首先我们要明确,加锁的对象是索引,加锁的基本单位是next-key lock,由记录锁和间隙锁组成。next-key是前开后闭区间,间隙锁是前开后开区间。根据不同的查询条件next-key 可能会退化成记录锁或间隙锁。
在能使用记录锁或者间隙锁就能避免幻读现象的场景下, next-key lock 就会退化成记录锁或间隙锁。
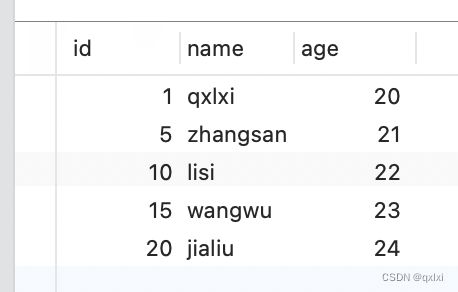
数据准备
CREATE TABLE
user(
idbigint NOT NULL AUTO_INCREMENT,
namevarchar(30) COLLATE utf8mb4_unicode_ci NOT NULL,
ageint NOT NULL,PRIMARY KEY (
id),KEY
index_age(age) USING BTREE) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
唯一索引等值查询
本案例其实就是在主键索引上进行等值查询,取决于查询记录是否存在,存在退化成记录锁,否则就是在索引树中找到第一个大于该查询记录的记录后,将改记录的索引中的next-key lock退换成间隙锁。
记录存在
当执行如下 id=1的锁,会给id=1的记录jiashangX型的记录锁
sql
BEGIN;
SELECT * from user where id = 1 for update;
可以发现对,id=1的记录加了记录锁。update user set age = 25 where id = 1; DELETE FROM user WHERE id = 1; 语句都会被阻塞。
图中 LOCK_TYPE 中的 RECORD 表示行级锁,而不是记录锁的意思
通过 LOCK_MODE 可以确认是 next-key 锁,还是间隙锁,还是记录锁:
如果 LOCK_MODE 为 X,说明是next-key 锁;
如果 LOCK_MODE 为 X, REC_NOT_GAP,说明是记录锁;
如果 LOCK_MODE 为 X,GAP,说明是间隙锁;
这里简单聊下,为什么唯一索引下等值查询就可以将next-key lock退化成记录锁,因为对指定行的操作加锁,可以直接避免其他事务对该行的删除、插入的时候,就可以避免幻读问题。
记录不存在
好了上面主要说的是针对记录存在,针对记录不存在的唯一索引添加锁。
sql
BEGIN;
SELECT * from user where id = 2 for update;
当LOCK_MODE是间隙锁或者Next-key LOCK时,LOCK_DATA代表的就是锁的右边界,锁的左边界就是表中id为5的上一条记录的id值,也就是1,所以本次间隙锁的范围就是(1,5)。当执行INSERT INTOtest.user (id, name, age) VALUES (3, 'zhangsan2', 21); 会获取锁失败,阻塞。
这里由一个疑问就是为什么唯一索引记录不存在的情况下,会从next-key lock退化成间隙锁。
其实这种情况仅靠间隙锁就能解决。幻读的问题。
为什么不可以针对不存在的记录加记录锁,锁是加在索引上的,记录不存在,自然没办法锁住这条不存在的记录。
唯一索引范围查询
针对唯一索引范围查询,会对扫描到的索引加next-key锁
大于或者大于等于的范围查询
情况1:针对大于等于的范围查询,存在等值条件,那么该记录索引中的next-key 退化成记录锁。
sql
BEGIN;
SELECT * from user where id > 15 for update;
1.首先找到的是id=20这一行,然后对该(15,20] 添加间隙锁。
2.由于是范围查询,innodb存储引擎中,有特殊的记录标识最后一条记录。supremum pseudo-record 所以扫描第二行的时候加的是(20,+8]的next- key
当对 16 17 18 19 20 以及20以上的记录进行删除 更新 插入操作时,会被阻塞。
>=情况
sql
BEGIN;
SELECT * from user where id >= 15 for update;
从图中可以看到加了三个锁,由于可以定位到id=15这样记录,所以针对ID=15的记录添加的就是记录锁,而接着扫描的就是20这行记录,对(15,20] 加间隙锁,(20,+8)加间隙锁。
从本案例中可以获取当大于等于时,如果有等于就会针对等于的记录加记录锁。
小于或者小于等于的范围查询
sql
BEGIN;
SELECT * from user where id < 6 for update;
针对「小于或者小于等于」的唯一索引范围查询,如果条件值的记录不在表中,那么不管是「小于」还是「小于等于」的范围查询,扫描到终止范围查询的记录时,该记录中索引的 next-key 锁会退化成间隙锁,其他扫描的记录,则是在这些记录的索引上加 next-key 锁。
< 情况
sql
BEGIN;
SELECT * from user where id < 5 for update;
非唯一索引等值查询
对非唯一索引进行等值查询的时候,因为存在两个索引,一个是主键索引,一个是二级索引。所以在加锁时,同时对这两个索引都加锁。但是对主键索引加锁的时候,只有满足查询条件的记录才会对主键索引加锁。
非唯一性 二级索引、主键索引都加锁
主键索引查询 只针对主键索引加锁
没有加索引的查询
如果锁定读查询语句,没有使用索引列作为查询条件,或者查询语句没有走索引查询,导致扫描是全表扫描。那么,每一条记录的索引上都会加 next-key 锁,这样就相当于锁住的全表,这时如果其他事务对该表进行增、删、改操作的时候,都会被阻塞。
update和delete语句如果查询条件不加索引,扫描方式也是全表扫描,对每一条记录加next-key 锁,相当于锁住的全表。
sql
BEGIN;
SELECT * from user where name = 'qxlxi' for update;
update user set age = age + 1 WHERE name = 'qxlxi';
DELETE FROM user WHERE name = 'qxlxi';
select * from performance_schema.data_locks;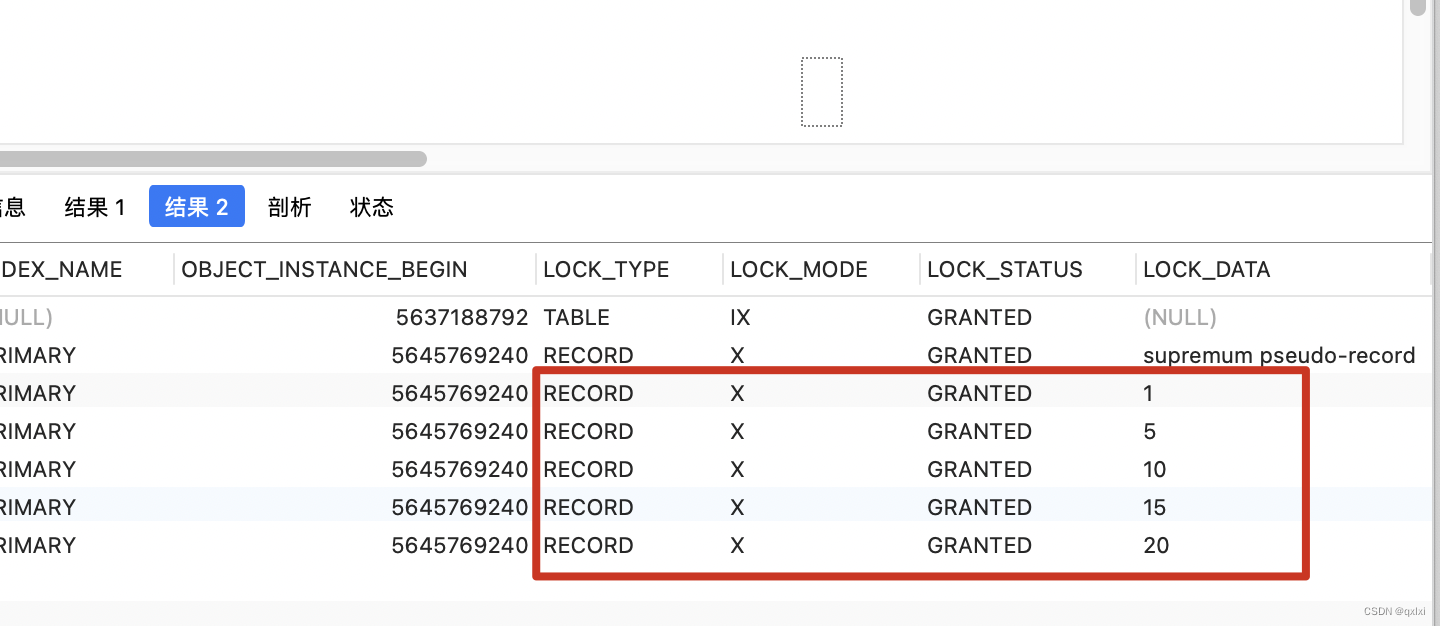
在线上在执行 update、delete、select ... for update 等具有加锁性质的语句,一定要检查语句是否走了索引,如果是全表扫描的话,会对每一个索引加 next-key 锁,相当于把整个表锁住了
小结
本篇主要从实操方面介绍是如何针对不同的查询条件进行加锁。当查询条件是主键索引、普通索引 会出现各种不同的情况,但是总体上其实主要解决的就是通过next-key lock、gap lock,record lock,取避免可能出现幻读的情况。
原则 1:加锁的基本单位是 next-key lock,next-key lock 是前开后闭区间。
原则 2:查找过程中访问到的对象才会加锁。
优化 1:索引上的等值查询,给唯一索引加锁的时候,next-key lock 退化为行锁。
优化 2:索引上的等值查询,向右遍历时且最后一个值不满足等值条件的时候,next-key lock 退化为间隙锁。
一个 bug:唯一索引上的范围查询会访问到不满足条件的第一个值为止。