- 主干网:darknet53网络架构,提取特征(52层卷积,5个下采样)
- 主干网包含:DBL是YOLOV3的最小卷积组件-->卷积提取特征
Resunit(残差单元)--借鉴resnet结构->通过跳跃链接来提取有效特征,通过concat做特征融合
Resn:其中n表示的数字,有多少个残差单元
在darknet53其中CBLcon2D、bn、leaky是YOLOV3最小卷积整合体
优势:提取更多的特征信息
其中1个darknet2维卷积-->Conv2D、BN(正则)
1个leakyrelu层,斜率是0.1,leakyrelu是relu的变换(升级版本)
网络结构:
YOLOV3只有卷积层,通过卷积、步长来提取特征的尺寸
缺点:对于小目标并不敏感
Neck端借鉴金字塔特征图的思想FPN+PAN
作用:根据不同大小尺寸用于提取不同大小物体,小尺寸特征检测大尺寸物体,大尺寸特征检测小物体
YOLOV3总共输出3个不同大小尺寸的特征图,其中
第一个特征图进行32倍下采样
第二个特征图进行16倍下采样
第三个特征图进行8倍下采样
网络结构整个过程:
输入一张原图--->darknet53(没全连接)--->经过YOLOlock生成特征图用于两个方面:
第一个经过3*3卷积,提取特征--产生的第一个特征图,提取特征
第二个经过1*1卷积+上采样
--->与darknet53网络经过的中间层(neck端)数据结构并且拼接
--->产生了第二个特征图-->中间层第二个链接(concat)与小目标ancolbox,与小目标感受野做融合
--->产生第三个特征图
其中:1.concat操作与加操作区别
加操作来源于resnet思想,将输入的特征图与输出的特征图进行做加法运算,维度增加 2.add张量相加-->维度不变
预测部分:
IOU--->交并比,再通过非极大值抑制对冗余的,但不大于最大的框的IOU值进行移除,然后一个完好的框(提取IOU最大的值)
CIOU NMS--在IOU的基础上加了一个闭包--目的是用于两个值有交集
预测部分输出三个不同大小的尺寸:
第一个输出的13*13大小的特征图--直接通过conv2d输出结果
第二个输出的26*26特征图,输出维度26*26--通过conv2d,将x由512通道数转换成256通道数--通过2倍的上采样,将13*13结构,转换26--13*13获取的感受野与中等大小目标做融合拼接
第三个输出的是52*25--经过128个卷积核进行卷积,执行上采样,输出52*52*128--通过darknet、conv2d与152做融合输出52*52检测图
13*13*255====>13*13是特征图的尺寸(宽高)
255====>3*(4+1)-->(x,y,w,h,c<置信度>)+80(coco数据集)=255
YOLOV3在YOLOV2基础上改进和优点:
- 网络结构:darknet19---->darknet53 :网络层次更高,提取特征越丰富
- 特征提取--->使用2个concat--->融入特征信息更加丰富,融入多持续特征图信息来预测
- 先验框更加丰富,每个尺寸都有3个规格,总共9个规格
- 激活函数的改进:通过softmax预测多个标签的需求
- 使用金字塔做不同尺寸的特征融合
感受野:就是通过3*3卷积核进行卷积得到2个特征图,其中第二个特征图由第一个特征图的3*3卷积区域所决定,这个时候可以说,第二个特征图的(一个函数网格)这个未知的感受野就是第一个特征图中的3*3卷积的区域
感受野作用:
- 小尺寸的卷积代替大尺寸卷积---->减少参数,增加网络深度,扩大感受野
- 对于分类任务最后一层特征图的感受野大小要大于等于输入的图像大小,不然性能下降
- 对于目标检测任务,如果感受野小,目标尺寸就大,或者目标比较小感受野比较大,针对模型没有办法收敛

- Anchor框
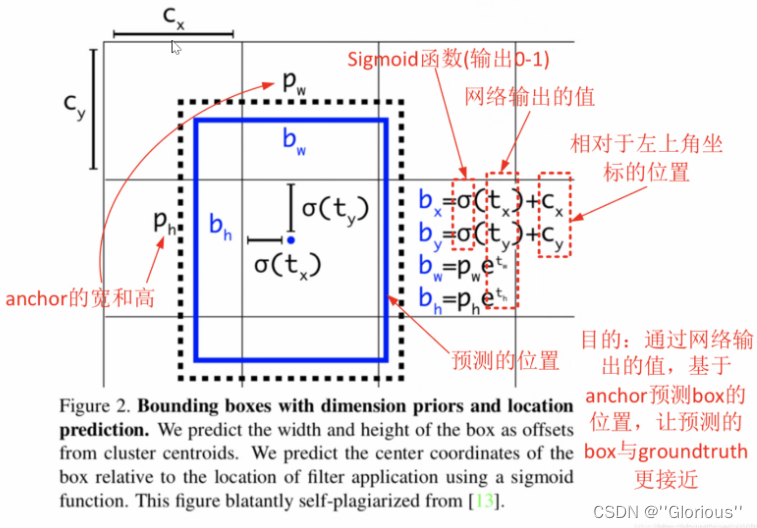
1.bx,by,bw,bh预测框时CX,CY相对于左上角的位置,每个小网格长度为1,
所以cx=1,cy=12.
Tx,ty是预测的坐标迁移量(中心点坐标)
2.Tw,th是尺寸,两个分别要经过sigmoid函数,输出0-1之间偏移量与cx,cy相加后得到bbox
3.pw,ph是预设的anchor、box,
手动设置ancho宽度和高度tw,th分别是pw,ph作用后得到bbox的宽度和高度
以上皆是本人自己的了解!!!