一、超文本传输
-
文本传输 => 字符串(能在utf8/gbk等码表上找到合法字符)
-
超文本传输 => 不仅仅是字符串,还可以携带一些图片,特殊得格式 HTML
-
富文本 word
http0.9 -> http1.0 -> http1.1 -> http2.0 -> http3.0
http1.0是主流版本
2.0 和 3.0 引入和很多新的特性
1.提高传输效率
2.提高传输得安全性
http3.0之前 在传输层是基于TCP,到了3.0这个版本,传输层是基于UDP的.
http3.0基于UDP实现了一系列的更复杂的机制,可以确保可靠性,也不怕大数据包.
http协议最主要的应用场景,就是网站.浏览器和服务器之间,传输数据.
客户端(手机,PC),和服务器之间的数据传输,也可能是HTTP.
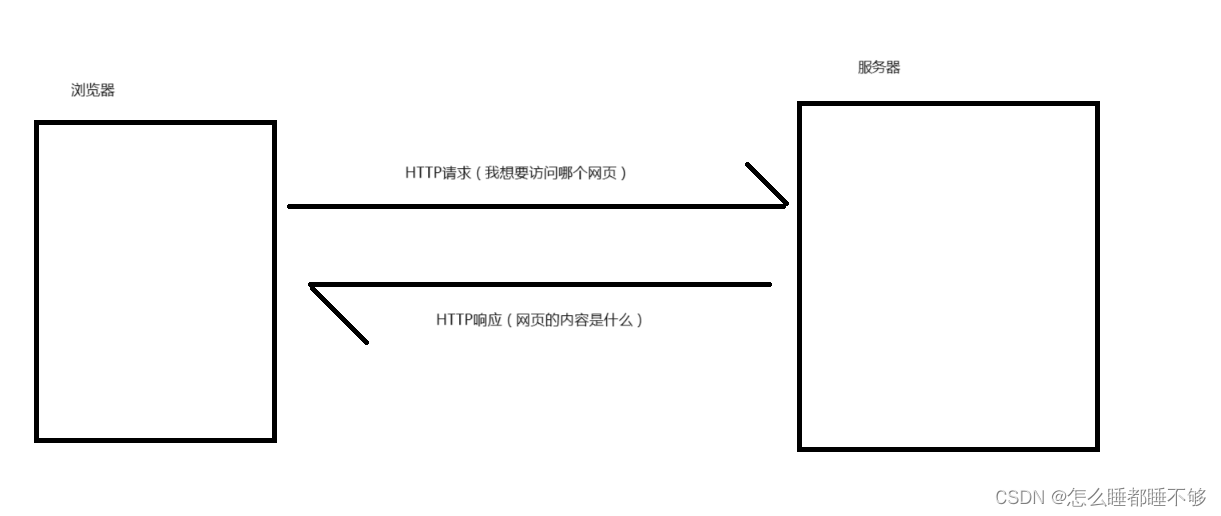
HTTP协议的交互过程,是非常典型的 " 一问一答 "
HTTP报文格式
抓包工具:抓包工具本质上是一个 " 代理程序 ",能够获取到网络上的传输的数据,并显示出来,从而给程序员提供一些参考.
fiddler就是一个抓包工具.
fiddler也是一个代理,代理之间可能会冲突.
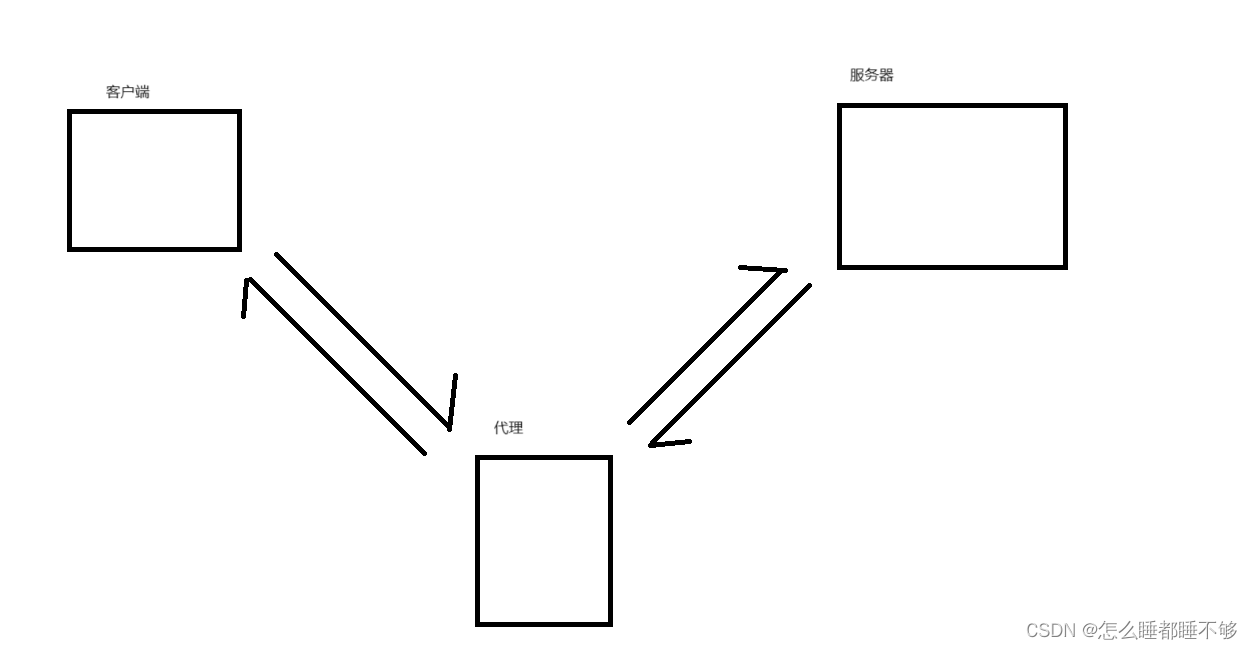
代理还分为两种,
正向代理(是客户端的代言人)
反向代理(是服务器的代言人)
代理,是程序,而不是设备,是工作在应用层的,上述的转发都是站在应用层的角度.
打开一个网站,浏览器和服务器之间进行的HTTP交互不是只有一次的,而是通常有很多次的.
第一次交互是拿到这个页面的HEML.
HTML还会依赖其他的CSS和JS,图片等,HTML被浏览器加载之后,又会触发一些其他的HTTP请求,获取到CSS,JS等等.
当执行JS的时候,JS代码里可能又要触发很多的HTTP请求,获取到一些数据.
HTTP请求
HTTP请求,包含4部分:
- 首行
首行又包含了三个内容:
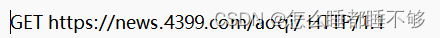
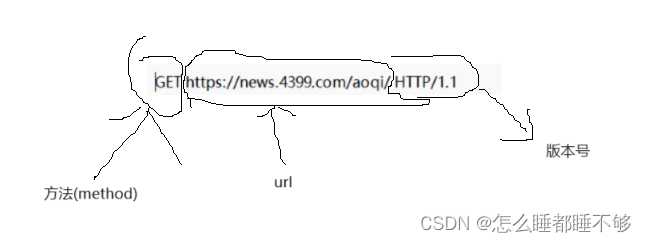
三个部分之间用 空格 来分割
- 请求头
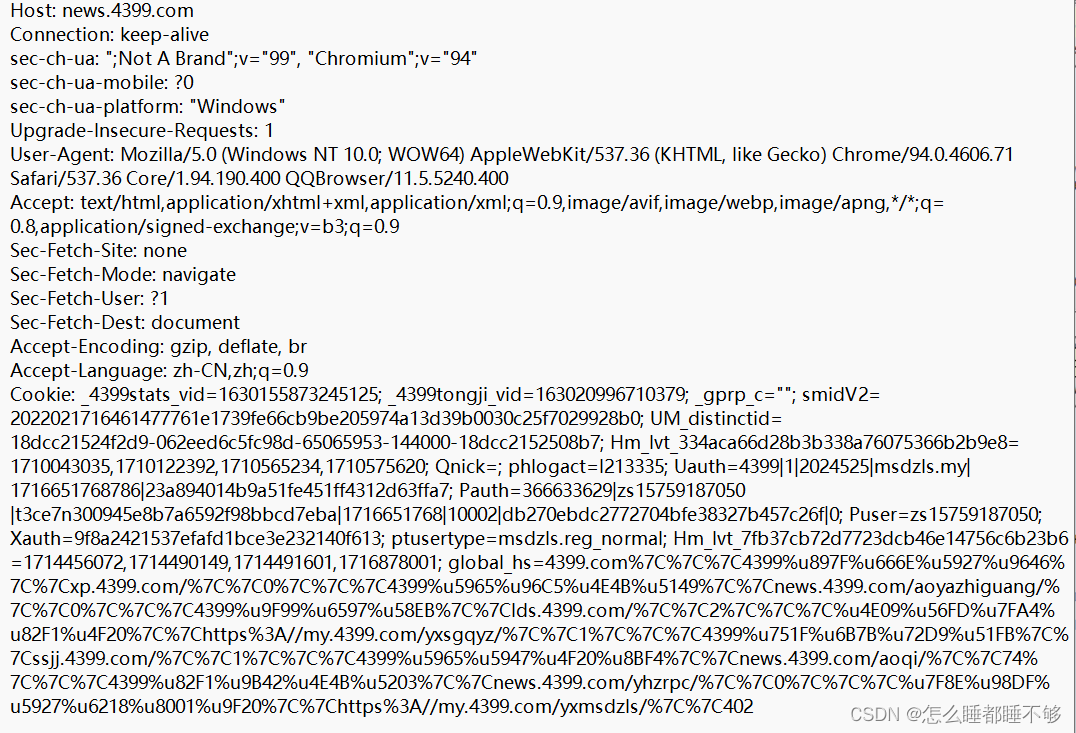
从第二行一直到后面都是请求头.类似于TCP报头/IP协议报头.重要的属性信息.
报头中包含了很多键值对,每个键值对占一行.键和值之间使用:空格来分割.
3.空行
请求头最下面会有一个空行,这个空行可以表示结束标记.
- 正文(body)
http载荷部分,有的http请求有body,有的就没有.
HTTP响应
HTTP响应的格式
1.首行
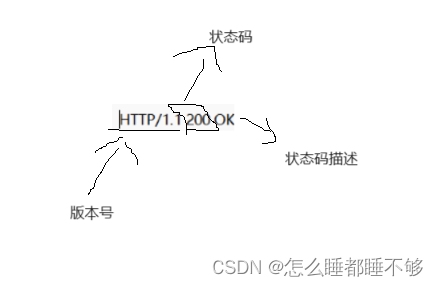
这里也是包含三个部分,三个部分之间用空格来分割.
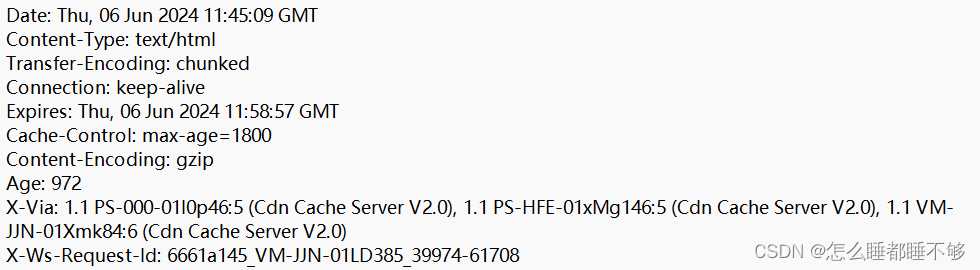
- 响应头 键值对
-
空行
-
响应正文(body) 载荷
响应的载荷是HTML
URL
描述一个网络上的资源位置.唯一资源定位符
uri:唯一资源标识符
uri的范围不url更广一些
标识一个变量的身份,可以使用变量的地址,也可以使用变量的hashCode


一个URL完整的结构

这里的域名,也可以是IP地址,后面带有端口号,表示你要访问服务器的哪个端口.
如果URL中不带端口号,浏览器就会自动给一个默认的端口号.此处用什么端口取决于默认值(http:80 https:433)
带层次的文件路径:
可能会对应一个真实的硬盘文件,也可能会对应一个虚拟的文件.
查询字符串:
针对请求的内容做的补充说明.
网络上资源的位置:
-
通过IP地址知道服务器在哪
-
通过端口号 知道程序是哪个
-
通过路径知道是访问哪个资源.
查询字符串,是客户端给服务器传递信息的重要途经.
这里的组织方式是按照键值对的方式来组织的
综上所述的IP地址,端口号,路径,查询字符串,就可以描述出一个网络资源了.
关于URL encode
query string 里是自定义的键值对.
在URL中,本身有些特殊符号具有特定的意义.如果URL的query string中也包含同样的符号,如果直接写进去,可能就会使服务器/浏览器解析失败,靠谱的方法就是对上述符号进行 " 转译 "
对于汉字,也是要进行转译的.