**"百度AI大底座"**是源自百度多年产业深度实践积累、结合AI全栈技术科研成果打造的国内首个全栈自研的AI基础设施, 面向企业和产业AI开发与应用提供端到端自主可控、自我进化的解决方案,能够快捷、低成本地实现"AI能力的随用随 取"。AI大底座可助力企业和产业快速高效地建立AI生产力。
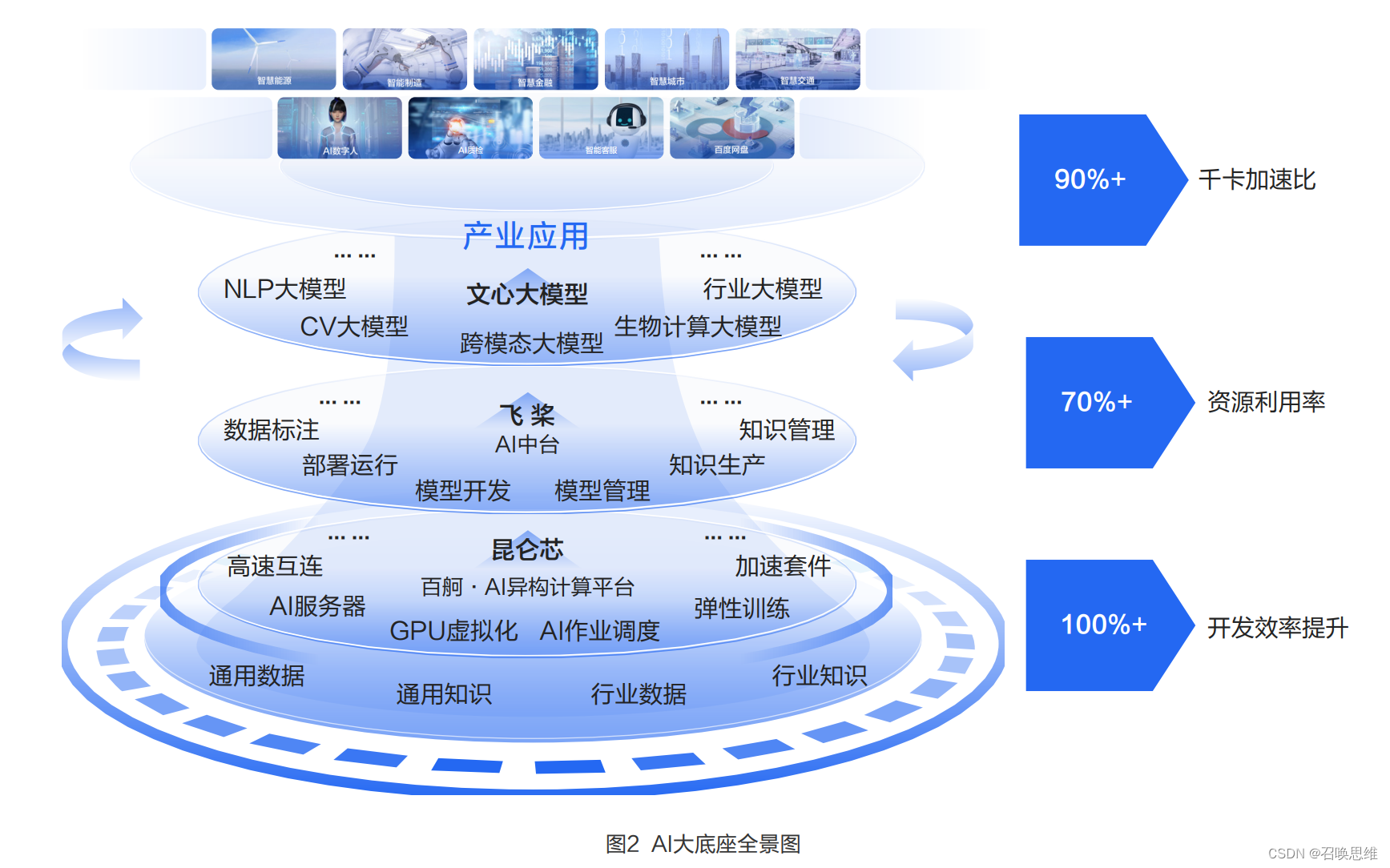
AI大底座涵盖了百度昆仑芯、飞桨深度学习框架以及文心大模型等核心能力以及百度百舸平台、AI中台等平台方案,可以 为客户提供高性价比的智能算力、自主研发的开发框架以及完善丰富的大模型体系,为企业部署和开发各类AI应用、服务 以及大模型提供一站式端到端支持,满足产业级低门槛、快速部署等AI落地需求。
AI大底座具备四大优势
AI大底座以其全栈技术能力,帮助用户从上云,进入到用数、赋智的快车道,极大降低AI产业应用的门槛,从而释放用户 侧的精力与资源,着力聚焦于业务融合创新。从落地实践看,AI大底座具备高效能算力、高效率研发、端到端优化、持续 性运营这四大优势。
2.3.1 高效能算力
以集约化、高性能、多样化的智能算力,为模型训练和推理提供绝佳负载。随着AI应用场景更加丰富、超大模型不断出 现,云上AI任务的管理复杂性越来越高,芯片多元化、算力规模化、云原生化成为未来智能算力发展的重点方向。百度百 舸支持各类异构计算芯片,单卡资源利用率达到 70% 以上,千卡并行加速比至90%以上,使得单卡和集群的算力能够被 充分发挥出来。云原生AI平台为百度百舸提供了各类高性能云资源的管理和任务调度,确保了大规模AI任务的高效运行。 在行业智能化升级的深化过程,百度百舸不仅支持了文心大模型的落地,更在生科医疗、自动驾驶以及智算中心等领域作 为AI基础设施提供普惠多元的AI算力,实现助力药物蛋白质结构预测模型的训练效率提升2倍、量产车自动驾驶迭代周期 从月级别缩短为周级别等,更加极致地满足了产业智能化的AI算力需求。
2.3.2 高效率研发
通过MLOps等一系列AI研发运维工具,以AI工程化能力突破AI落地的"最后一公里"。AI模型开发运营全流程是多环 节、复杂程度高的工作,从数据采集、数据标注、模型训练再到数据回流和模型观察,任何一个环节未能规范都将影响AI 模型的应用效果。2023年初中国信通院首次公布了MLOps服务能力旗舰级评测结果,百度智能云企业AI开发平台成为全 国首批在AI开发管理能力上达到旗舰级的MLOps平台。百度零门槛AI开发平台EasyDL与全功能AI开发平台BML提供高 自动化水平的模型开发工具和标准化的流程规范指导,能大幅降低企业AI开发门槛,并让模型开发有规范和标准可参照,保障开发质量。例如,通过丰富的AutoML/AutoDL能力,企业可以根据数据集及任务来自动选择网络和参数,从而节省 90%的参数调优人力投入。
2.3.3 端到端优化
AI大底座构建平台化的反馈闭环机制,通过持续迭代、循环增强提升AI应用的整体效果。在面向实际业务场景时,AI生产 全要素中的每一层能力都会得到很多真实业务的反馈,并通过不断调优,实现端到端优化,从而带来应用效能的大幅提 升。例如,应用落地过程中的模型效果问题,将驱动迭代新的模型结构,新的模型结构又需要新的框架能力支撑,而新的 框架能力对于底层芯片算力又会提出新的要求。百度在端到端各层都具有自主可控的核心产品技术,能够深入底层,进行 纵向的深度整合优化,以提供极致的资源效能和模型效能。比如,在大模型的端到端自适应分布式训练过程中,飞桨统一 的资源和计算视图以及自动并行能力可与百度百舸的弹性调度能力相结合,通过AI 框架和AI 异构算力平台的深入交互,实 现算力、框架、算法三位一体的系统优化,支持大模型自动弹性地进行训练,端到端实测有2.1倍的性能提升,保证了大规 模训练的高效性,训练场景资源利用率可达70%以上。在2022年11月发布的MLPerf Trainning v2.1测试结果中,百度使 用飞桨加百度百舸提交的模型训练性能结果,位列同等GPU配置下世界第一,端到端训练时间和训练吞吐均超越NGC PyTorch框架。
2.3.4 持续性运营
AI大底座构建长效运营的平台,通过持续运营充分释放AI业务价值,实现全面升级和持续创新。AI大底座整合以上技术优 势,并作为一个可持续运营的平台,从技术设施向企业发展全面赋能,提供人才培养赋能、业务场景共创、优秀案例推广 等系列运营服务,将逐步提升面向企业各业务与管理等领域场景智能化需求的支撑能力,促进AI资产沉淀复用,保障资源 高效使用。AI大底座成为企业的AI生产力中心,让AI渗透到企业的毛细血管之中,构筑起企业的智能化核心竞争力。