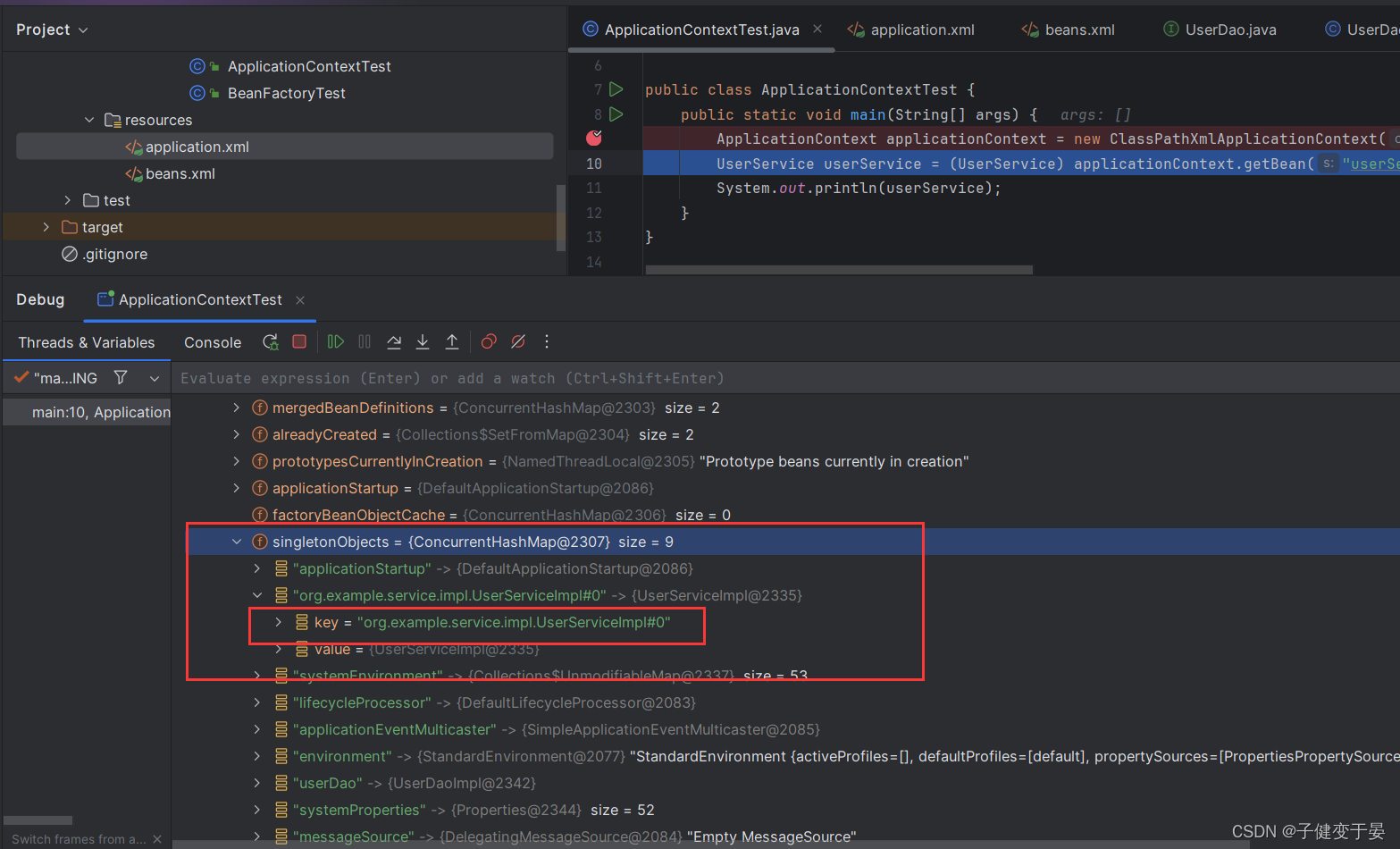
<2> <bean name="">配置了这个表示实例除了可以使用id获取,还可以用name别名获取。
比如
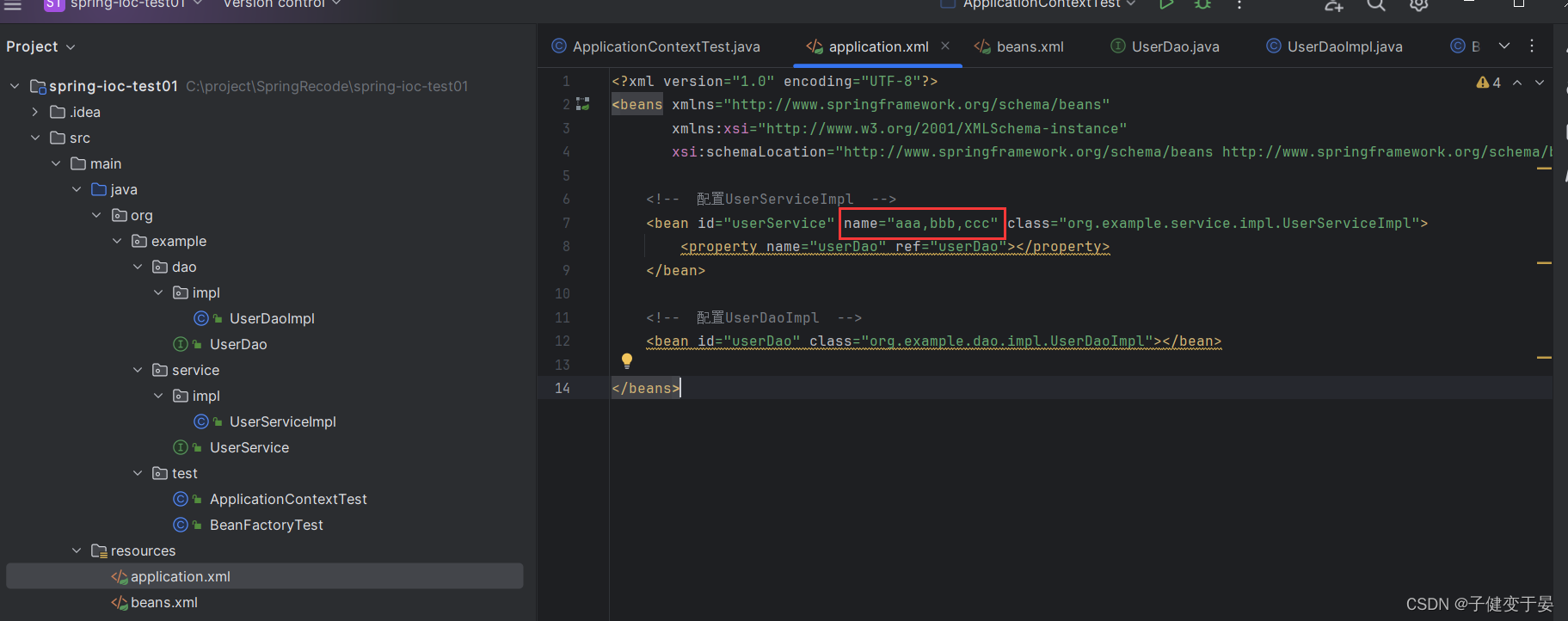

这样一样可以拿到对应的实例对象。
一样我们debug看看为什么可以通过别名获取。
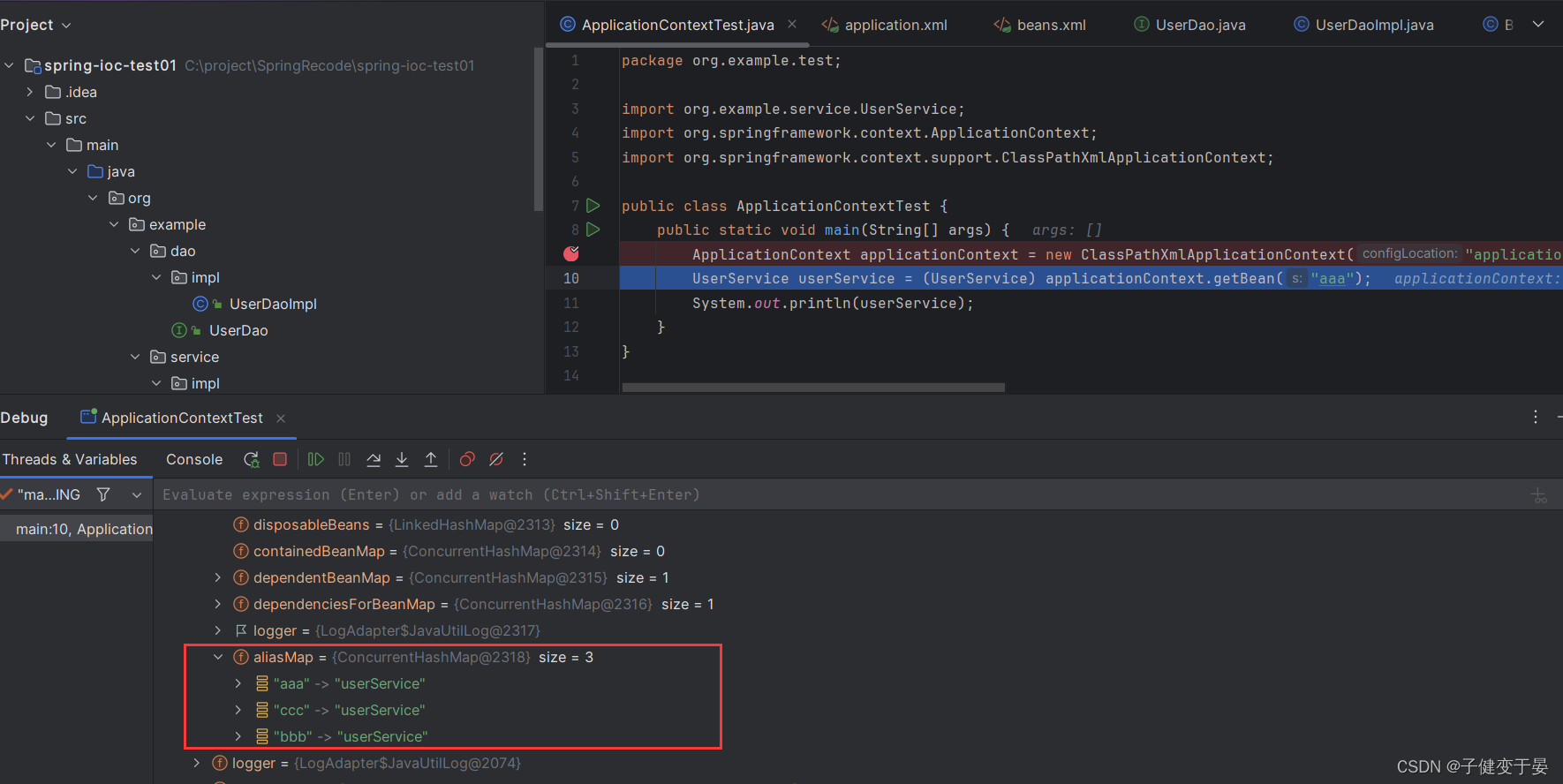
发现这些个别名都指向了beanName。
如果此时我们没有配置id,那么这里默认的beanName就是别名的第一个,也就是这里的aaa。
<3> <bean scope=""> 默认情况下Spring环境Bean的作用范围有两个:Singleton和Prototype
singleton:单例,默认值,Spring容器创建的时候,就会进行Bean的实例化,并存储到容器内部的单例池中,每次getBean时都是从单例池中获取相同的Bean实例。
prototype:原型,Spring容器初始化时不会创建Bean实例,当调用getBean时才会实例化Bean,每次getBean都会创建一个新的Bean实例。
这是没有配置scope的情况下,也就是默认的singleton,发现获取的都是相同的Bean实例
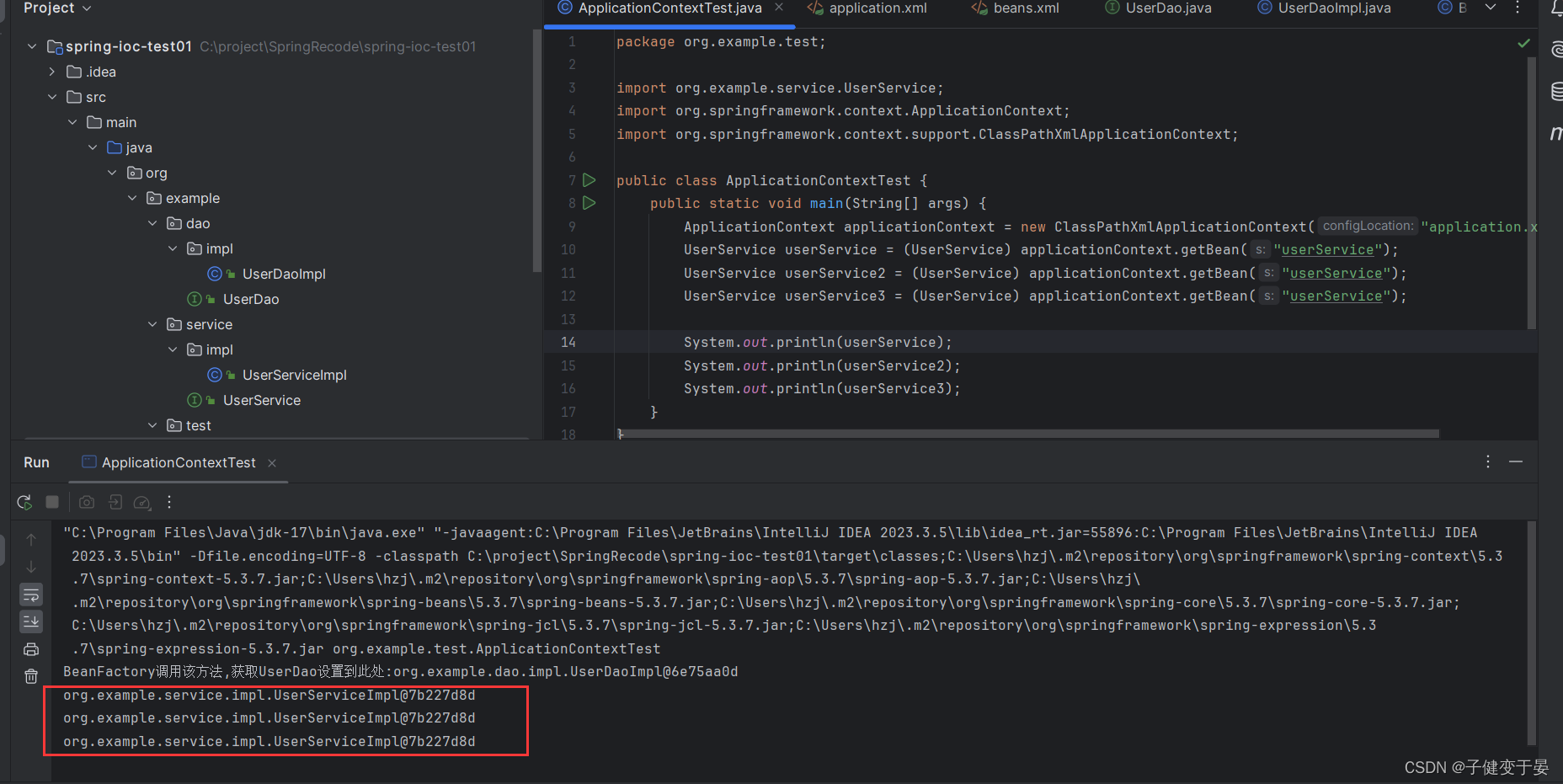
这是配置了scope="prototype" 原型模式的情况下,可以发现每个Bean都是不同的Bean
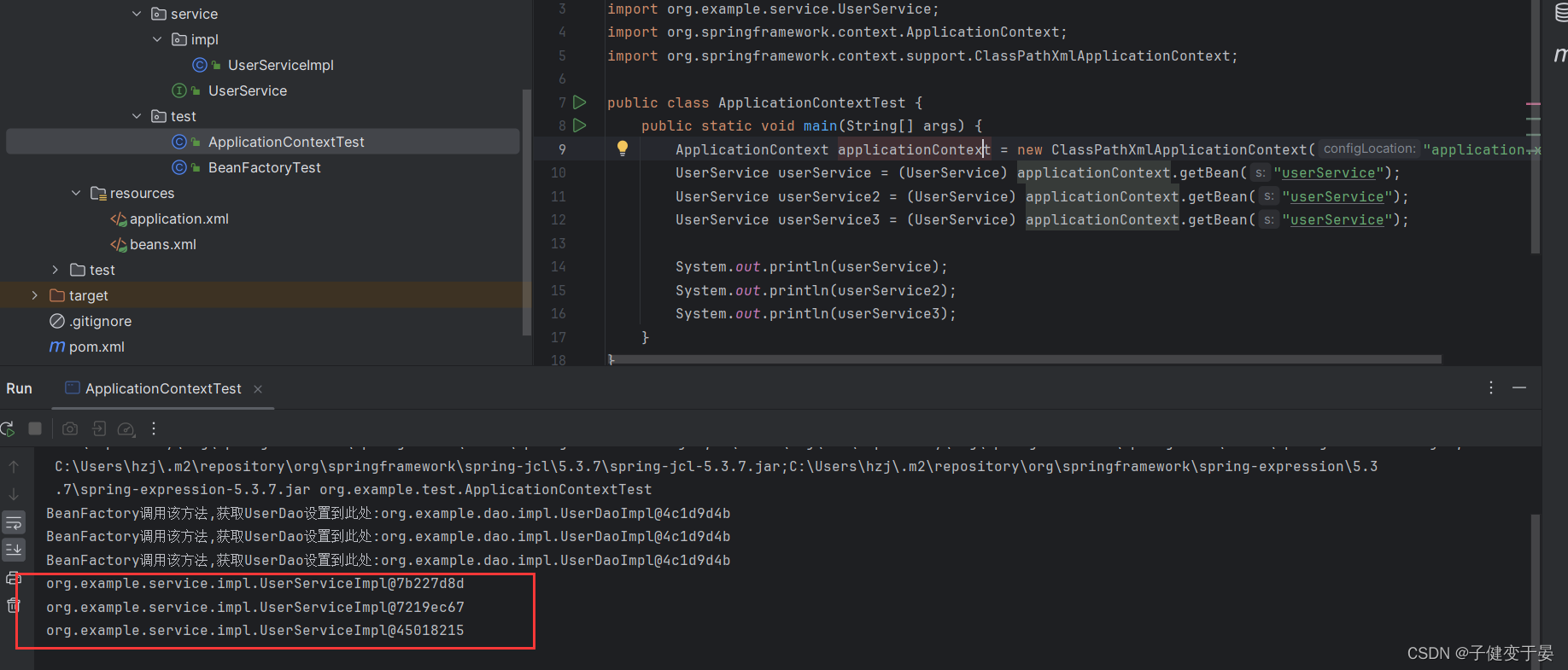
<4> <bean lazy-init="true"> Bean的延迟加载
我们知道ApplicationContext是加载配置文件的时候就将Bean创建了,而如果我们不想要立即创建Bean那么就可以用到这个配置。
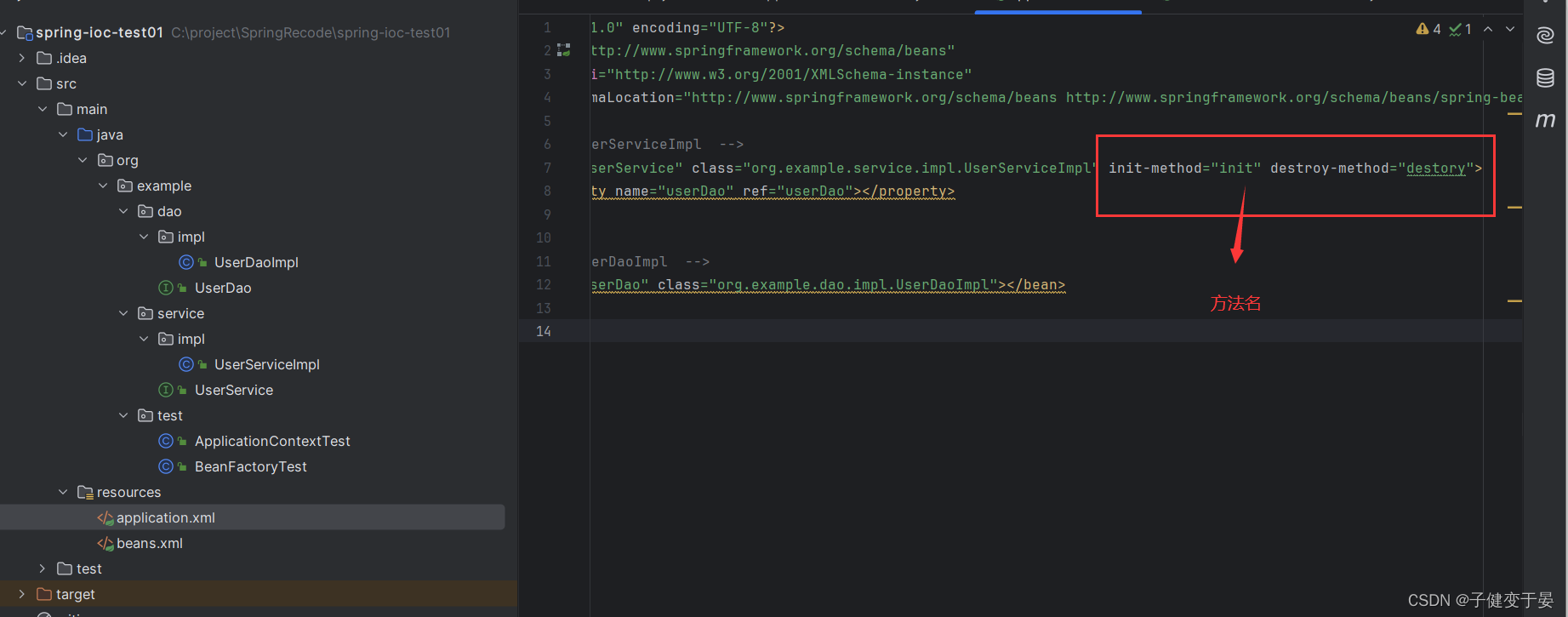
<5> <bean init-method="" destroy-method=""> Bean的初始化和销毁方法配置
首先我们先在实例对象中写初始化方法和销毁方法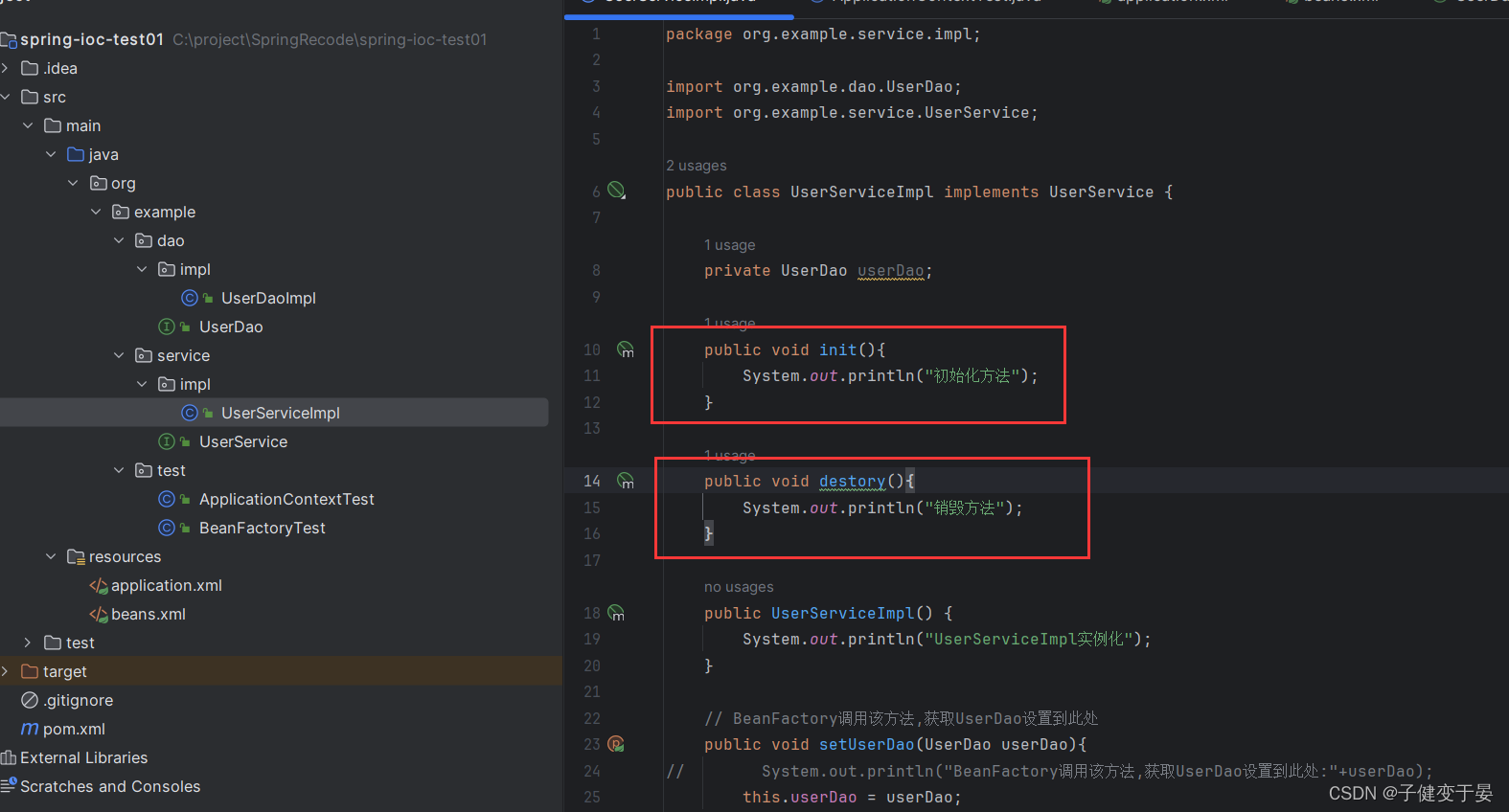 这样就只是个普通方法,我们还需要在xml中配置
这样就只是个普通方法,我们还需要在xml中配置
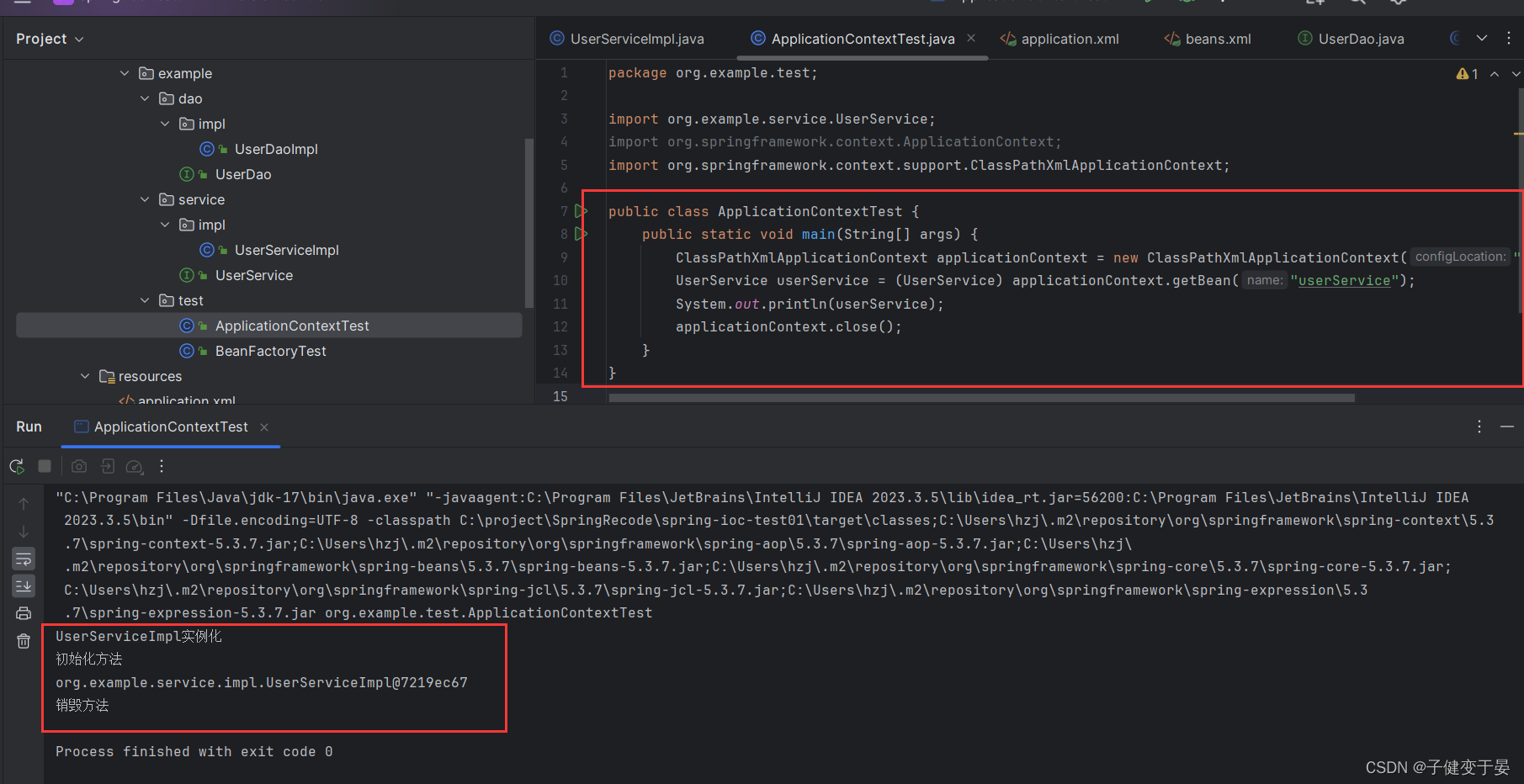
扩展:除了init-method方法进行初始化之外,还可以通过实现InitializingBean接口,完成Bean的初始化操作(实现InitializingBean接口调用afterPropertiesSet方法)。

我们可以看到这个方法是在对象实例化属性设置完毕后执行的
1.2 Bean的实例化方式
(1) 构造方法实例化
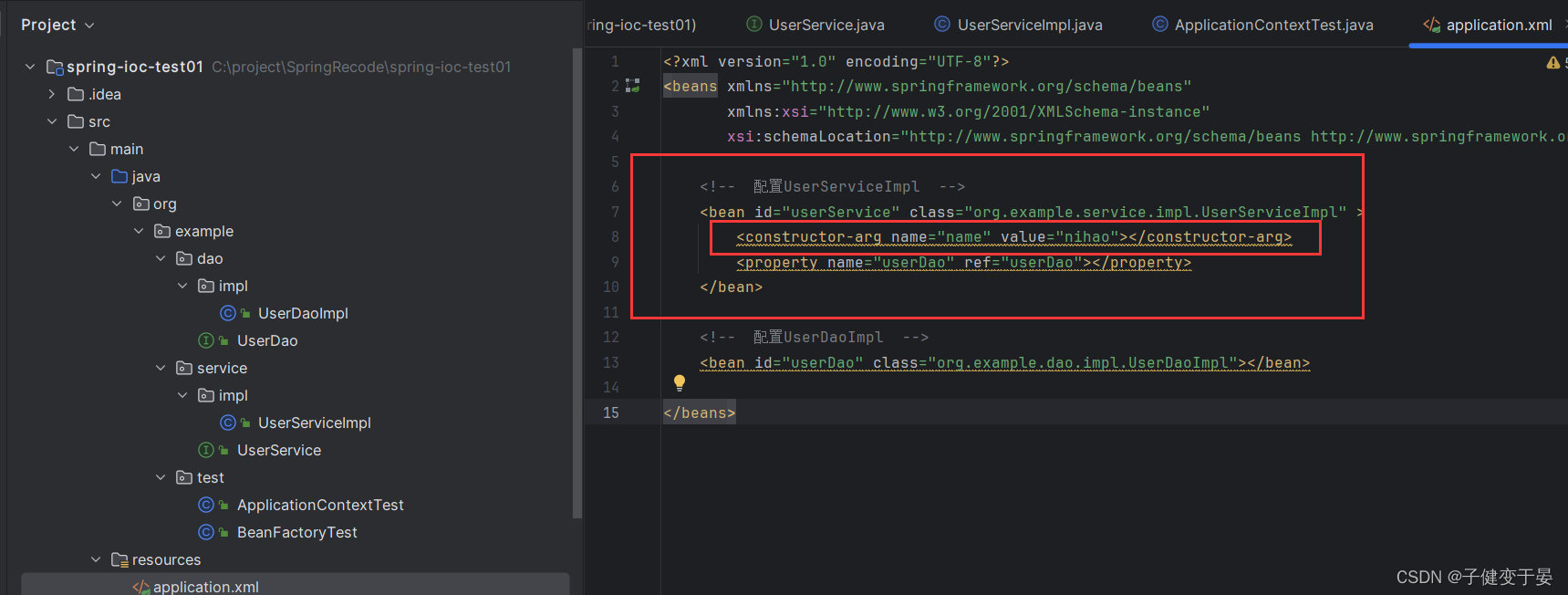
在上述我们默认用的都是无参的构造方法进行Bean的实例化,而大部分场景也确实是这样的,都是我们能否使用有参的构造方法呢?
当然也是可以的<constructor-arg name="" value="">
(2) 工厂方式实例化Bean
a. 静态工厂方法实例化Bean
首先我们创建一个工厂,写一个静态方法,返回值为UserServiceImpl对象
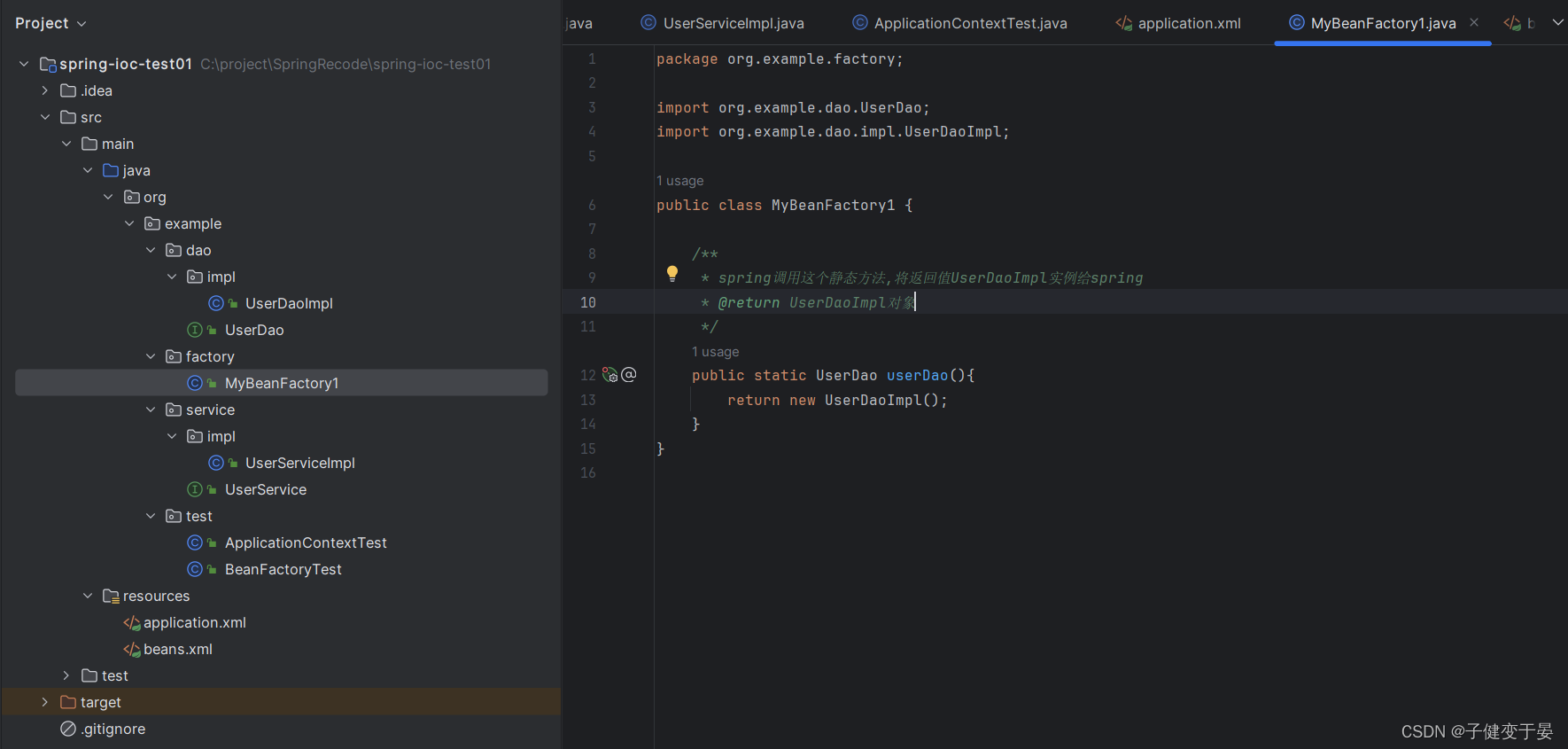
接着我们进行配置
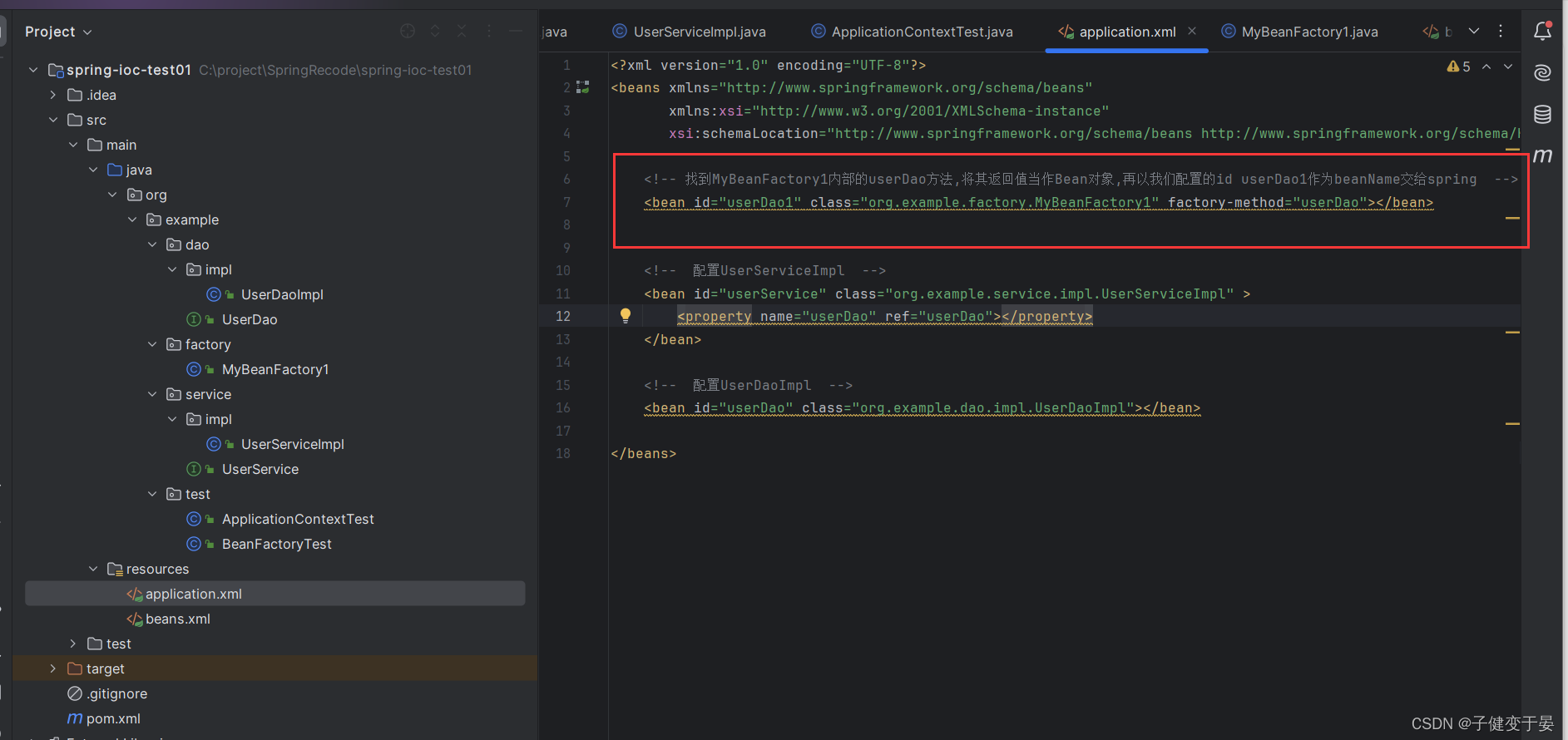
执行测试代码后就可以发现可以得到beanName 为 userDao1的对象
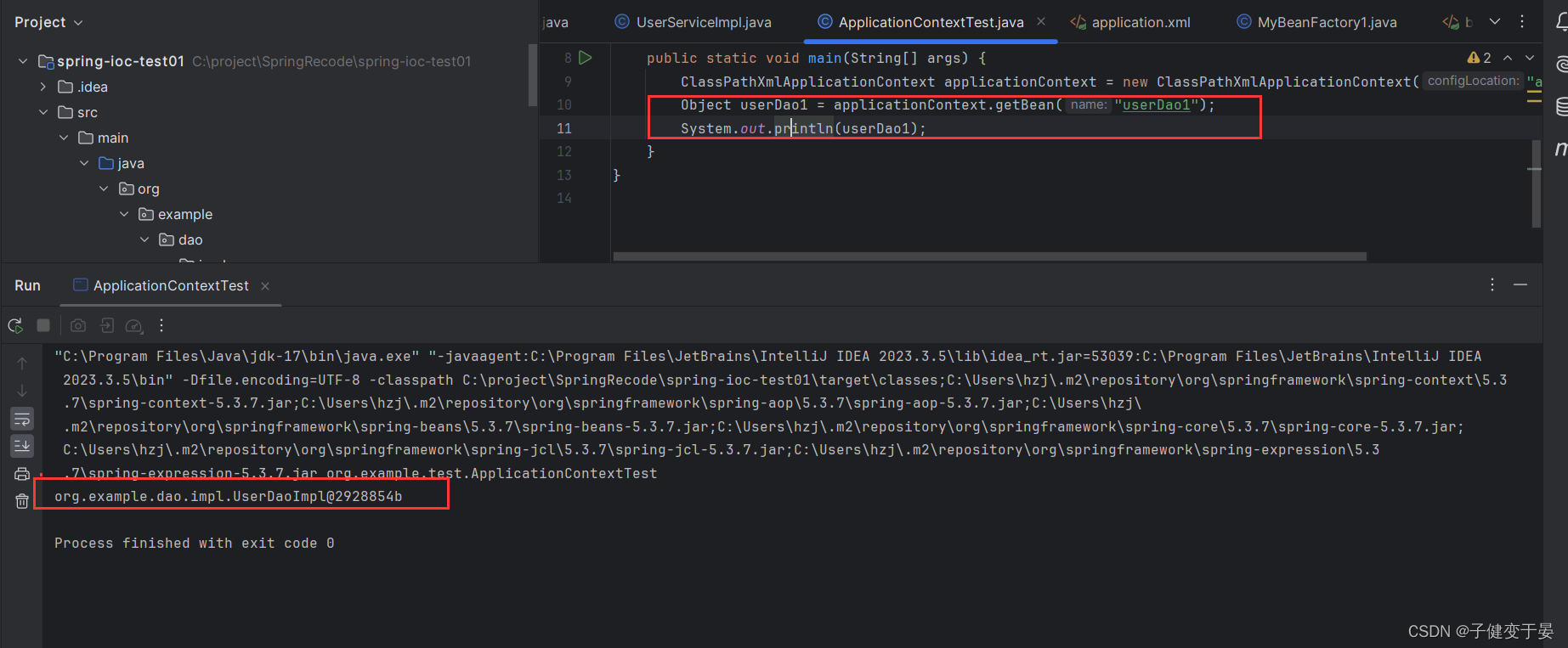
所以我们就可以明白这个配置是找到MyBeanFactory1中的userDao方法,将其返回值当作Bean对象,再以我们配置的id userDao1作为beanName交给spring。
使用这种方法的好处在于,我们可以在对象创建之前和创建之后进行一些操作,还有就是类似不属于spring的bean对象DriverManager.getConnection就是使用这种方式进行的。
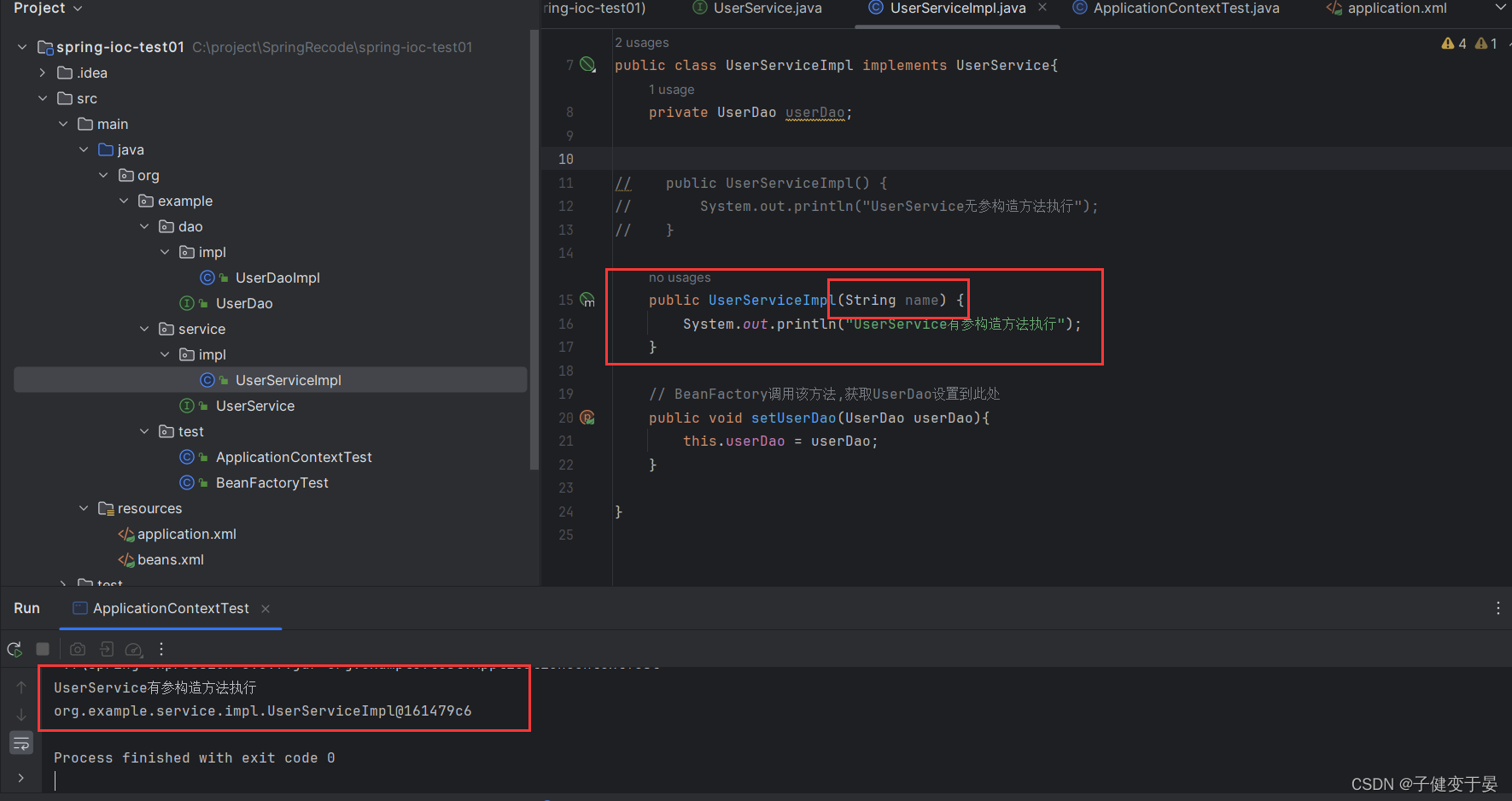
b. 实例工厂方法实例化Bean
我们还是一样先创建一个工厂MyBeanFactory2,且其中有一个实例方法,返回值一样是UserServiceImpl对象。
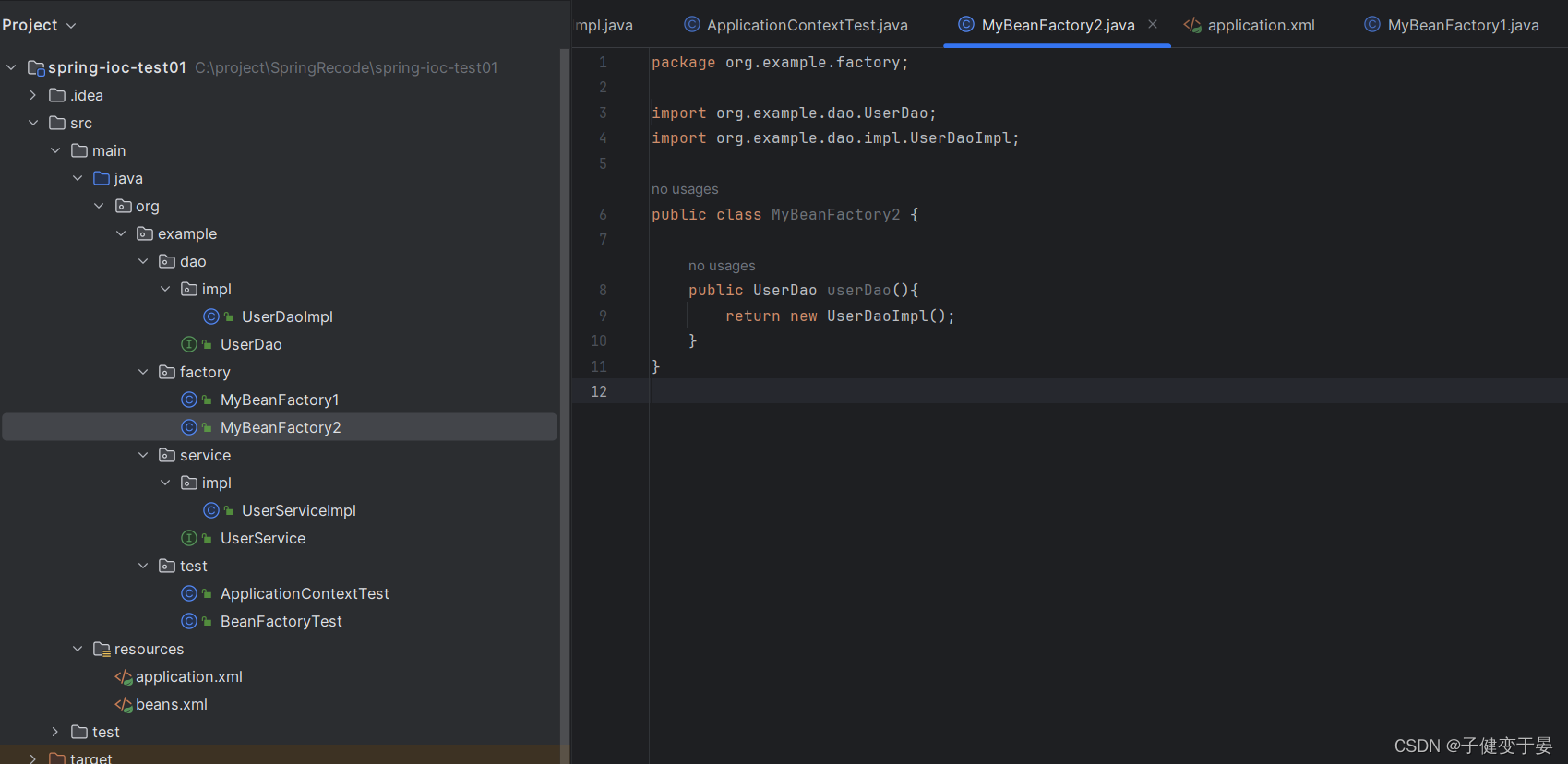
那么我们该如何配置呢?
先让我们想想看静态和实例的区别,我们知道静态我们可以不需要知道类直接调用方法,而实例我们必须要先知道其对应的类,再通过类调用方法。
所以这里的配置也是一样的,需要先将工厂配置进去,再配置其中的方法
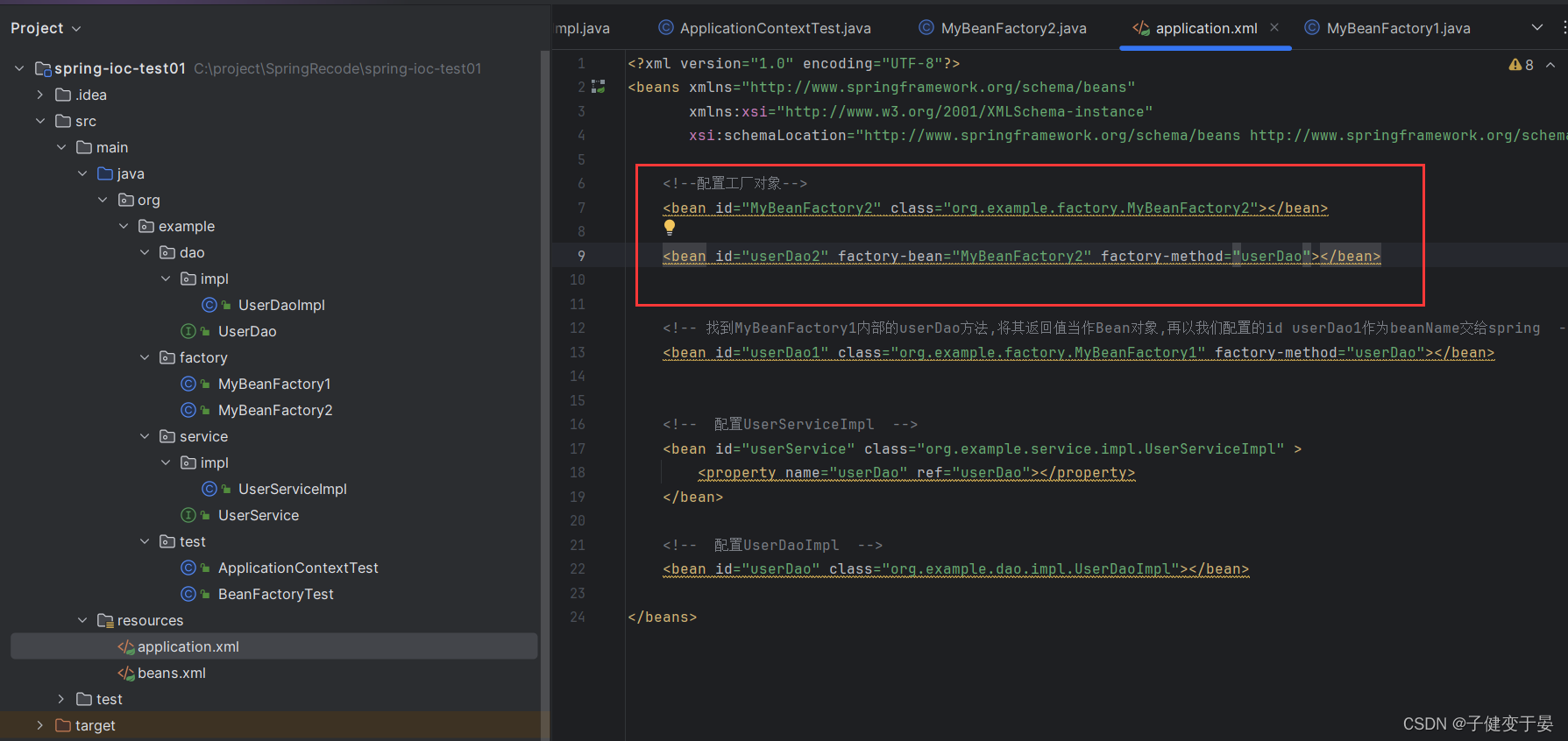
接着我们进行测试
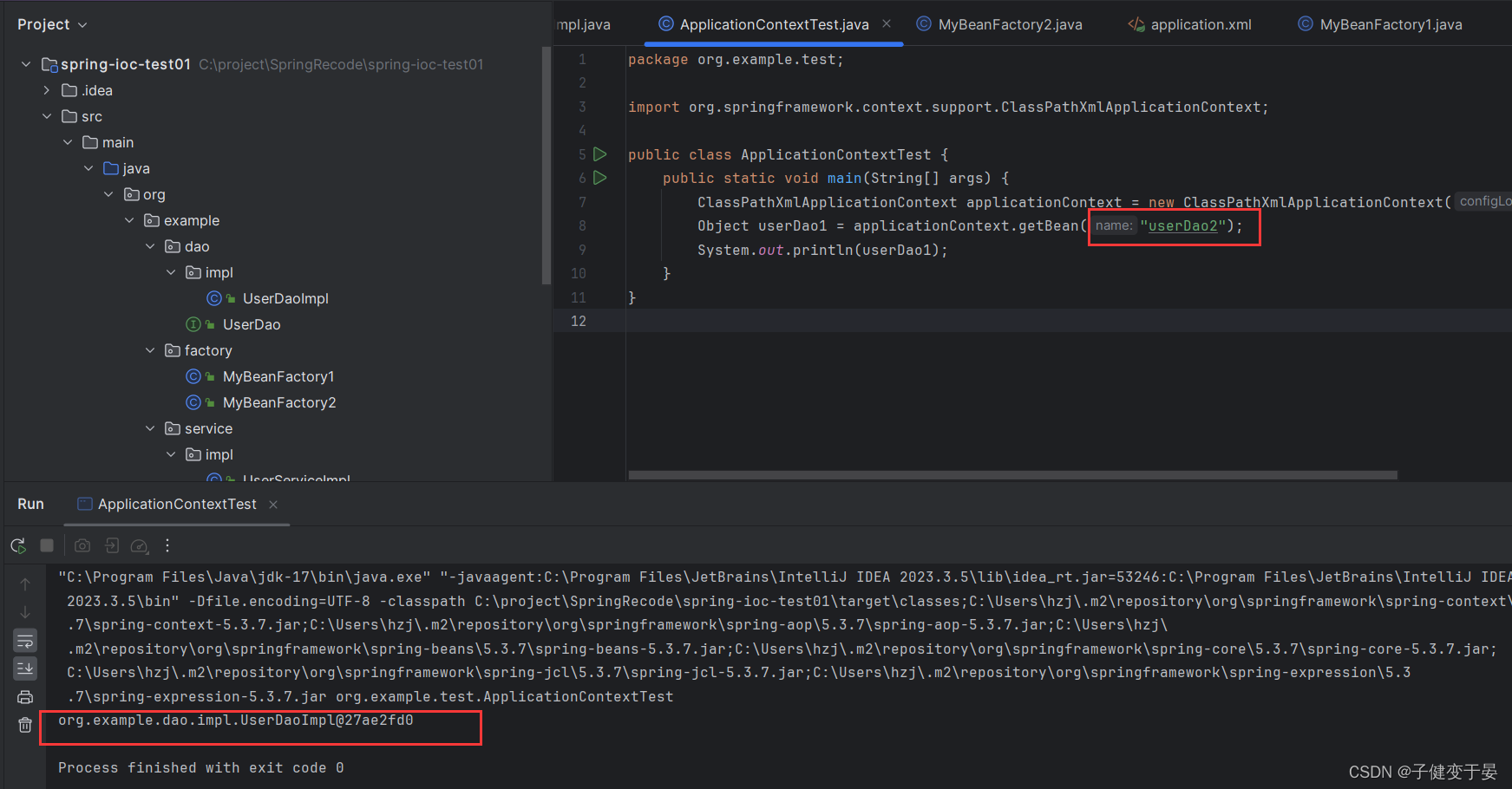

这种方法的好处也是可以在对象创建前以及创建之后进行一些操作,而且有些第三方Bean的产生并表示通过构造产生的,也是通过某些对象的方法产生的,那么就可以使用这种实例方法进行配置。
注意:这里我们写的都是没有参数的静态方法与实例方法,那么如何编写有参数的方法呢?其实使用<constructor-arg name="" value="">就可以实现,所以我们不能把constructor-arg这个配置想得太小,不只是构造方法,而是需要参数都可以使用。
c. 实现FactoryBean规范延迟实例化Bean
和上面一样我们先创建一个工厂,并且继承FactoryBean,重写其中的方法。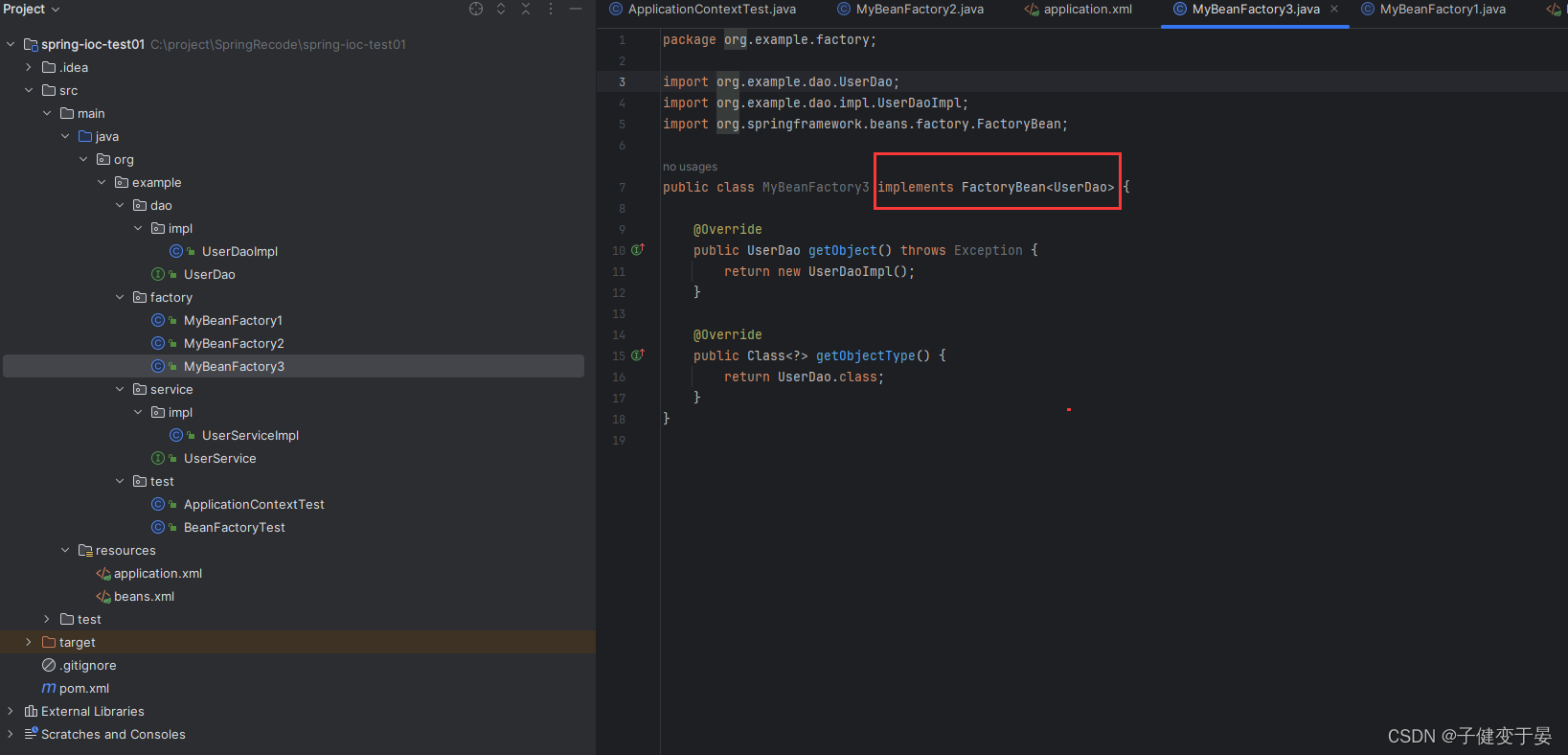
对其进行配置。

这里我们获取的实例对象不是MyBeanFactory3,而是他里面的getObject方法返回的对象。
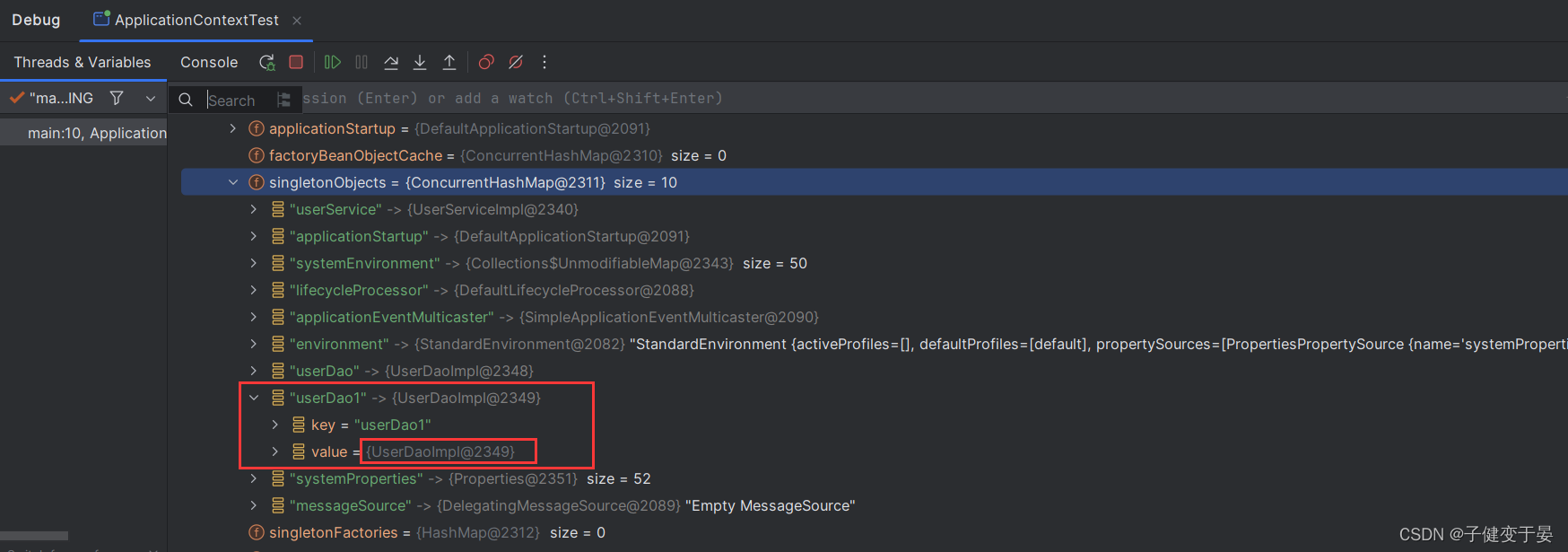
接着我们进行测试发现确实是拿到了UserDaoImpl,但是我们debug看看内部细节。

我们可以发现这里确实有一个beanName叫userDao3,但是它对应的value却不是UserDaoImpl,而是MyBeanFactory3,但是我们测试结果确确实实拿到了UserDaoImpl?
这里其实就是延迟实例化Bean的体现。
我们接着往下看。

我们从名字可以看出来这是一个缓存,意思就是这个UserDaoImpl缓存到了这里。
至于为什么说延迟是因为,我们在加载配置文件和创建Spring容器的时候,这里的getObject方法是没有调用的,当我们调用了getBean方法时,才将MyFactoryBean3中的getObject中返回的UserDaoImpl缓存到了这里。
之后如果还需要调用对应的beanName的方法,就可以不用创建,而是去缓存中取。
1.3 Bean的依赖注入配置
(1) 基本数据类型和引用数据类型
|-------------------|-----------------------------------------------------------------------------------------------|
| 注入方式 | 配置方式 |
| 通过Bean的set方法注入 | <property name="UserDao" ref="UserDao"/> <property name="UserDao" value="nihao"/> |
| 通过构造方法Bean的方法进行注入 | <constructor-arg name="name" ref="userDao"/> <constructor-arg name="name" value="nihao"/> |
其中ref用于引用其他Bean的id,value则是注入普通属性值。
但是我们要如何注入集合类型的数据呢?
首先我们先编写一个set注入List数据类型的方法。

接着我们对其进行配置,这里我们就有一个问题,基础数据类型我们用value,引用数据类型我们用ref,那么集合类型如何使用呢?
(2) List类型数据
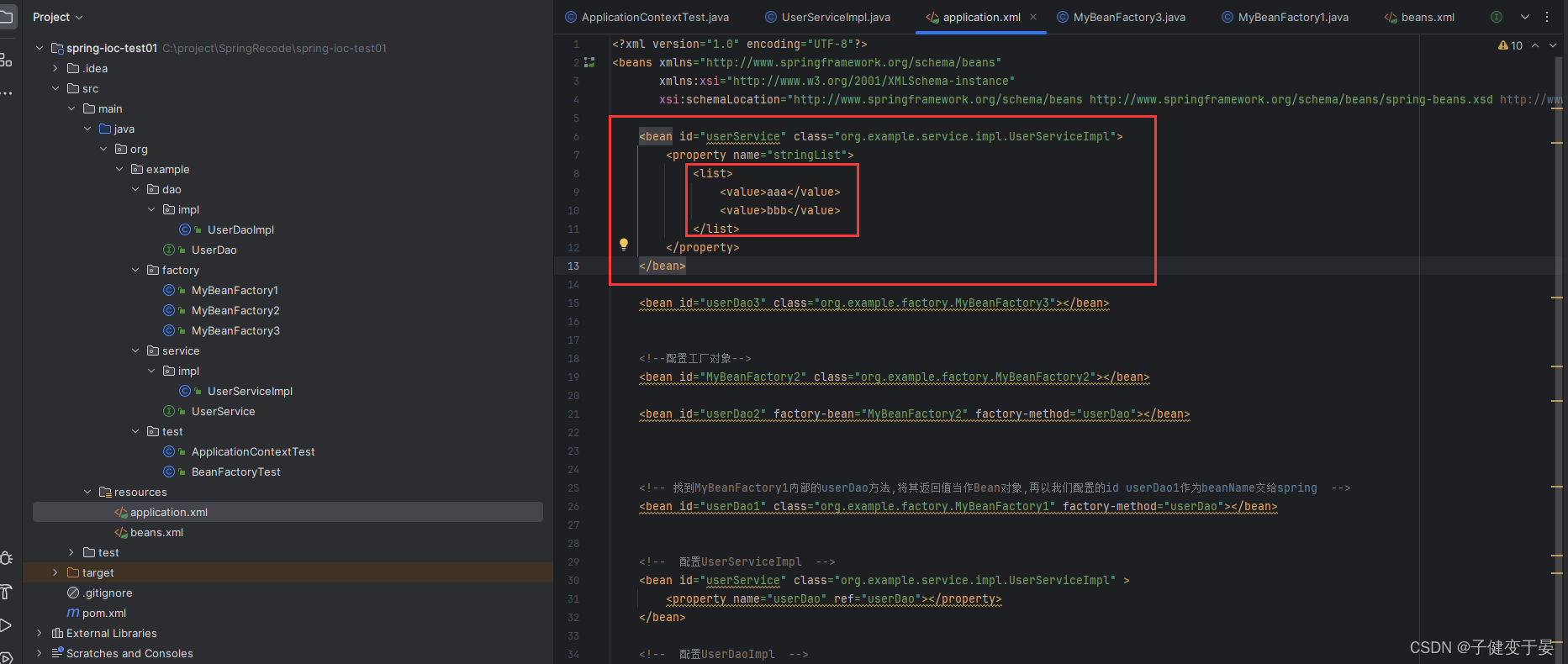
使用子标签list。
接着我们进行测试,发现可以注入。
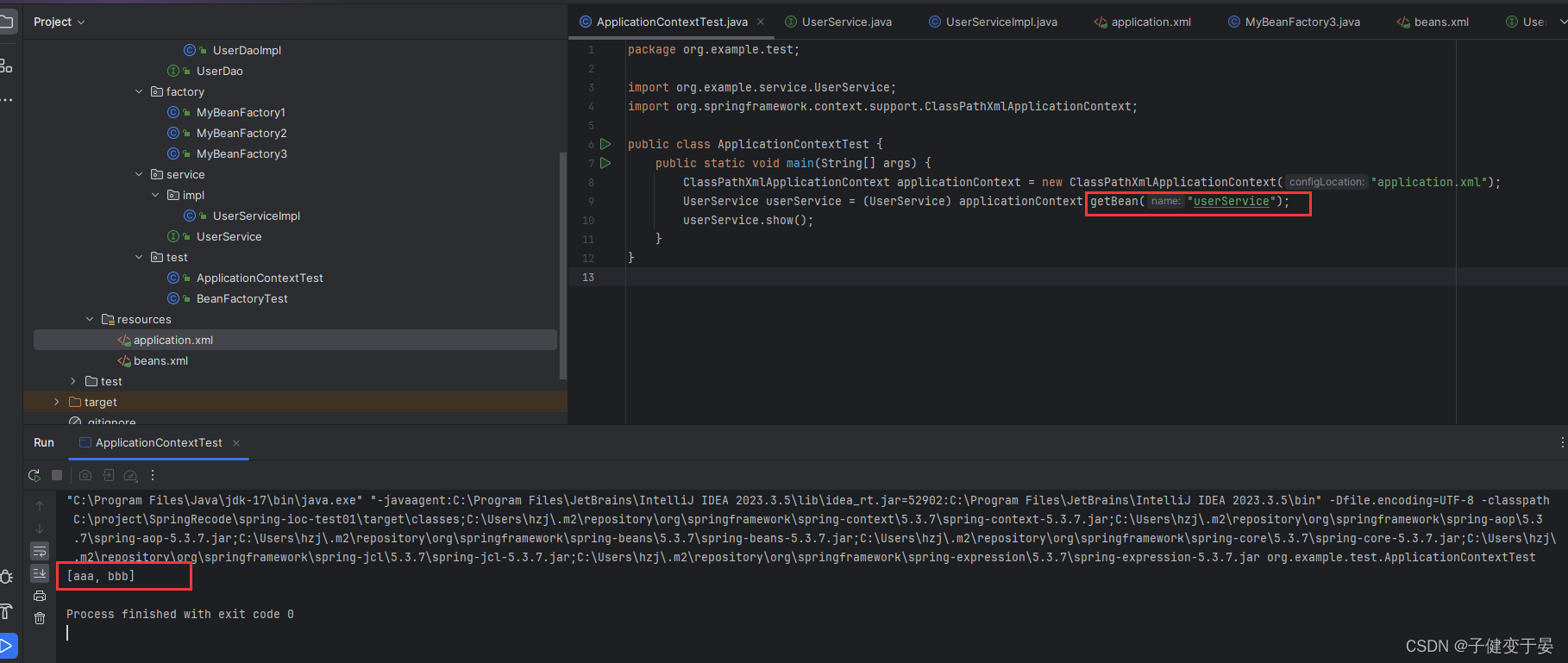
那么如果我们的List里面的的引用类型的呢?
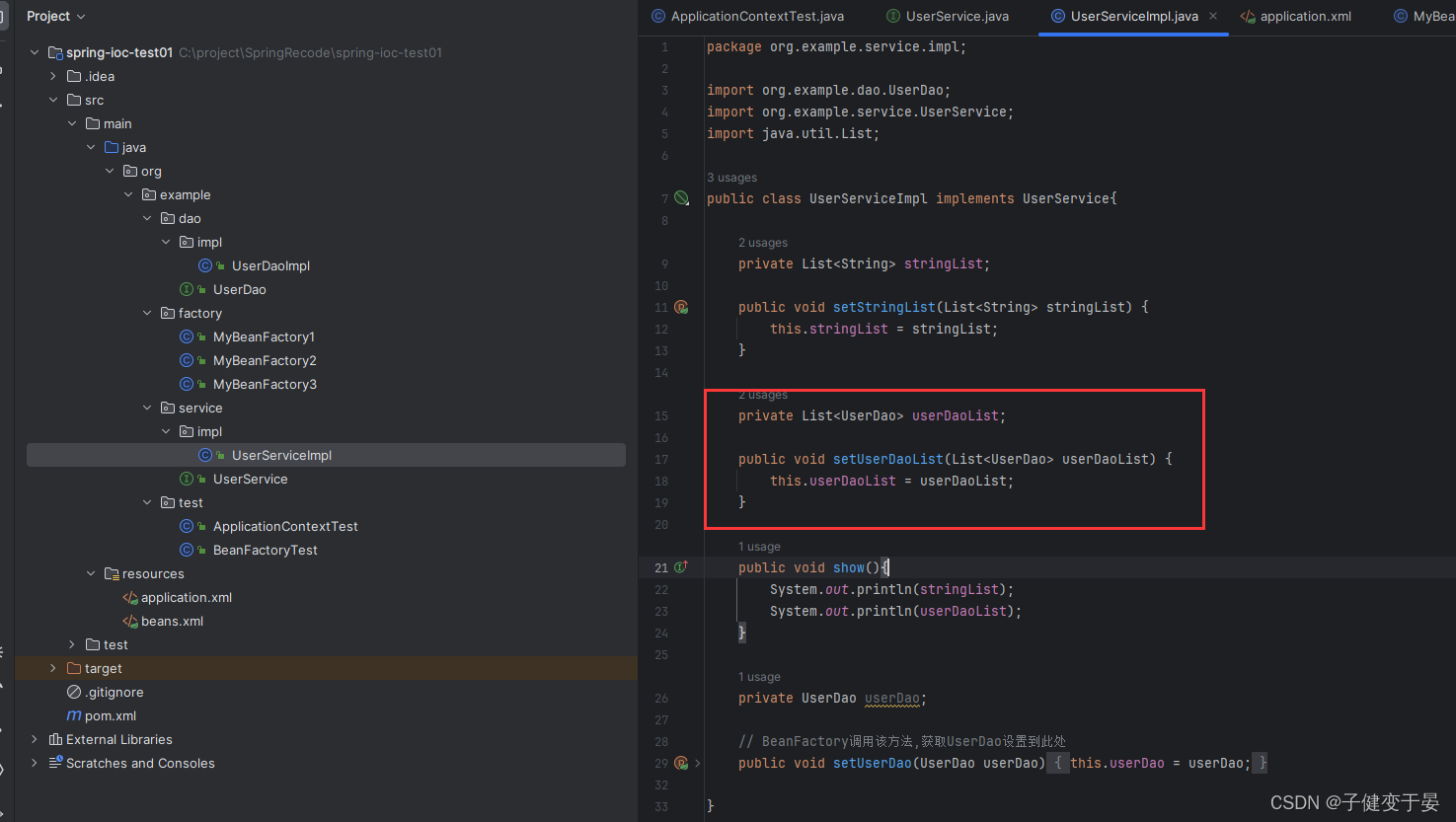
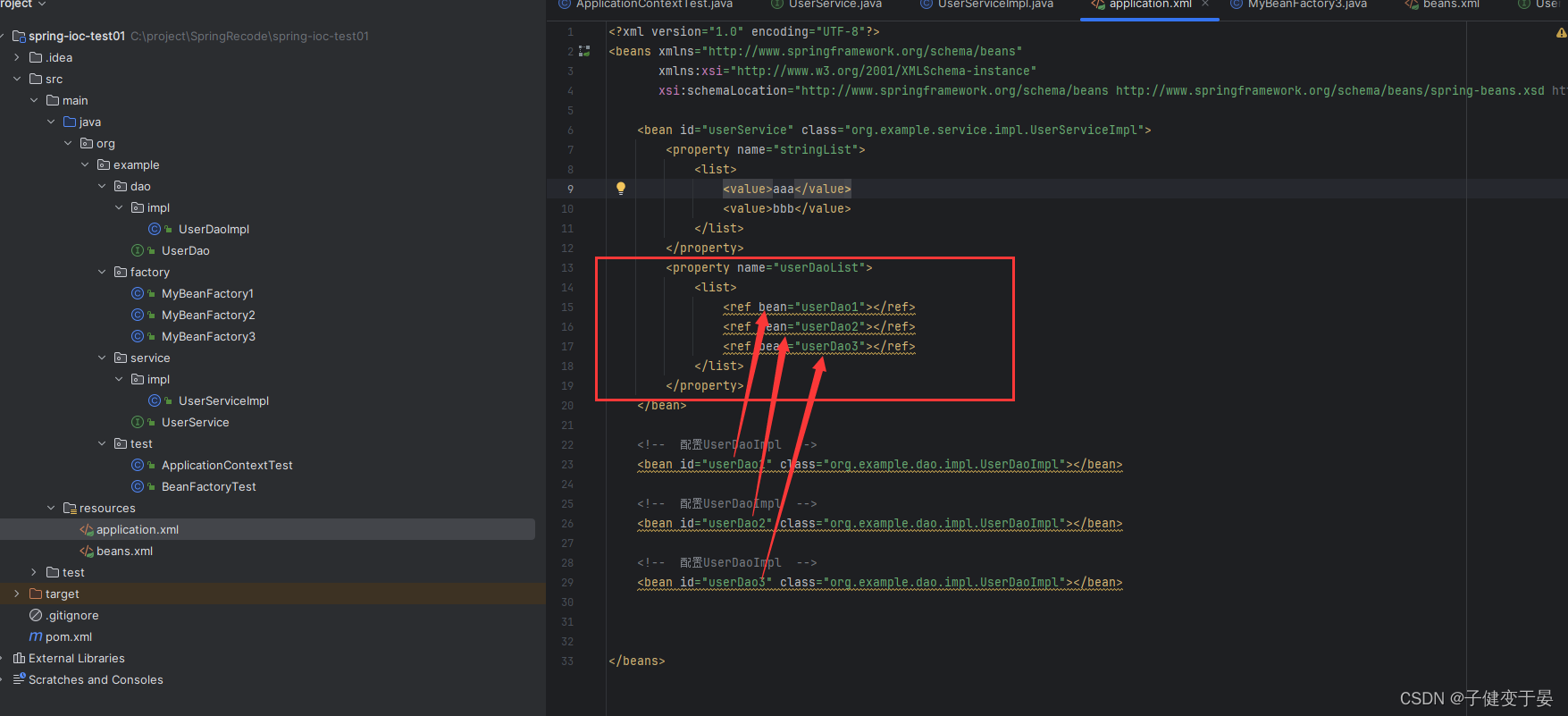
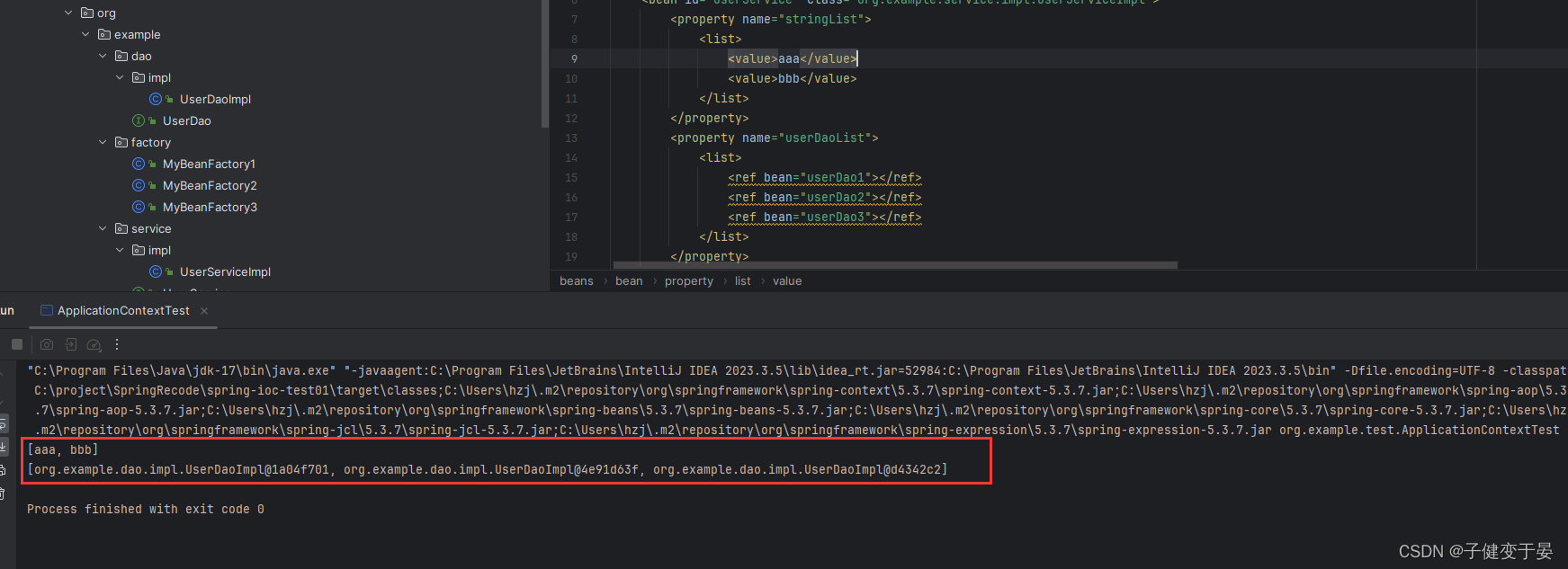
这就是List类型注入的配置。
接着我们把set和map类型的也一起来看看。
(3) Set类型数据
set类型的注入。
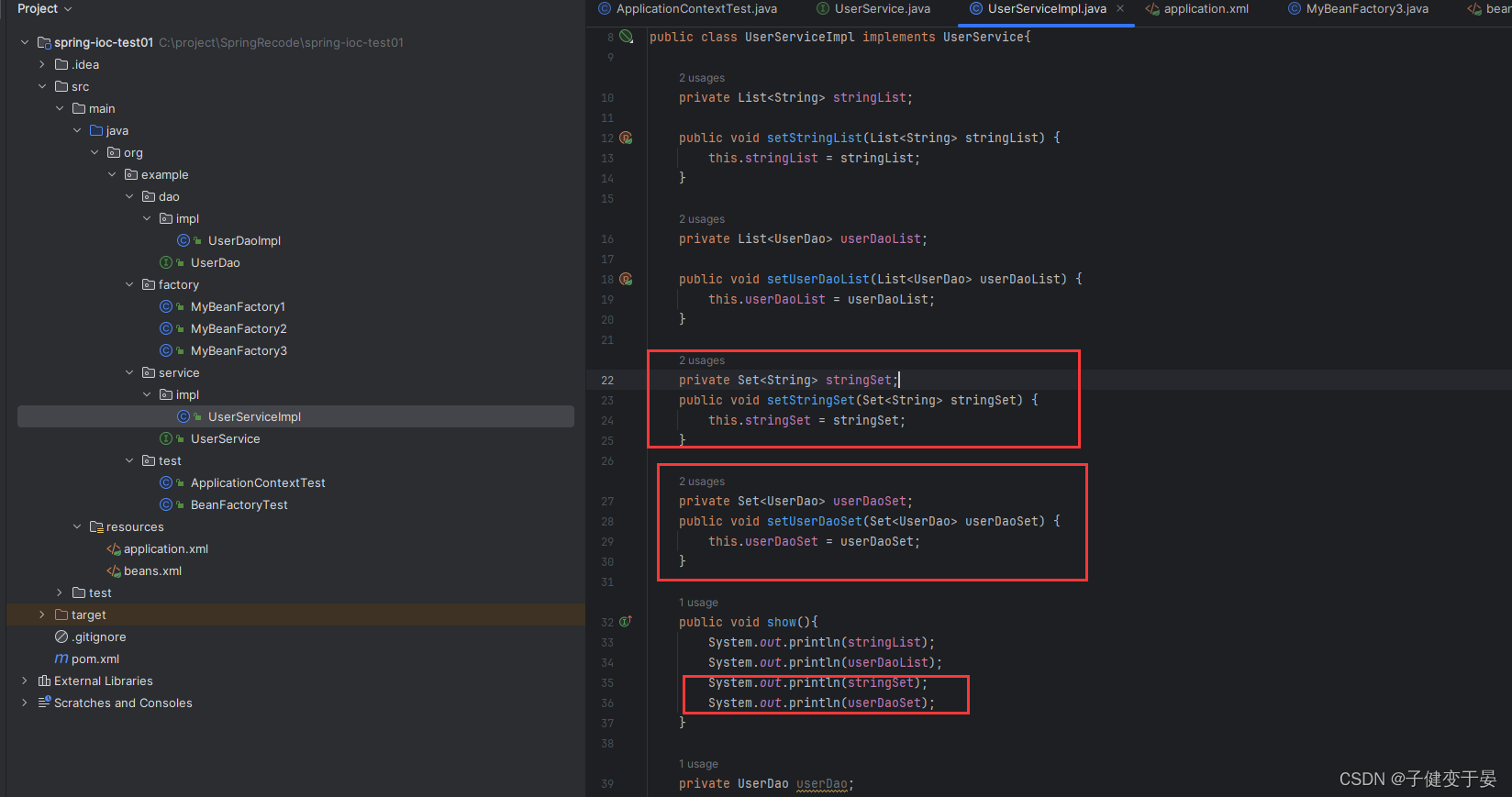

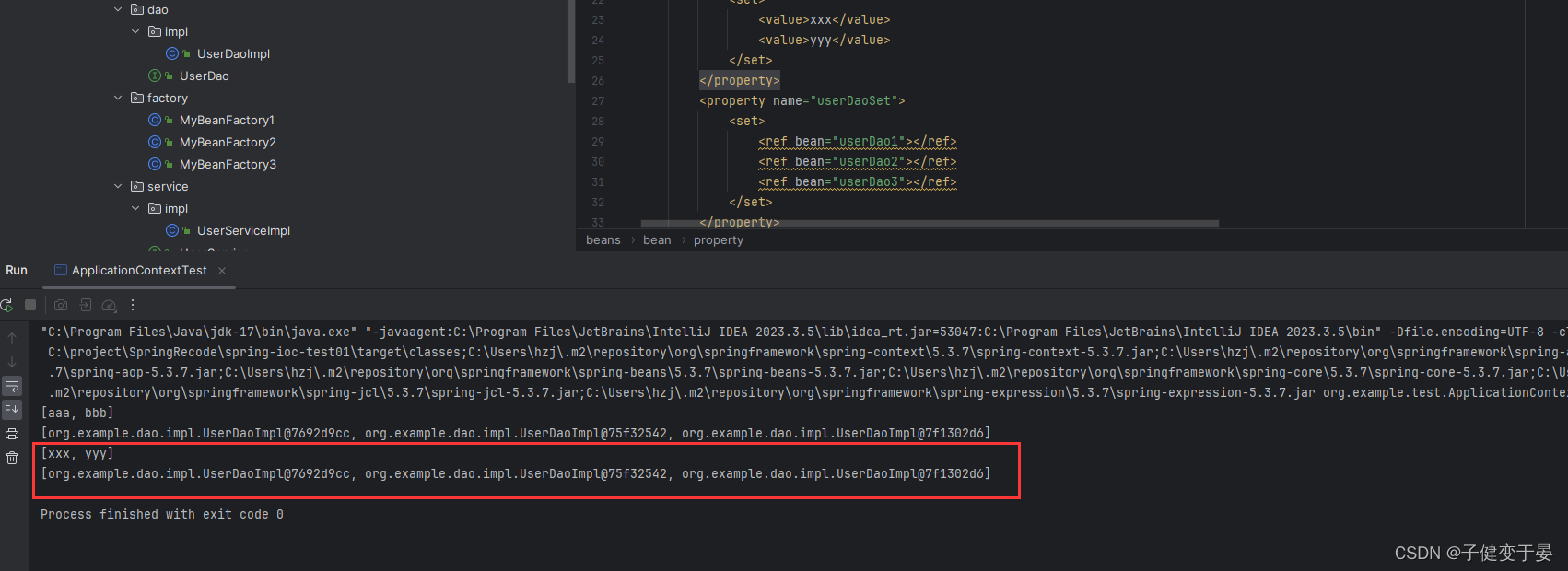
(4) Map类型数据
最后再看看map的。
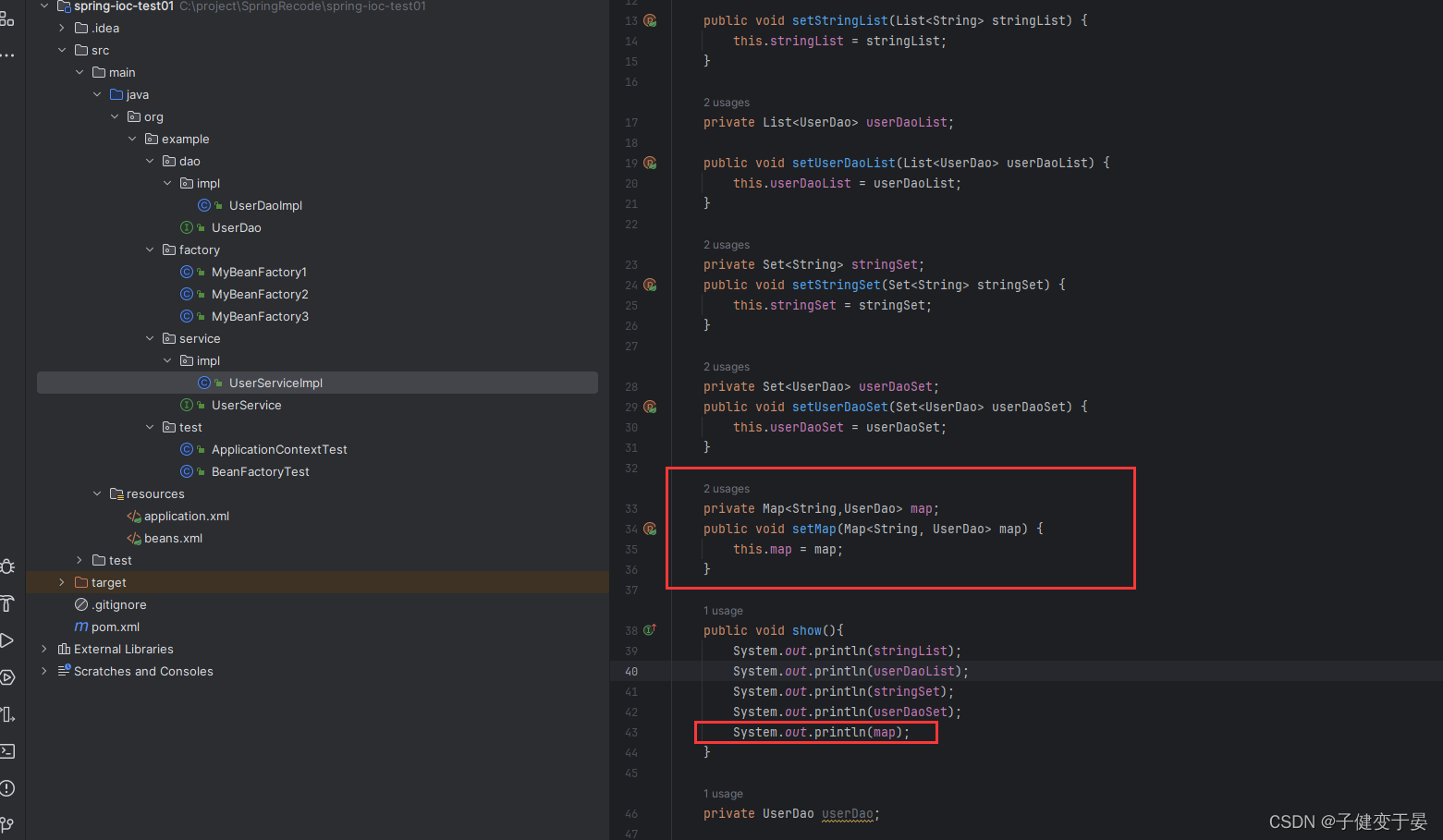
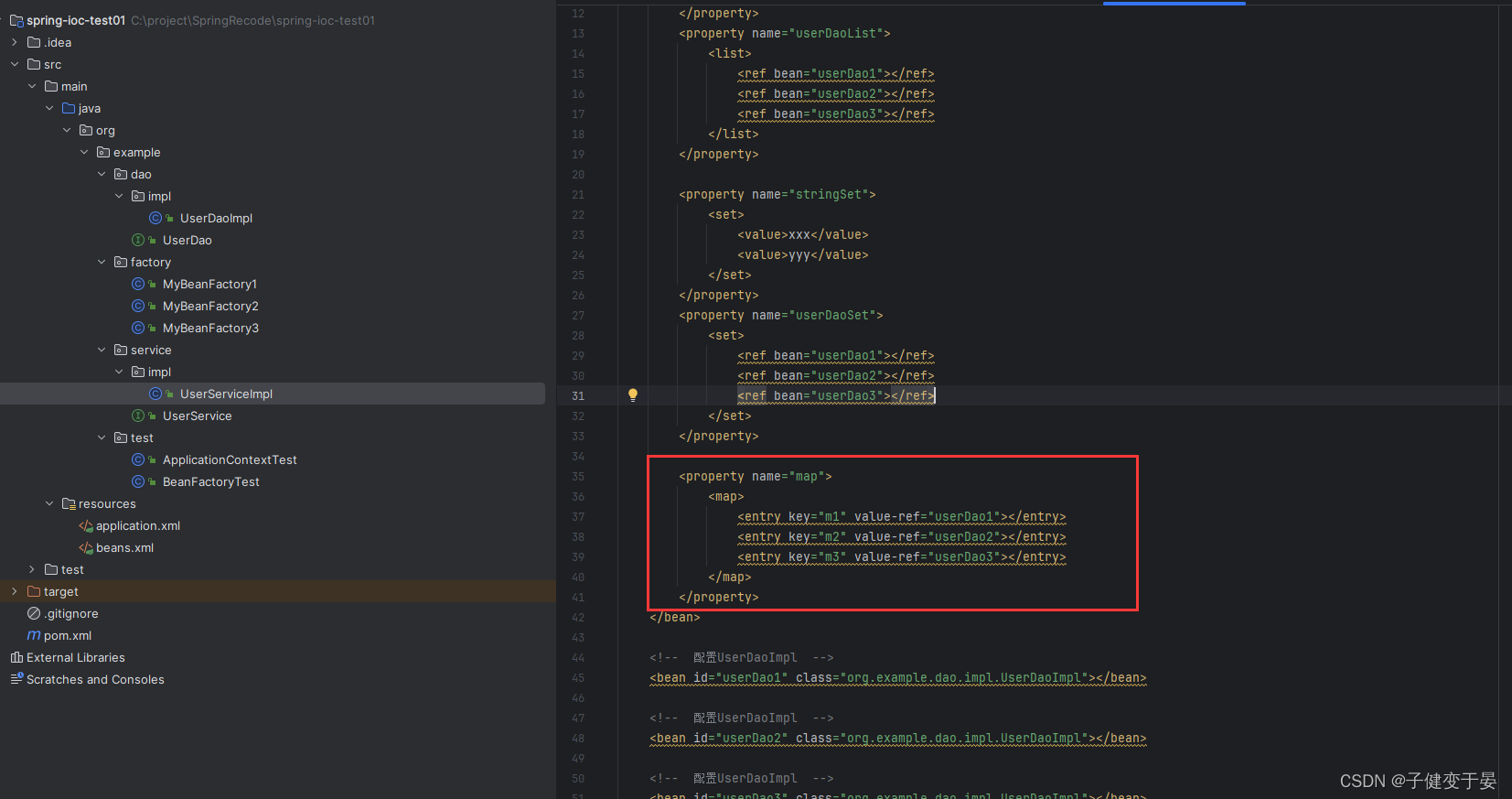
这里的entry里面为什么使用key和value-ref呢,因为这个map中键为基础数据类型而值是引用数据类型。
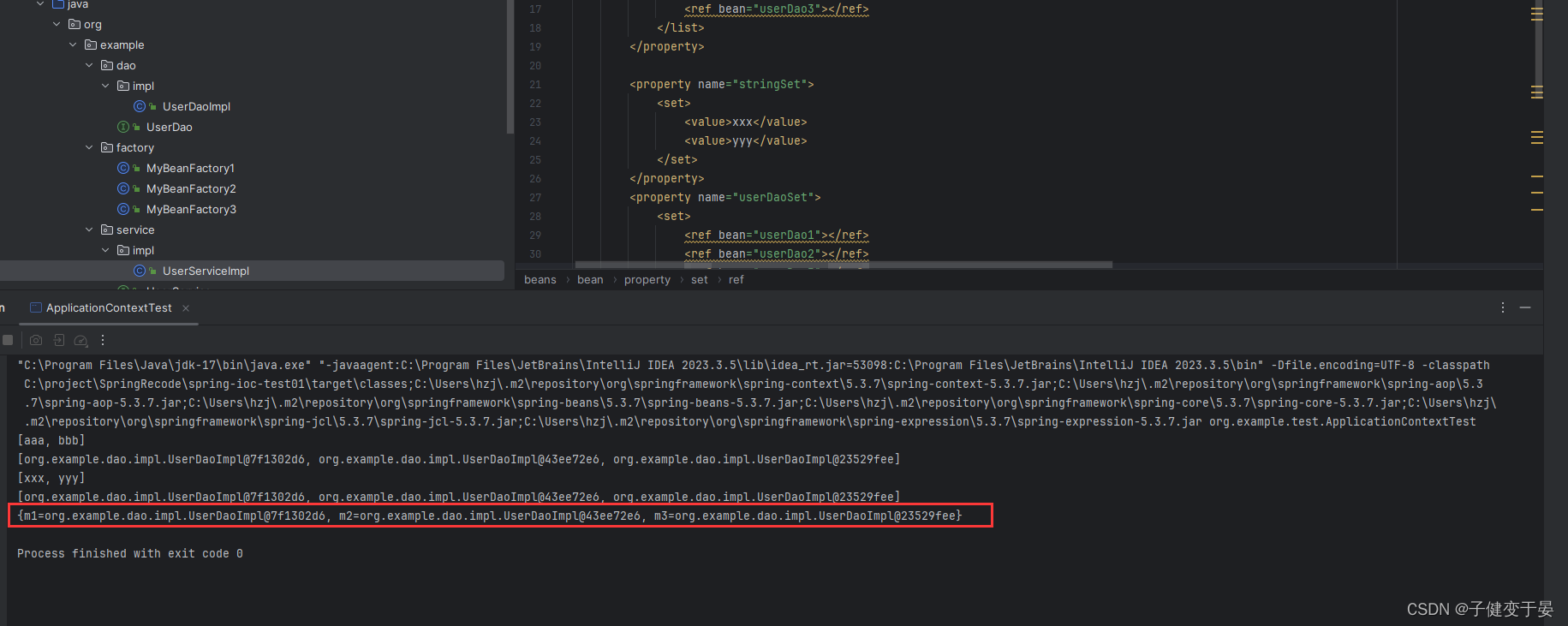
扩展:自动装配方式
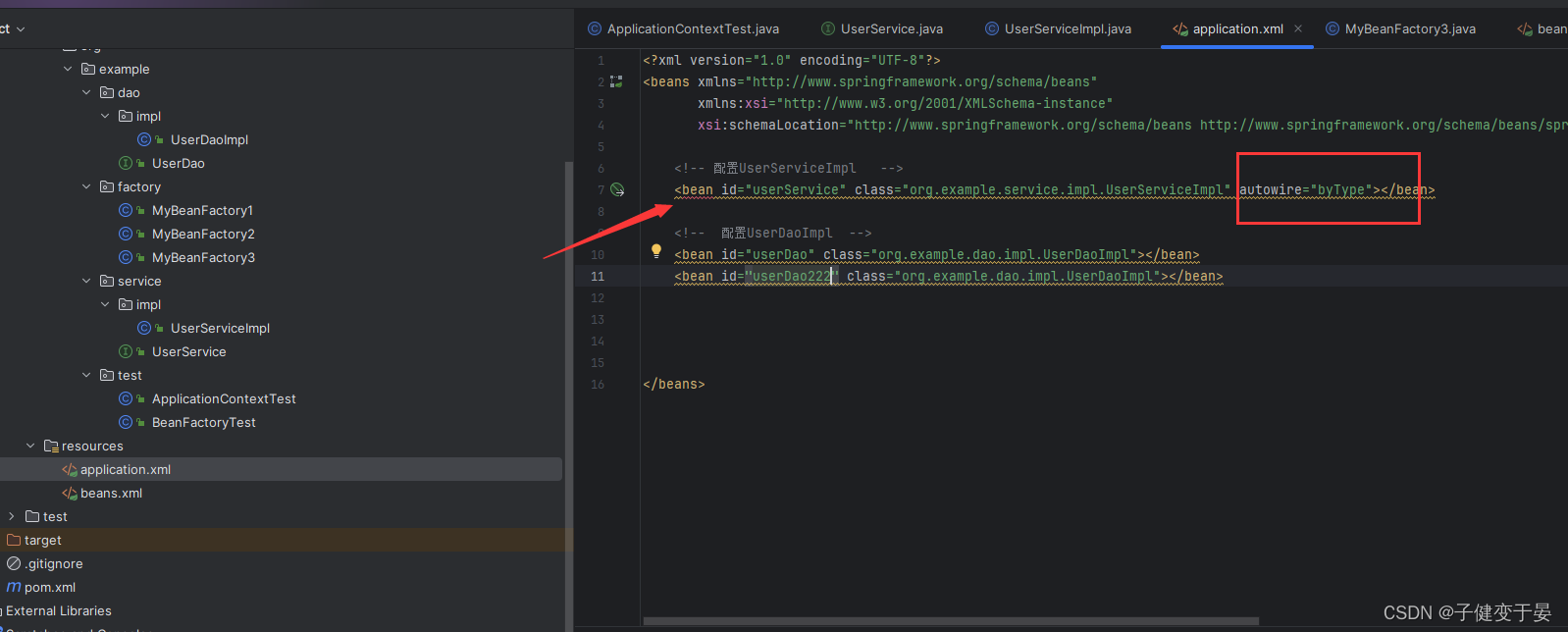
如果被注入的属性类型是Bean引用的话,那么可以在<bean>标签中使用autowire属性去配置自动注入方式,属性值有两个:
- byName:通过属性名自动装配,即去匹配setXxx 与 id="xxx" 是否一致;
- byType:通过Bean的类型从容器中匹配,匹配出多个相同Bean类型时,报错。
接下来我们分别来看看
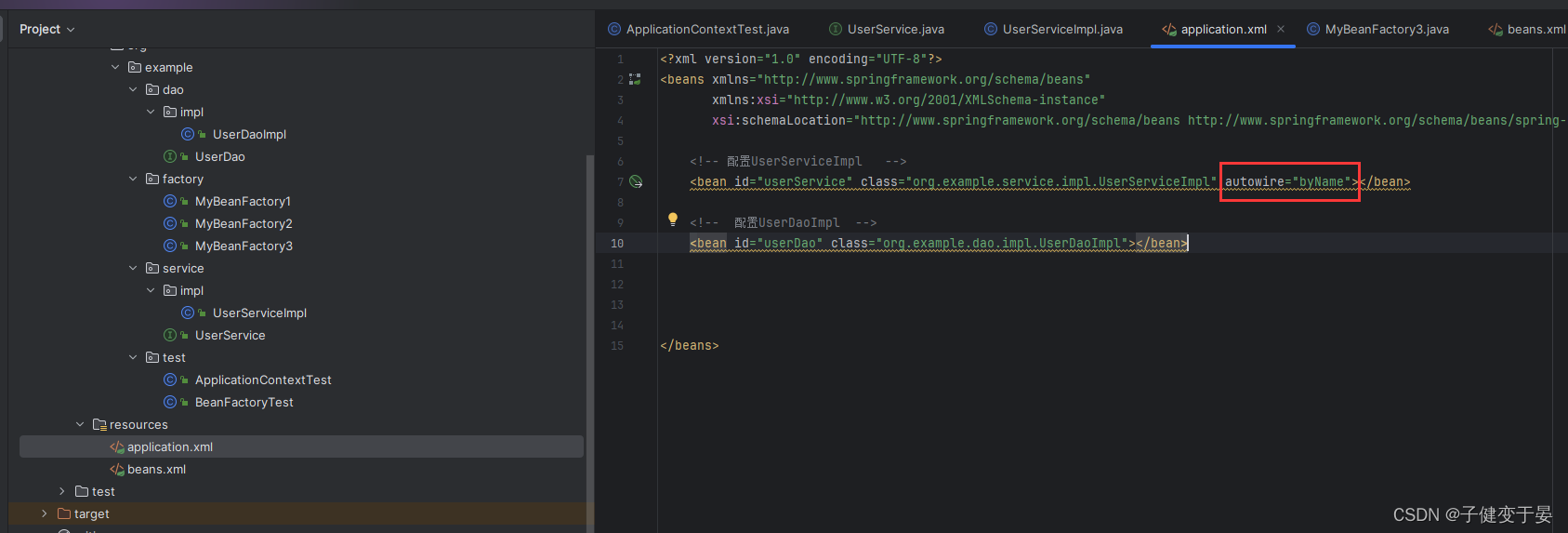
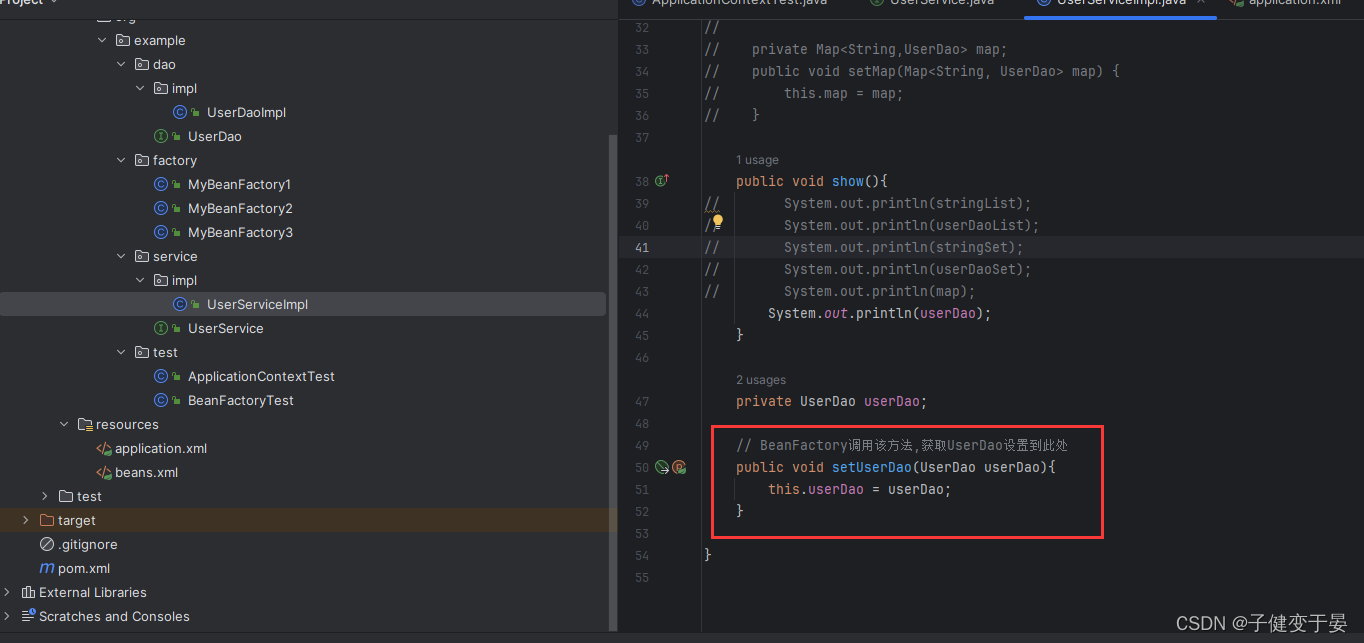
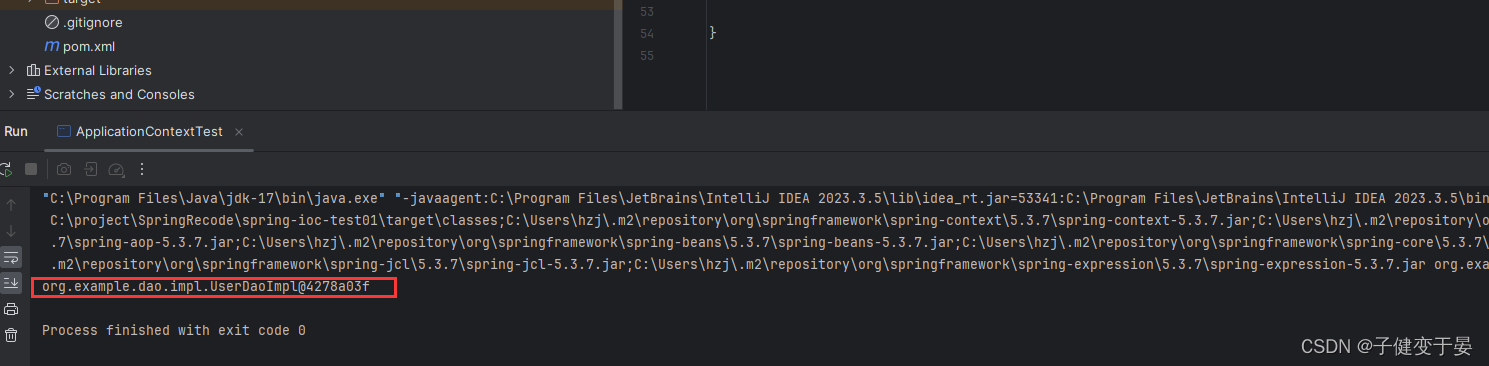
但是如果我们改为byType,配置一个没问题,但是配置多个相同类型的就会报错。

2. Spring的get方法
|---------------------------------------|--------------------------------------------------------|
| 方法定义 | 返回值和参数 |
| Object getBean(String beanName) | 根据beanName从容器中获取Bean实例,要求容器中Bean唯一,返回值Object,需要强转 |
| T getBean(Class type) | 根据Class类型从容器中获取Bean实例,要求容器中Bean类型唯一,返回值Class类型实例,不需要强转 |
| T getBean(String beanName,Class type) | 根据beanName从容器中获得Bean实例,返回值为Class类型实例,无需强转 |
第一种就是我们上面使用的方式,就不进行演示了,接下来我们看看第二种和第三种。
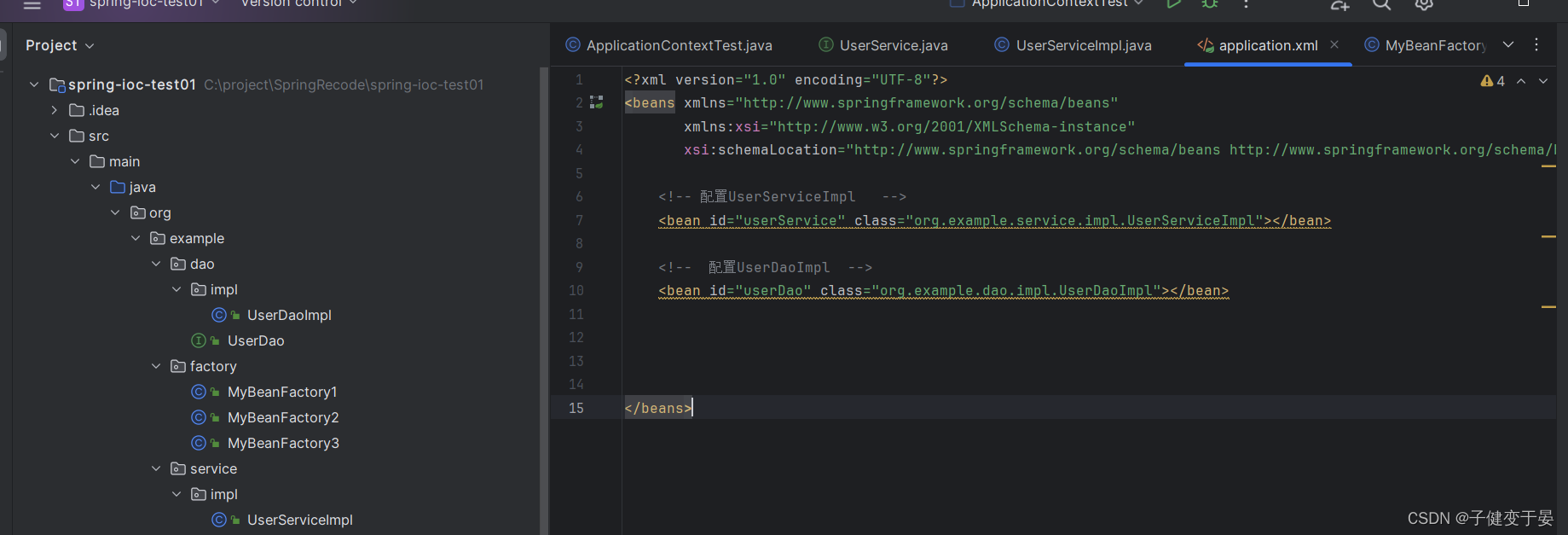 根据类型获取Bean实例,在这个类型只有一个bean的情况下使用是比较方便的,但是如果此类型有多个bean实例,那么就会报错,需要注意的是在大多数情况下,我们的同一个类型的bean也应该只有一份。
根据类型获取Bean实例,在这个类型只有一个bean的情况下使用是比较方便的,但是如果此类型有多个bean实例,那么就会报错,需要注意的是在大多数情况下,我们的同一个类型的bean也应该只有一份。
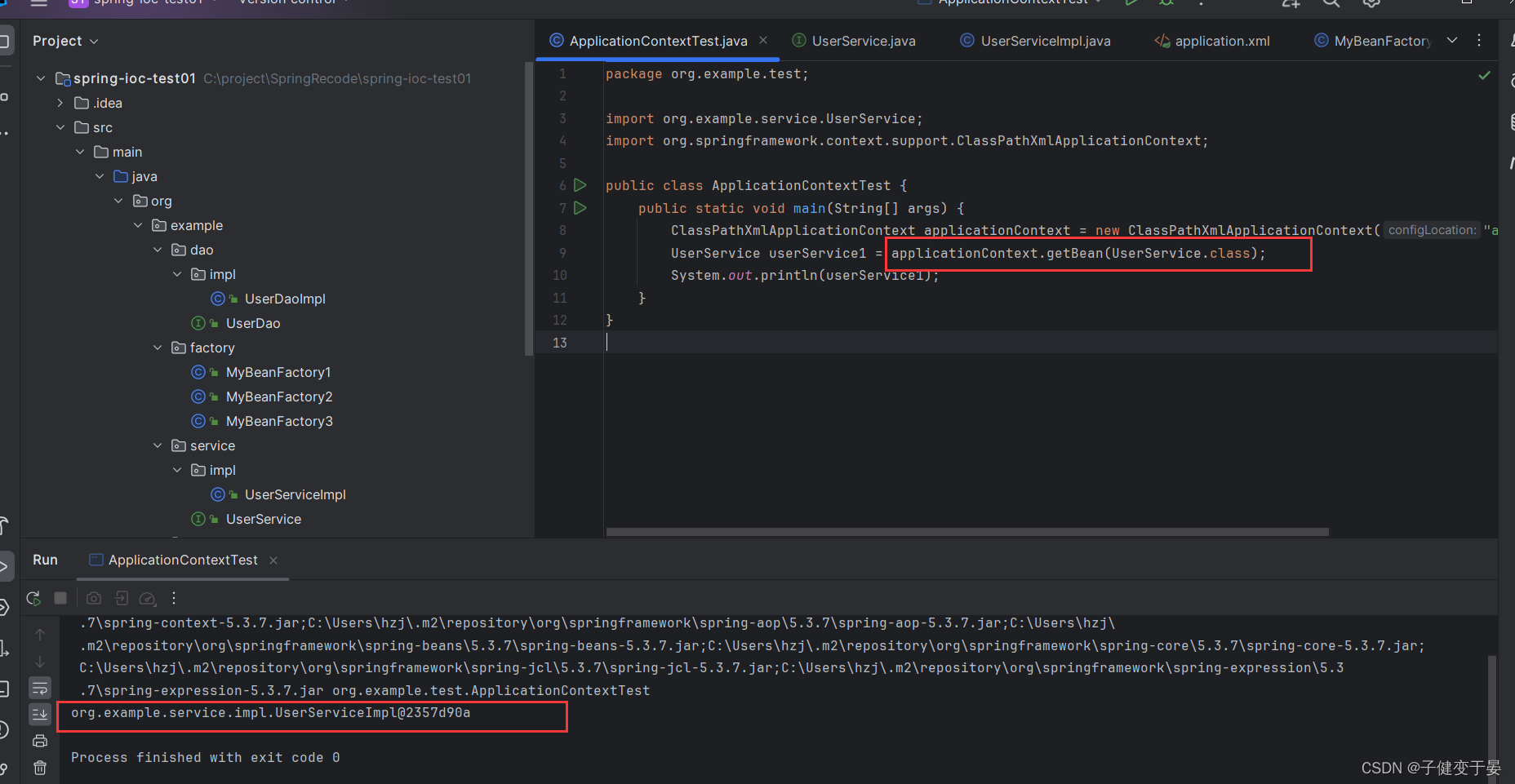
使用第三种也是没有问题的,而且貌似更稳妥了,即提供了beanName又提供其对应类型。
3. Spring配置非自定义Bean
上方我们配置的都是自定义的Bean,那么如何配置非自定义Bean呢?
什么是非自定义Bean,就是是第三方的,接下来我会配置Druid数据源交给Spring管理。
首先我们需要想两个问题:
- 配配置的Bean的实例化方式是什么?无参构造、有参构造、静态工厂还是实例工厂?
- 被配置的Bean是否需要注入必要的属性。
3.1 配置Druid交给Spring管理
接下来我们就开始,先引入Druid的坐标。
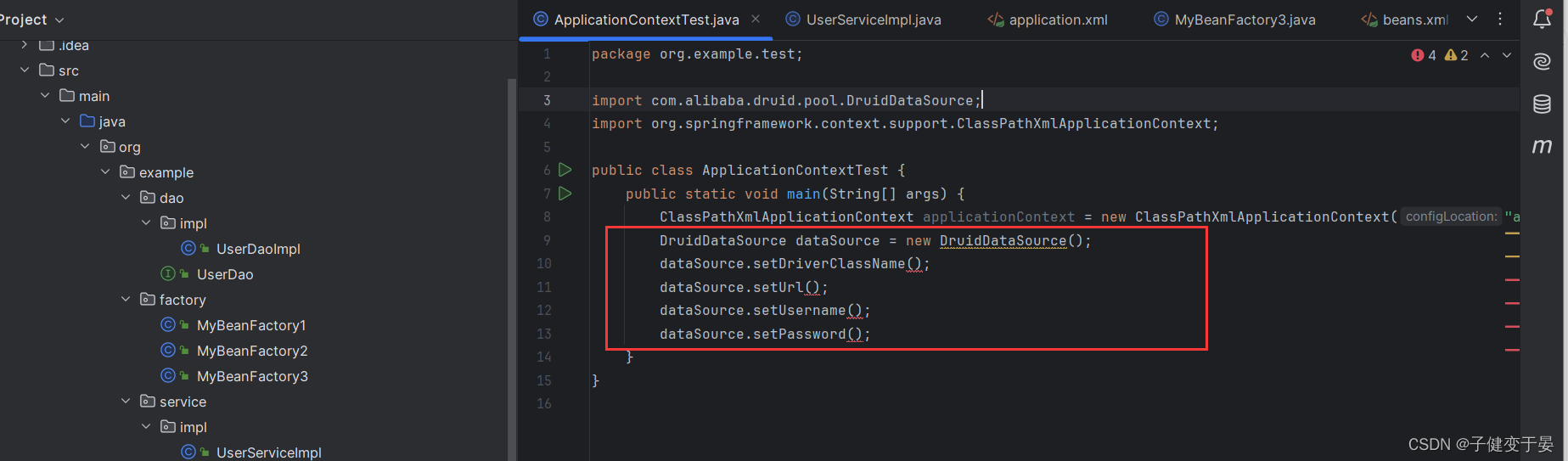
我们知道获取数据源的代码应该是这样写的。
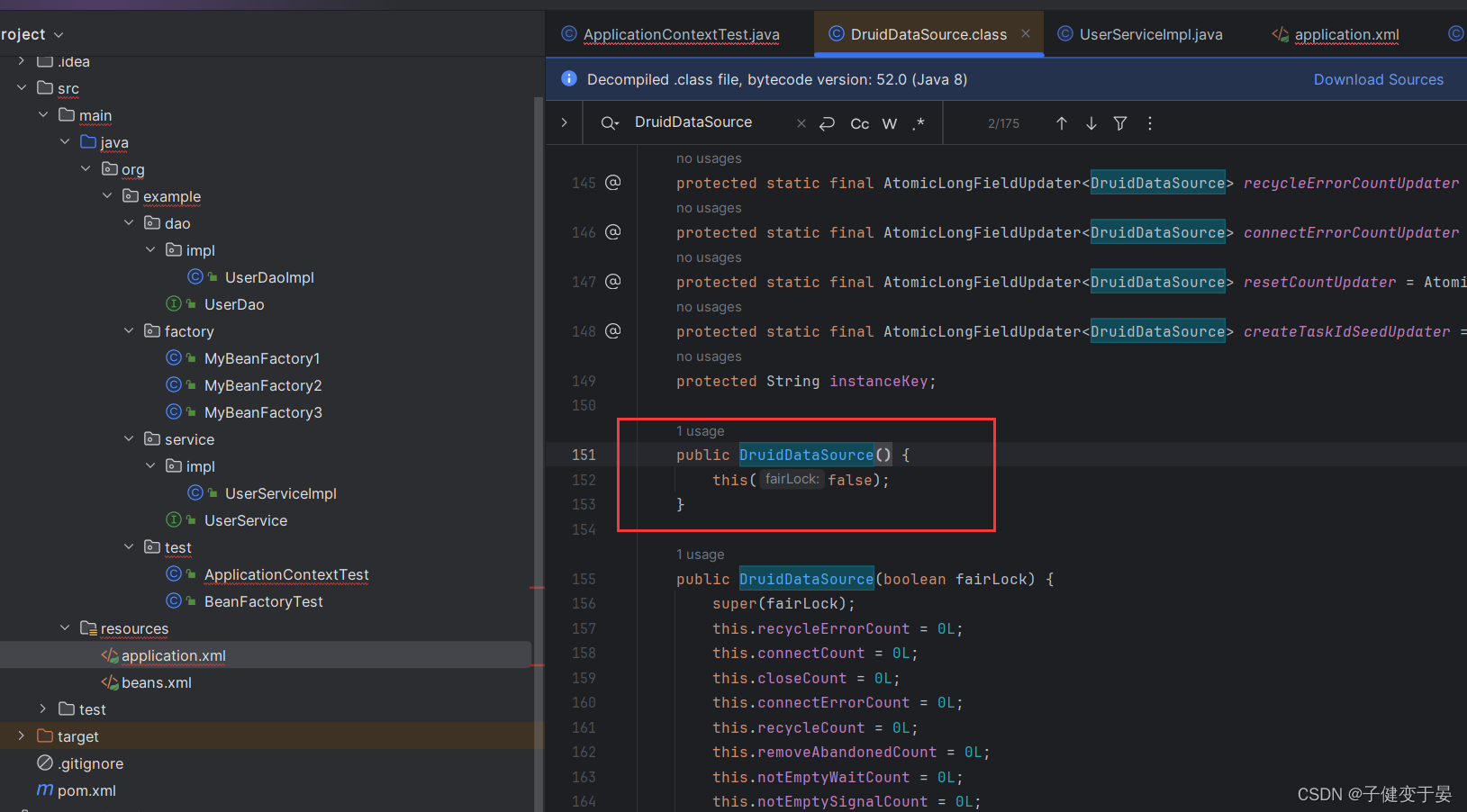
并且在源码中我们也可以看到,它是有无参构造方法的(这就意味着我们可以直接写配置)。
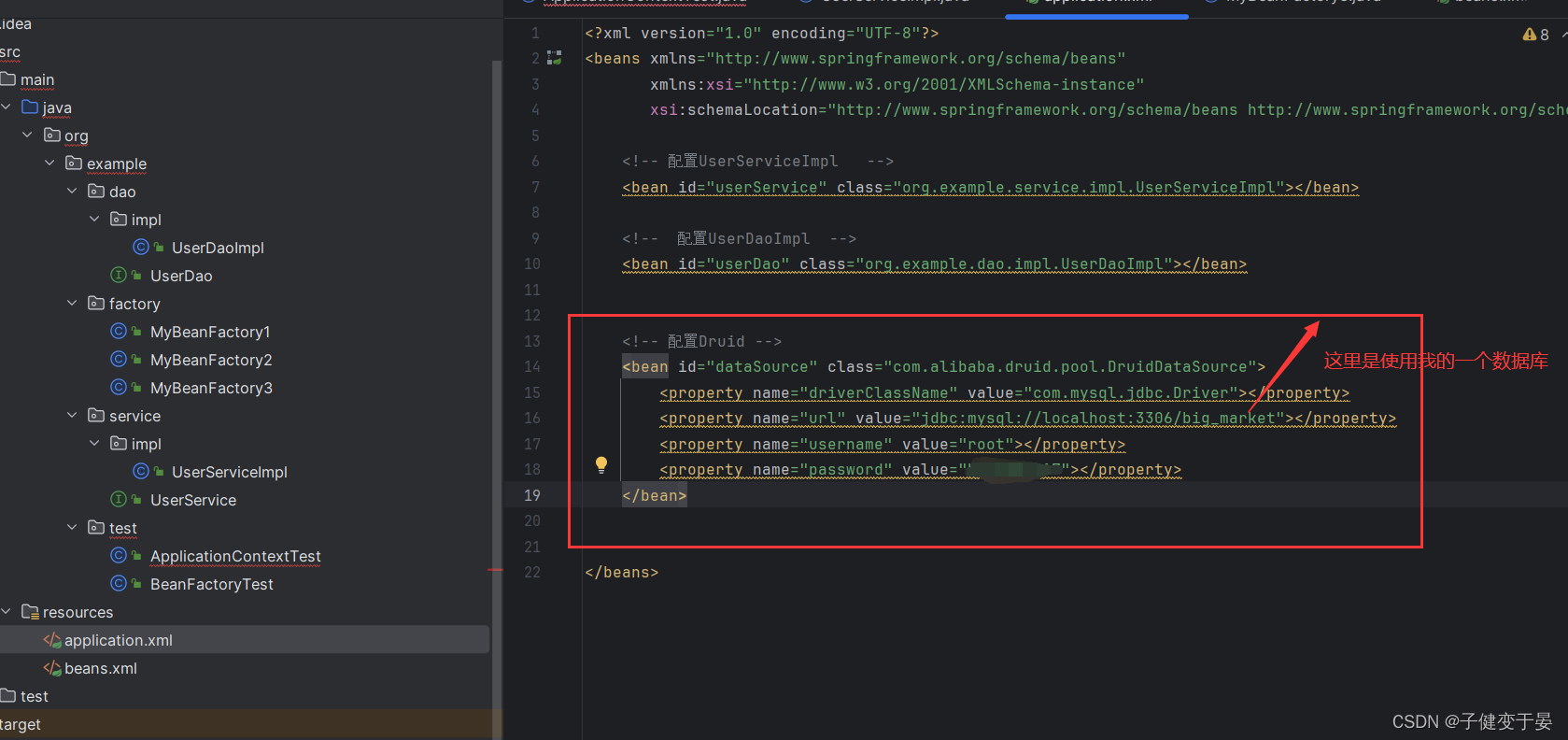
那么我们就知道了需要注入的属性,接下来就在配置文件中进行配置。
接着进行测试。
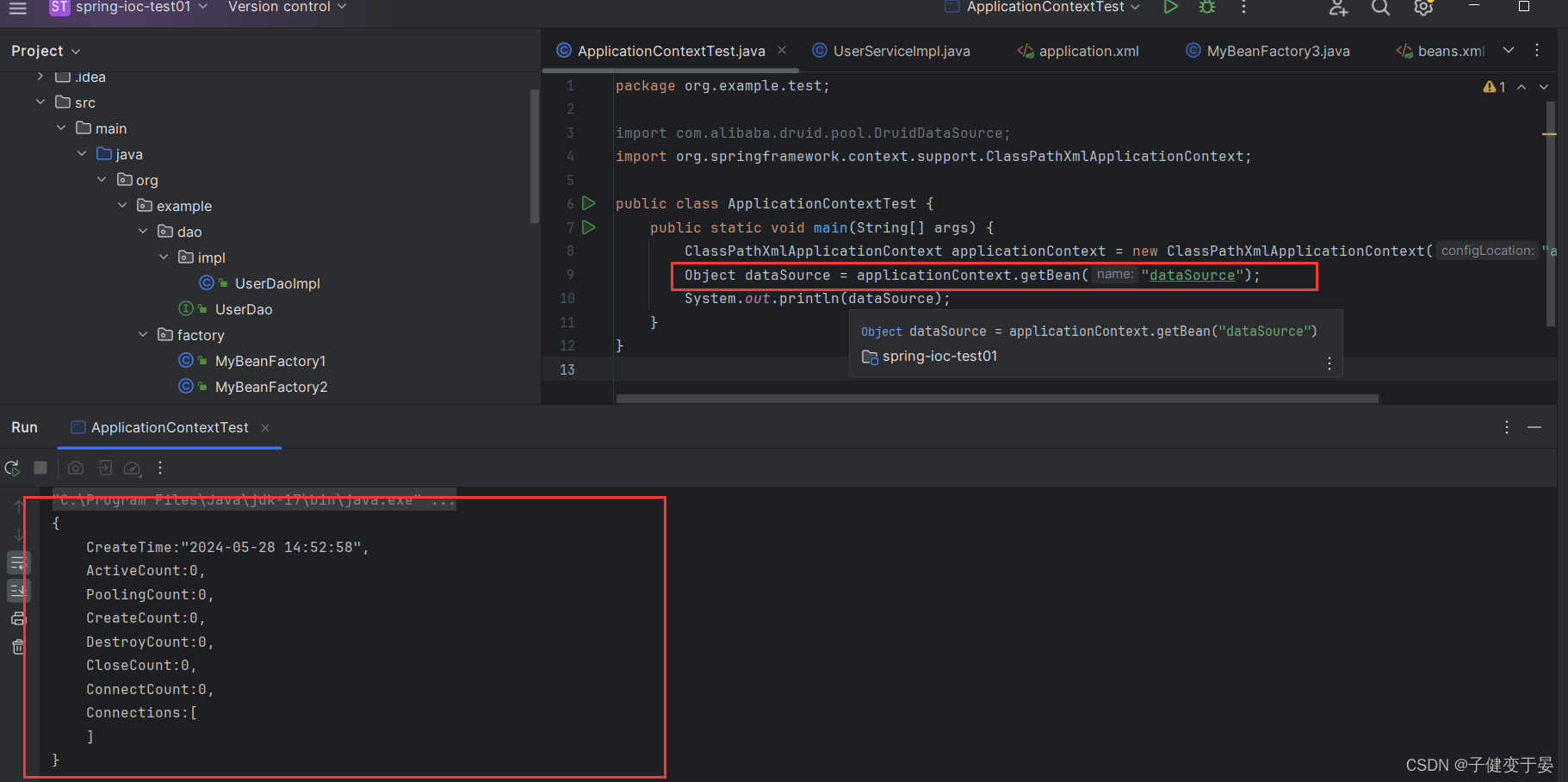
3.2 配置Connection交给Spring管理
Connection的产生是通过DriverMannager的静态方法getConnection获取的,所以我们要使用静态工厂方法进行配置。
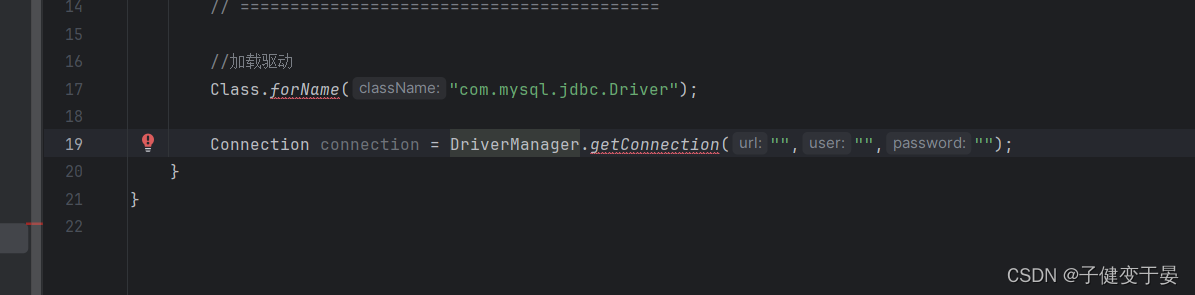
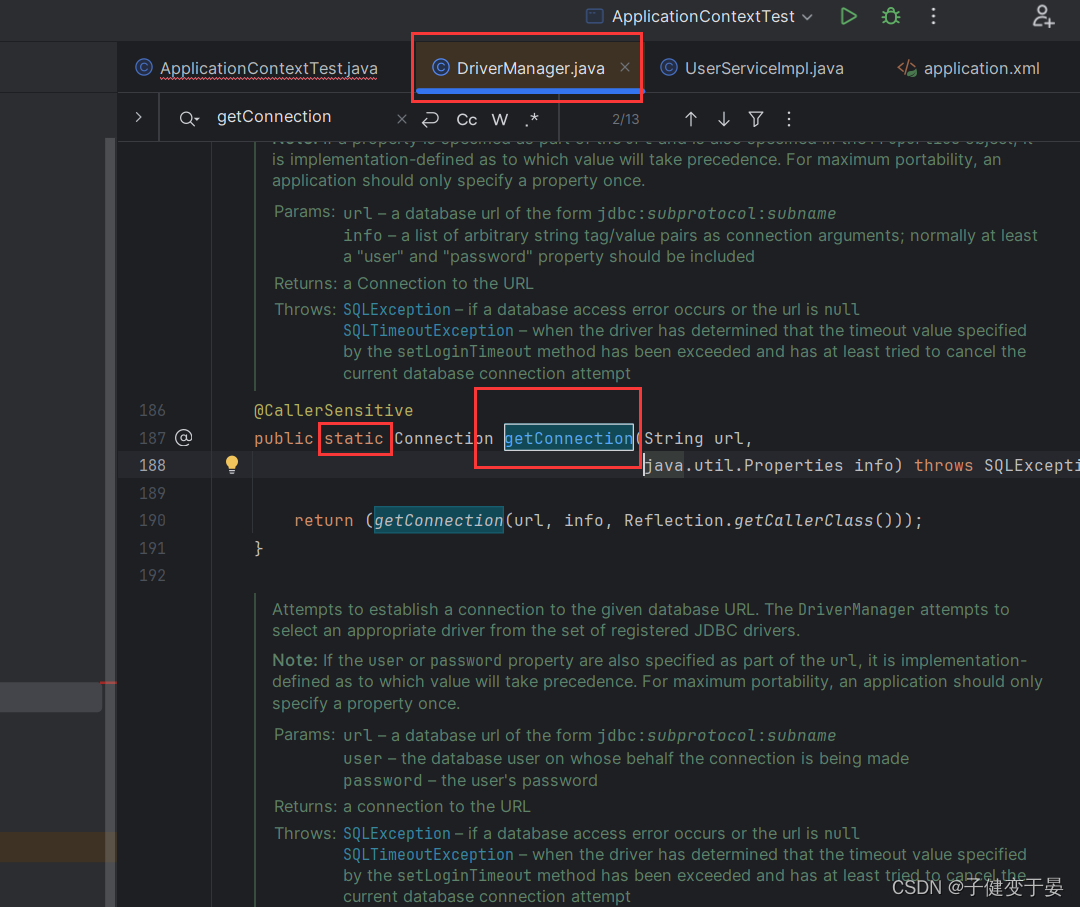
首先Class.forName,就是可以看出是静态工厂方式进行配置,因为是直接类名.方法进行的,并且getConnection这个方法也是静态方法且有参数,那么我们就来配置Connection。

这里可以看到静态方法里的参数名字叫className,我们就可以将其作为属性注入的name。
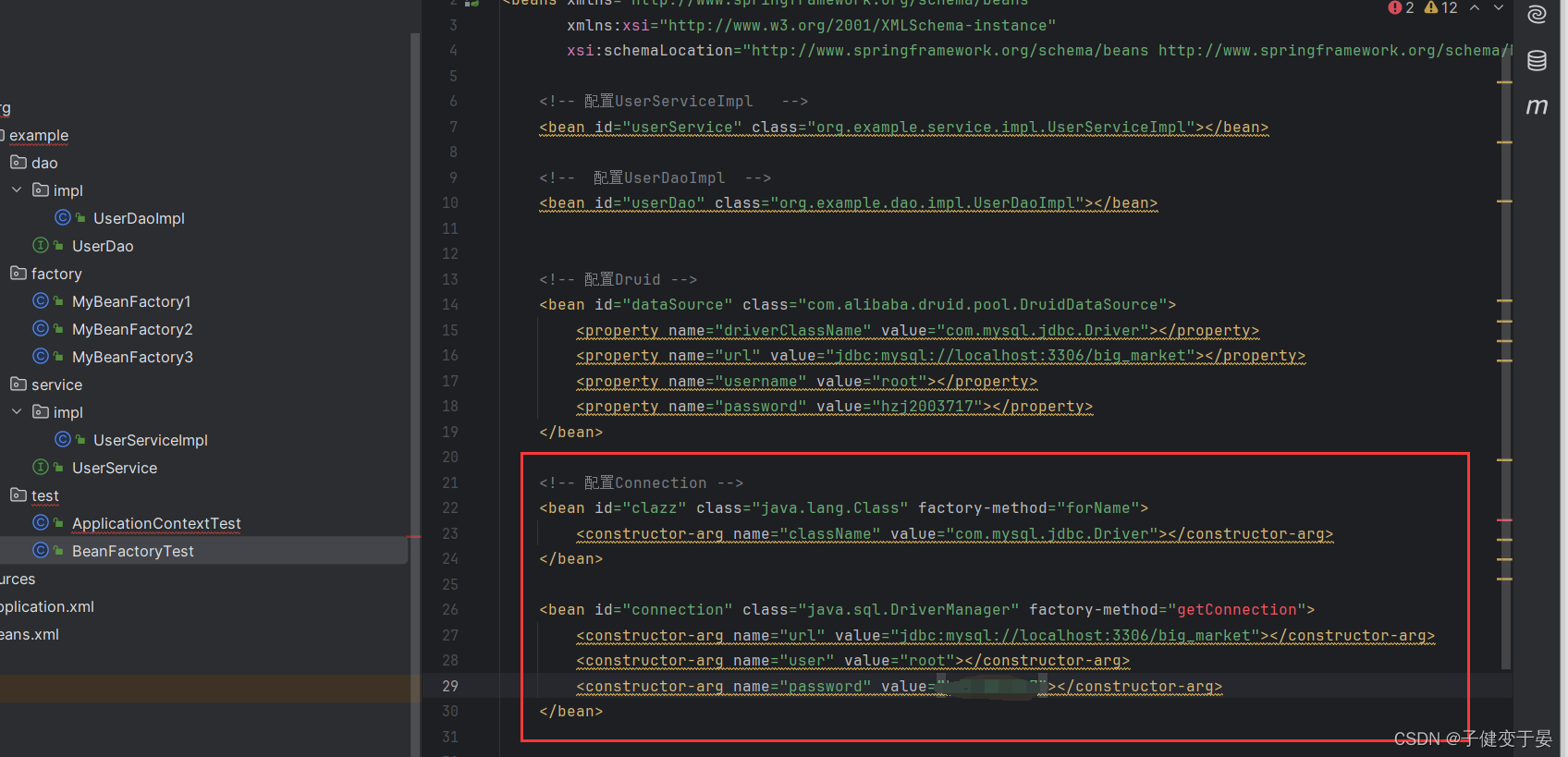
配置好之后我们进行测试看看。
真实开发过程中,绝对不会这样进行配置的,这里只是为了让我们学习的深刻一些。
4. Bean实例化的基本流程(关键)
就是你从配置文件中配置后,到交给spring管理这个过程都经历了什么。
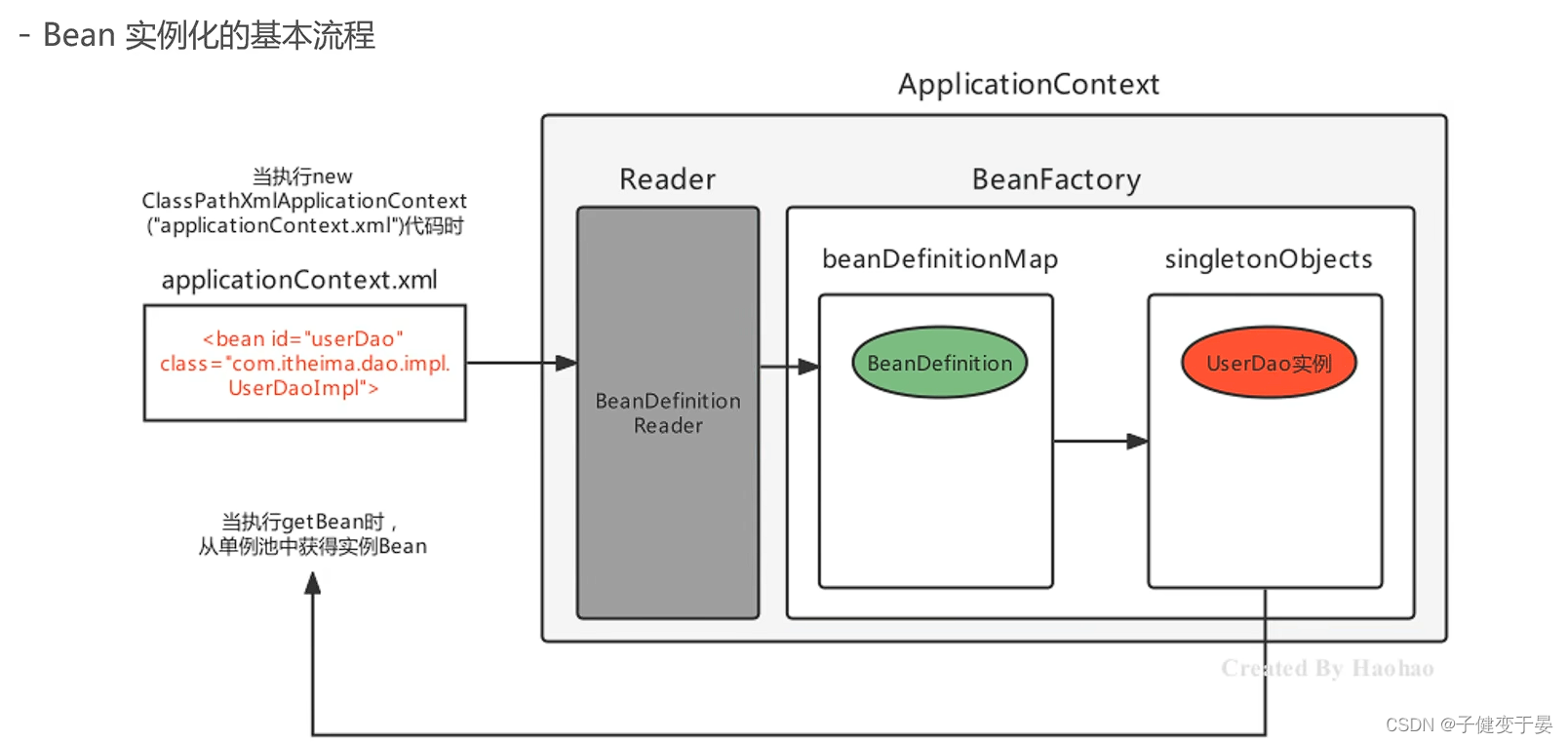
Spring容器在进行初始化时,会将xml配置的<bean>的信息封装成一个BeanDefinition对象,所有的BeanDefinition存储到一个名为beanDefinitionMap的集合中去,Spring框架在对该Map进行遍历,使用反射创建Bean实例对象,创建好的Bean对象存储在一个名为singletonObjects的Map集合中,当调用getBean方法时则最终从该Map集合中取出Bean实例对象返回。

在这里我们就可以看到这个流程,beanDefinitionMap中存储的BeanDefinition不是一个实例对象,而是一个bean配置的信息,后续再通过遍历这个map创建Bean对象到singletonObjects中。
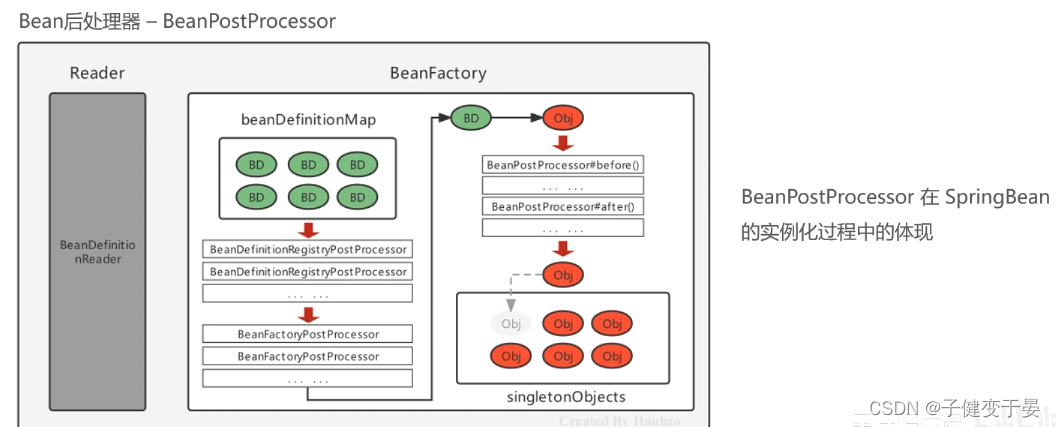
5. Spring的后处理器入门
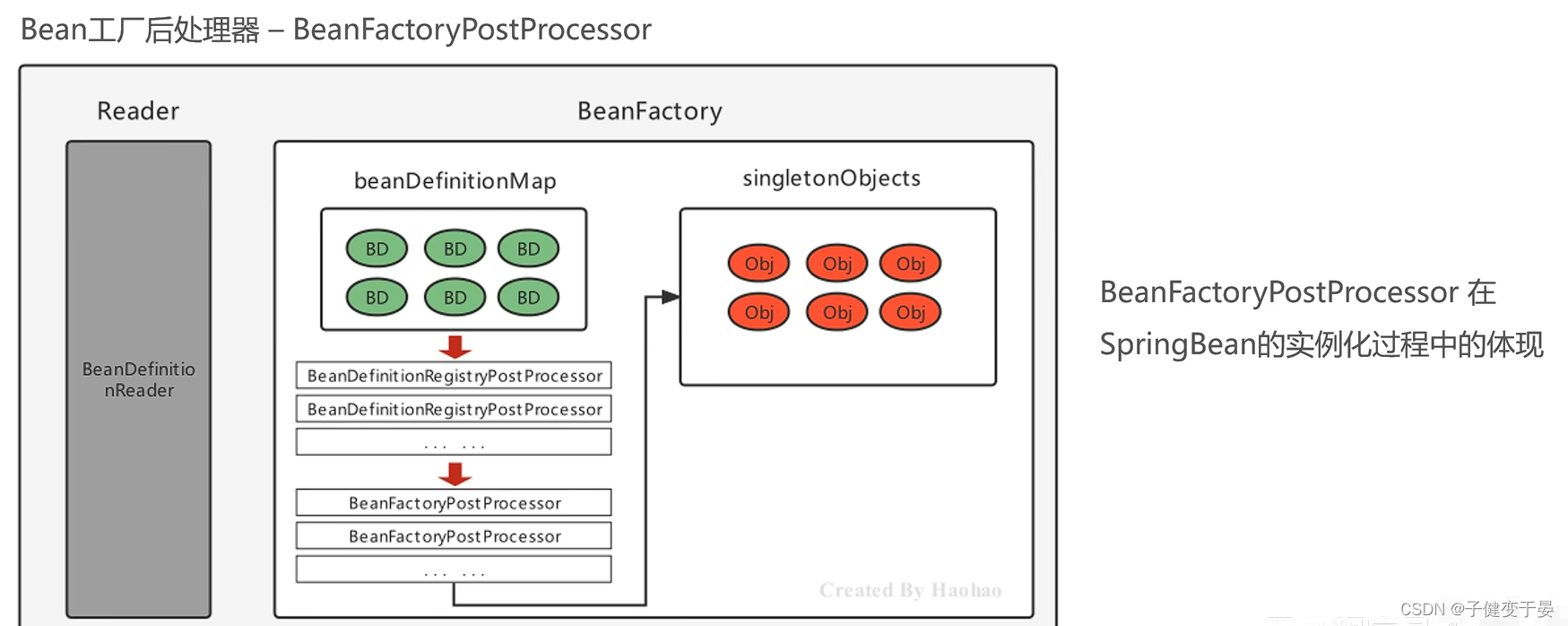
Spring的后处理器是Spring对外开发的重要扩展点,允许我们介入到Bean的整个实例化流程中,以达到动态注册BeanDefinition,动态修改BeanDefinition,以及动态修改Bean的作用。
Spring主要有两种后处理器:
- BeanFactoryPostProcessor:Bean工厂后处理器,在BeanDefinitionMap填充完毕,Bean实例化之前执行;
- BeanPostProcessor:Bean后处理器,一般在Bean实例化之后,填充到单例池singletonObjects之前执行;
BeanDefinitionMap->Bean工厂后处理器->循环Map(实例化->Bean后处理器->填充singtonObjects)
5.1 BeanFactoryPostProcessor
BeanFactoryPostProcess是一个接口规范,实现了该接口的类只要交由Spring容器管理的话,那么Spring就会回调该接口的方法,用于对BeanDefinition注册和修改的功能。
首先我们写一个类实现该接口,并进行测试看看其运行时机。
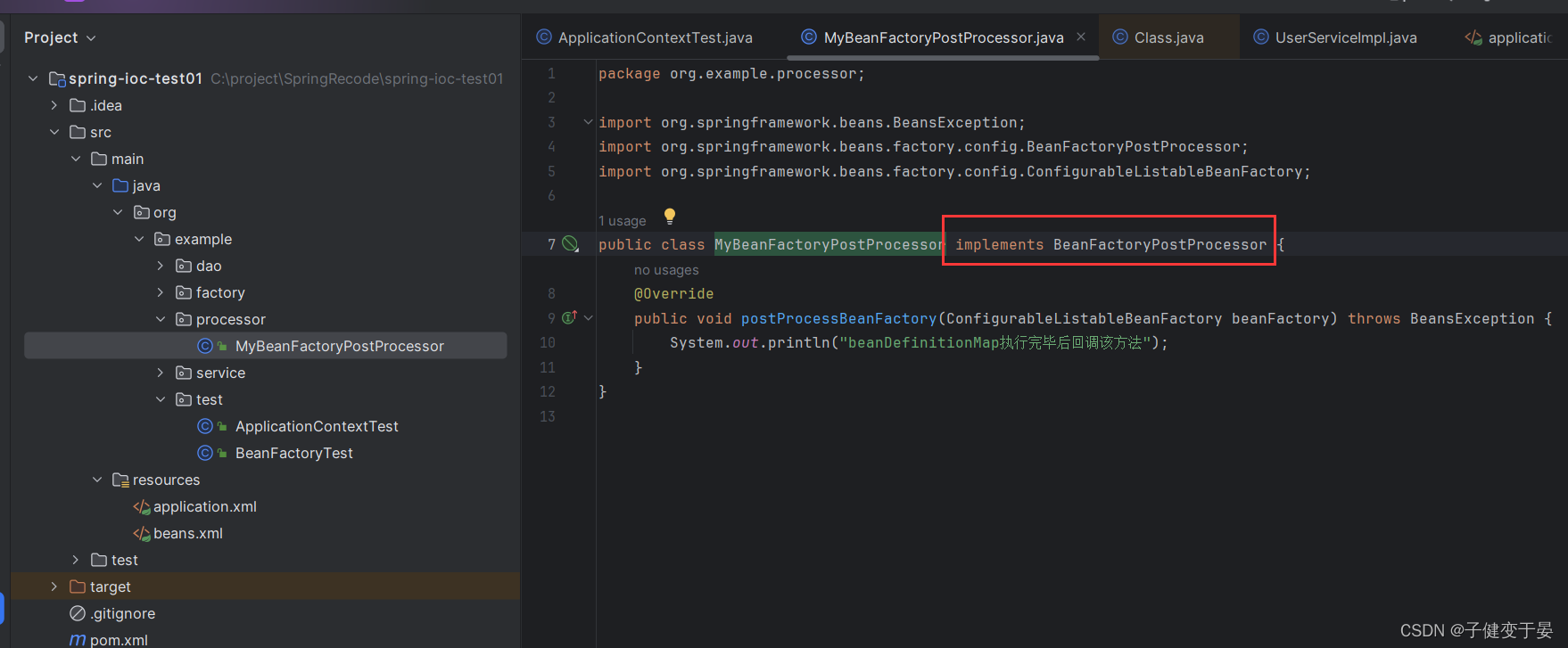
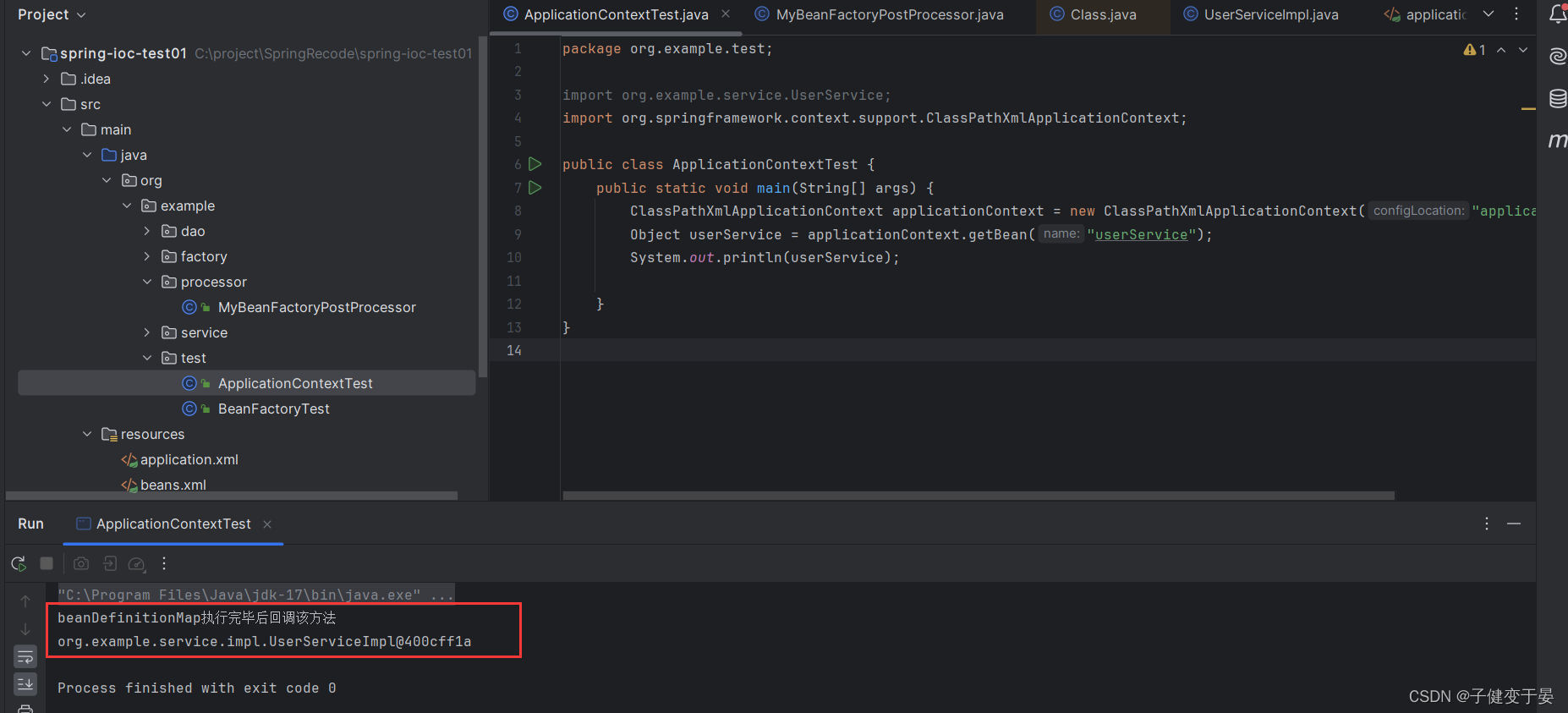
发现是在实例化Bean对象前执行的,那么这个有什么用处呢?
接下来我们尝试对其"动手脚"。
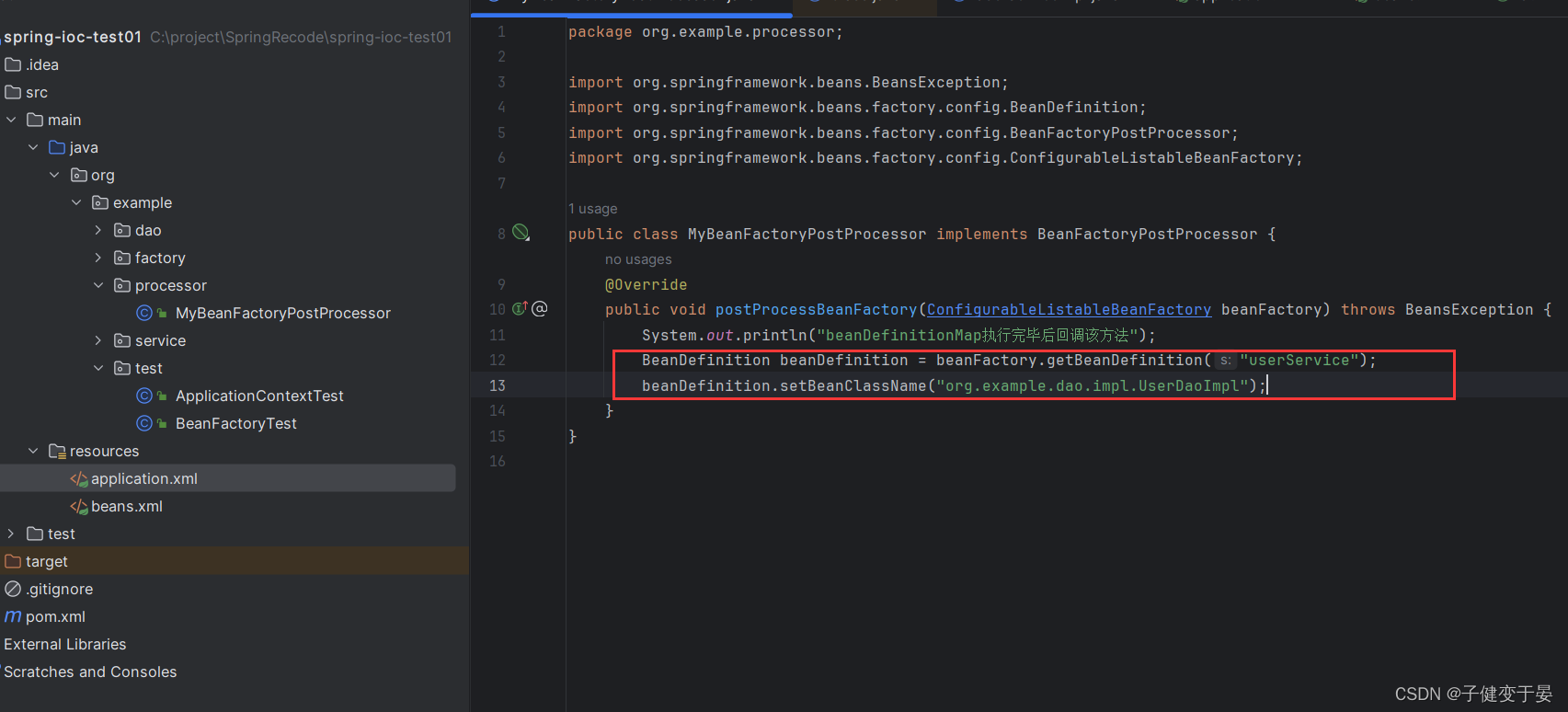
我们获取了一个beanName为userService的beanDefinition,但是把全限定名改为了UserDaoImpl实例对象的,让我们测试看看会发送什么。
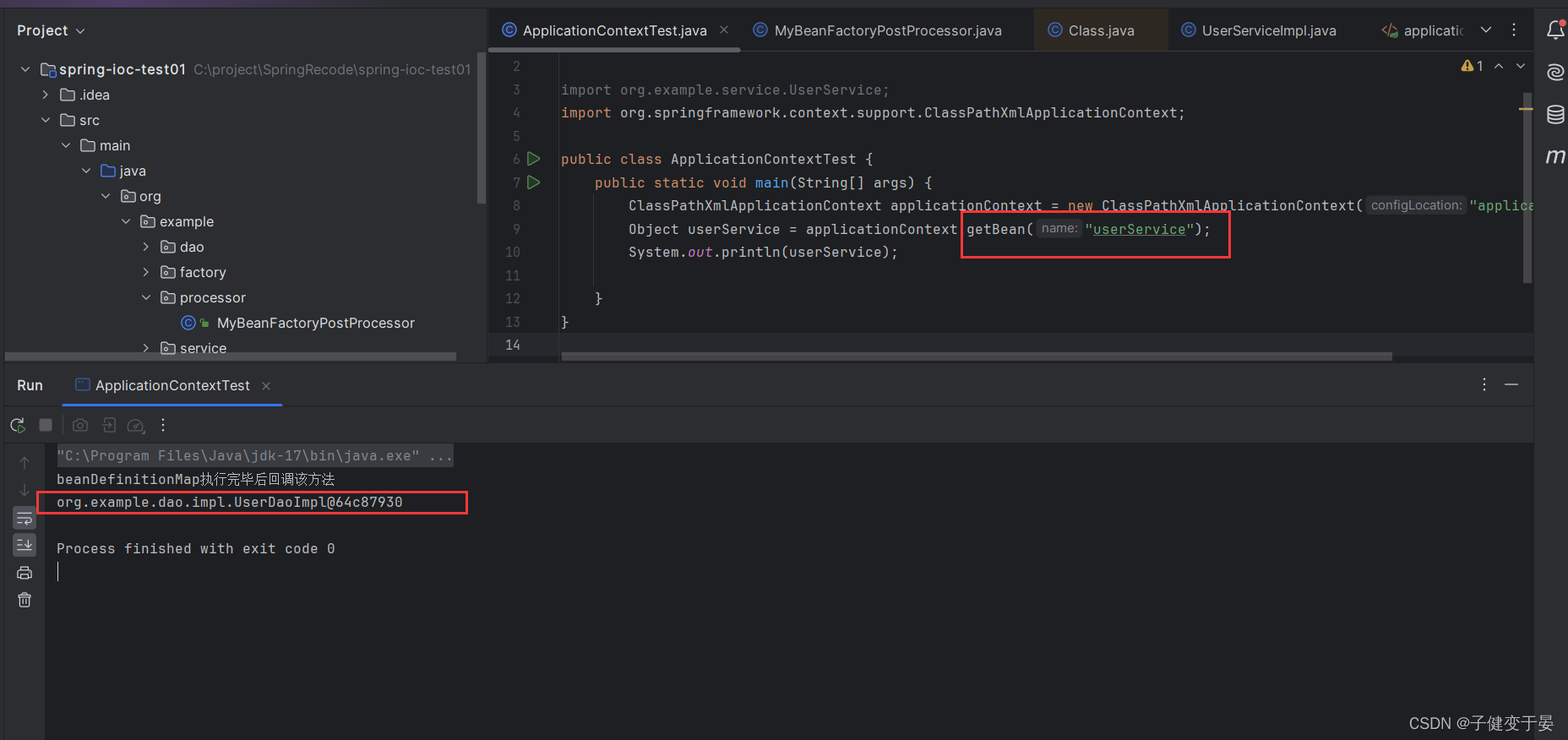
可以看到我们明明get的是userService,按理应该返回UserServiceImpl对象,但是却变成了UserDaoImpl,这就是动态对beanDefinition进行修改。
再来看看如何进行beanDefinition的注册。
先创建一个新的dao以及其实现类,但是不进行配置。

那么没配置肯定获取就是会报错的。
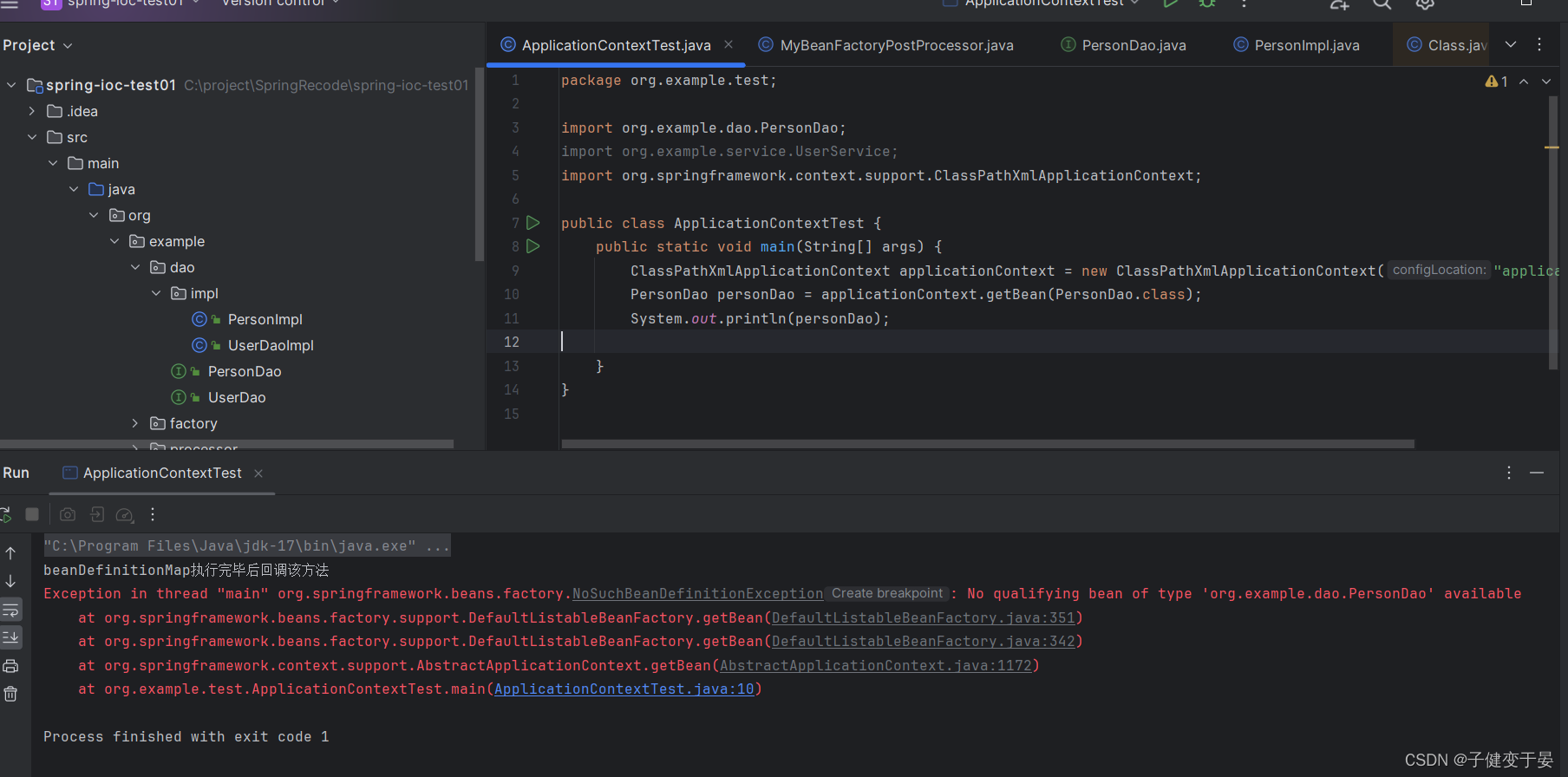
接下来我们通过BeanFactoryPostProcessor动态的将其注册到beanDefinition中去。
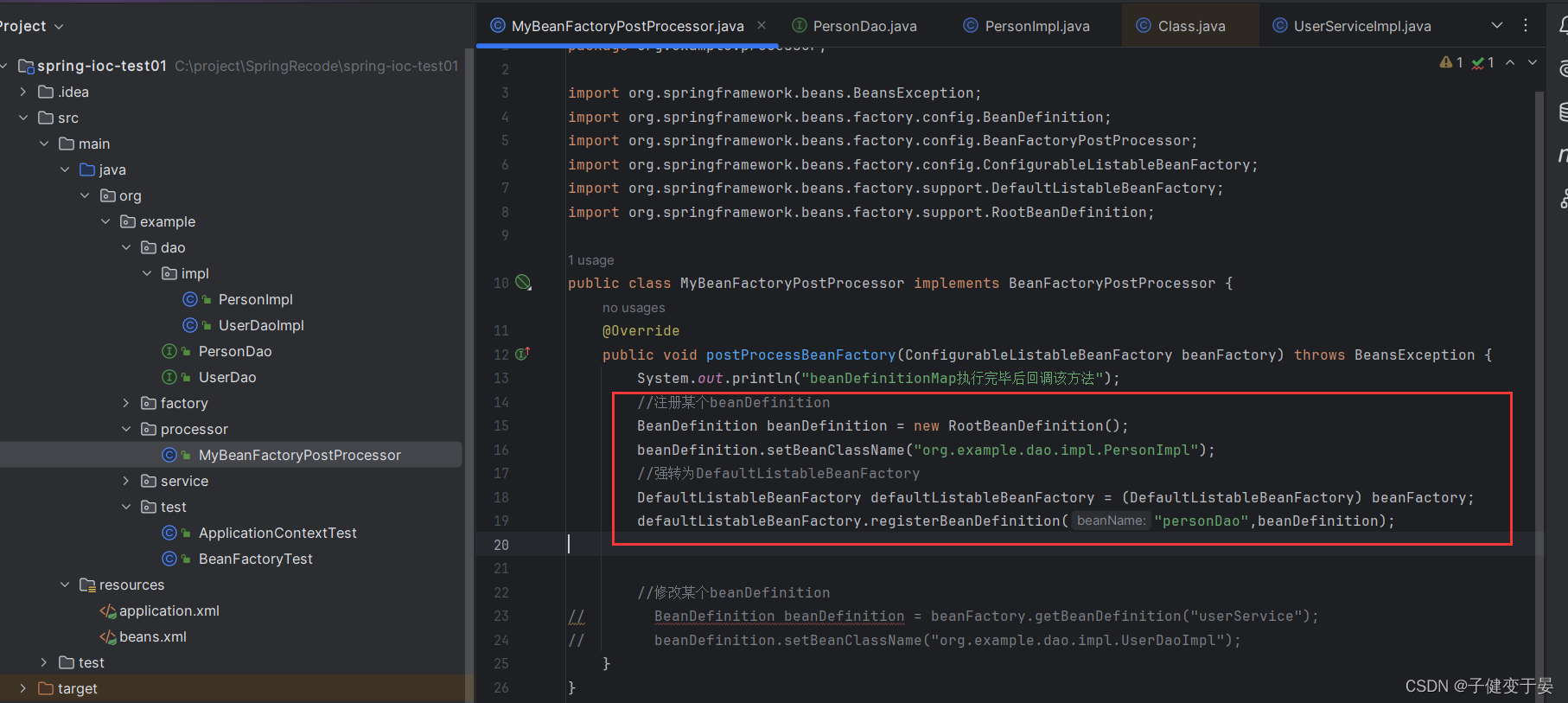
接着进行测试看看能否获取到personDao。
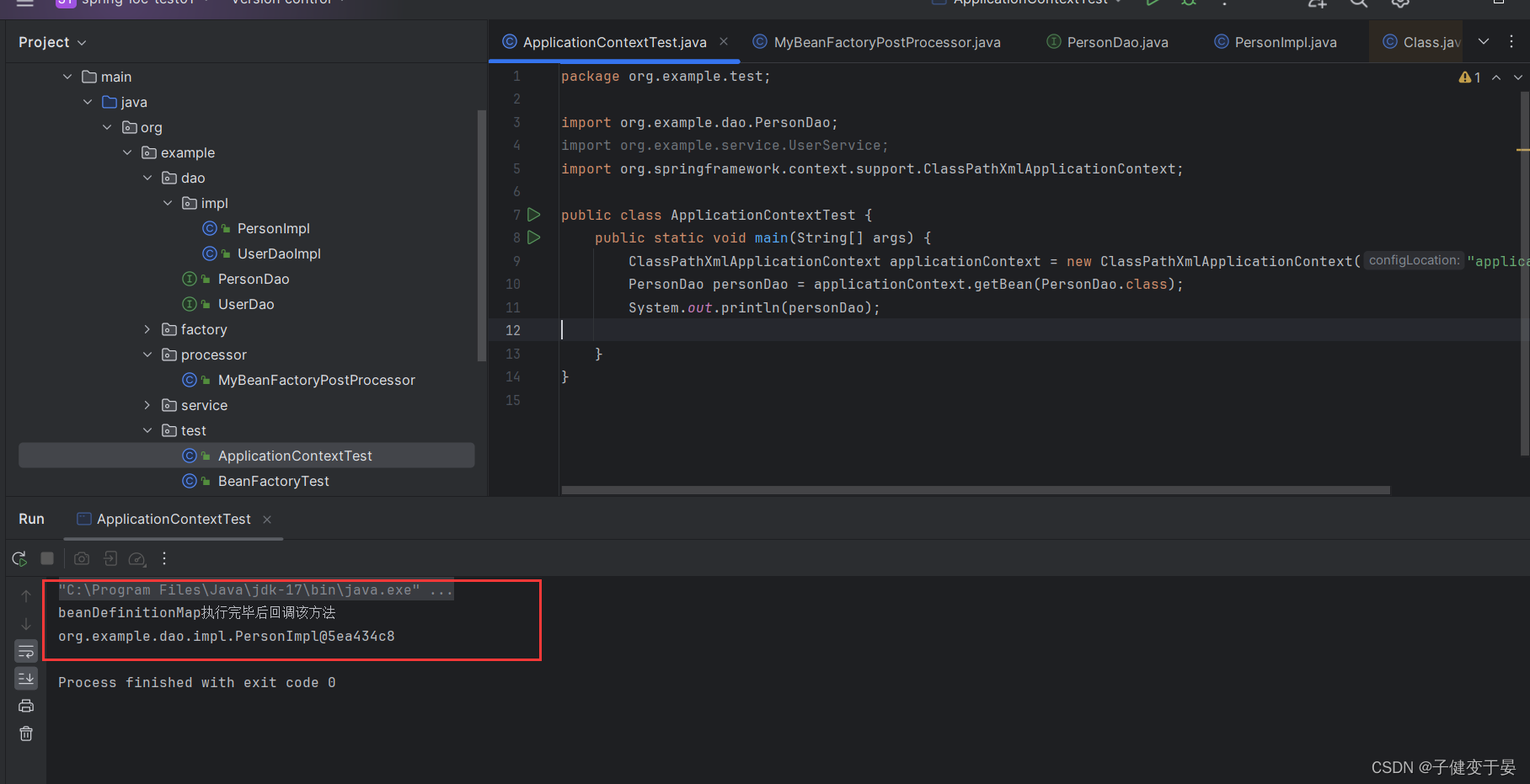
5.2 自定义@Component
学到这里我们可以做一个demo,就是我们知道配置给我们切换的代价很大,写完接口,写实现类,接着还要去配置文件中去进行配置。
我们希望的是使用一个注解就可以解决配置的问题。
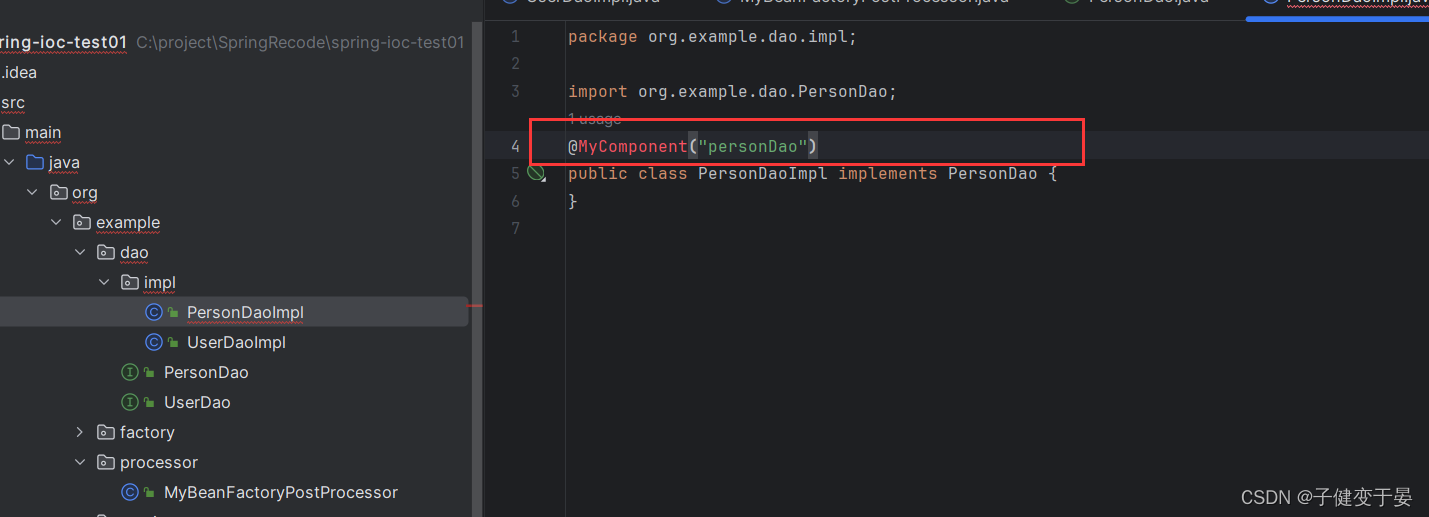

接下来就让我们看看如何实现吧。
首先我们要先创建自定义注解MyComponent。
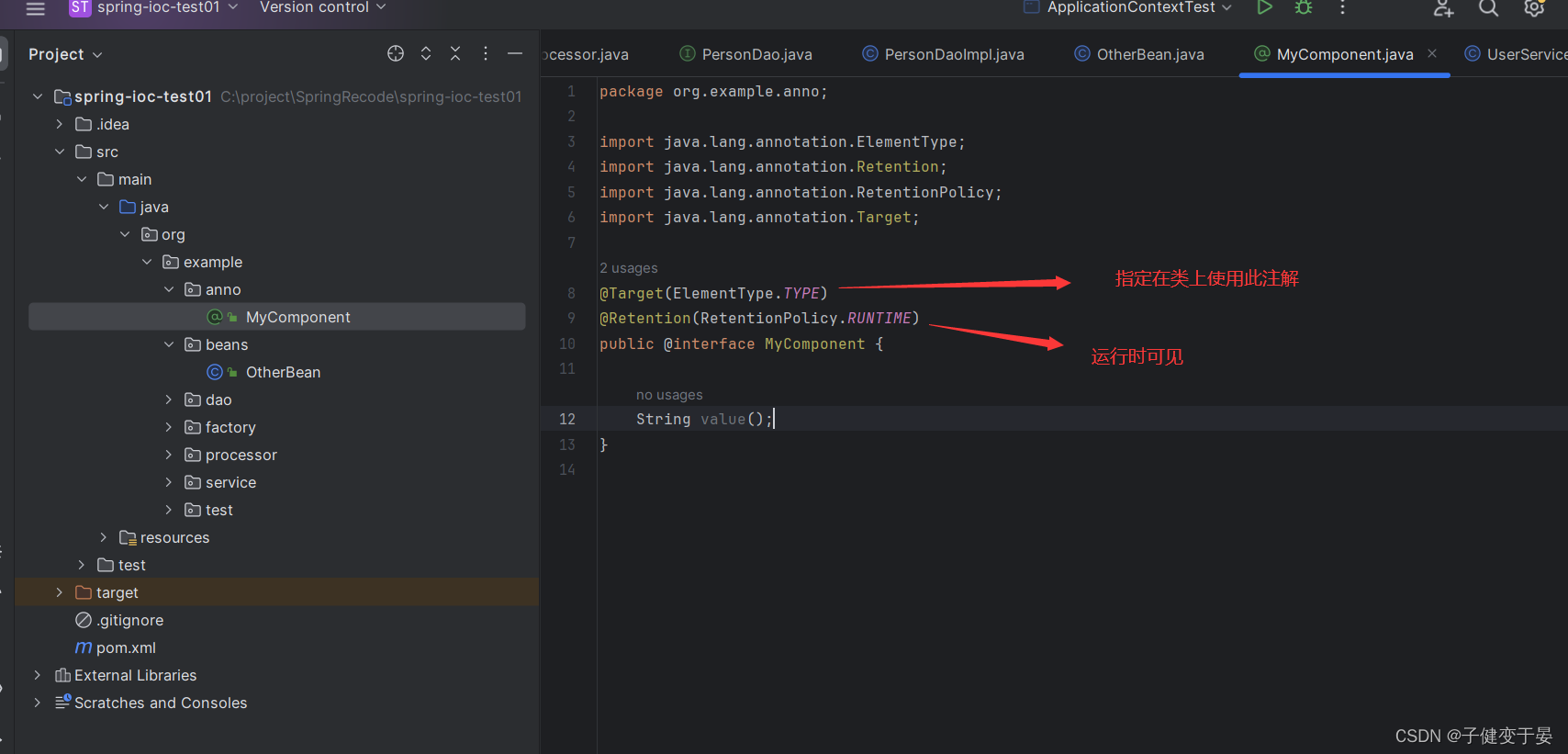
接着我们需要一个工具类,这个工具类的作用就是扫描该包以及其子包下的类,谁使用了该注解。
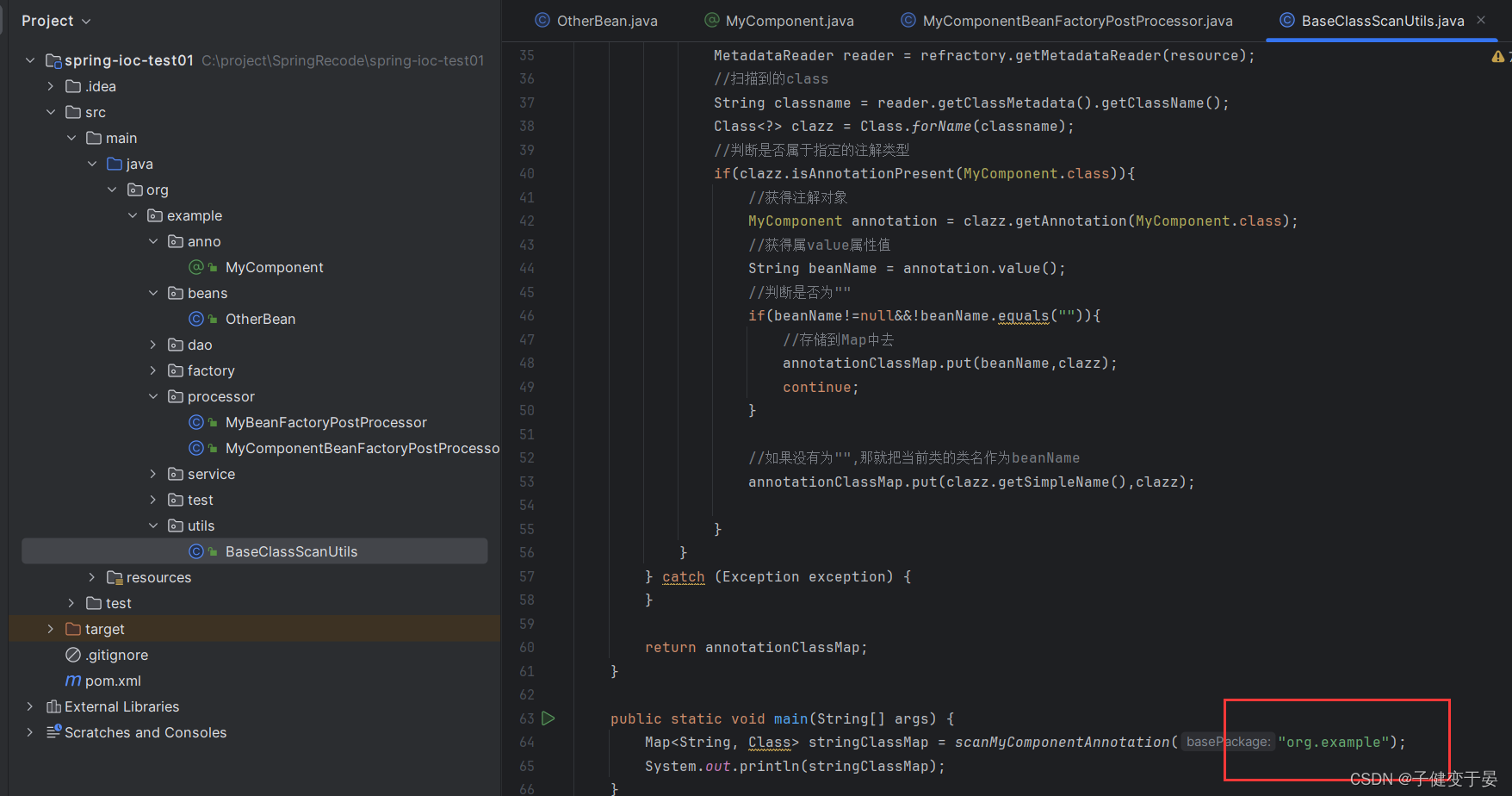
最后在Bean工厂后处理器中进行Bean的注册。

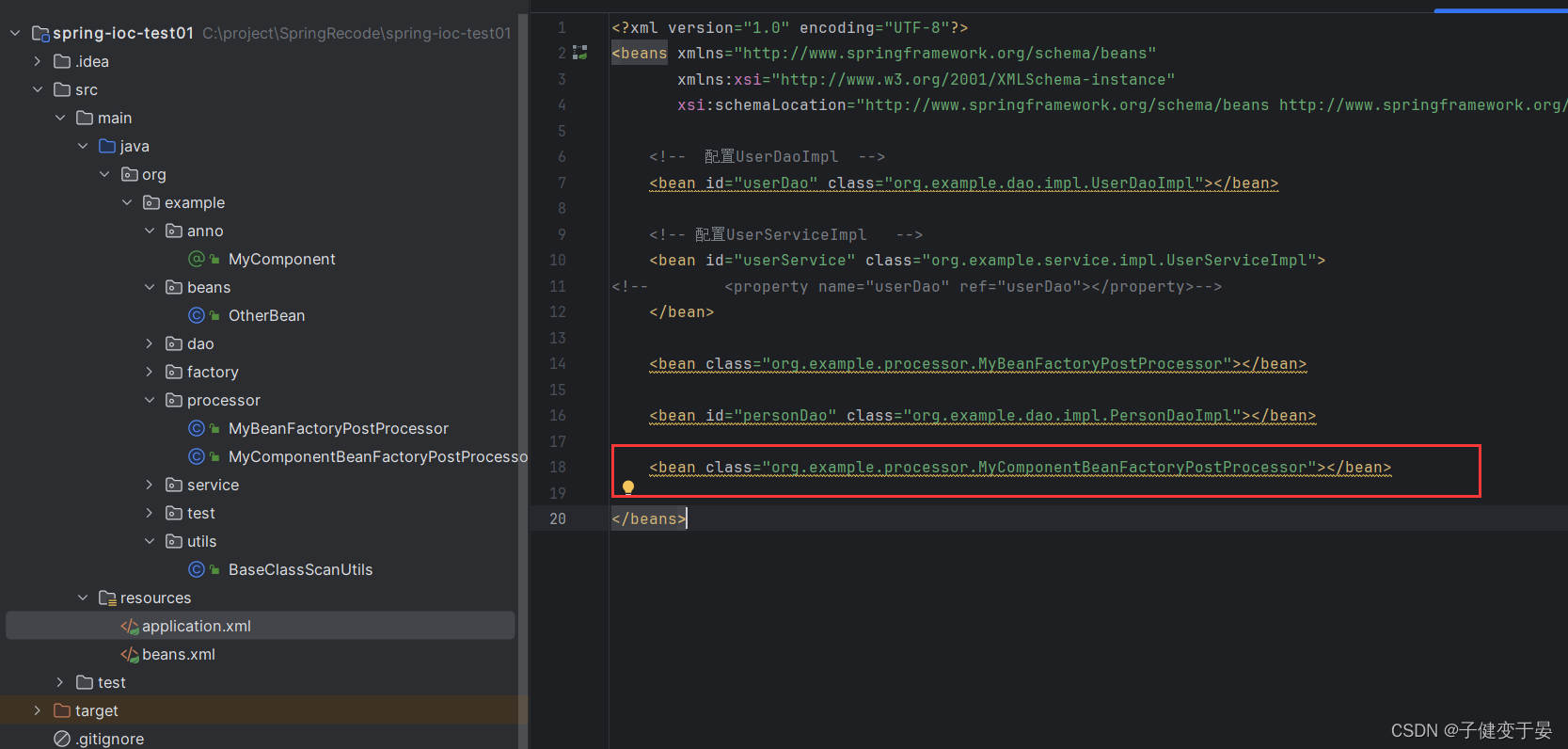
最后我们需要让这个后处理器生效需要对其进行配置。
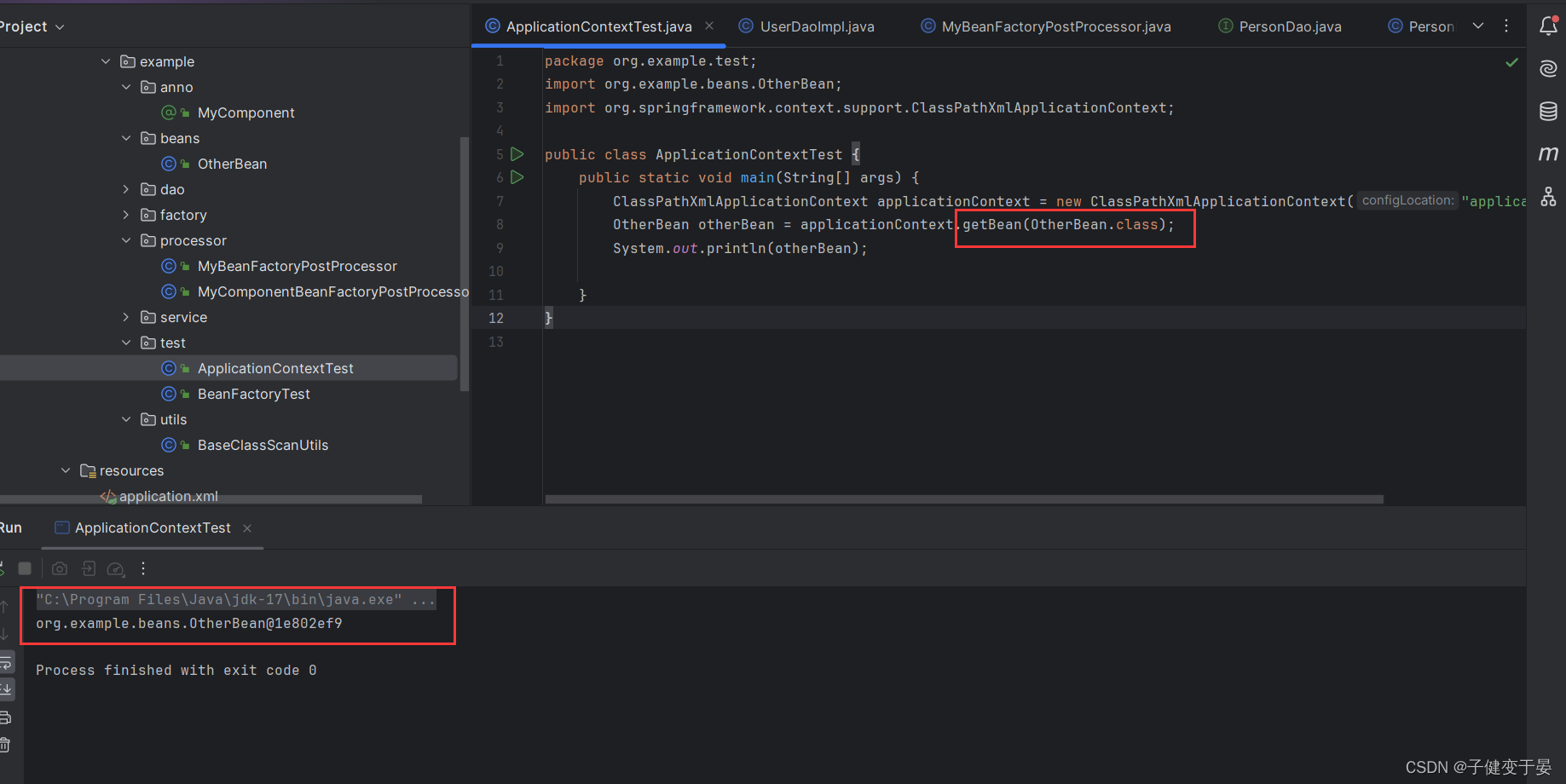
最后我们测试获取OtherBean。

我觉得这一块的知识点非常重要,和后期的注解注入有很强的关联,这也是为什么我要重新学习spring课程的原因,因为很多特性没搞明白。
5.3 BeanPostProcessor
从之前的实例化流程中我们也可以知道,Bean被实例化后最终会缓存到singletonObjects单例池之前,会经过Bean的初始化过程,例如属性填充、初始化方法init的执行,而其中就有一个扩展的点BeanPostProcessor,我们称为Bean后处理器,与上述的Bean工厂后处理器相似,也是一个接口,实现了该接口并被容器管理的BeanPostProcessor,会在流程节点上被Spring自动调用。
那么我们就可以在还未填充到singletonObjects的Bean对象做一些"手脚"。
先创建一个方法实现BeanPostProcessor。

接着将其进行配置。

最后我们进行测试看看。
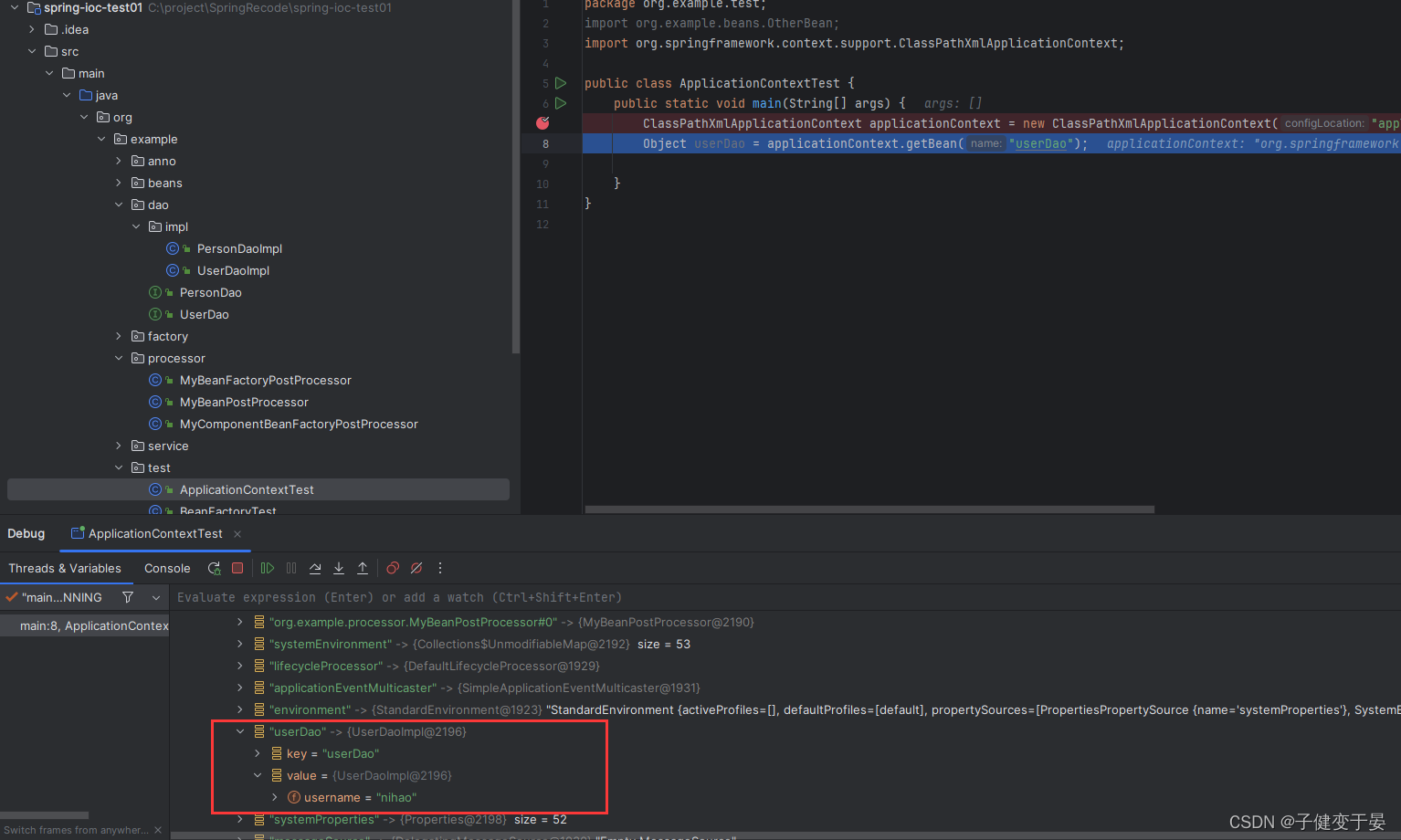
我们发现我们明明没有配置这个属性,但是用BeanPostProcessor就进行干预了。
这里的Bean后处理器的before方法和after方法之间,其实是Bean的初始化,比如我们上方说过的自定义init方法和after方法(需要在配置中进行配置)。
5.4 对Bean方法进行执行时间日志增强
我们需要在Bean方法执行之前控制台打印当前时间,Bean方法执行之后控制台打印当前时间,对方法进行增强主要是代理设计模式和包装设计模式,在Bean实例化完毕后,进入到单例池之前,使用Proxy代替真实的目标Bean。
我们先创建一个TimeLogBeanPostProcessor类,这里涉及到proxy和lambad的编写。
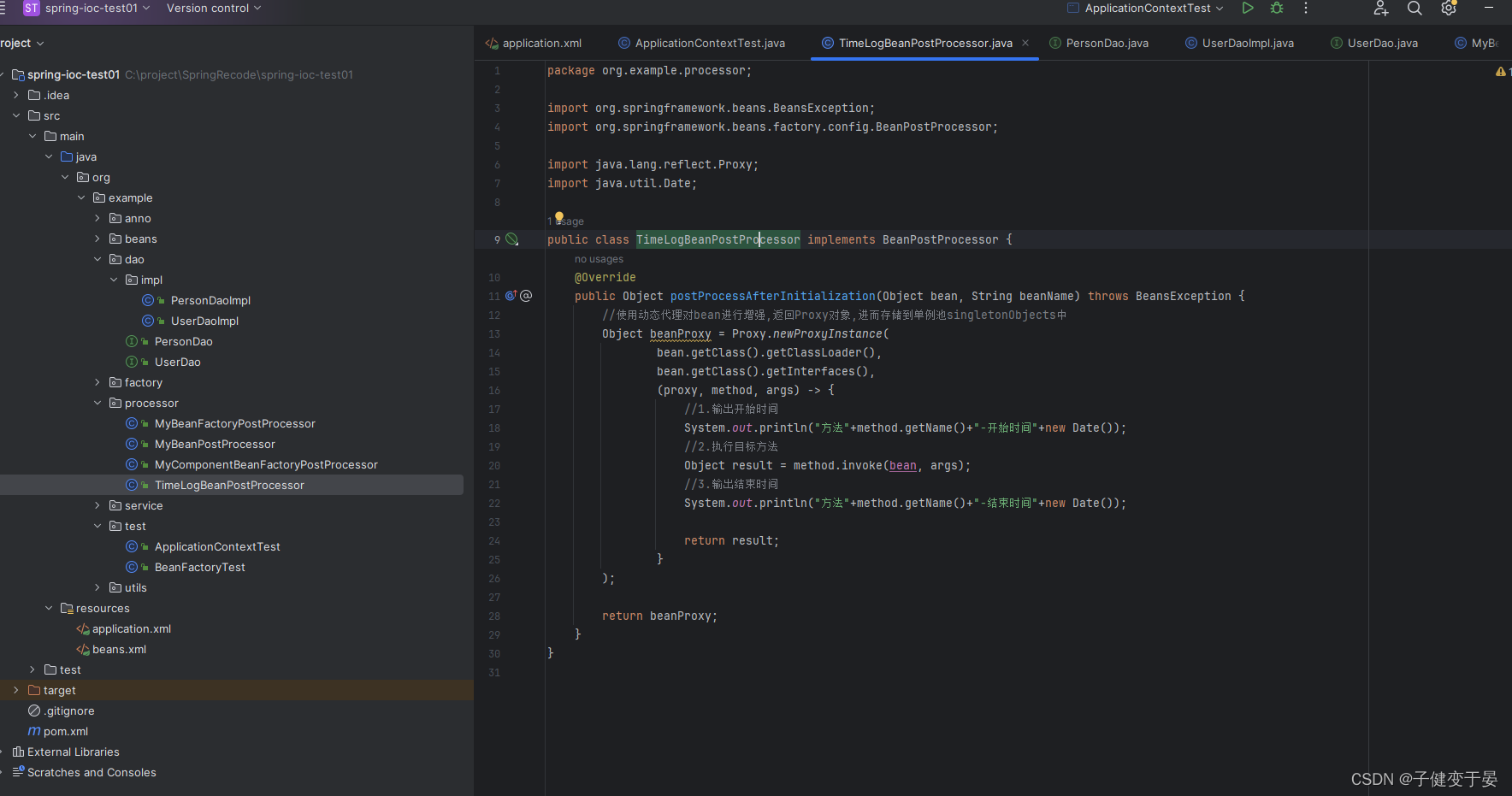
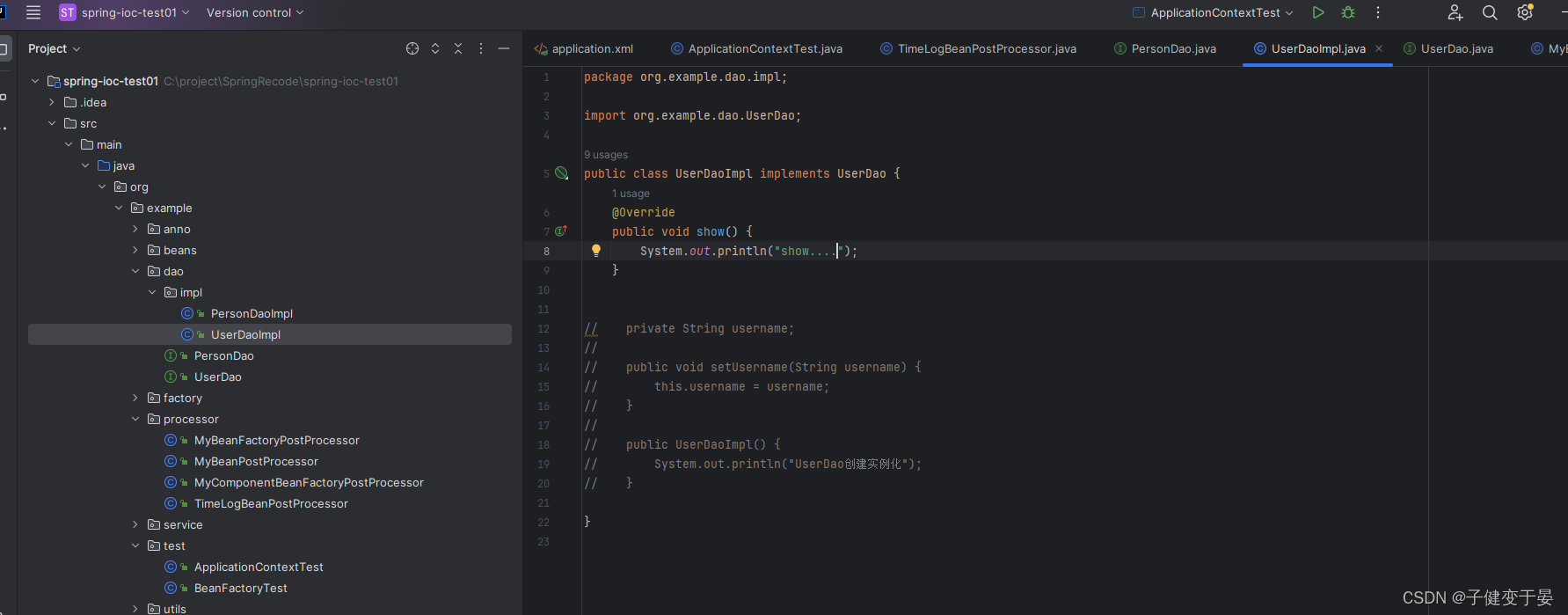
接着在UserDaoImpl写一个show方法。
如果没有配置这个TimeLogBeanPostProcessor,那么运行出来的就是show方法,但是如果我们配置了,那么就可以使用动态代理将方法进行增强(打印开始和结束的时间)。
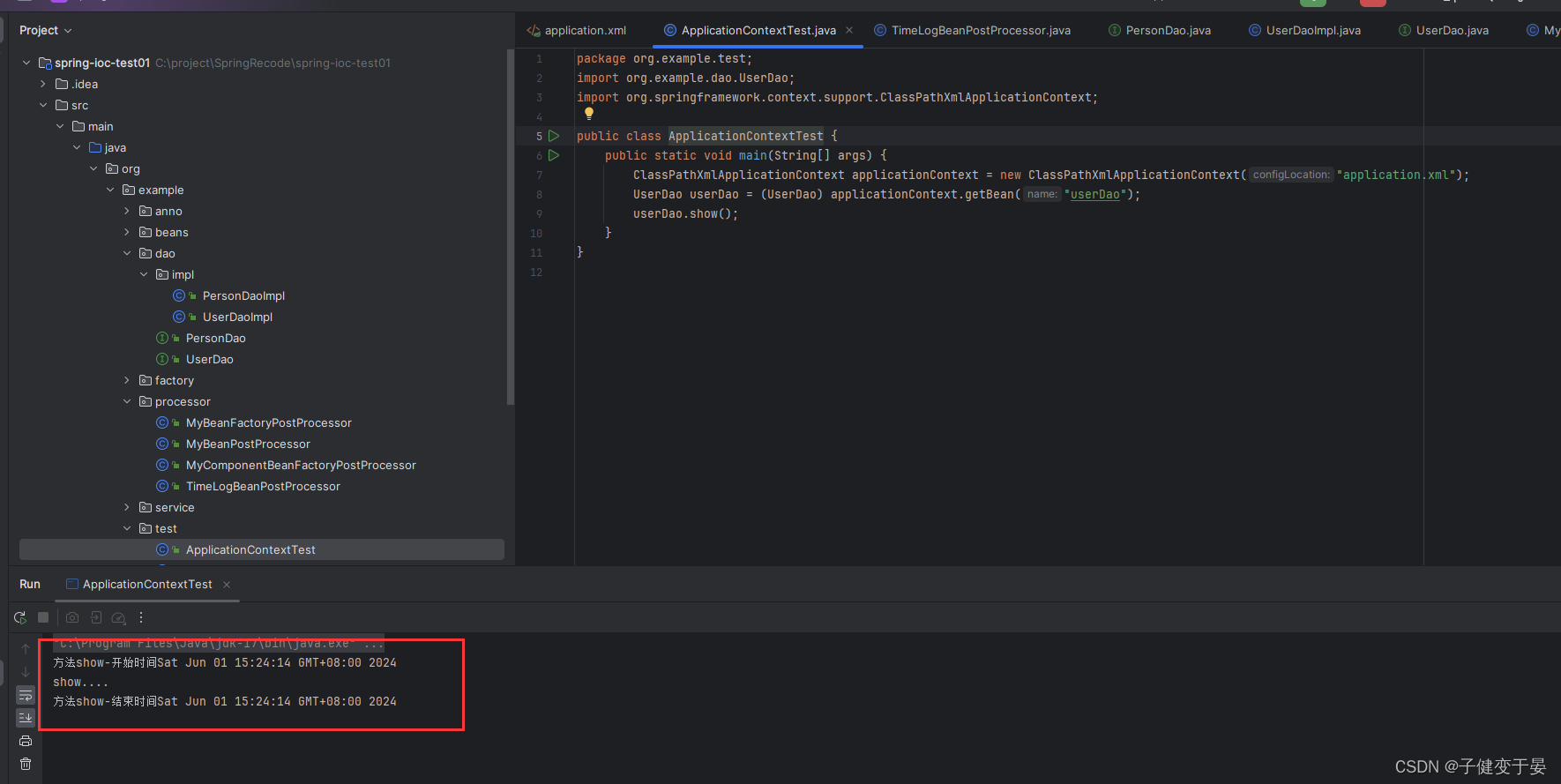
到这里后处理器就讲的差不多了,这个我感觉就是aop的实现,spring的很多功能甚至是第三方框架,都是基于这个后处理器实现的,所以这个是很重要的一点,与别人的差距就可以在这些地方拉开。
6. Spring Bean的生命周期(高频面试题!)
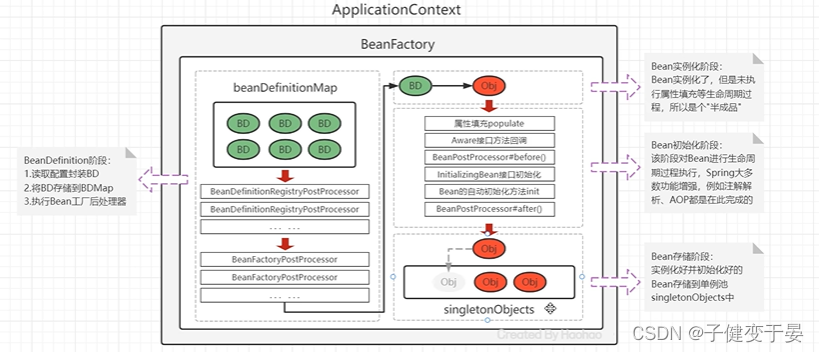
Spring Bean的生命周期是从Bean实例化之后,即通过反射创建出对象之后,到Bean成为一个完整对象,最后存储到单例池中,这个过程被称为Spring Bean的生命周期,大致分为三个阶段。
- Bean的实例化阶段:Spring框架会取出BeanDefinition的信息进行判断当前Bean的范围是否singleton的,是否是延迟加载的,是否不是FactoryBean等,最终将一个普通的singleton的Bean通过反射进行实例化;
- Bean的初始化阶段:Bean创建之后还只是一个"半成品",还需要对Bean实例的属性进行填充、执行一些Aware接口等方法,执行BeanPostProcessor方法、执行InitializingBean接口的初始化、执行自定义初始化init方法等,该阶段是Spring最具有技术含量和复杂度的阶段,Aop增强功能还要后面要学习的Spring的注解功能等;
- Bean的完成阶段:经过初始化阶段,Bean就成为了一个完整的Spring Bean,被存储到单例池singletonObjects中去了,即完成了Spring Bean的生命周期;
6.1 Bean实例的属性填充
在Spring Bean的生命周期中,我们着重的是初始化阶段,而初始化阶段涉及如下过程:
- Bean实例的属性填充
- Aware接口属性注入
- BeanPostProcessor的before()方法回调
- InitializingBean接口的初始化方法回调
- 自定义初始化方法init方法回调
- BeanPostProcessor的after()方法回调
在上述我们以及验证了后四个的执行,以及其顺序,接下来我们讲Bean实例的属性填充。
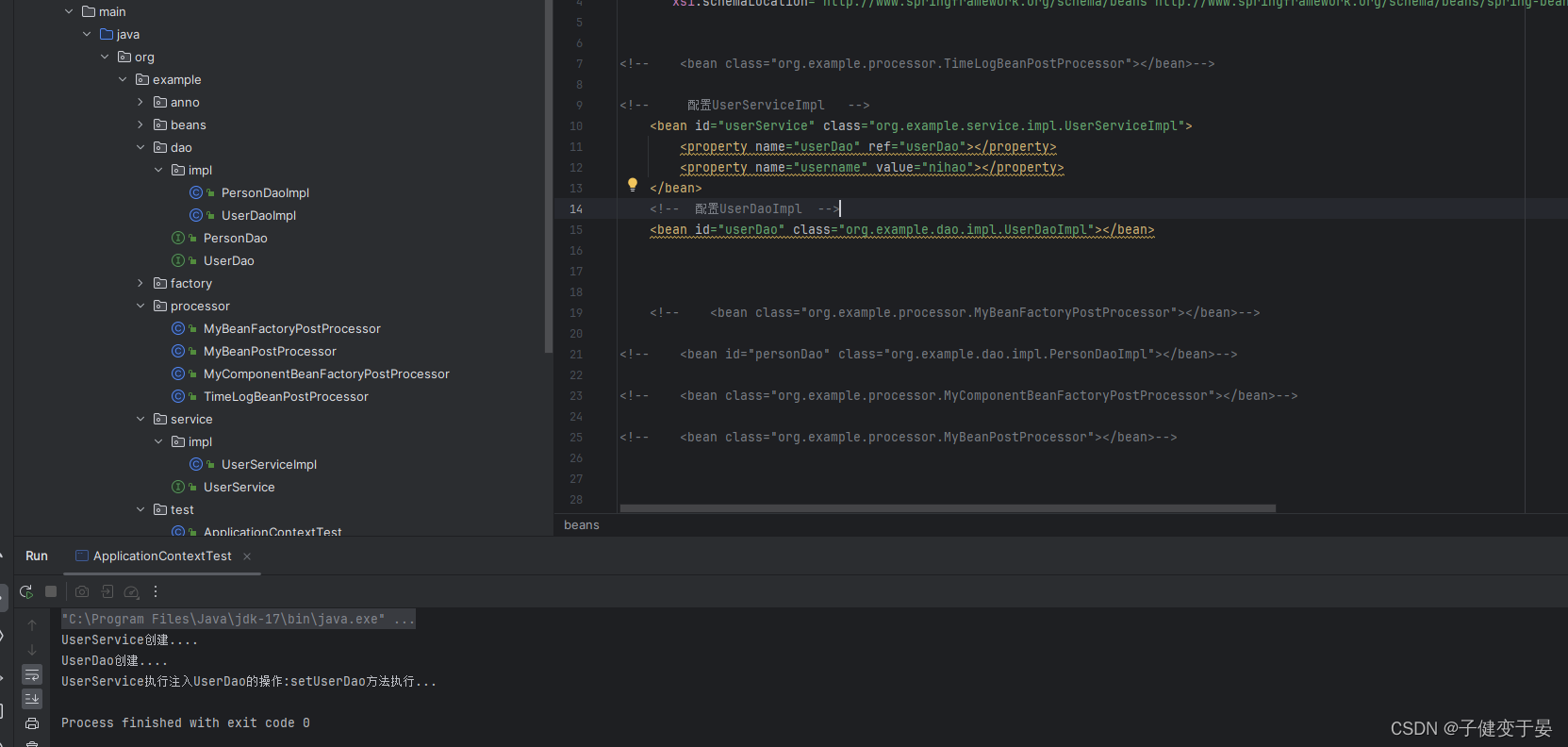
这里我们在UserServiceImpl实例中注入了UserDao和username这两个属性,接下来我们可以去debug验证一下。
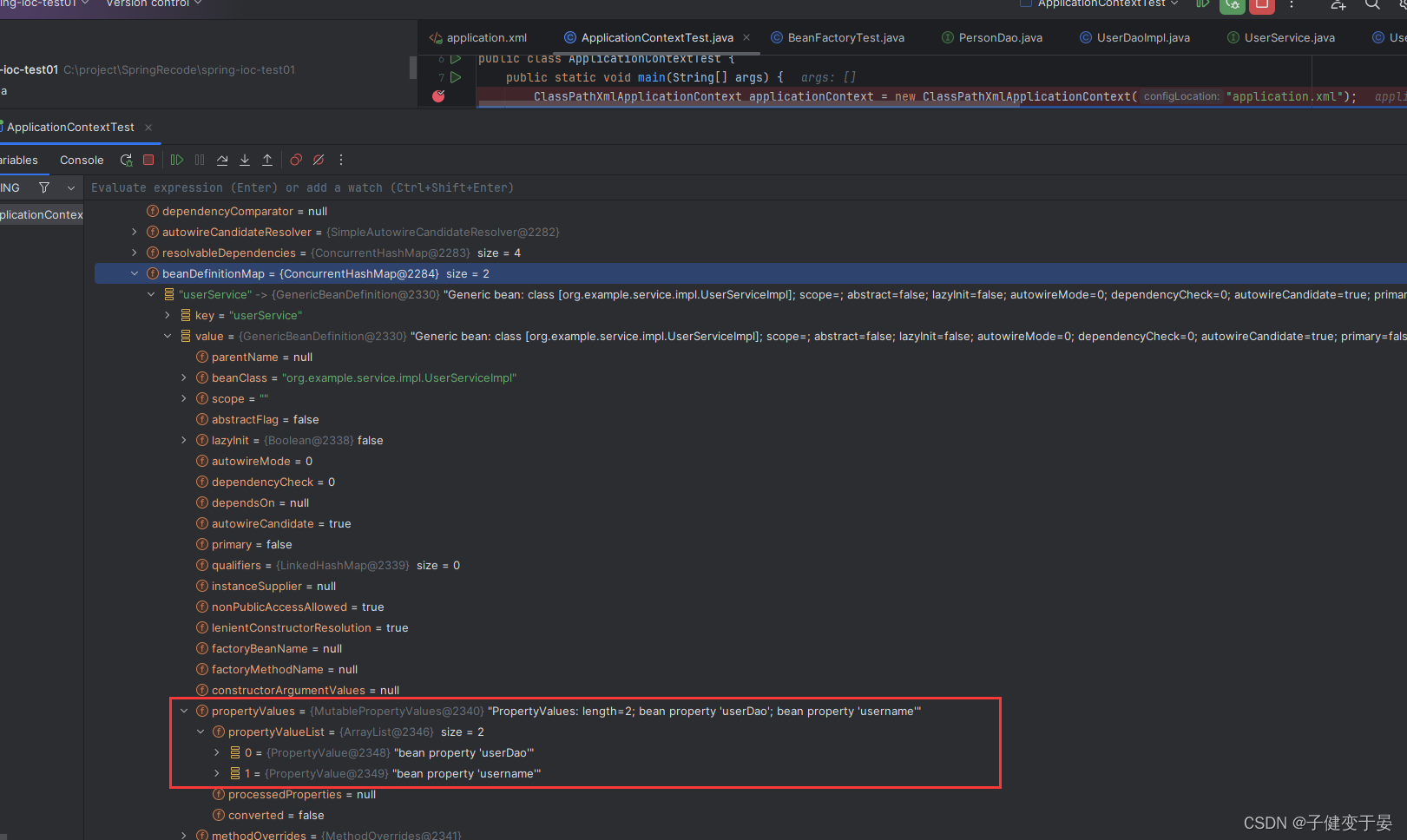
当在配置文件配置要注入的信息时,这些注入的信息也会封装到BeanDefinition中,后期spring容器根据需要的属性,去propertyValues中取即可。
在进行属性填充的时候会有以下几种情况:
- 注入普通属性,String、int或存储基本类型的集合时,直接通过set方法的反射设置进去;
- 注入单向对象引用属性时,从容器中getBean获取后通过set方法反射设置进去,如果容器中没有,则先创建被注入对象Bean实例(完成整个生命周期)后,在进行注入操作;
- 注入双向对象引用属性时,就比较复杂了,涉及了循环引用问题,下面会详细阐述解决方案;
6.1.1 单向属性注入
我们先演示第二种情况,比如上方我UserService注入UserDao时,如果此时还没有UserDao,那么需要等到UserDao创建完毕后,再进行注入操作。
要验证这个我们需要做一些准备工作。
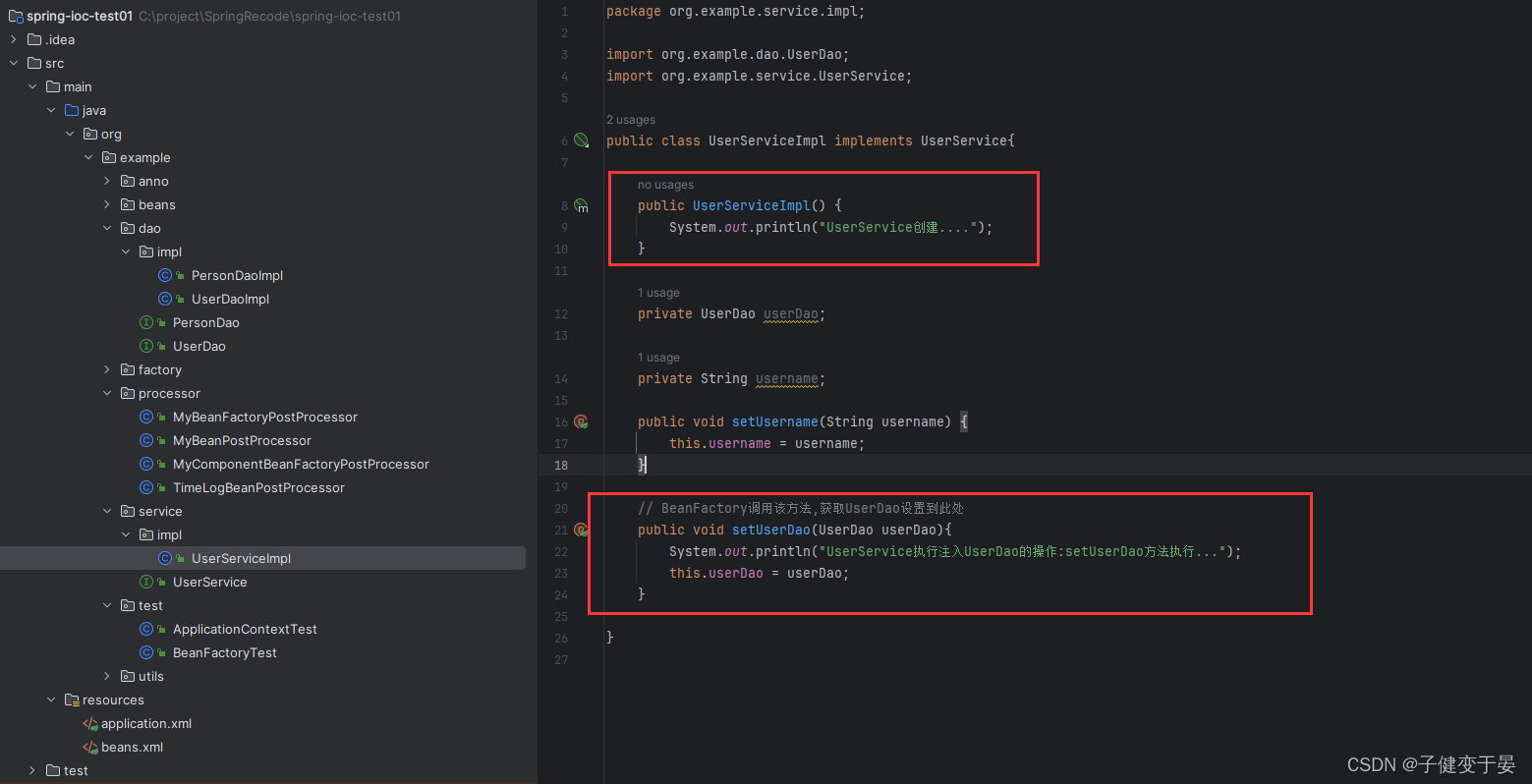
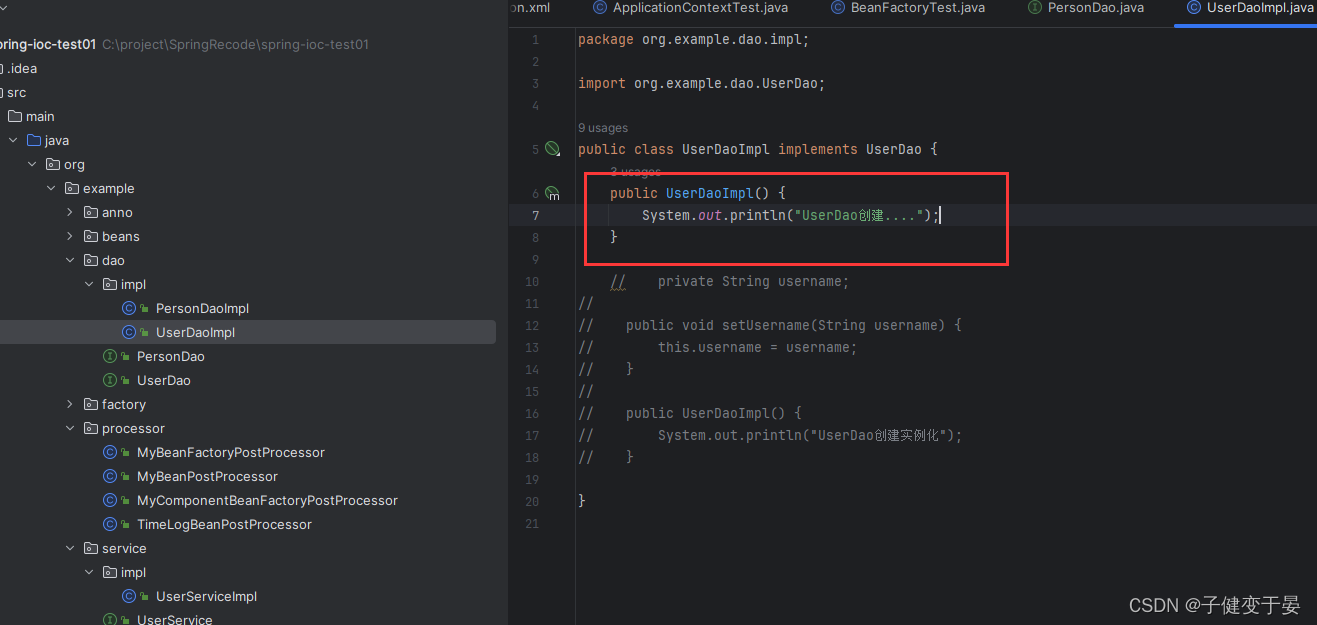
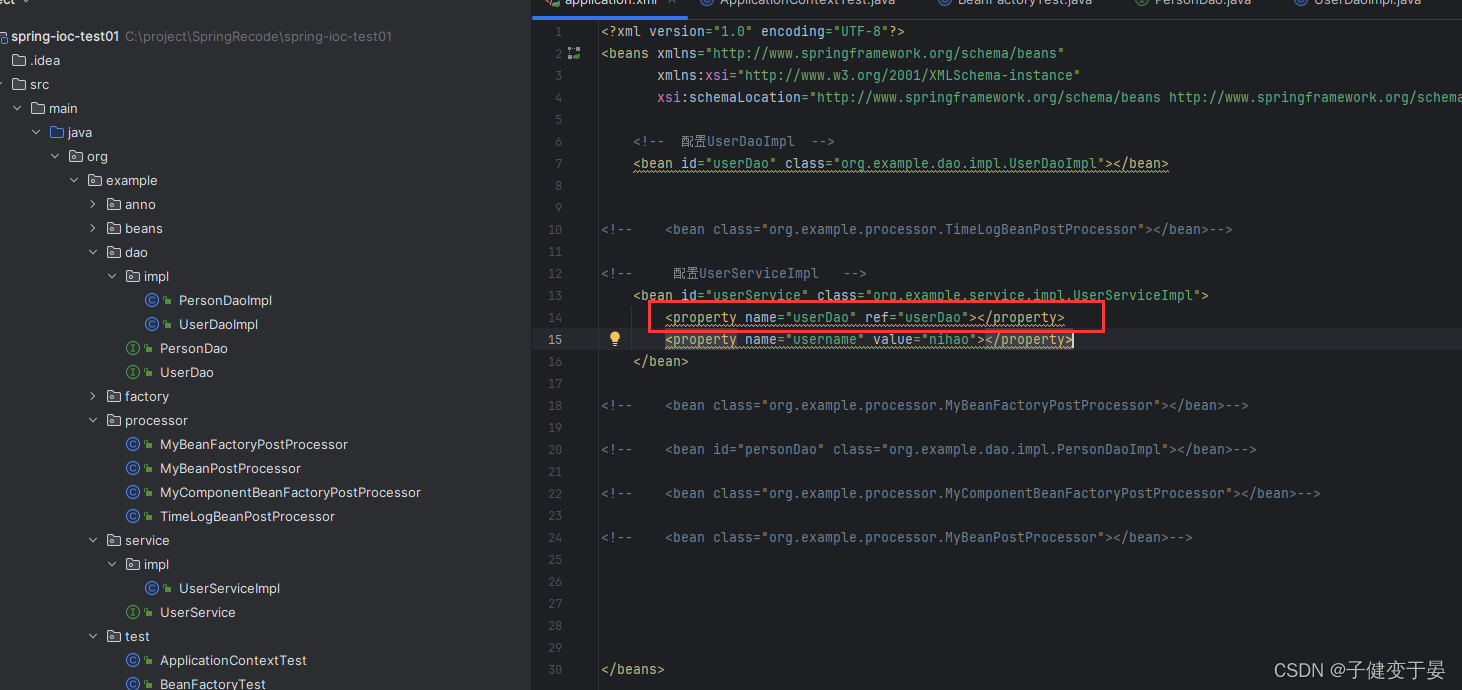
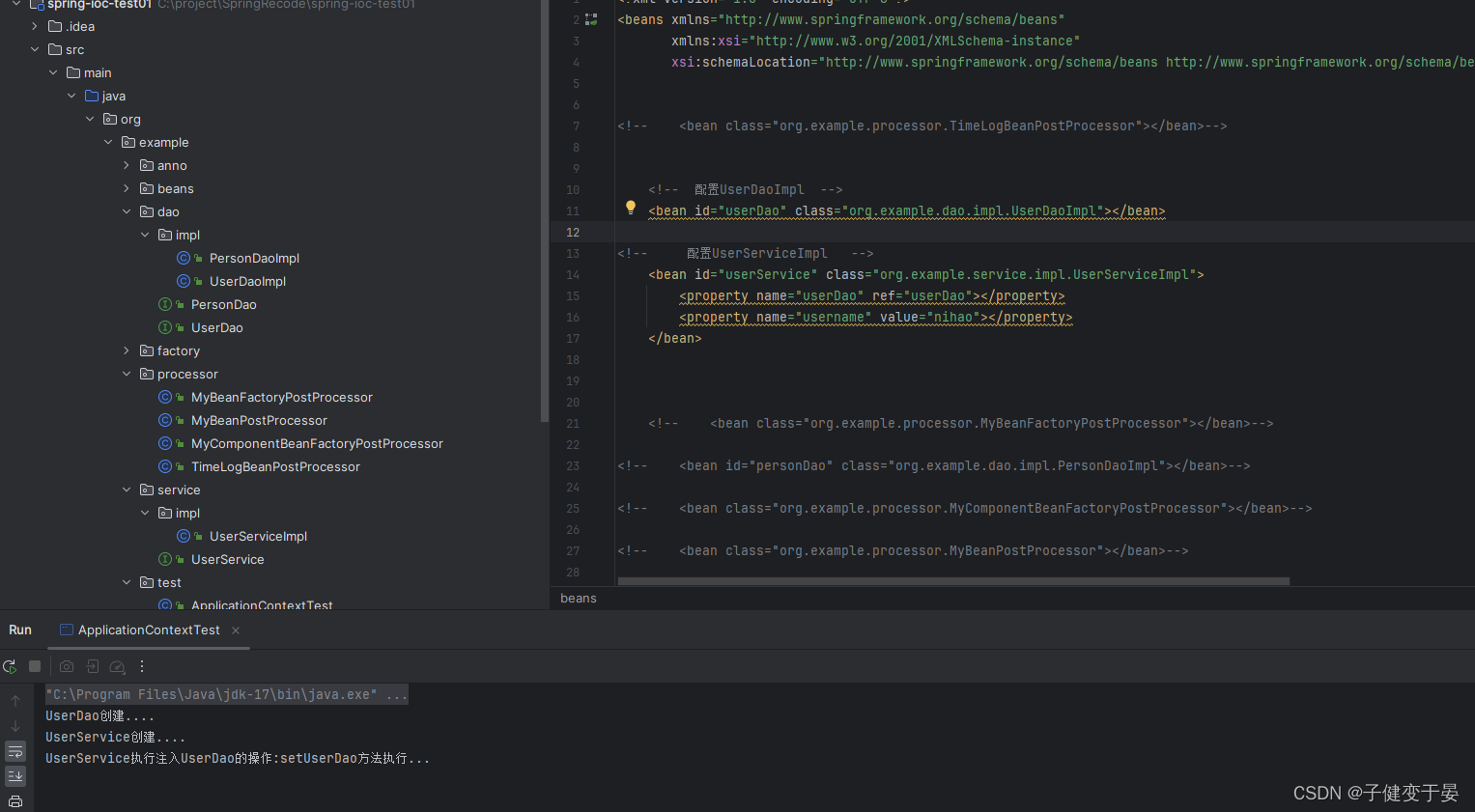
此时我们测试看到UserDao是先创建的,那么我们这样好像看不出来需要验证的点。
我们把配置文件中的顺序调换一下。
再进行测试可以看到我们先创建的是UserService,然后进行它的生命周期,在其中需要注入属性发现有UserDao,但是容器中没有UserDao,所以就先去创建UserDao再执行注入。
6.1.2 双向属性注入(循环依赖问题)!!!

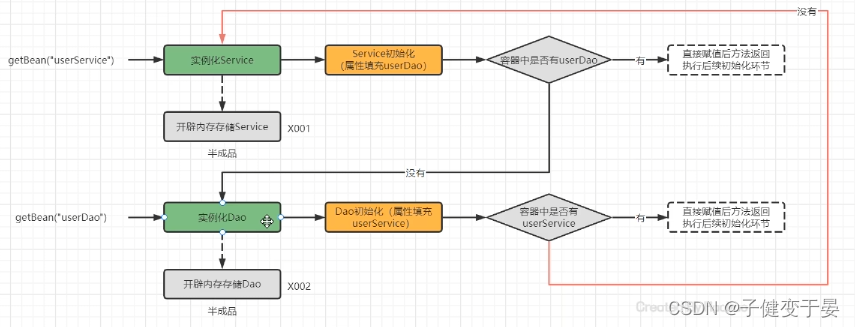
看这张图,就是循环引用的例子,比如我们从上方进入,实例化Service后,需要走其生命周期其中我们需要匝忽然UserDao但是我们容器中没有UserDao,那么我们就需要去创建UserDao,实例化后UserDao后,也需要走它的生命周期,其中需要注入UserService,但是容器中又没有Uservice,又需要去创建UserService(实例化UserService不是创建了UserService将其放入容器中,因为我们需要走完其生命周期,放入到单例池中才是真正创建完毕),这样就构成了循环依赖问题。
从上图看我们可以知道问题出现在判断容器中是否有对应的Bean造成了问题,那么我们可以将没有完全创建好的Bean也就是半成品的Bean先拿来用(类似先将这个盒子拿来用,之后往盒子里填充东西,也可以用的到)。
解决循环引用问题:三级缓存!!!(面试常见)
这就引出了我们常说的Spring三级缓存。
Spring提供了三级缓存存储完整Bean实例和半成品Bean实例,在DefaultListableBeanFactory的上四级父类DefaultSingletonBeanRegistry中提供如下三个Map:
- Map<String,Object> singletonObjects = new ConcurrentHashMap<256>//存储单例Bean成品容器,实例化和初始化都完成的Bean,称之为一级缓存。
- Map<String,Object> earlySingletonObjects = new ConcurrentHashMap<16>//早期Bean单例池,缓存半成品对象,且当前对象已经被其他对象引用了,称之为二级缓存。
- Map<String,ObjectFactory<?>> singletonFactories = new HashMap(16)//单例Bean的工厂池,缓存半成品对象,对象未被引用,使用时在通过工厂创建Bean,称之为三级缓存。
我们继续看这幅图,从上方开始,当实例化Service的时候,将其放入三级缓存中,将其进行简单的包装一下,放入三级缓存中,之后需要用到就调用singletonFactories中的ObjectFactory方法,这个时候的对象是没有被引用的。
接下来就需要注入UserDao(UserDao和Service一样操作放入三级缓存),从一级缓存开始找-->二级缓存-->三级缓存,在三级缓存中找到将其注入到Service,并且将Service从三级缓存中移除放入到二级缓存中,这个时候这个对象是被引用的半成品对象。
最后执行赋值后返回执行后续的初始化,最终放入一级缓存。
所以整个的流程是这样的:
- UserService实例化对象,但尚未初始化,将UserService存储到三级缓存;
- UserService属性注入,需要UserDao,从缓存中获取,没有UserDao;
- UserDao实例化,但尚未初始化,将UserDao存储到三级缓存;
- UserDao属性注入,需要UserService,从三级缓存中获取到UserService,UserService从三级缓存移入二级缓存;
- UserDao执行其他生命周期过程,最终成为一个完整的Bean,存储到一级缓存,删除二三级缓存
- UserService注入UserDao;
- UserService执行其他生命周期,最终成为一个完整的Bean,存储到一级缓存,删除二三级缓存;
接下来放出一张图:Spring IoC容器实例化Bean整体流程
7. Spring整合第三方框架
Spring xml方式整合第三方框架有两种整合方案:
- 不需要自定义名空间,不需要使用Spring的配置文件配置第三方框架本身内容,例如:MyBatis;
- 需要引入第三方框架命名空间,需要使用Spring的配置文件配置第三方框架本身内容,例如:Dubbo;
下面我们主要演示Spring整合MyBatis。
我们先来看看原始的方式开发MyBatis是怎么样的。
首先我们需要有一张对应的表。
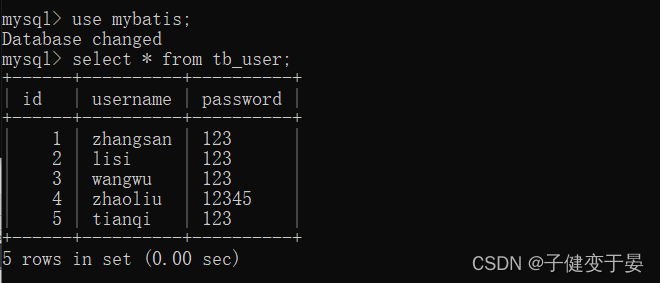
接着我们需要有这个表对应的对象。
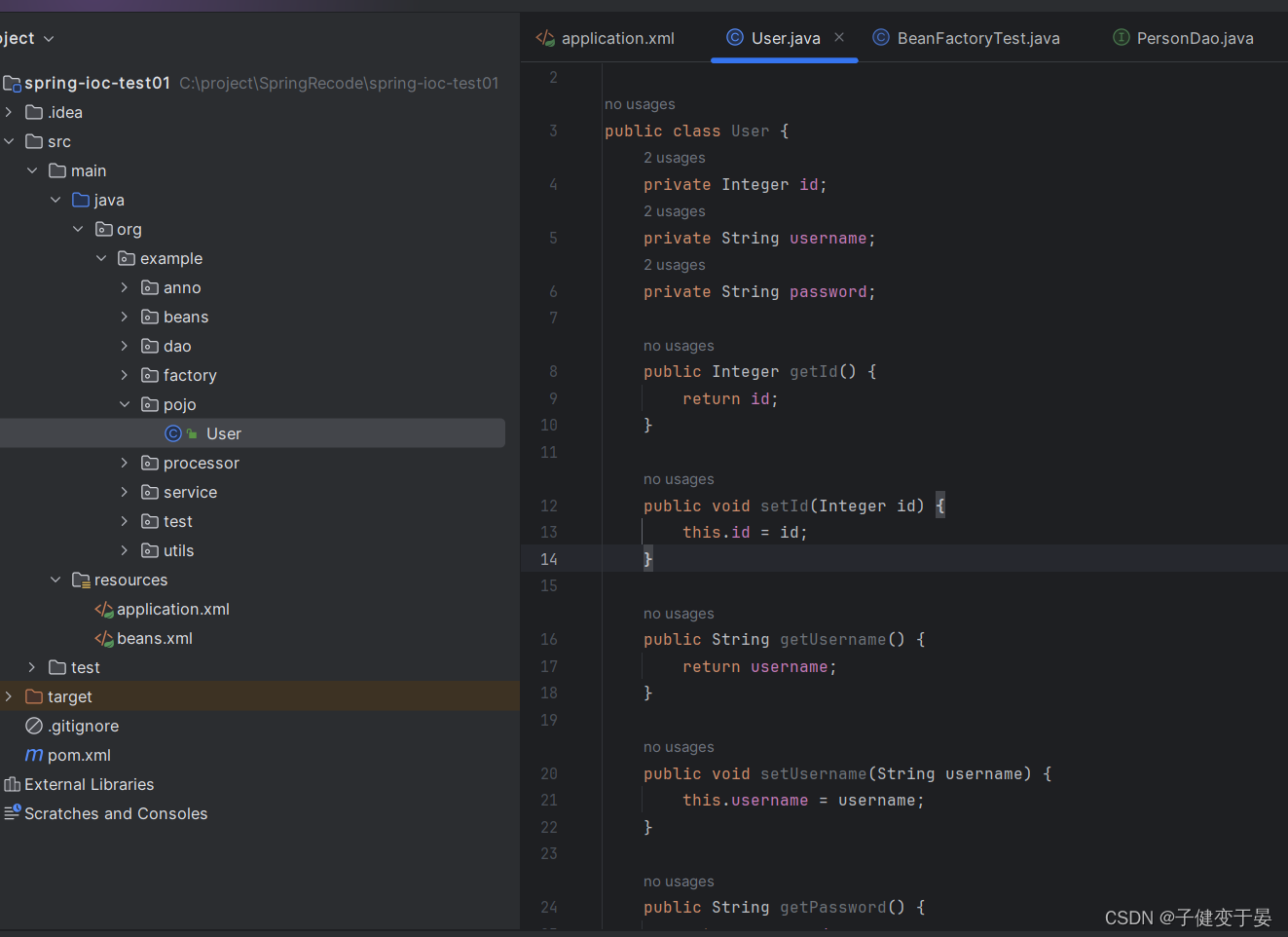
接着我们需要在mapper中进行操作。
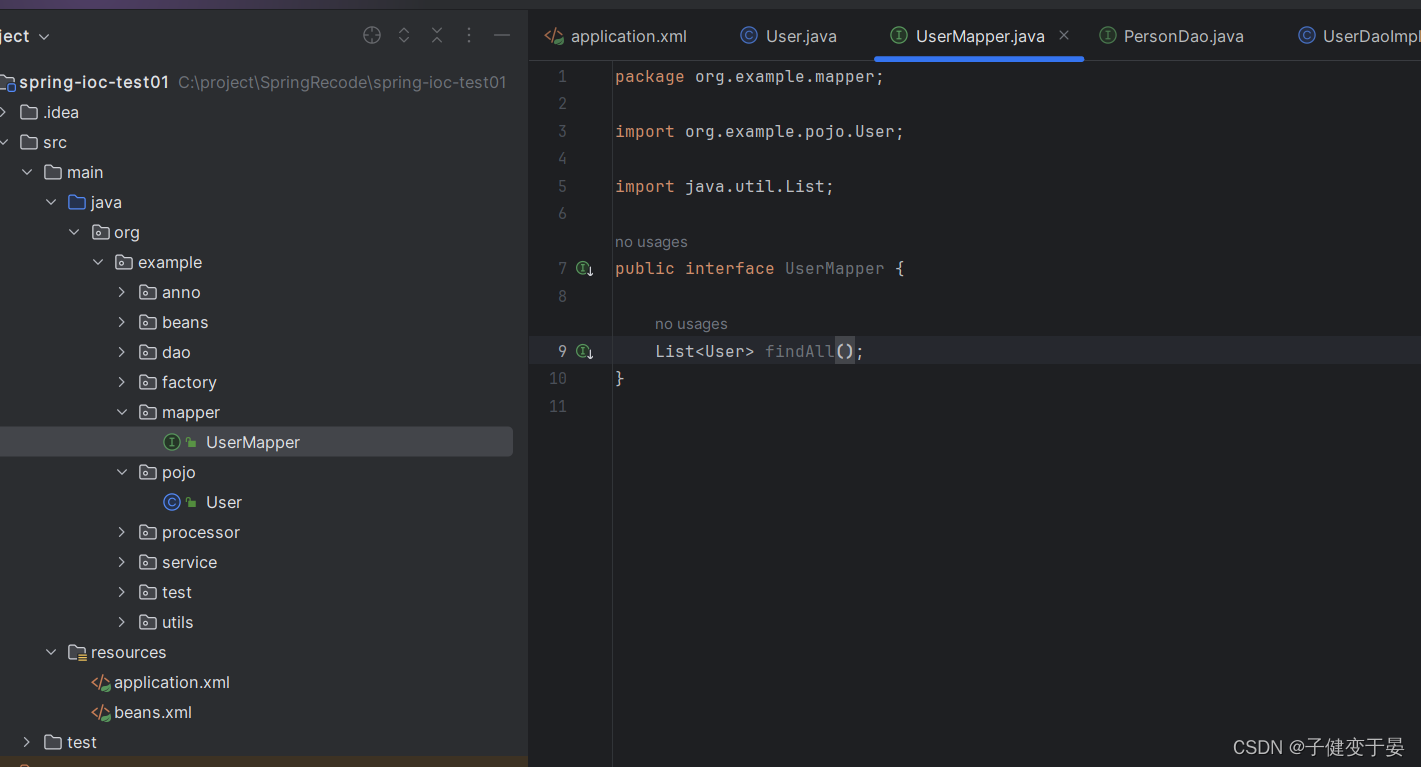
并且这个mapper接口需要有对应的xml文件。
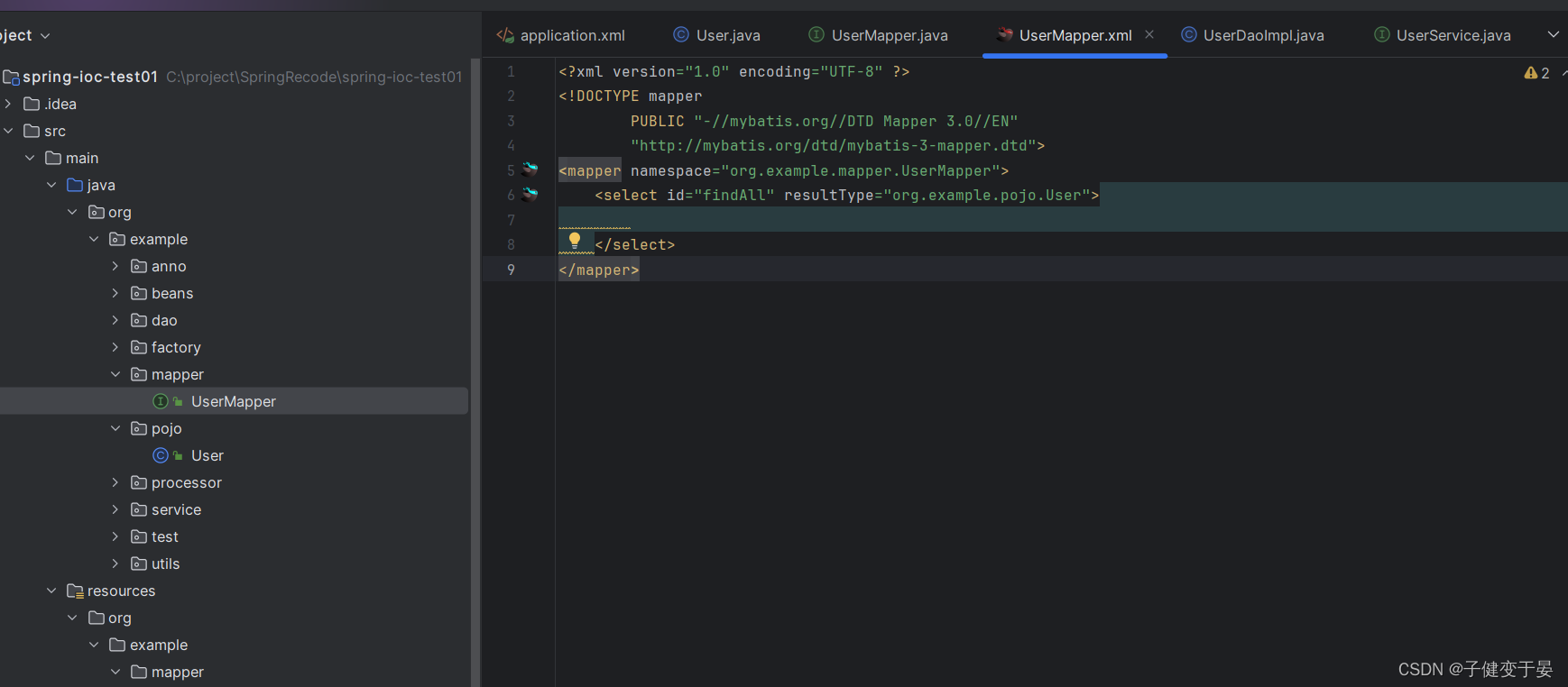
还需要在mybatis配置文件中将刚刚的xml文件配置进去(扫描到)。
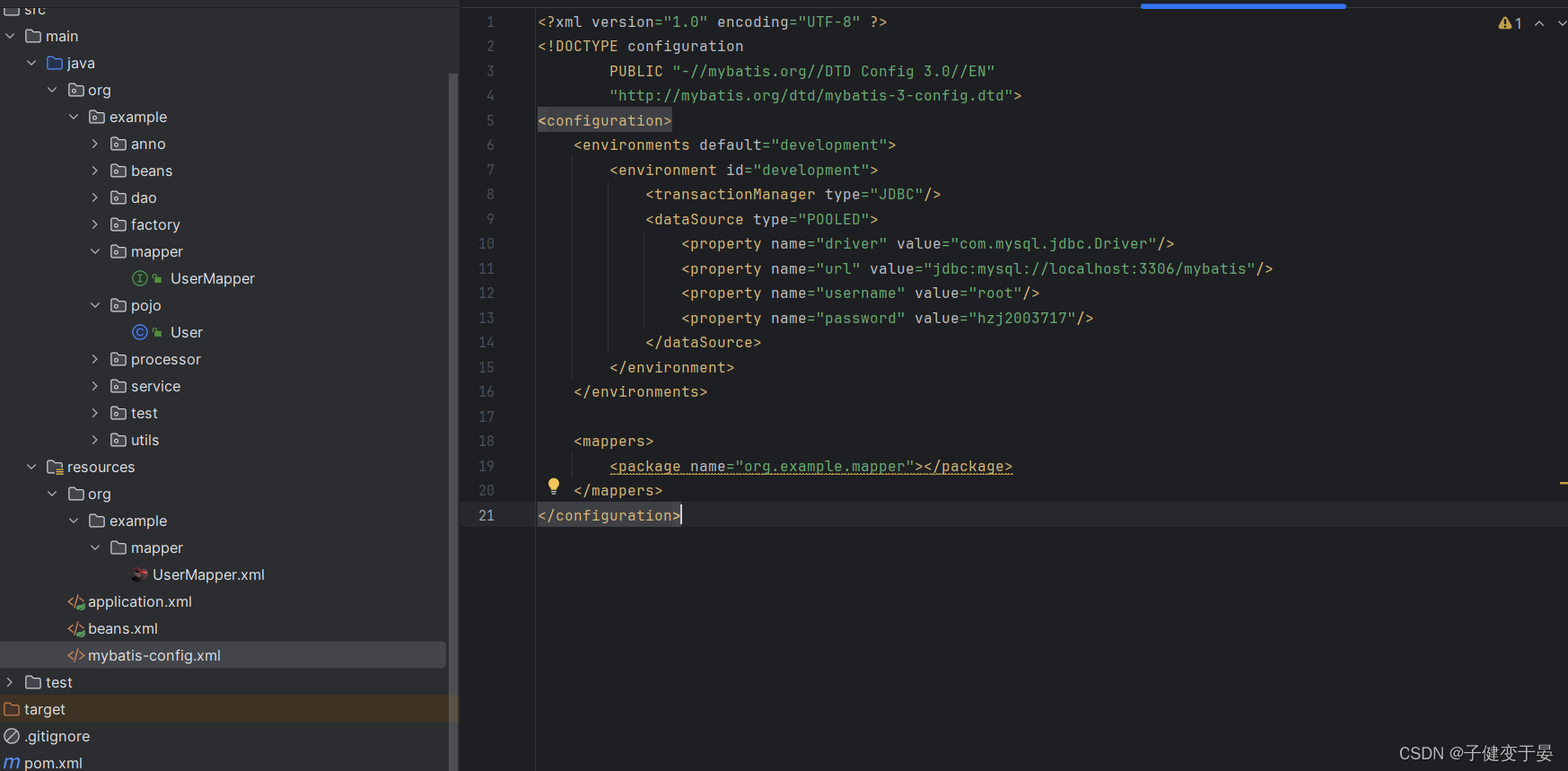
最后写客户端代码。

最后才能拿到数据库中的数据。
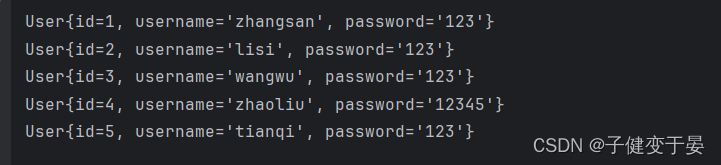
我们可以发现这种原始的方式,非常的麻烦,我们想要将上方的代码都消除掉,将mybatis-config.xml这个配置文件都加入到spring的配置中。
7.1 Spring整合MyBatis
Spring整合MyBatis我们分为以下步骤:
- 导入MyBatis整合Spring的相关坐标;
- 编写Mapper和Mapper.xml;
- 配置SqlSessionFactoryBean和MapperScannerConfiguer;
- 编写测试代码;
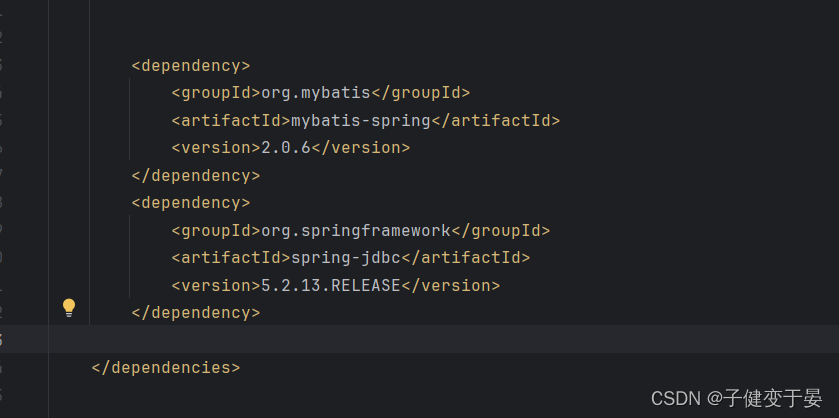
编写Mapper和Mapper.xml我们之前就写好了。
接着配置SqlSessionFactoryBean是为了获得SqlSessionFactory,进而获得SqlSession从而获得Mapper。
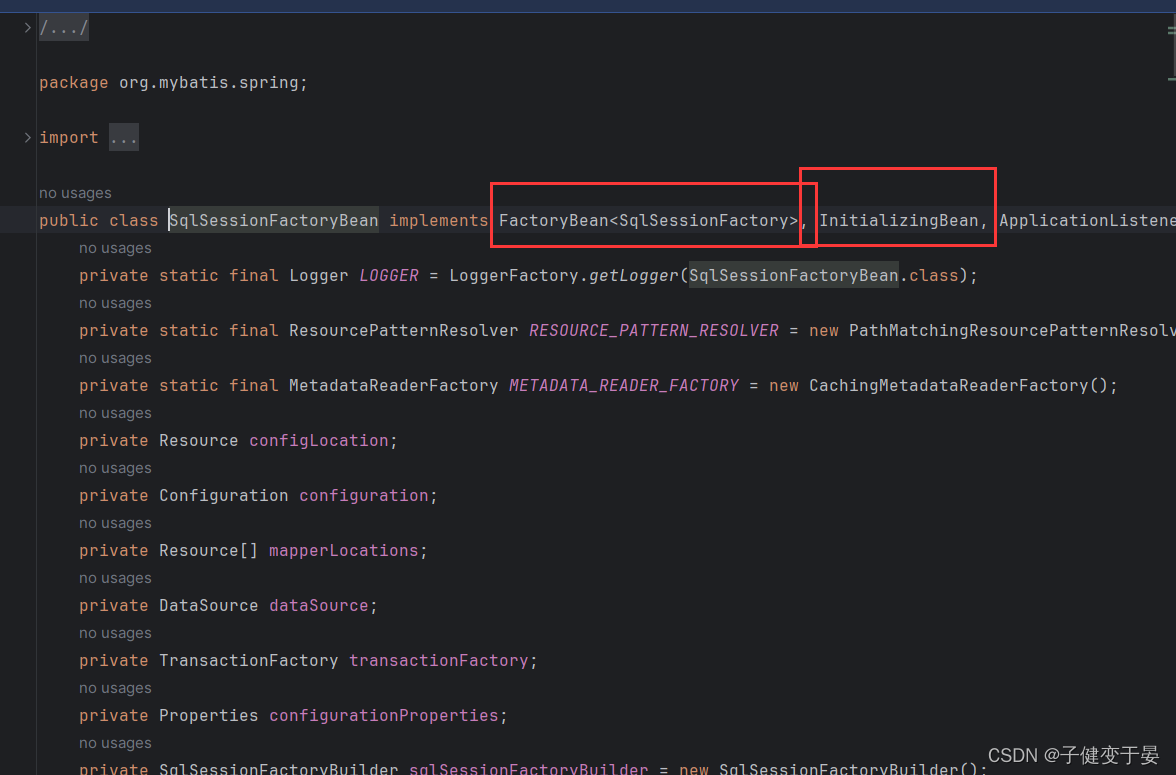
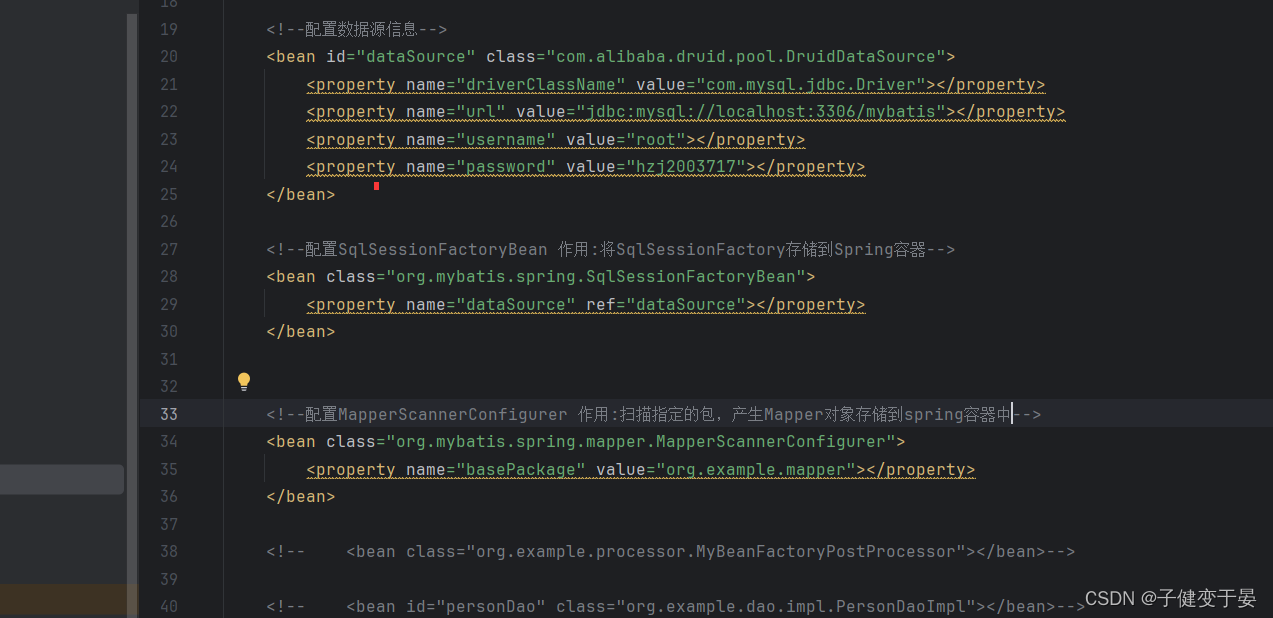
然后我们配置MapperScannerConfiguer是为了将Mapper对象存储到Spring容器中的(也就是不用写之前那么复杂的mybatis客户端代码,直接能获取到mapper了)。
从这两幅源码图中我们可以也看到我们之前讲过的熟悉的"老伙伴"。
那么我们将其配置一下。
接下来我们就可以很方便的使用了。
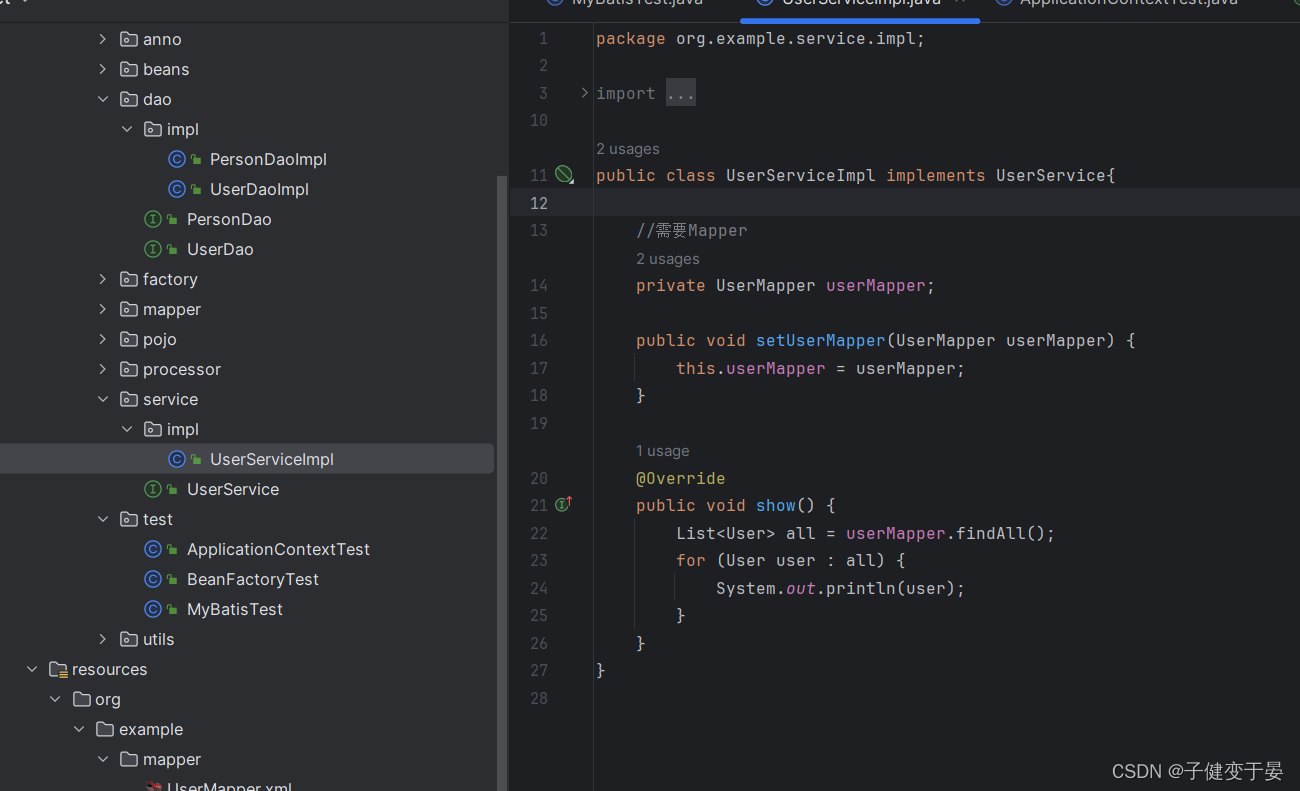
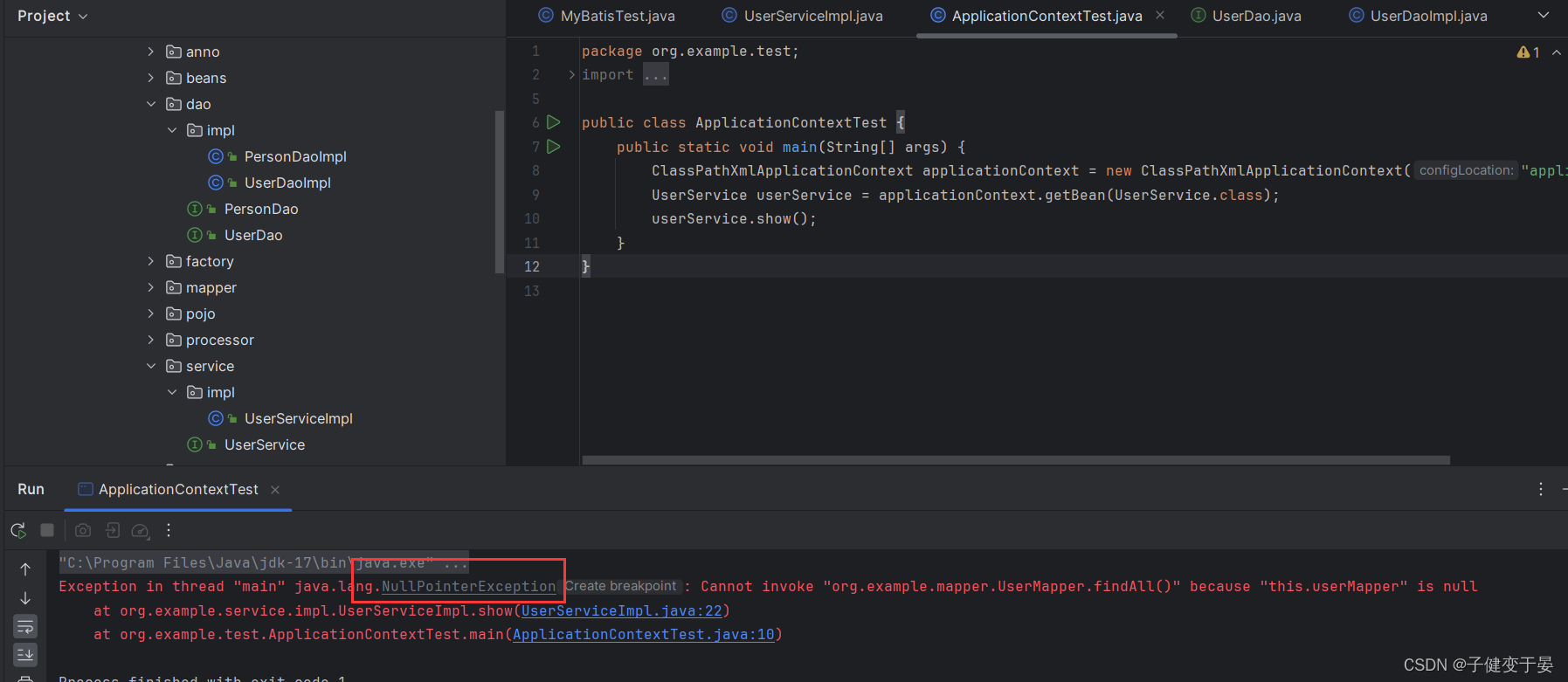
但是这里显示show为空,也就是mapper为空,原因是我们没有在UserService中配置mapper,可以去配置文件中配置。

我们配置信息中明明没有userMapper但是却可以配置进去,这就是MapperScannerConfigurer的功劳了,扫描指定的包,将产生的Mapper对象存储到Spring容器中。

这样比原始的mybatis开发简单多了。
7.2 加载外部properties文件
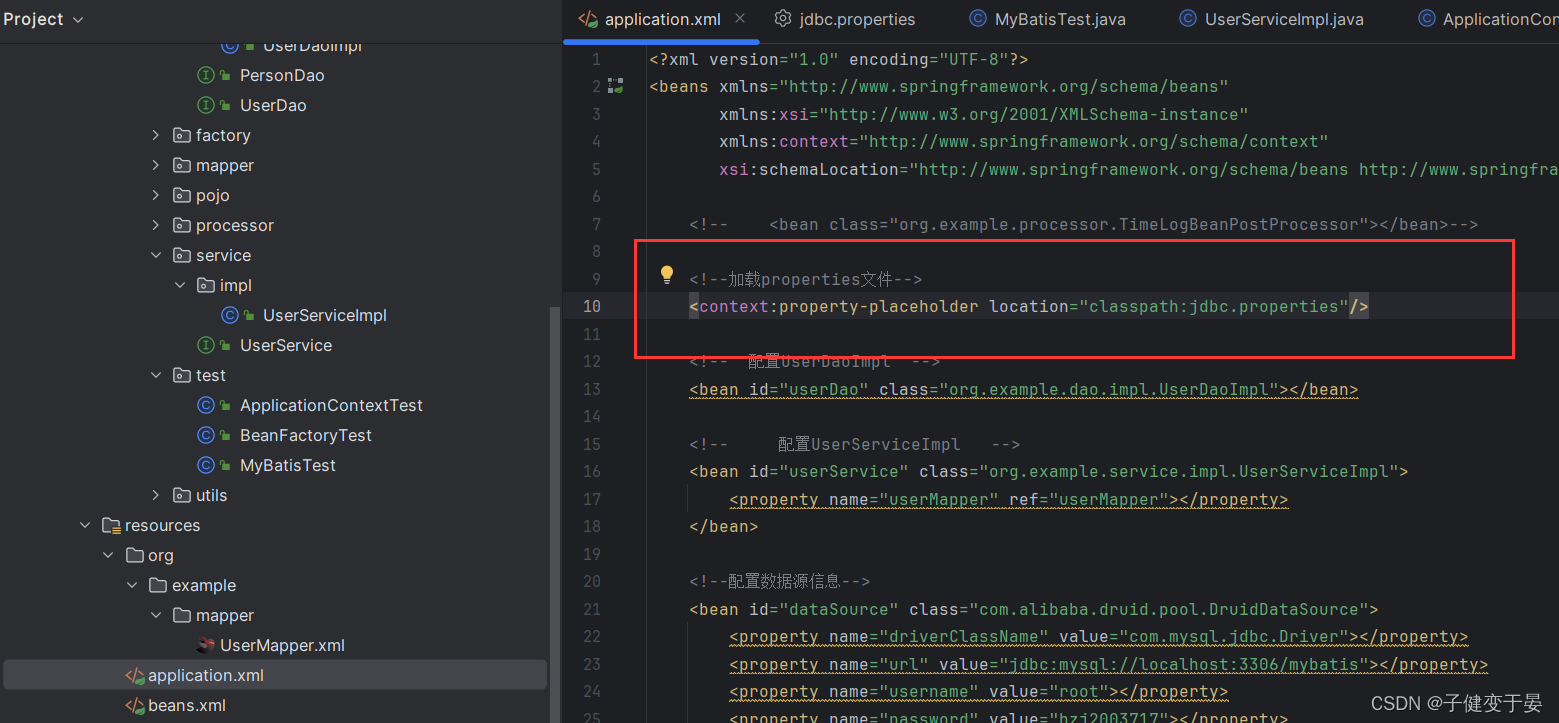
接着就可以将properties中配置的数据以键值对的形式放到了spring容器中。

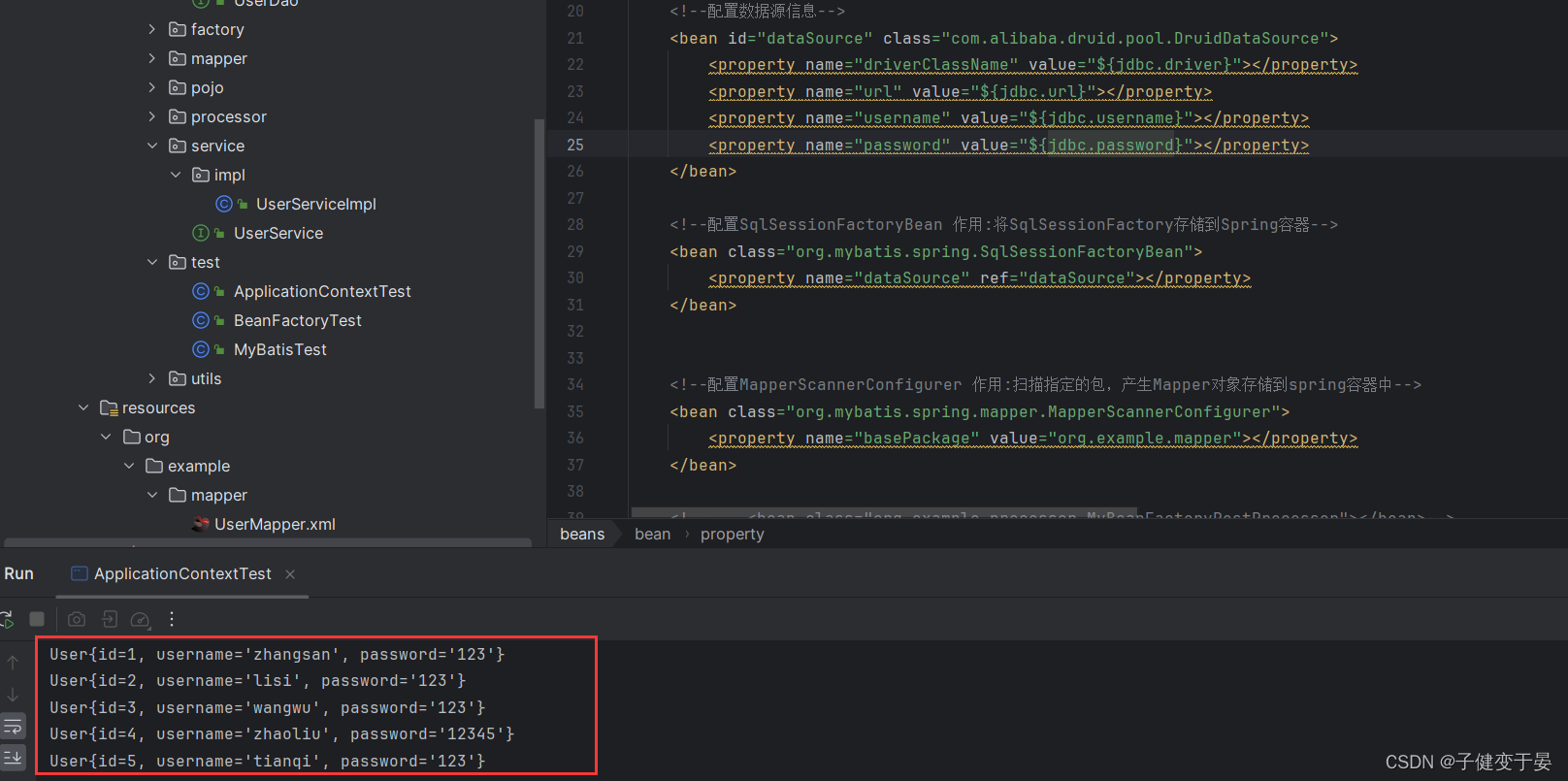
这里的使用的方式是自定义命名空间的方式进行加载的,这里我们用到了context这个自定义命名空间
在黑马下面的课程中有做一个demo,实现某一个框架与spring的集成开发。这里我实在解释不来,涉及到源码的理解,有兴趣的可以去看看。
那么到这里基于xml的spring的应用就总结完毕了。