1. 生产者发送消息源码分析
java
public class SimpleProducer {
public static void main(String[] args) {
Properties pros=new Properties();
pros.put("bootstrap.servers","192.168.8.144:9092,192.168.8.145:9092,192.168.8.146:9092");
// pros.put("bootstrap.servers","192.168.8.147:9092");
pros.put("key.serializer","org.apache.kafka.common.serialization.StringSerializer");
pros.put("value.serializer","org.apache.kafka.common.serialization.StringSerializer");
// 0 发出去就确认 | 1 leader 落盘就确认| all(-1) 所有Follower同步完才确认
pros.put("acks","1");
// 异常自动重试次数
pros.put("retries",3);
// 多少条数据发送一次,默认16K
pros.put("batch.size",16384);
// 批量发送的等待时间
pros.put("linger.ms",5);
// 客户端缓冲区大小,默认32M,满了也会触发消息发送
pros.put("buffer.memory",33554432);
// 获取元数据时生产者的阻塞时间,超时后抛出异常
pros.put("max.block.ms",3000);
// 创建Sender线程
Producer<String,String> producer = new KafkaProducer<String,String>(pros);
for (int i =0 ;i<1000000;i++) {
producer.send(new ProducerRecord<String,String>("mytopic",Integer.toString(i),Integer.toString(i)));
// System.out.println("发送:"+i);
}
//producer.send(new ProducerRecord<String,String>("mytopic","1","1"));
//producer.send(new ProducerRecord<String,String>("mytopic","2","2"));
producer.close();
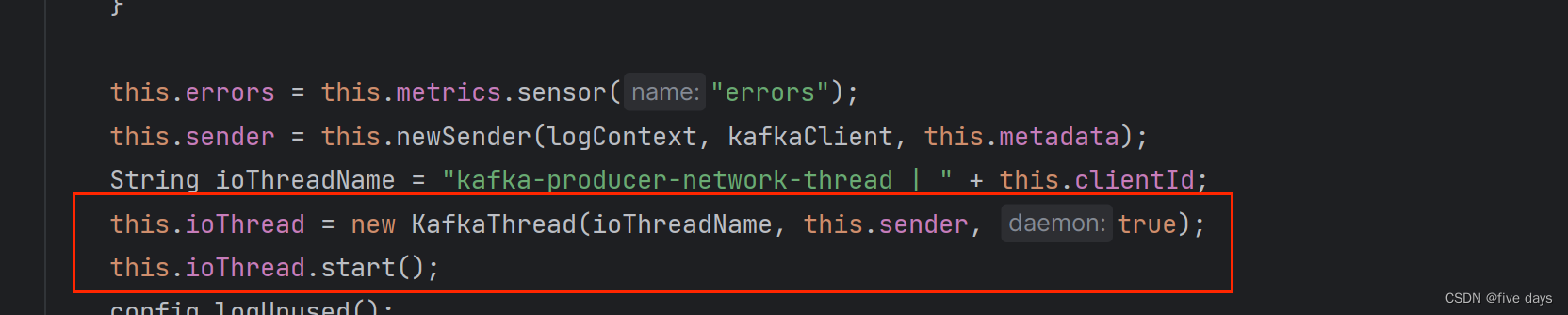
}a. 首先我们是创建一些kafka的连接配置以及参数配置,然后先new出来一个生产者,创建一个sender线程,由下图源码可以看出,我们在new生产者的时候,kafak会帮我们船舰一个sender线程,并进行了命名和启动
b.随后我们的main线程中,进行批量send发送,那么接下来我们看下send方法

可以看到,在send方法中,还有一个interceptors做了一个拦截器的处理, 那么拦截器应该怎么使用的呢?
我们只需要实现ProducerInterceptor中的onsend方法,并且在kafka send消息前进行配置就可以了
java
public class ChargingInterceptor implements ProducerInterceptor<String, String> {
// 发送消息的时候触发
@Override
public ProducerRecord<String, String> onSend(ProducerRecord<String, String> record) {
System.out.println("1分钱1条消息,不管那么多反正先扣钱");
return record;
}
带有拦截器的kafka demo
java
public static void main(String[] args) {
Properties props=new Properties();
props.put("bootstrap.servers","192.168.8.144:9092,192.168.8.145:9092,192.168.8.146:9092");
// props.put("bootstrap.servers","192.168.8.147:9092");
props.put("key.serializer","org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer","org.apache.kafka.common.serialization.StringSerializer");
// 0 发出去就确认 | 1 leader 落盘就确认| all 所有Follower同步完才确认
props.put("acks","1");
// 异常自动重试次数
props.put("retries",3);
// 多少条数据发送一次,默认16K
props.put("batch.size",16384);
// 批量发送的等待时间
props.put("linger.ms",5);
// 客户端缓冲区大小,默认32M,满了也会触发消息发送
props.put("buffer.memory",33554432);
// 获取元数据时生产者的阻塞时间,超时后抛出异常
props.put("max.block.ms",3000);
// 添加拦截器
List<String> interceptors = new ArrayList<>();
interceptors.add("com.zsc.mq.kafka.javaapi.interceptor.ChargingInterceptor");
// 这个键就是拦截器的配置,因为拦截器是个list,因此可以实现多个拦截器
props.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, interceptors);
Producer<String,String> producer = new KafkaProducer<String,String>(props);
producer.send(new ProducerRecord<String,String>("mytopic","1","1"));
producer.send(new ProducerRecord<String,String>("mytopic","2","2"));
producer.close();
}
}c. send方法走完拦截器后,我们进入到dosend方法中,接着看

可以看到,kafka对我们的消息进行了一个序列化,那么序列化方式就是在我们初始配置参数的时候进行配置的,可以指定不同的序列化方式,并且也可以自定义序列化方式,实现序列化接口,增加到配置类中即可

d. 看完序列化,我们的消息发送接着往下面走, 进入到分区器流程



由上面可知,我们的分区器如果指定了分区就会走我们指定的分区;消息没有指定分区但是自定义了消息分区器,就会走到消息分区器中,自定义消息器代码如下(实现partitioer接口即可):
java
public class SimplePartitioner implements Partitioner {
public SimplePartitioner() {
}
@Override
public void configure(Map<String, ?> configs) {
}
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
String k = (String) key;
System.out.println(k);
if (Integer.parseInt(k) % 2 == 0){
return 0;
}else{
return 1;
}
// return Integer.parseInt(k)%2;
}
@Override
public void close() {
}还有第三个情况,既没有指定也没有自定义分区器。那么key不为空,那就是走hash取模算法;key也会空的话,就是采用粘连策略(根据topic来确定在哪里存储)
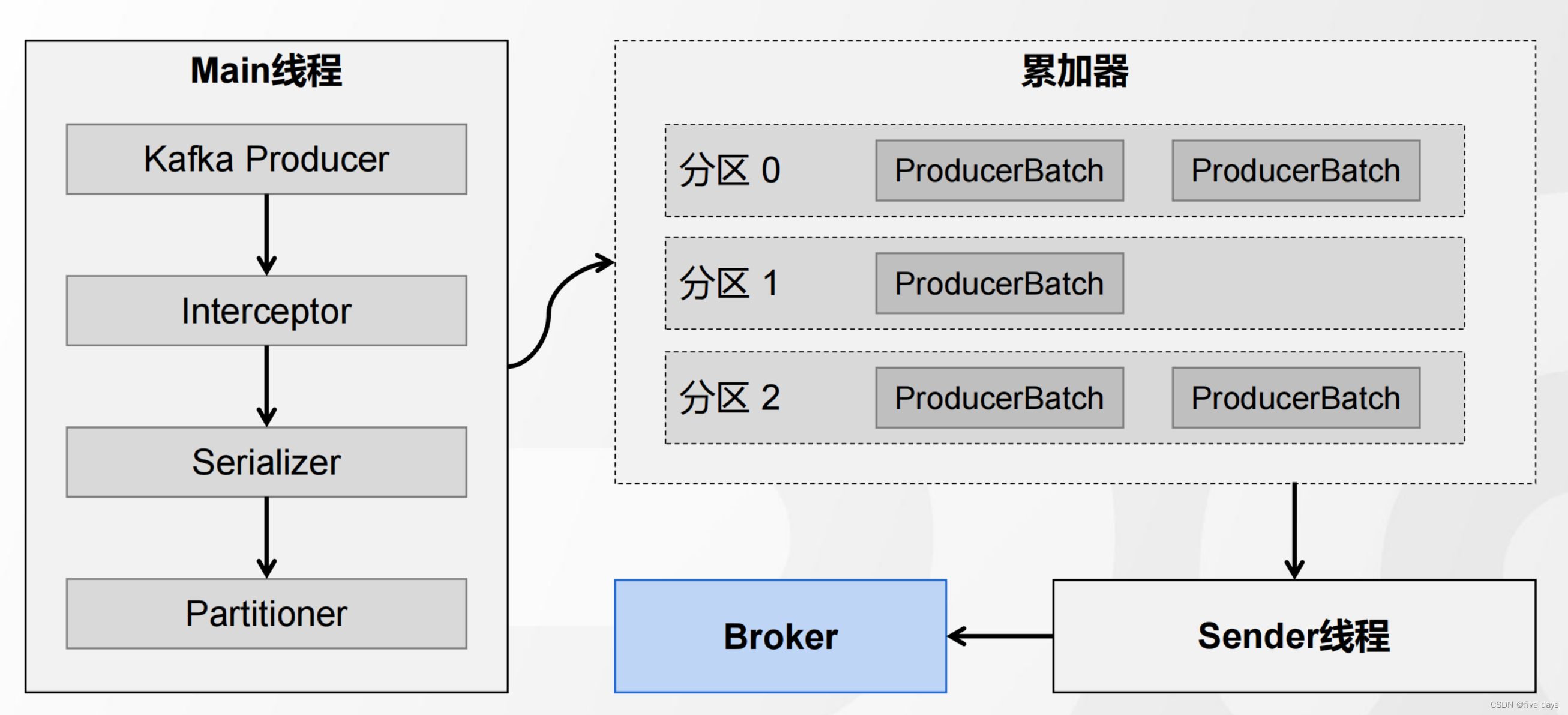
e. 当我们消息的分区器走完之后,就进入到我们的累加器,在上篇博客MQ之初识kafka-CSDN博客我们介绍组件的时候就提到过,kafka为了提升高吞吐,查询效率快,消息并不是堆积在一起的,而是一批一批去放的,因此经过一个累加器。

可以看到 按批次添加到累加器中,那么添加到累加器之后,是怎么触发流程的呢?
f . 顺着源码再往下看,可以看到一个判断,当累加器的批次满了的话或者是刚创建的批次,就会去唤醒sender线程,向Broker中发送消息。

生产者发送消息的整个流程图如下所示:
2. ACK应答机制与ISR机制
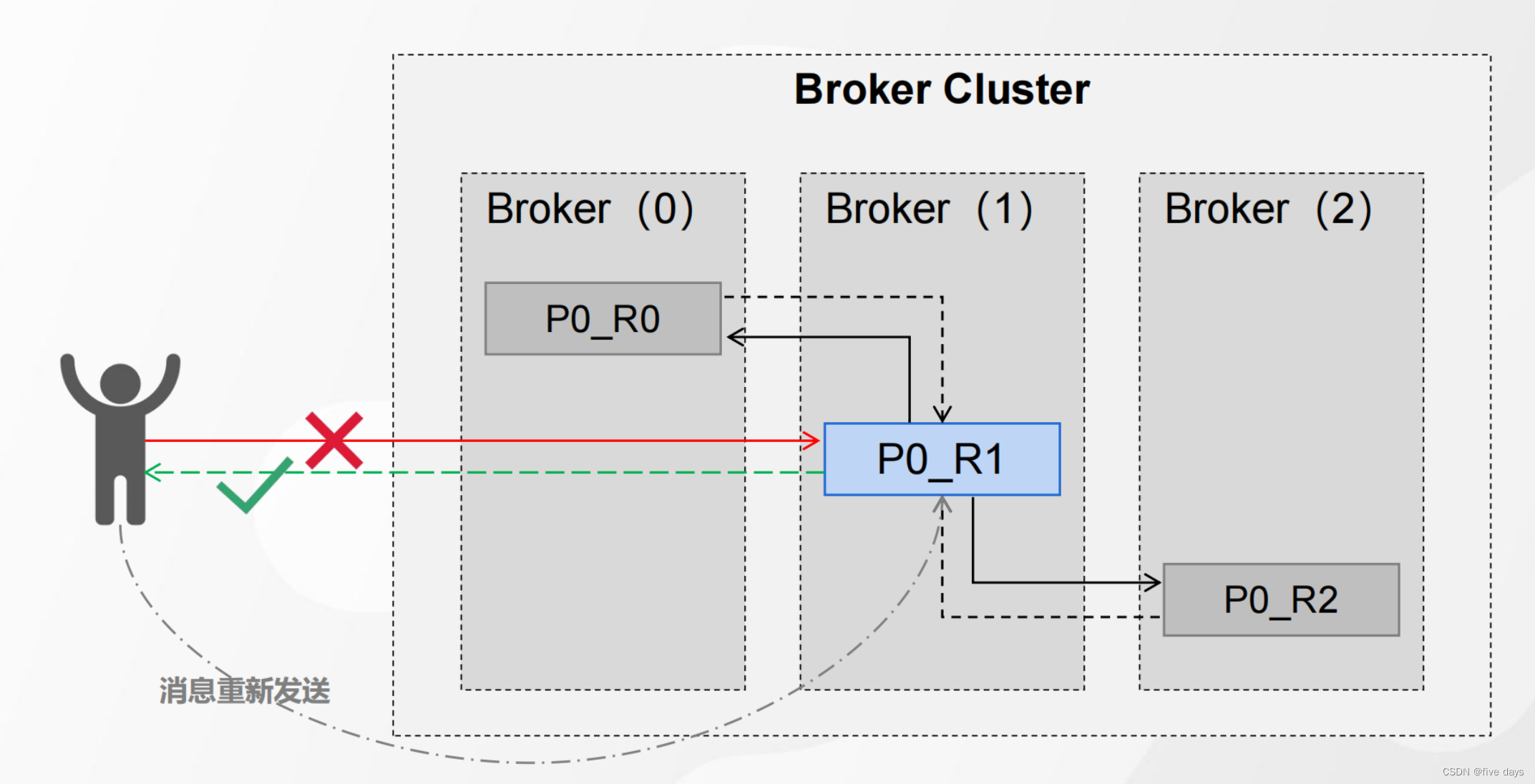
2.1 服务器端响应策略的必要性
如图所示,我们正常的执行流程是生产者producer向leader中发送消息,然后leader同步到两个follower副本中,那么当发送消息的过程中服务异常的话,我们的leader就接收不到消息了,因此需要一个应答机制来保证我们能够接收到消息,如果leader没有接收到消息,就触发重发机制,让producer重新发送消息给leader
2.2 ACK应答机制
kafka中提供了三种可靠性级别,可以根据对可靠性和延迟性的要求进行选择
1.acks = 0 producer 不等待 broker动作、直接返回ack
2.acks = 1(默认) producer等待broker 动作、 leader 落盘成功、返回 ack
3.acks=-1(all) producer 等待 broker 动作、 leader&follower 全部落盘成功、返回 ack
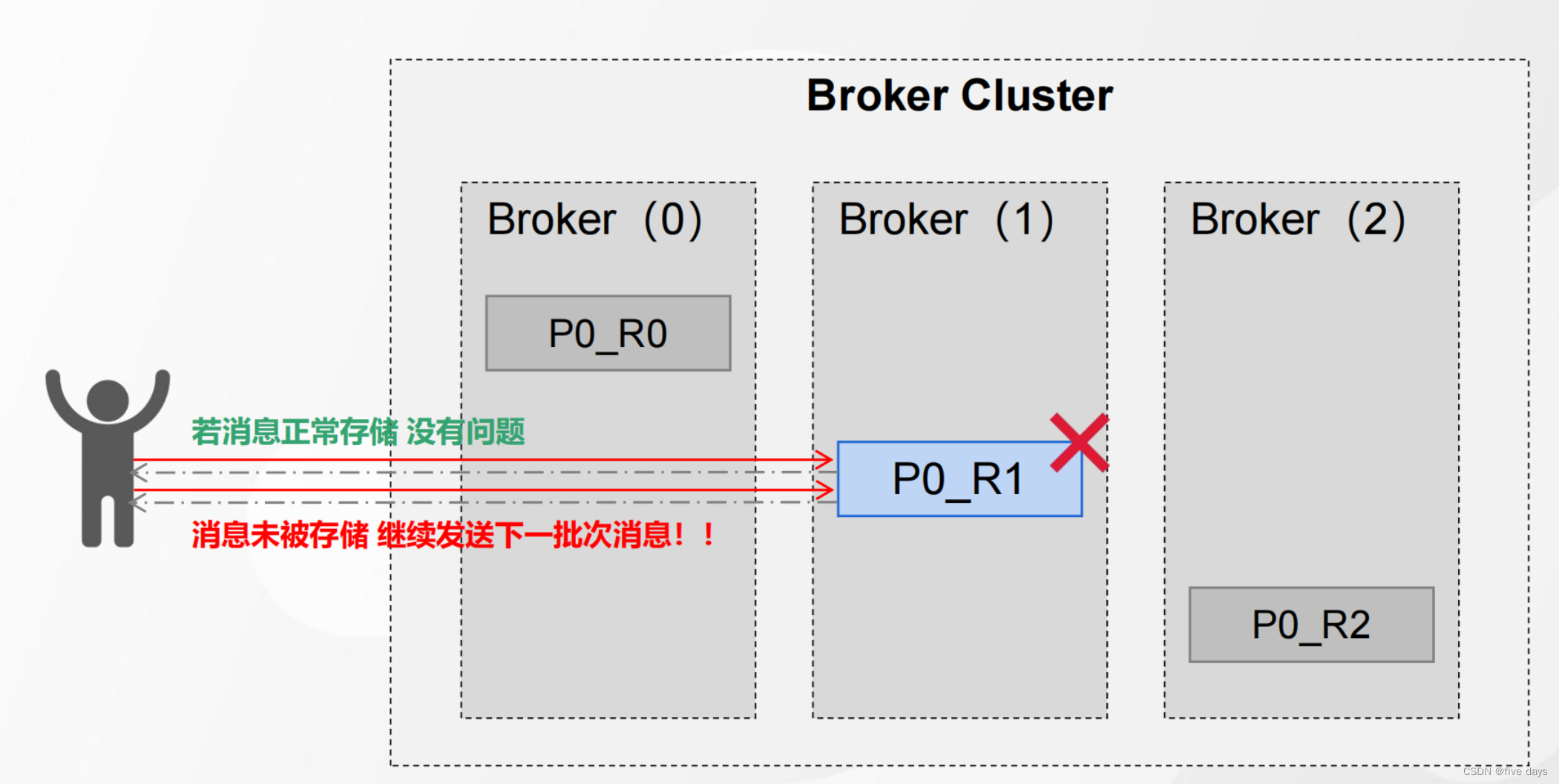
props.put("ack","0"); 不等待ACK
这种情况是说我们的producer发送消息给leader,leader异步返回ack给peoducer告诉消息已经发送成功了,这种正常存储的情况下肯定是没有问题的。但是如果还没有同步副本的情况下,我们的leader此时挂掉了,而producer已经收到了应答,因此不会再重发消息。当再次重启leader所在的服务器时,数据就丢失了
props.put("ack","1"); Leader落盘、返回ACK(默认)
这种下,我们peoducer确定了leader已经落盘了,但是如果极端情况下,leader还没有同步副本给follower,那么此时leader服务器挂了,数据是不是也就丢失了,因为也还没有进行备份
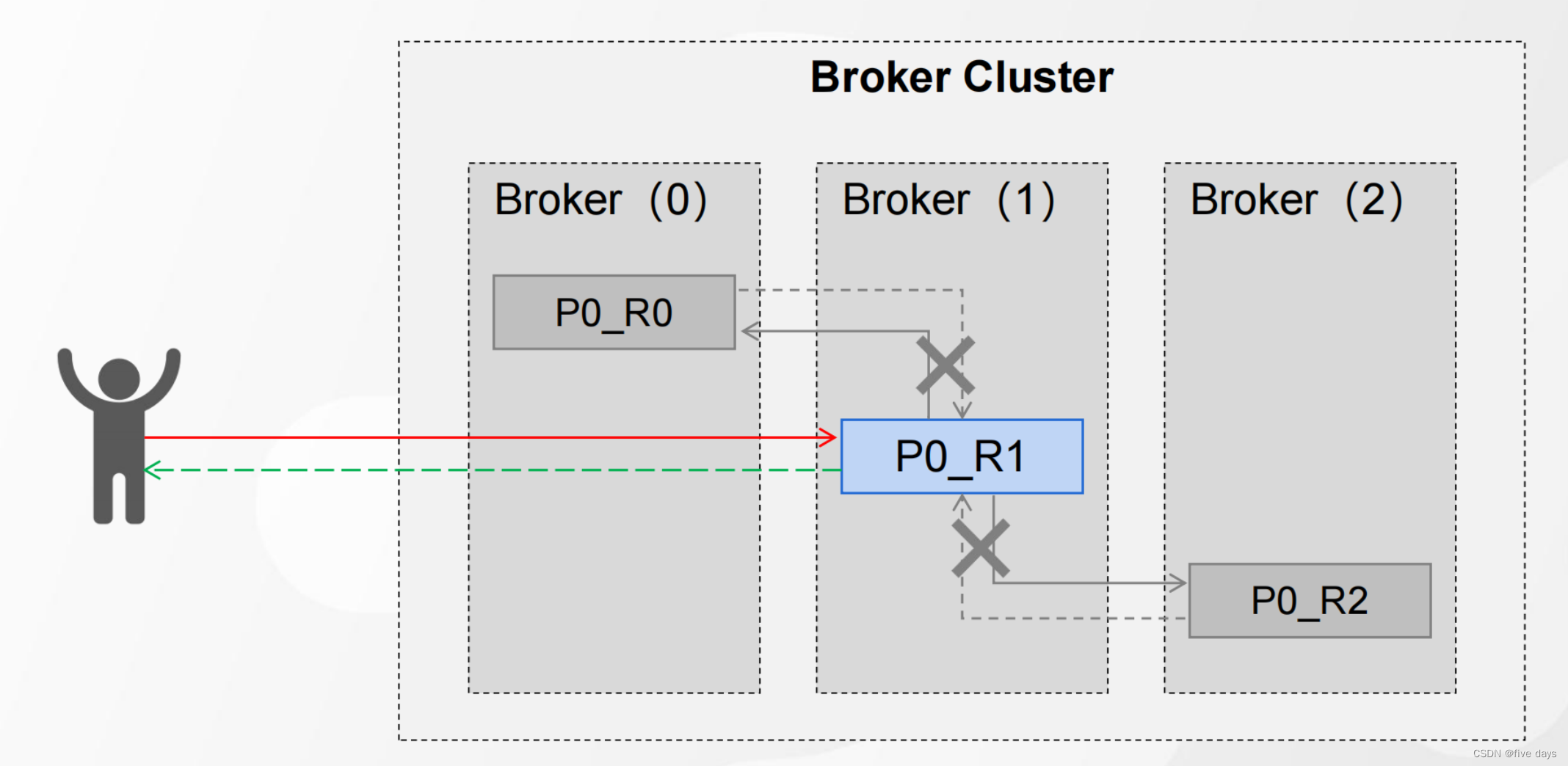
props.put("ack","-1"); Leader和全部Follower落盘、返回ACK
这种情况是我们的producer等待leader和follower全部落盘成功后,进行ack响应,这种策略的可靠性最高,但是吞吐量是最低的,因此要根据具体业务具体配置。那么这种策略是不是就没有什么问题了呢?当然也有,比如当leader和follower都落盘后,再返回应答信号时,leader挂了,那么peoducer没有收到消息,就会任务leader没有接收到消息,还是会对消息进行重发,那这个问题怎么解决呢? 可以用消息幂等性(在第三章进行赘述说明)
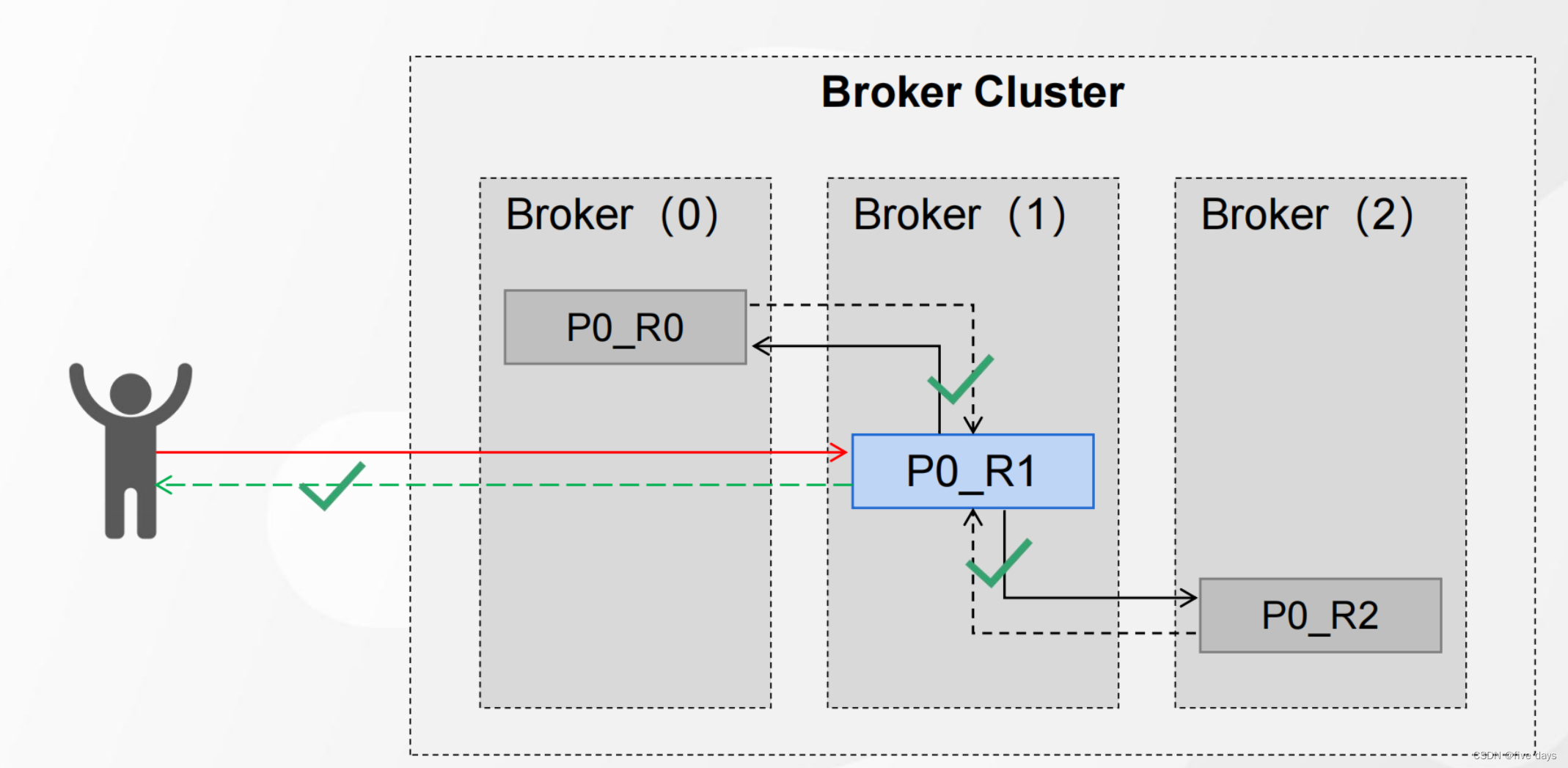
应答异常
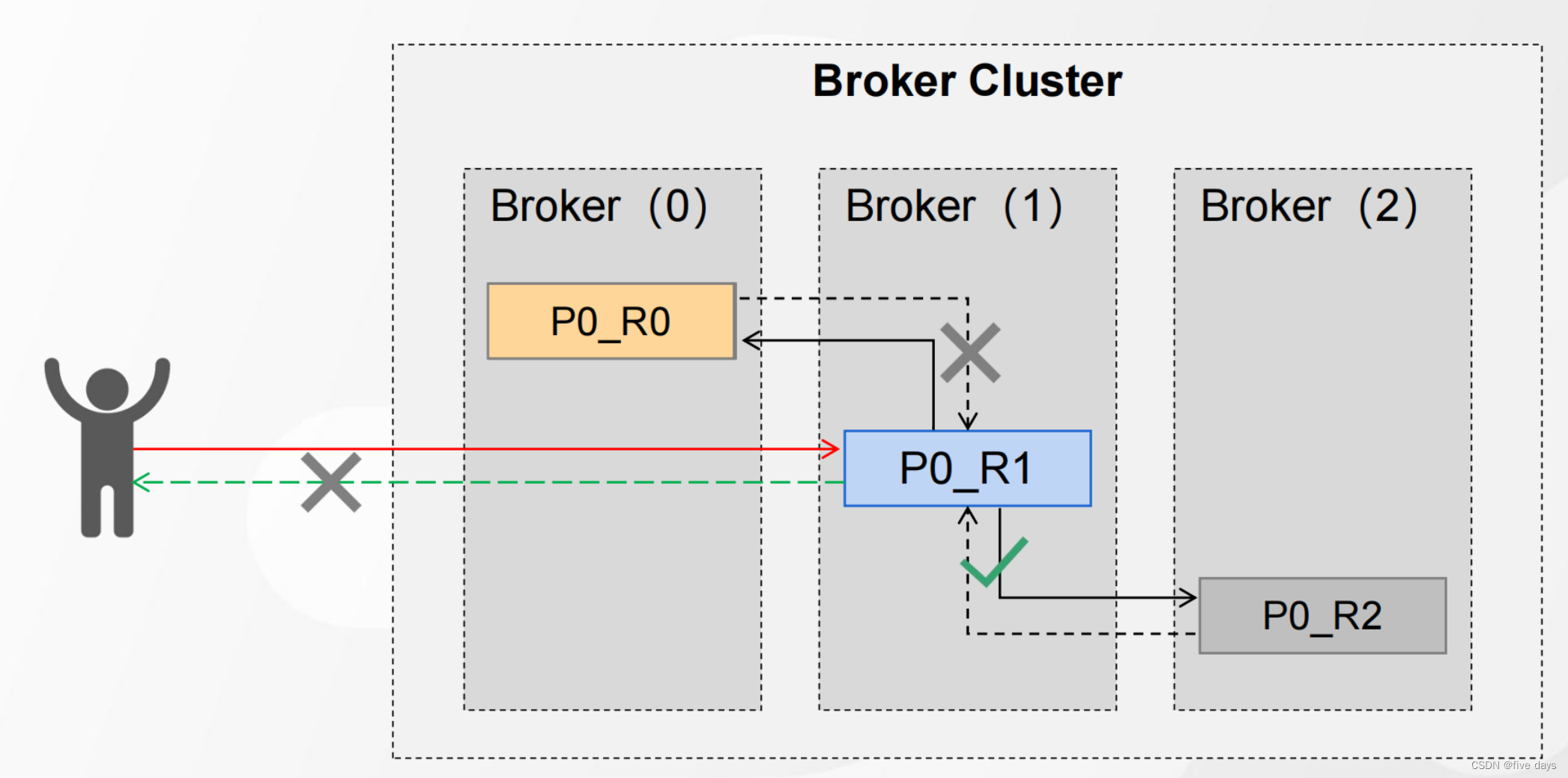
如上图,当一个flower挂了的情况下,是不是我们的leader就没法同步了,没法同步,就会造成整个链路的阻塞,peoducer没收到应答信息还啥也不知道,又往leader发消息,如果这样持续下去,服务是不是就该崩了,因此引入了一个ISR机制。
2.3 ISR机制
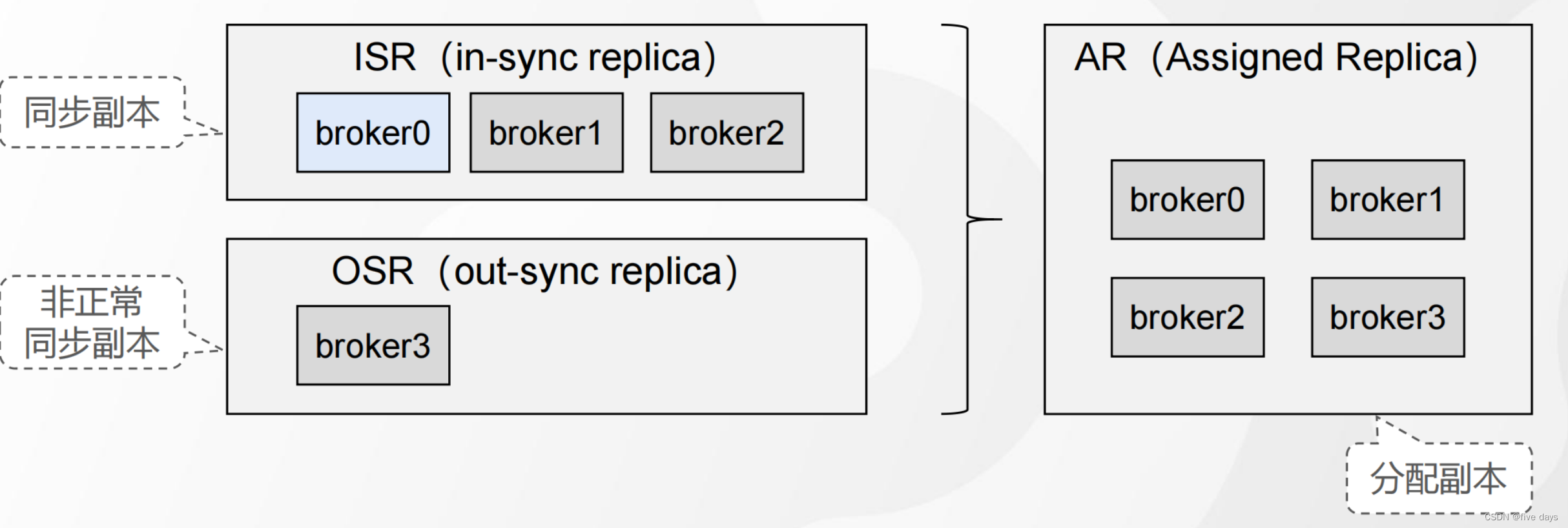
ISR是一组动态维护的同步副本集合,它的作用就是把leader和follower同时放到一个ISR队列中,比如上面的P0_R0挂掉了,同步不积极,那么就把它移除ISR队列,默认为30s,可以经过replica.lag.time.max.ms进行配置,当ISR中的队列都同步完了的话,就返回ACK应答信号
AR = ISR+OSR
3. 消息幂等性
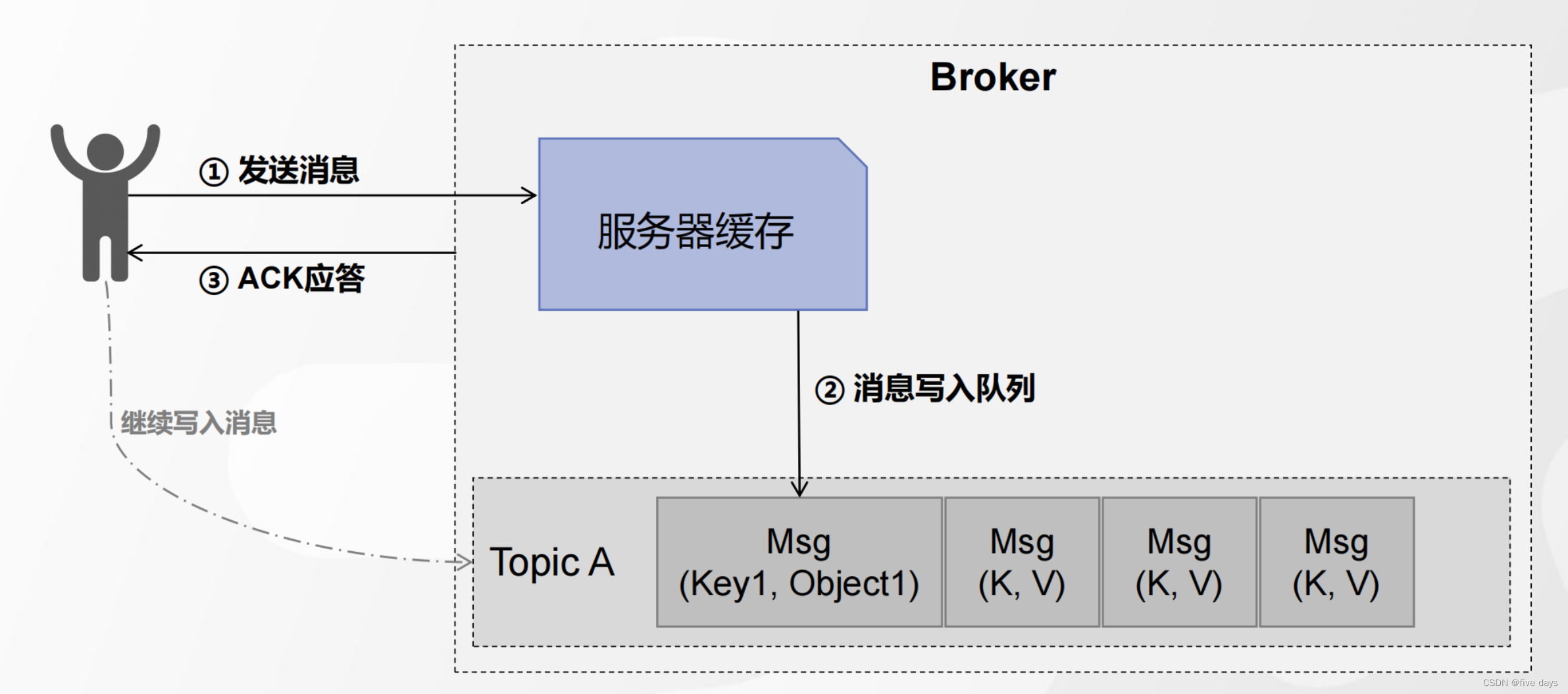
发送消息情形-1: 正常发送
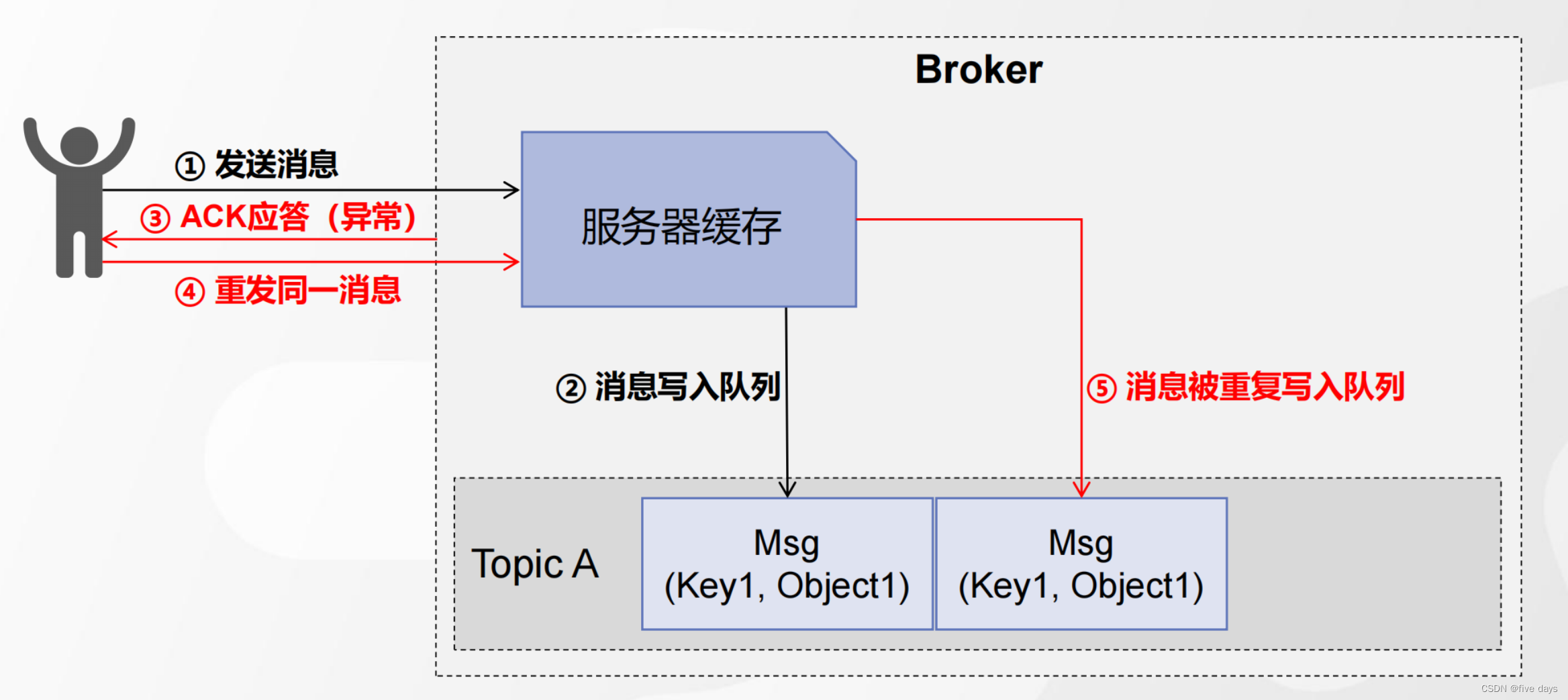
发送消息情形-2:消息发送失败,触发消息重发,造成消息重发写入
发送消息情形-3:消息发送失败,触发消息重发,消息不重复写入
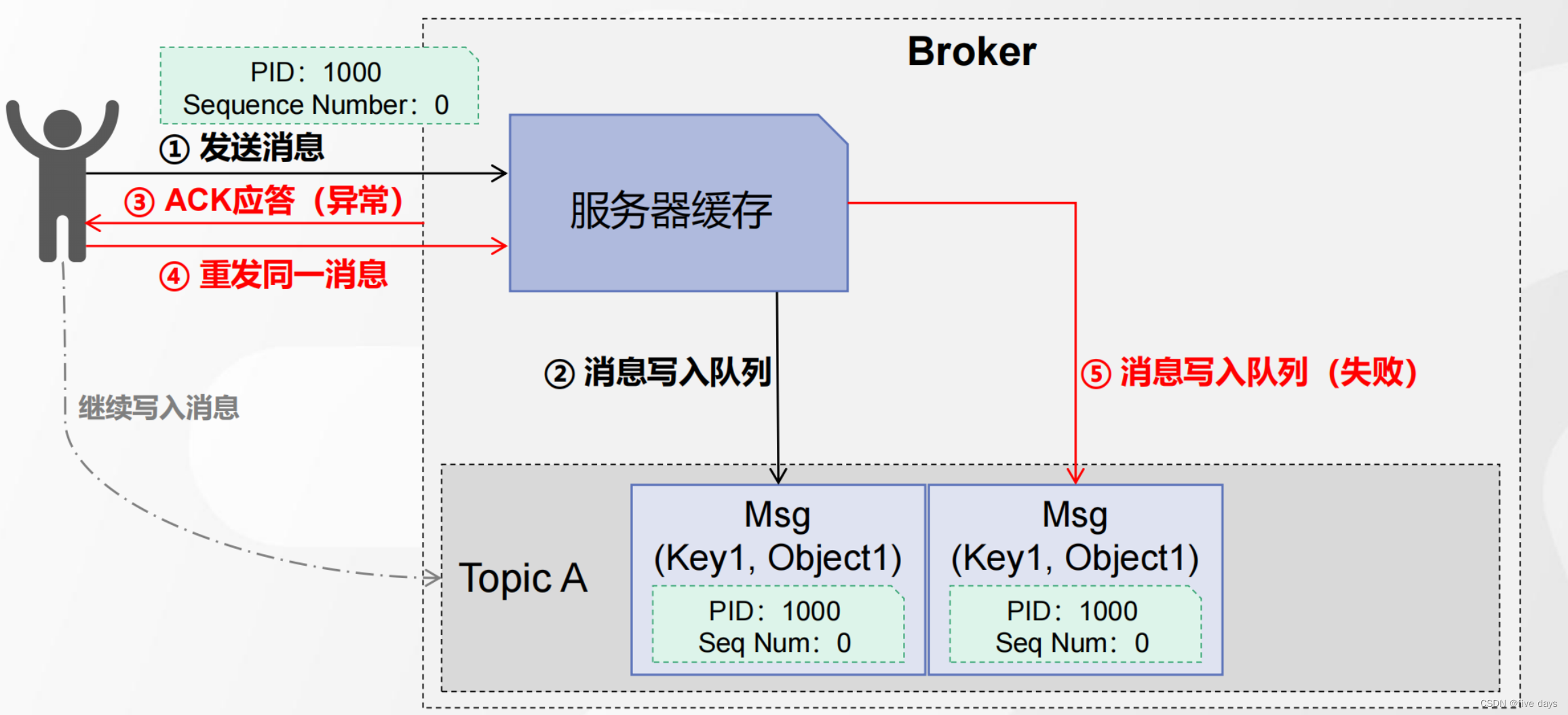
如上图所示,是怎么保证消息不被重复写入的呢?利用幂等性,在发送消息的时候新增两个参数PID与Sequence Number分别代表生产者ID和消息的编码,那么Broker存储的时候也会多加一点空间存储这两个值,当ack应答异常时,再次重发消息到队列中时,就会进行一次判断a.如果PID和sequence Number都相等,则消息写入队列失败,b.如果Sequence Number为1 则顺序写入 c.如果Sequence Number为2,则抛出异常,表示数据有丢失
幂等性生产者发送消息流程总结:
1 、 Producer 端发送消息(消息本身、 PID 、 Sequence Number )
2 、 Broker 端接收到消息(将消息和 PID 、 Sequence Number 一起保存)
3 、若 ACK 响应失败,生产者重试,再次发送消息
kafka是在Broker端完成的去重处理
4. Kafka生产者事务
生产者的幂等性只能保证在单分区单会话的场景下有效,因此对于多分区来说,kafka事务就提供了对多个分区写入操作的原子性。但是kafka事务的前提是开启幂等性。
kafka事务API的相关方法
initTransactions() 初始化事务
beginTransaction() 开启事务
commitTransaction() 提交事务
abortTransaction() 中止事务
sendOffsetsToTransaction()
事务的一个demo
java
public static void main(String[] args) {
Properties props=new Properties();
//props.put("bootstrap.servers","192.168.8.144:9092,192.168.8.145:9092,192.168.8.146:9092");
props.put("bootstrap.servers","192.168.8.147:9092");
props.put("key.serializer","org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer","org.apache.kafka.common.serialization.StringSerializer");
// 0 发出去就确认 | 1 leader 落盘就确认| all或-1 所有Follower同步完才确认
props.put("acks","all");
// 异常自动重试次数
props.put("retries",3);
// 多少条数据发送一次,默认16K
props.put("batch.size",16384);
// 批量发送的等待时间
props.put("linger.ms",5);
// 客户端缓冲区大小,默认32M,满了也会触发消息发送
props.put("buffer.memory",33554432);
// 获取元数据时生产者的阻塞时间,超时后抛出异常
props.put("max.block.ms",3000);
props.put("enable.idempotence",true);
// 事务ID,唯一
props.put("transactional.id", UUID.randomUUID().toString());
Producer<String,String> producer = new KafkaProducer<String,String>(props);
// 初始化事务
producer.initTransactions();
try {
producer.beginTransaction();
producer.send(new ProducerRecord<String,String>("transaction-test","1","1"));
producer.send(new ProducerRecord<String,String>("transaction-test","2","2"));
// Integer i = 1/0;
producer.send(new ProducerRecord<String,String>("transaction-test","3","3"));
// 提交事务
producer.commitTransaction();
} catch (KafkaException e) {
// 中止事务
producer.abortTransaction();
}
producer.close();
}
}kafka事务操作的基本流程
最后标记消费状态后,就可以进行消费了
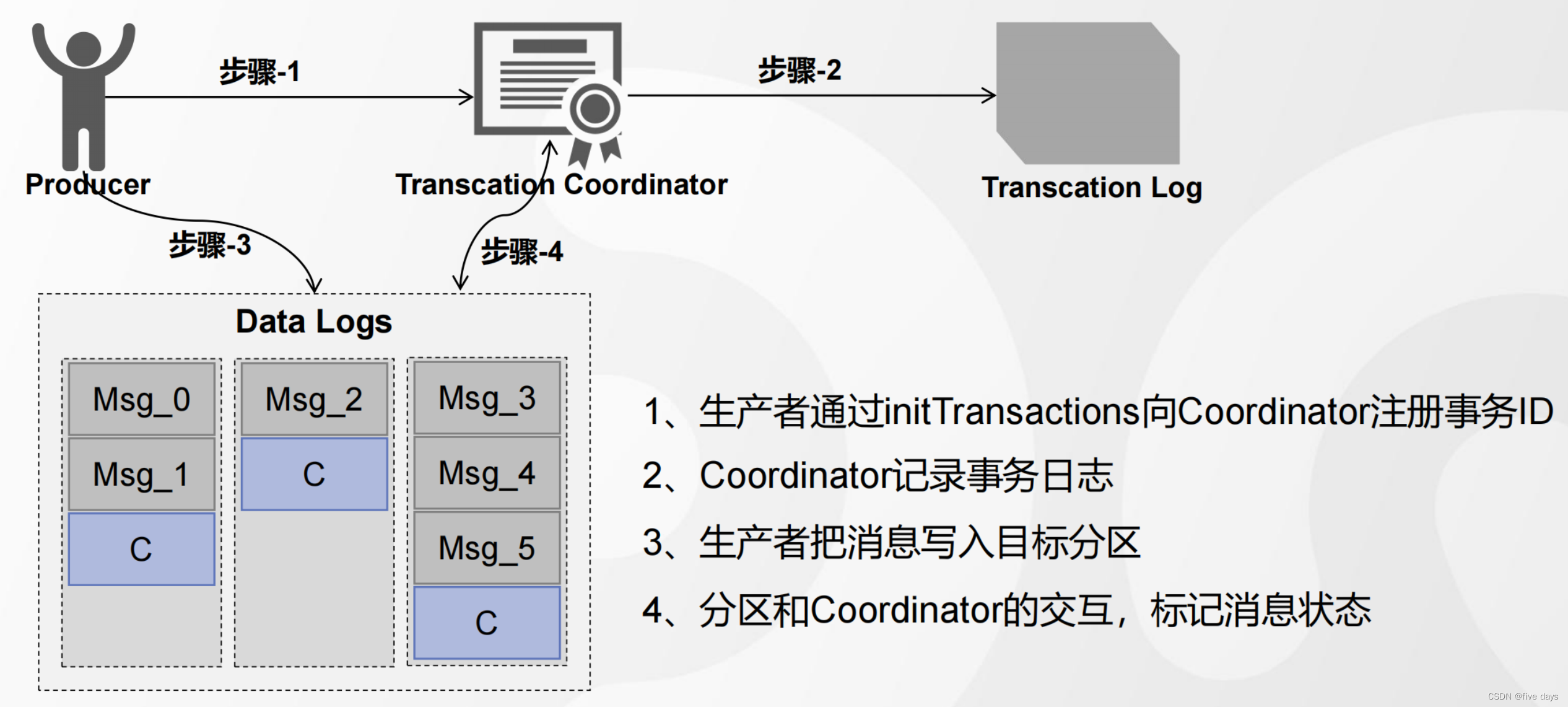
kafka的事务细节流程:
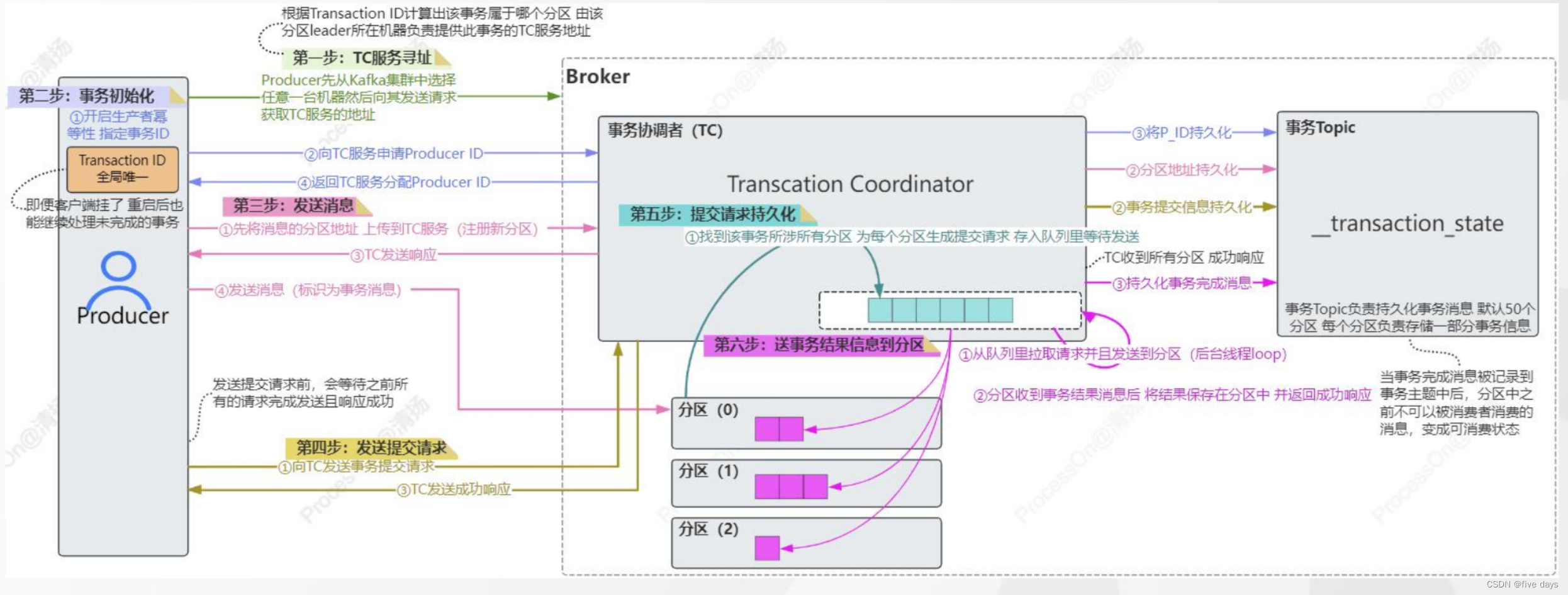
5. 总结
本文主要是介绍了kafka生产者端的一些原理,先是从源码出发,介绍了生产者发送消息到Broker经历的一系列过程:先是创建了一个sender线程,然后在发送消息的过程中一次经过拦截器、累加器、分区器最后根据分区的批量消息是否新建或者满了来触发sender线程发送到Broker服务器中。随后我们介绍了,peoducer跟broker服务器之间的交互采用的是应答机制,在这里有3种配置,可根据业务需要来具体配置,当配置-1的时候,我们分析了为什么会出现重发消息的问题,通过幂等性来保证,follower从节点挂了的情况下,应答异常,采用ISR队列机制进行避免。但是幂等性只能保证单分区单会话的场景,而针对多分区的情况下,kafka主要是采用分布式事务来解决,利用分布式ID,事务coordinattor和事务日志分二PC提交,并且对事务的状态进行存储标记,当事务的状态更改为可消费的时候,才会进行消费。