本文主要记录自己在用 Tensorflow 1.x 复现经典模型过程中遇到的一些函数及用法,方便查阅
guide:https://www.tensorflow.org/guide?hl=zh-cn
注:本文只记录在 Tensorflow 2.x 中已经被移除的函数。1.x 和 2.x 通用的函数这里不做记录,详见 TensorFlow 2.x常用函数总结(持续更新)
python
# 查看自己 TensorFlow 的版本
import tensorflow as tf
print(tf.__version__)tf 1.x 特性
执行模式 Graph/Eager Execution
Graph Execution 为静态图模式,需要预先定义计算图,运行时反复使用,不能改变。简而言之,进行一系列计算时,需要依次进行如下两步:
- 建立一个计算图 Graph,这个图描述了如何将输入数据通过一系列计算得到输出
- 建立一个会话 Session,并在会话中与计算图进行交互,即向计算图传入计算所需的数据,并从计算图中获取结果
Eager Execution 是在 TensorFlow 1.7 版本中首次引入的 ,但被作为主要的特性并默认启用是从 TensorFlow 2.0 开始的。在 TensorFlow 2.0 及以后的版本中,无需手动启用 Eager Execution,它会默认为开启状态,可以立即开始执行 Tensors,无需事先构建一个静态的计算图。这种方式使得 TensorFlow 更加友好和易于调试
- 在 Eager Execution 模式下,每一个操作在代码中的位置,就是 TensorFlow 运行此操作的时间点。这种特性带来了像 Python 一样的直观编程体验,同时不失去 TensorFlow 的性能和可扩展性
- 当在 TensorFlow 中运行任意的操作,该操作的结果会立即返回,而不是创建一个计算图以供以后执行,这样可以很容易地用 print 语句或者调试器来检查结果
- Eager Execution 模式一旦启用,就无法在同一程序中关闭,无论该程序的后续操作是什么
python
import tensorflow as tf
# 启动 eager execution
tf.enable_eager_execution() # 注意,TensorFlow 2.x默认开启,因此没有这个函数
x = [[2.]]
m = tf.matmul(x, x)
print("hello, {}".format(m)) # 输出 'hello, [[4.]]'
# Eager Execution 自动识别 Python原生类型
if tf.executing_eagerly():
print('Eager execution is enabled (running operations immediately)\n')
print('4. * 2. = ', 4. * 2.)两种执行模式的区别可参考 tensorflow图模式和eager模式小结
session.run()
在 TensorFlow 1.x 中,session.run() 是一个关键操作,作用是执行计算图中的节点操作
- 在 TensorFlow 1.x 中定义模型时,实际上只是构建了一个计算图(Computation Graph)。这个图包含了所有的运算,但是没有真正进行任何计算
- 实际的计算在开启一个会话(session),并运行特定的操作时开始
python
import tensorflow as tf
# 创建常量
a = tf.constant(1)
b = tf.constant(2)
# 创建操作
c = tf.add(a, b)
# 打开会话执行计算
with tf.Session() as sess:
result = sess.run(c)
print(result) # 输出结果 3在这个例子中,sess.run(c) 将在 c 节点(及其所有依赖项)上调用计算操作。完成计算后,run() 方法返回结果,即节点 c 的输出
在 TensorFlow 2.0 及以上版本中,默认的执行模式变为了即刻执行模式(Eager Execution) ,这意味着计算可以立即进行,因此不需要显式地创建和使用
tf.Session
placeholder
placeholder 在编程语言中常用于代表一个尚未赋值的变量或者一个待补充的位置
在一些编程语法中,例如 Python 的字符串格式化,常使用 {} 作为 placeholder,后续可以通过 format 函数填充进去具体的值。例如:
python
placeholder_str = "Hello, my name is {}."
print(placeholder_str.format("John")) # 输出:Hello, my name is John.而在 TensorFlow 1.x 中,placeholder 代表一个尚未赋值的变量。可以在定义了计算图之后,通过feed_dict 的方式在需要的时候把值传递进去,这在机器学习和深度学习的训练中很有用。例如:
python
import tensorflow as tf
x = tf.placeholder(tf.float32, shape=(1024, 1024))
y = tf.matmul(x, x)
with tf.Session() as sess:
rand_array = np.random.rand(1024, 1024)
print(sess.run(y, feed_dict={x: rand_array}))TensorFlow 2.x 不再使用
placeholder的方式创建变量,而是通过 Eager Execution 的模式直接进行运算
tf 1.x 常用函数
tf.is_nan()
tf.is_nan() 用于检测张量中 NaN(Not a Number) 值。它返回一个与输入张量形状相同 的布尔张量,指示每个元素是否为 NaN
- NaN 只存在于浮点数类型中,整数、字符串、布尔类型不会产生 NaN
python
import tensorflow as tf
import numpy as np
tensor = tf.constant([1.0, 2.0, np.nan, 4.0, float('nan')])
result = tf.is_nan(tensor)
# 创建session并运行计算
with tf.Session() as sess:
print(sess.run(tensor)) # [ 1. 2. nan 4. nan]
print(sess.run(result)) # [False False True False True]这个函数常常用于数据清洗和预处理阶段,找出数据中的缺失值或异常值(如 NaN),以便进一步处理
python
# 用指定值如 0.0 替换 NaN
cleaned_data = tf.where(tf.is_nan(data), 0.0, data)
tf.is_nan()在 TensorFlow 2.x 中为tf.math.is_nan()
tf.diag_part()
tf.diag_part() 用于从输入的张量中提取对角线元素并返回一个张量
python
import tensorflow as tf
x = tf.constant([[1, 0], [0, 1]])
# 创建session并运行计算
with tf.Session() as sess:
print(sess.run(tf.diag_part(x))) # [1 1]
tf.diag_part()在 TensorFlow 2.x 中为tf.linalg.diag_part()
tf.random_uniform()
tf.random_uniform() 用于生成一个指定形状的张量 ,其元素都是从一个均匀分布中随机采样得到的。默认情况下这个均匀分布的范围是 [0, 1),但可以通过 minval 和 maxval 参数来调整这个范围
python
import tensorflow as tf
# 生成一个形状为 [2, 3] 的张量,元素取自 [0, 1) 的均匀分布
random_tensor = tf.random_uniform([2, 3])
# 创建session并运行计算
with tf.Session() as sess:
print(sess.run(random_tensor))输出结果为:
python
# 得到一个形状为 [2, 3] 的张量,它的元素都是随机的、位于 [0, 1) 范围内的浮点数
[[0.15524721 0.94767785 0.6065396 ]
[0.39362884 0.25403404 0.9098687 ]]如果想要改变随机数的范围,可以设置 minval 和 maxval 参数,如下所示:
python
# 生成一个形状为 [2, 3] 的张量,元素取自 [-1, 1) 的均匀分布
random_tensor = tf.random.uniform([2, 3], minval=-1, maxval=1)
tf.random_uniform()在 TensorFlow 2.x 中为tf.random.uniform()
tf.is_numeric_tensor()
tf.is_numeric_tensor() 用于检查输入对象是否为数值类型张量 。以下条件同时满足时该函数返回 True:
x是一个tf.Tensor或tf.Variablex的数据类型(dtype)是数值类型(如float16,float32,int32等)
否则返回 False
python
import tensorflow as tf
numeric_tensor = tf.constant([1, 2, 3])
string_tensor = tf.constant(["hello", "world"])
bool_tensor = tf.constant([True, False])
# 创建session并运行计算
with tf.Session() as sess:
# 直接调用函数,不需要 sess.run()
# 因为返回结果为 Python 布尔值,而不是 Tensorflow 张量
# 在 sess.run() 中只能运行张量或操作
print(tf.is_numeric_tensor(numeric_tensor)) # True
print(tf.is_numeric_tensor(string_tensor)) # False
print(tf.is_numeric_tensor(bool_tensor)) # False
tf.is_numeric_tensor()在 TensorFlow 2.x 中被移除了。在 TensorFlow 2.x 中,可以使用tf.is_tensor()+ 类型检查tensor.dtype
tf.log()
使用 tf.log() 计算张量的自然对数,输出和输入形状相同的张量
python
import tensorflow as tf
a = tf.constant([1.0, 2.0, 3.0])
# 创建session并运行计算
with tf.Session() as sess:
print(sess.run(tf.log(a))) # [0. 0.6931472 1.0986123]
tf.log()在 TensorFlow 2.x 中为tf.math.log()
tf.nn.top_k()
tf.nn.top_k() 用于查找张量中前k个最大值及其索引
python
tf.nn.top_k(input, k=1, sorted=True, name=None)input:输入张量,至少1维,数据类型需支持排序(如float32,int32)k:要返回的最大值的个数sorted:是否对结果降序排列(默认为True)
返回值 :一个命名元组 (values, indices),包含
values:前 k 个最大值,形状为input.shape[:-1] + [k]。默认对最后一维(axis=-1) 进行操作,如输入形状[2, 3, 4]+k=2→ 输出形状[2, 3, 2]indices:这些值在原始输入中的索引,形状与values相同
python
import tensorflow as tf
# 一维张量
x = tf.constant([5, 2, 7, 1, 9, 4])
values, indices = tf.nn.top_k(x, k=3)
# 二维张量(沿最后一维操作)
y = tf.constant([[3, 1, 4], [1, 5, 9]])
vals, idx = tf.nn.top_k(y, k=2)
# 创建session并运行计算
with tf.Session() as sess:
print(sess.run(values))
print(sess.run(indices))
print(sess.run(vals))
print(sess.run(idx))输出结果为:
python
# 一维
[9 7 5] # values
[4 2 0] # indices
# 二维即返回每行的topk值及索引
[[4 3]
[9 5]] # values
[[2 0]
[2 1]] # indices**如果有重复值,返回的索引是第一个出现的下标。**如:
python
import tensorflow as tf
z = tf.constant([3, 1, 3, 2])
vals, idx = tf.nn.top_k(z, k=3)
# 创建session并运行计算
with tf.Session() as sess:
print(sess.run(vals)) # [3 3 2]
print(sess.run(idx)) # [0 2 3]
tf.nn.top_k()在 TensorFlow 2.x 中为tf.math.top_k()
tf.convert_to_tensor()
tf.convert_to_tensor() 用于将 Python 对象或其他类型的张量转换为 TensorFlow 的 Tensor 对象,以确保输入数据能够被 TensorFlow 计算图处理。支持以下输入类型:
- Python标量(如
int/float/bool) - Python列表 / NumPy数组
- ......
python
import tensorflow as tf
import numpy as np
# 将 Python 标量转为 Tensor
t1 = tf.convert_to_tensor(3.14)
arr = np.array([1, 2, 3])
matrix = [[1, 2], [3, 4]]
# 创建session并运行计算
with tf.Session() as sess:
print(sess.run(t1))
# 将 NumPy 数组转为 Tensor
print(sess.run(tf.convert_to_tensor(arr)))
# 将列表/矩阵转为 Tensor
print(sess.run(tf.convert_to_tensor(matrix)))输出结果分别为:
python
3.14
[1 2 3]
[[1 2]
[3 4]]在 TensorFlow 2.x 中,大多数 API 已自动调用
tf.convert_to_tensor(),因此显式调用的需求减少
tf.to_float() / tf.to_int32()
tf.to_float() 用于将输入张量强制转换为 float32 数据类型。tf.to_int32() 同理
python
import tensorflow as tf
# 将整数张量转换为 float32
int_tensor = tf.constant([1, 2, 3], dtype=tf.int32)
# 将布尔张量转换为 float32
bool_tensor = tf.constant([True, False])
# 将浮点数张量转换为 int32
float_tensor = tf.constant([1.0, 2.0, 3.0], dtype=tf.float32)
# 创建session并运行计算
with tf.Session() as sess:
print(sess.run(tf.to_float(int_tensor))) # 输出 dtype=tf.float32
print(sess.run(tf.to_float(bool_tensor))) # True→1.0, False→0.0
print(sess.run(tf.to_int32(float_tensor)))输出结果为:
python
[1. 2. 3.]
[1. 0.]
[1 2 3]
tf.to_float()在 TensorFlow 2.x 中已被弃用。在 TensorFlow 2.x 中,应使用tf.cast()实现相同功能
python
float_tensor = tf.cast(int_tensor, dtype=tf.float32) # 显式指定目标类型compute_weighted_loss
compute_weighted_loss 主要用于对基础损失值进行加权求和或平均 ,属于 tf.losses 模块(具体路径为 tensorflow.python.ops.losses.losses_impl)
python
from tensorflow.python.ops.losses.losses_impl import compute_weighted_loss
compute_weighted_loss(
losses,
weights=1.0,
reduction=Reduction.SUM_BY_NONZERO_WEIGHTS,
scope=None)- 输入:基础损失值(如每个样本的交叉熵损失)
losses和对应的权重weights - 输出:加权后的标量损失值(支持多种归约方式
reduction) - 用途:
- 样本级别的加权(如处理类别不平衡的情况)
- 损失值的归一化(如按样本数或权重和缩放)
参数说明:
| 参数名 | 类型 | 说明 |
|---|---|---|
losses |
Tensor |
基础损失值,形状通常为 [batch_size] 或 [batch_size, ...] |
weights |
Tensor/标量 |
权重值,形状需与 losses 广播兼容(如标量、[batch_size]) |
reduction |
tf.losses.Reduction |
归约方式(默认 Reduction.SUM_BY_NONZERO_WEIGHTS,详见下文) |
scope |
str |
可选。操作命名空间 |
通过 reduction 参数控制如何聚合损失:
| 归约模式 | 计算公式 | 说明 |
|---|---|---|
Reduction.SUM |
sum(losses * weights) |
直接加权求和 |
Reduction.MEAN |
sum(losses * weights) / sum(weights) |
加权平均(推荐) |
Reduction.SUM_BY_NONZERO_WEIGHTS |
sum(losses * weights) / max(1, count(weights > 0)) |
默认。类似 MEAN,但分母是非零权重的数量(防止除零) |
Reduction.NONE |
losses * weights |
不归约,返回与输入相同形状的加权损失 |
示例:
python
import tensorflow as tf
from tensorflow.python.ops.losses.losses_impl import compute_weighted_loss
losses = tf.constant([1.0, 2.0, 3.0]) # 样本损失值
weights = tf.constant([0.5, 1.0, 0.0]) # 样本权重
# 加权平均损失(默认 reduction=SUM_BY_NONZERO_WEIGHTS)
weighted_loss = compute_weighted_loss(losses, weights)
# 创建session并运行计算
with tf.Session() as sess:
# 计算过程:(1.0*0.5 + 2.0*1.0 + 3.0*0.0) / 2 = 1.25
print(sess.run(weighted_loss))在 pairwise logistic loss 中的应用:alibaba/EasyRec - pairwise_loss.py
- TensorFlow 1.x(完整代码)
python
from tensorflow.python.ops.losses.losses_impl import compute_weighted_loss
# 难例挖掘。=1为使用所有样本,即不进行难例挖掘
if ohem_ratio == 1.0:
return compute_weighted_loss(losses, pairwise_weights) # 默认是 Reduction.SUM_BY_NONZERO_WEIGHTS,计算公式为 sum(losses * weights) / max(1, count(weights > 0))
# Reduction.NONE 不归约,保持每个样本对的独立损失
losses = compute_weighted_loss(losses, pairwise_weights, reduction=tf.losses.Reduction.NONE) # losses * weights
# 进行难例挖掘时,需要保留的样本对数量。如 ohem_ratio=0.7 表示使用 70% 最难样本
k = tf.to_float(tf.size(losses)) * tf.convert_to_tensor(ohem_ratio)
k = tf.to_int32(tf.rint(k)) # 四舍五入到最接近的整数
topk = tf.nn.top_k(losses, k) # 选取损失最大的前k个样本对
losses = tf.boolean_mask(topk.values, topk.values > 0) # 确保只保留损失值为正(即模型预测错误)的样本进行梯度更新
return tf.reduce_mean(losses) # 默认计算所有元素的均值- TensorFlow 2.x(完整代码)
python
# 难例挖掘 (OHEM)
if ohem_ratio == 1.0:
# 加权平均损失 (替代compute_weighted_loss), 计算公式: sum(losses * weights) / max(1, count(weights > 0))
return tf.reduce_sum(losses * pairwise_weights) / tf.maximum(
tf.reduce_sum(tf.cast(pairwise_weights > 0, tf.float32)),
1.0)
# 保持每个样本对的独立损失
weighted_losses = losses * pairwise_weights
k = tf.cast(tf.size(losses), tf.float32) * ohem_ratio # 使用ohem_ratio比例的最难样本
k = tf.cast(tf.round(k), tf.int32) # 四舍五入到最接近的整数
topk = tf.nn.top_k(losses, k=k) # 选取损失最大的前k个样本对
topk_weighted_losses = tf.gather(weighted_losses, topk.indices)
topk_weighted_losses = tf.boolean_mask(topk_weighted_losses, topk_weighted_losses > 0) # 只保留损失值为正(即模型预测错误)的样本进行梯度更新
return tf.reduce_mean(topk_weighted_losses) # 计算均值tf.summary.xxx
histogram() 张量
tf.summary.histogram() 用于将张量 中的值分布记录到 TensorBoard 中,这样可以在 TensorBoard 上直观地看到梯度、权重或其他张量随训练步骤的变化
python
tf.summary.histogram('histogram', tensor)histogram是这个summary的名称(在 TensorBoard 中显示),tensor则是希望记录的张量
然后通过如下操作将所有 summary 合并,并通过 writer 写入指定路径,如 ./logs :
python
with tf.Session() as sess:
summary = tf.summary.merge_all()
writer = tf.summary.FileWriter('./logs', sess.graph)接着在运行模型时,需要在会话中运行这个 summary 操作,并将结果添加到 writer 中:
python
...
writer.add_summary(sess.run(summary), step) # step就是当前的训练步骤
# 此时就可以在每个训练步骤对应的 histogram 中看到张量的分布变化了最后打开 TensorBoard,指向日志目录,就可以可视化特征了:
python
tensorboard --logdir=./logsscalar() 标量
tf.summary.scalar() 用于创建一个写入标量 结果到 TensorBoard 的操作,以便在训练和评估模型时追踪模型的某些关键指标,如损失、精度、学习率等
python
for step in range(100):
# 这里的 value 可以是想要追踪的任何标量值
tf.summary.scalar('my_scalar', value, step=step) tf.summary.scalar()在每一步都写入一个名为my_scalar的标量,值是value,步数是step
merge_all()
tf.summary.merge_all() 是 TensorBoard 在 TensorFlow 1.x 版本中使用的一个函数,作用是将所有的 summary 合并成一个操作,以便一次性执行。 该函数会返回一个可以生成所有 summary 协议缓冲区的操作;如果没有任何 summary,返回None
- 为了在 TensorBoard 中展示训练过程中各种参数的变化趋势,需要添加
summary操作。这些操作可能包括:tf.summary.scalar:记录标量,如损失、准确率等tf.summary.histogram:记录张量值的分布情况,如权重、偏置等的变化- ......
- 每一次训练都要运行这些
summary操作,然后把结果写入日志文件。为了方便,可以用tf.summary.merge_all()把它们合并成一个操作,这样一次运行就能获取所有信息
python
tf.summary.scalar('loss', loss)
tf.summary.scalar('accuracy', accuracy)
# 在训练循环中
with tf.Session() as sess:
...
summary = sess.run(tf.summary.merge_all())
writer.add_summary(summary, step)
...完整应用案例
代码:
- 前期准备工作:
python
import tensorflow as tf
import numpy as np
# 清除之前的图
tf.reset_default_graph()
# 创建数据
x = tf.placeholder(tf.float32, [None, 10], name='input') # None表示批次大小可以是任意的
weights = tf.Variable(tf.random_normal([10, 5]), name='weights')
bias = tf.Variable(tf.zeros([5]), name='bias')
# 前向传播
layer_output = tf.matmul(x, weights) + bias
activations = tf.nn.relu(layer_output)
# 预测值和 label
predictions = tf.argmax(activations, axis=1, output_type=tf.int32)
labels = tf.placeholder(tf.int32, [None], name='labels')
# 计算损失和准确率
loss = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(
logits=activations, labels=labels))
accuracy = tf.reduce_mean(tf.cast(tf.equal(predictions, labels), tf.float32))
# 优化器
train_op = tf.train.AdamOptimizer(0.001).minimize(loss)- 创建summary:
python
# 1. tf.summary.scalar - 用于标量值(损失、准确率等)
tf.summary.scalar('loss', loss)
tf.summary.scalar('accuracy', accuracy)
# 2. tf.summary.histogram - 用于分布(权重、激活值等)
tf.summary.histogram('weights', weights)
tf.summary.histogram('bias', bias)
tf.summary.histogram('layer_output', layer_output)
tf.summary.histogram('activations', activations)
# 合并所有 summary
merged_summary = tf.summary.merge_all()- 训练:
python
with tf.Session() as sess:
# 初始化变量
sess.run(tf.global_variables_initializer())
# 创建 FileWriter
train_writer = tf.summary.FileWriter('./logs/train', sess.graph)
# 生成模拟数据
batch_size = 32
for step in range(100):
# 生成随机数据
batch_x = np.random.randn(batch_size, 10)
batch_y = np.random.randint(0, 5, batch_size)
# 运行训练和 summary
_, summary, train_loss, train_acc = sess.run(
[train_op, merged_summary, loss, accuracy],
feed_dict={x: batch_x, labels: batch_y}
)
# 每10步记录一次
if step % 10 == 0:
train_writer.add_summary(summary, step)
print('Step {}, Loss: {:.4f}, Accuracy: {:.4f}'.format(step, train_loss, train_acc))
train_writer.close()运行日志如下:
python
Step 0, Loss: 3.2550, Accuracy: 0.0938
Step 10, Loss: 3.3541, Accuracy: 0.1875
Step 20, Loss: 3.3477, Accuracy: 0.1875
Step 30, Loss: 2.3716, Accuracy: 0.2500
Step 40, Loss: 2.5764, Accuracy: 0.2188
Step 50, Loss: 2.7840, Accuracy: 0.1875
Step 60, Loss: 2.5993, Accuracy: 0.2812
Step 70, Loss: 3.3903, Accuracy: 0.0938
Step 80, Loss: 2.7080, Accuracy: 0.2188
Step 90, Loss: 2.3253, Accuracy: 0.2188在命令行中启动 TensorBoard(注意,一定要在 logs 文件的上一层目录下输入该命令,否则打开TensorBoard 会显示 No scalar data was found. ):
tensorboard --logdir=./logs
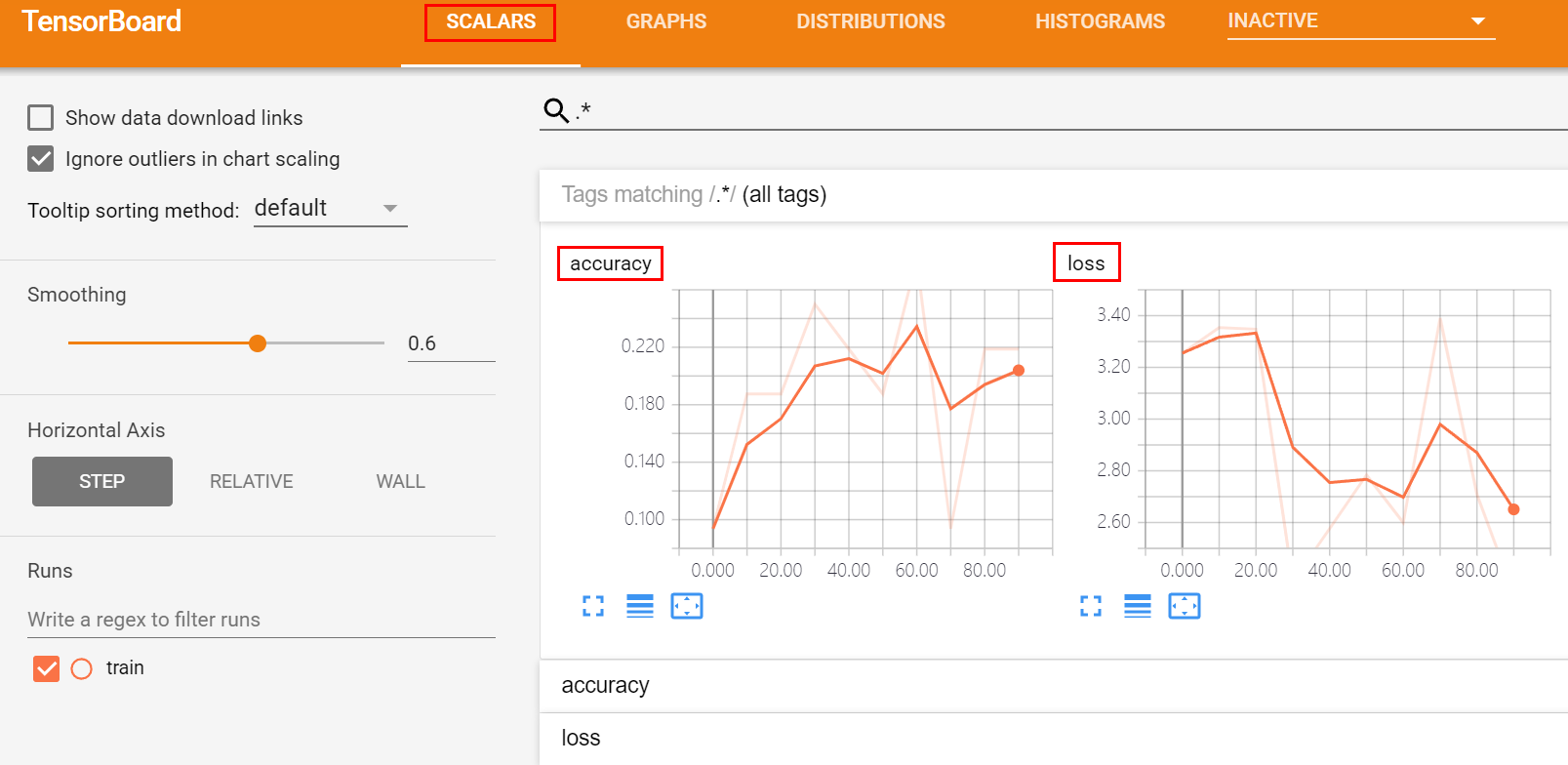
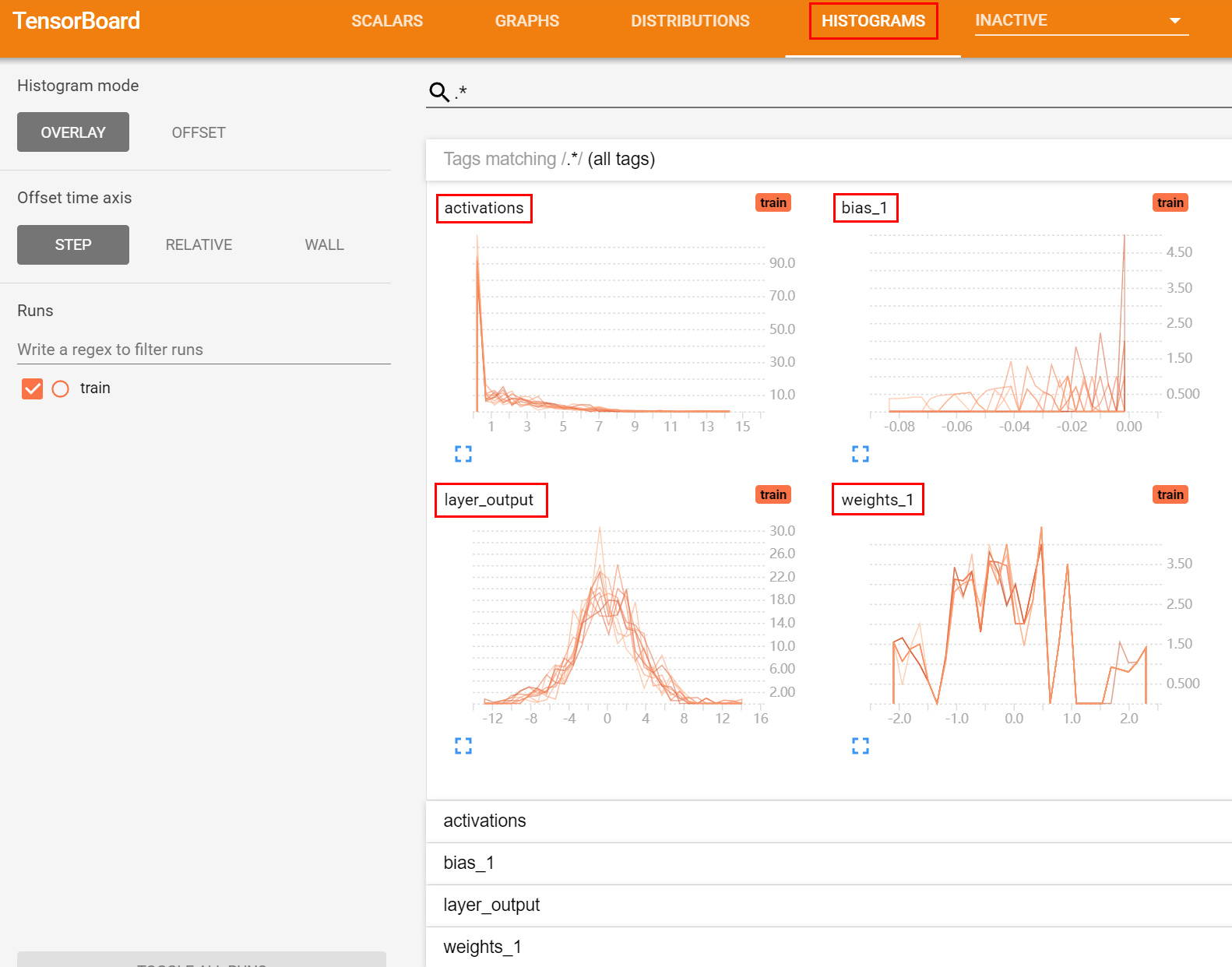
打开链接,TensorBoard 中会显示:
- SCALARS:损失和准确率曲线
- HISTOGRAMS:权重、偏置、激活值的分布
- DISTRIBUTIONS:同上,但以分布形式显示
- GRAPHS:计算图结构
注意,
tf.summary.merge_all()在 TensorFlow 2.x 中已经被移除,因为采用了更加灵活的tf.summary.create_file_writer()进行日志写入,且在with tf.summary.create_file_writer().as_default()块中记录
python
with tf.summary.create_file_writer('logs/train').as_default():
for step in range(100):
tf.summary.histogram('weights', weights, step=step)
tf.summary.scalar('loss', loss, step=step) 其他常用
with tf.name_scope(layer_name)
tf.name_scope() 是 Tensorflow 中使用的一种命名空间技术,用于使 Tensorflow 图(Graph)的结构更加清晰,便于后续的维护和理解
- 当创建多层神经网络时,神经网络的每一层都包含了很多元素,包括各种变量、参数、运算等。如果不做任何区分,所有的元素都会在同一个级别上,这就使得整个网络结构看起来非常混乱,理解和维护起来会非常困难
- 在
tf.name_scope里创建的所有元素的名称,都会带有该name_scope的前缀。例如,如果在"layer1" 这个name_scope里创建一个名为 "weights" 的变量,那么这个变量的全名将会是 **"layer1/weights"。**这样在查看图结构时,就可以清晰地看出这个变量是属于哪一层的
另外,使用 tf.name_scope() 还可以对在 TensorBoard 等工具中展示的图结构进行分层,使得不同的层、模块可以在展示的时候进行折叠和展开,更加直观地展示整个模型的结构
python
with tf.name_scope('layer1'):
w1 = tf.Variable(..., name='weights')
b1 = tf.Variable(..., name='biases')
...在这个例子中,w1 和 b1 的全名将会是 "layer1/weights" 和 "layer1/biases",它们都在 "layer1" 这个命名空间下
@tf.custom_gradient 装饰器
首先说一下修饰符@,其功能是在不改变原有函数内部代码的基础上,拓展原函数的功能
@tf.custom_gradient 是 TensorFlow 中的一个装饰器,用于自定义操作的梯度计算。即定义一个前向计算操作,并明确指定该操作的梯度计算方式。装饰的函数有两部分组成:
- 一部分是前向传播的操作:return的第一项,前向传播过程中函数的输出值
- 一部分是反向传播(计算梯度)的操作:return的第二项,反向传播过程中的梯度值
python
import tensorflow as tf
# TensorFlow 1.x,通常在构建静态计算图时使用
def custom_op_tf1(x):
@tf.custom_gradient
def _inner(x):
# 前向计算
y = tf.log(1. + tf.exp(x)) # softplus函数定义: softplus(x) = log(1 + exp(x))
def grad(dy):
dx = tf.sigmoid(x) * dy # softplus的导数就是sigmoid函数 = 1 / (1 + exp(-x))
return dx
return y, grad
return _inner(x)
x = tf.placeholder(tf.float32)
y = custom_op_tf1(x)
dy_dx = tf.gradients(y, x) # 梯度计算
with tf.Session() as sess:
result = sess.run(dy_dx, feed_dict={x: 2.0})
print(result)注意,
@tf.custom_gradient是在 tensorflow 1.7+ 版本中引入的。在 tensorflow 2.x 中,@tf.custom_gradient常与tf.GradientTape配合使用
python
import tensorflow as tf
@tf.custom_gradient
def custom_op(x):
# 前向计算
result = tf.tanh(x)
# 定义梯度计算
def grad(upstream): # upstream 是来自后续层的梯度
local_grad = 1 - tf.square(result) # tanh的导数
return upstream * local_grad # 链式法则
return result, grad
# 使用自定义操作
x = tf.constant(2.0)
with tf.GradientTape() as tape:
tape.watch(x)
y = custom_op(x)
gradient = tape.gradient(y, x)
print(f"结果: {y.numpy()}, 梯度: {gradient.numpy()}")
# 结果:0.9640275835990906, 梯度:0.07065081596374512应用:梯度裁剪
python
@tf.custom_gradient
def clipped_gradient_op(x):
result = tf.nn.relu(x)
def grad(upstream):
local_grad = tf.cast(x > 0, tf.float32) # relu的导数
clipped_grad = tf.clip_by_value(upstream * local_grad, -1.0, 1.0) # 对梯度进行裁剪
return clipped_grad
return result, gradtf.compat.v1
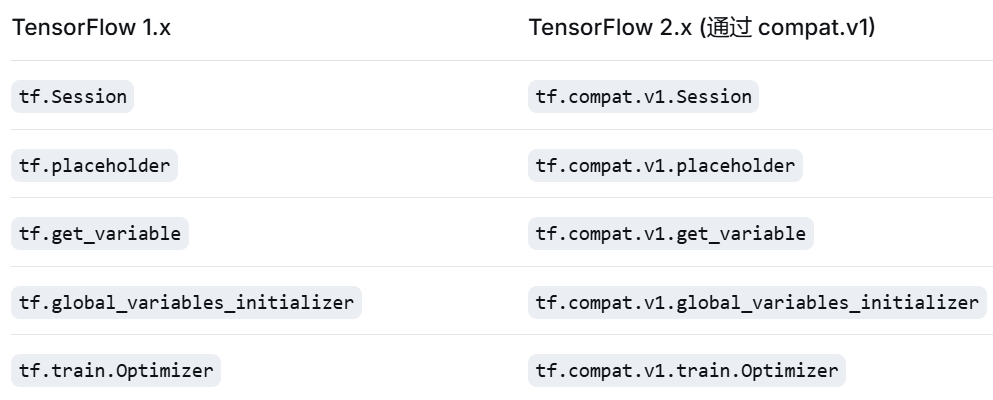
tf.compat.v1 是 TensorFlow 2.x 中提供的一个兼容性模块,用于在 TensorFlow 2 环境中运行 TensorFlow 1.x 的代码
- TensorFlow 1.x :基于静态计算图,使用
tf.Session、placeholder、Variable等 - TensorFlow 2.x:默认启用 Eager Execution,使用更简单的 API
两个例子(以下代码都是在 TensorFlow 2.x 中运行):
python
import tensorflow as tf
tf.compat.v1.disable_v2_behavior() # 启用 v1 行为
x = tf.compat.v1.placeholder(tf.float32, name='input')
w = tf.compat.v1.get_variable('weight', shape=[],
initializer=tf.compat.v1.initializers.ones())
b = tf.compat.v1.get_variable('bias', shape=[],
initializer=tf.compat.v1.initializers.zeros())
output = x * w + b
with tf.compat.v1.Session() as sess:
sess.run(tf.compat.v1.global_variables_initializer())
result = sess.run(output, feed_dict={x: 5.0})
print(result) # 5.0
python
import tensorflow as tf
tf.compat.v1.disable_eager_execution() # 禁用默认的即时执行模式
x = tf.compat.v1.placeholder(tf.float32, shape=[None, 2], name='x')
w = tf.compat.v1.Variable(tf.random.normal([2, 1]), name='weights')
b = tf.compat.v1.Variable(tf.zeros([1]), name='bias')
prediction = tf.matmul(x, w) + b
with tf.compat.v1.Session() as sess:
sess.run(tf.compat.v1.global_variables_initializer())
result = sess.run(prediction, feed_dict={x: [[1, 2], [3, 4]]})
print(result)
# [[-2.5415072]
# [-5.1246552]]TensorFlow 2.x 需要使用 Eager Execution 模式来获取 tensor 的值(默认就是启用的)
python
tf.compat.v1.enable_eager_execution()TensorFlow Allocator
TensorFlow 提供了一个内存管理系统,称为 Allocator,用于在CPU和GPU中分配和回收内存来存储 tensor。主要功能是对内存进行管理,以避免内存溢出或由于内存不足导致的错误。TensorFlow 提供了以下几种类型的 Allocator:
- BFC Allocator (Best Fit with Coalescing):是 TensorFlow 的默认内存分配器,它在内存配置、使用和回收方面有很优秀的性能。通过查找最合适的内存块来满足内存分配需求,并通过合并在释放期间返回的相邻内存区块以获得连续的内存段以减少碎片
- Jemalloc:是由 Facebook 提供的一个 malloc 实现,当 GPU 使用方法不完全符合标准时会使用它
- Eigen ThreadPool Device Allocator:这是 Eigen 中的默认内存分配器,当用户没有指定任何分配器时会使用它。它提供了线程安全的内存分配和管理
这些 Allocator 在需要的时候负责为 tensor 分配内存,当这些 tensor 不再需要时,再进行内存回收