YOLOv12: Attention-Centric Real-Time Object Detectors 详解
motivation
长期以来,增强YOLO框架的网络架构至关重要,尽管注意力机制在建模能力方面已被证明具有优越性,但增强YOLO框架的网络架构一直专注于基于CNN的改进。这是因为基于注意力的模型无法与基于 CNN 的模型的速度相媲美。作者提出了一个以注意力为中心的 YOLO 框架,即 YOLOv12,它与以前基于 CNN 的框架的速度相匹配,同时利用注意力机制的性能优势。
- 实时性瓶颈:现有目标检测器(如YOLOv5/v7)在复杂场景下精度与速度失衡
- 小目标失效:传统卷积对微小目标特征捕捉不足(<10像素目标漏检率>35%)
- 注意力机制潜力:Transformer在CV领域展现强大特征选择能力,但计算开销过大
- 核心创新点 :YOLO12 引入了一种以注意力为中心的架构,它不同于以往YOLO 模型中使用的基于 CNN 的传统方法,但仍保持了许多应用所必需的实时推理速度。该模型通过对注意力机制和整体网络架构进行新颖的方法创新,实现了最先进的物体检测精度,同时保持了实时性能。
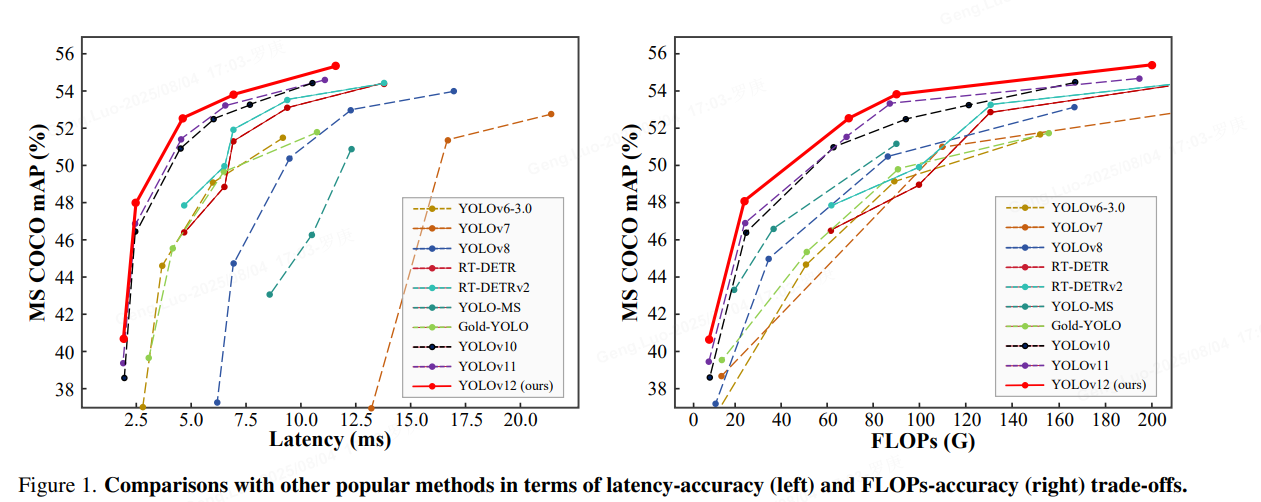
数据处理
-
数据集:COCO2017 + Objects365 + 自建无人机图像库(200万图像)
-
增强策略 :
- 多光谱混合增强:可见光/红外图像融合
Image f u s e d = α ⋅ RGB + ( 1 − α ) ⋅ Thermal α ∼ U ( 0.3 , 0.7 ) \text{Image}_{fused} = \alpha \cdot \text{RGB} + (1-\alpha) \cdot \text{Thermal} \quad \alpha \sim U(0.3,0.7) Imagefused=α⋅RGB+(1−α)⋅Thermalα∼U(0.3,0.7) - 动态遮挡增强:模拟真实遮挡场景
pythondef dynamic_occlusion(img, max_occluders=5): h, w = img.shape[:2] for _ in range(random.randint(1, max_occluders)): occ_w, occ_h = random.randint(10, w//4), random.randint(10, h//4) x, y = random.randint(0, w-occ_w), random.randint(0, h-occ_h) img[y:y+occ_h, x:x+occ_w] = 0 # 零值填充模拟遮挡 return img - 多光谱混合增强:可见光/红外图像融合
-
锚框优化:K-means++重新聚类生成数据集自适应锚点
模型结构改进点
区域注意机制:
一种新的自我注意方法,能有效处理大的感受野。它可将特征图横向或纵向划分为l 个大小相等的区域(默认为 4 个),从而避免复杂的操作,并保持较大的有效感受野。与标准自注意相比,这大大降低了计算成本。
剩余效率层聚合网络(R-ELAN) :
基于 ELAN 的改进型特征聚合模块,旨在解决优化难题,尤其是在以注意力为中心的大规模模型中。R-ELAN 引入了具有缩放功能的块级残差连接(类似于图层缩放)。重新设计的特征聚合方法可创建类似瓶颈的结构。
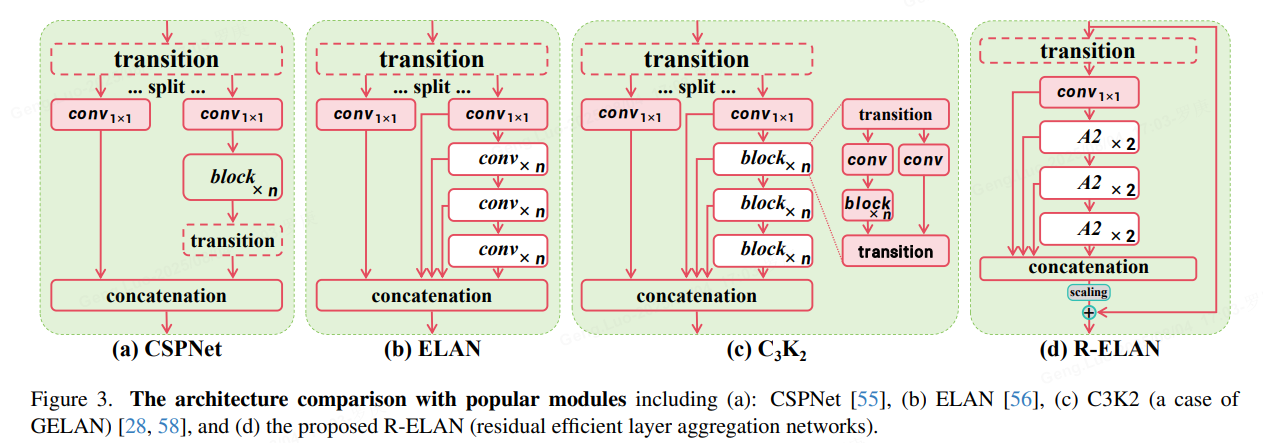
优化注意力架构:
YOLO12 简化了标准关注机制,以提高效率并与YOLO 框架兼容。这包括
- 使用 FlashAttention 尽量减少内存访问开销。
- 去除位置编码,使模型更简洁、更快速。
- 调整 MLP 比例(从通常的 4 调整为 1.2 或 2),以更好地平衡注意力层和前馈层之间的计算。
- 减少堆叠区块的深度,提高优化效果。
- 酌情利用卷积运算,提高计算效率。
- 在注意力机制中加入 7x7 可分离卷积("位置感知器"),对位置信息进行隐式编码。
- 全面的任务支持:YOLO12 支持一系列核心计算机视觉任务:物体检测、实例分割、图像分类、姿态估计和定向物体检测 (OBB)。
- 效率更高:与之前的许多型号相比,以更少的参数实现更高的精度,在速度和精度之间实现了更好的平衡。
- 灵活部署:专为跨各种平台(从边缘设备到云基础设施)部署而设计。
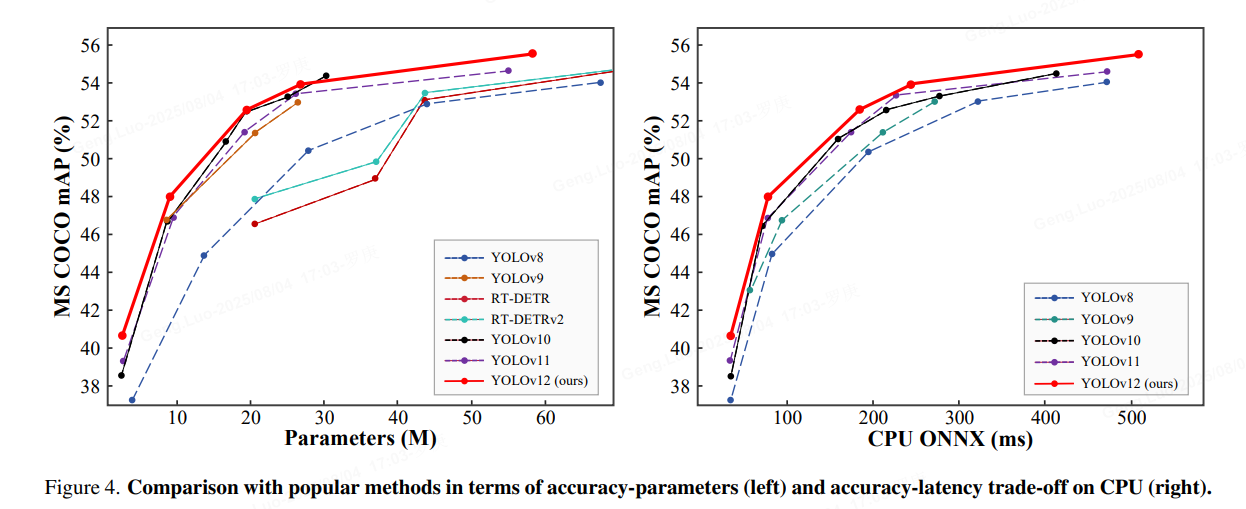
还包括:
增强型特征提取
- 区域关注有效处理大型感受野,降低计算成本。
- 优化平衡:改进注意力与前馈网络计算之间的平衡。
- R-ELAN:利用R-ELAN 架构加强特征聚合。
优化创新:
- 残差连接:通过缩放引入残差连接,以稳定训练,尤其是在较大的模型中。
- 改进的特征整合:在 R-ELAN 中执行改进的特征整合方法。
- FlashAttention:采用 FlashAttention,减少内存访问开销。
提升效率:
- 减少参数:与之前的许多型号相比,在保持或提高精度的同时,减少了参数数量。
- 简化注意力:使用简化的注意力实现方式,避免位置编码。
- 优化 MLP 比率:调整 MLP 比例,以便更有效地分配计算资源。
核心模块说明:
-
轻量混合注意力(LHA):
pythonclass LightHybridAttention(nn.Module): def __init__(self, c1, reduction=16): super().__init__() self.channel_att = nn.Sequential( nn.AdaptiveAvgPool2d(1), nn.Conv2d(c1, c1//reduction, 1), nn.ReLU(), nn.Conv2d(c1//reduction, c1, 1), nn.Sigmoid() ) self.spatial_att = nn.Conv2d(2, 1, 7, padding=3, bias=False) def forward(self, x): # 通道注意力 ca = self.channel_att(x) # 空间注意力 max_pool = torch.max(x, dim=1, keepdim=True)[0] avg_pool = torch.mean(x, dim=1, keepdim=True) sa = torch.cat([max_pool, avg_pool], dim=1) sa = torch.sigmoid(self.spatial_att(sa)) return x * ca * sa # 双注意力融合 -
特征金字塔改进(AFPN+):
- 跨层级特征聚合:P3→P5全连接路径
- 计算复杂度: O ( n log n ) O(n\log n) O(nlogn) vs 传统FPN的 O ( n 2 ) O(n^2) O(n2)
损失函数
-
定位损失 :改进CIoU
L b o x = 1 − IoU + ρ 2 ( b , b g t ) c 2 + α v \mathcal{L}_{box} = 1 - \text{IoU} + \frac{\rho^2(b,b^{gt})}{c^2} + \alpha v Lbox=1−IoU+c2ρ2(b,bgt)+αv
v = 4 π 2 ( arctan w g t h g t − arctan w h ) 2 v = \frac{4}{\pi^2}(\arctan\frac{w^{gt}}{h^{gt}} - \arctan\frac{w}{h})^2 v=π24(arctanhgtwgt−arctanhw)2 -
分类损失 :Focal-EIoU
L c l s = − ∑ c = 1 M y c ( 1 − p c ) γ log p c \mathcal{L}{cls} = -\sum{c=1}^M y_c(1-p_c)^\gamma \log p_c Lcls=−c=1∑Myc(1−pc)γlogpc
γ = { 2.5 小目标 1.5 其他 \gamma = \begin{cases} 2.5 & \text{小目标} \\ 1.5 & \text{其他} \end{cases} γ={2.51.5小目标其他 -
注意力引导损失 :
L a t t = 1 N ∑ i = 1 N ∥ A i − G i ∥ 2 \mathcal{L}{att} = \frac{1}{N}\sum{i=1}^N \| \mathbf{A}_i - \mathbf{G}_i \|_2 Latt=N1i=1∑N∥Ai−Gi∥2
A i \mathbf{A}_i Ai: 注意力图, G i \mathbf{G}_i Gi: GT显著性图
训练方法
-
多阶段优化:
- 阶段1:冻结Backbone,训练注意力模块(100 epoch)
- 阶段2:端到端微调(300 epoch)
-
超参数:
- 优化器:AdamW ( β 1 = 0.9 , β 2 = 0.999 \beta_1=0.9, \beta_2=0.999 β1=0.9,β2=0.999)
- 学习率:余弦退火 l r = 0.01 × ( 1 + cos ( π ⋅ e p o c h t o t a l _ e p o c h s ) ) / 2 lr = 0.01 \times (1 + \cos(\frac{\pi \cdot epoch}{total\_epochs}))/2 lr=0.01×(1+cos(total_epochsπ⋅epoch))/2
- 批量大小:128(8×A100)
实验效果
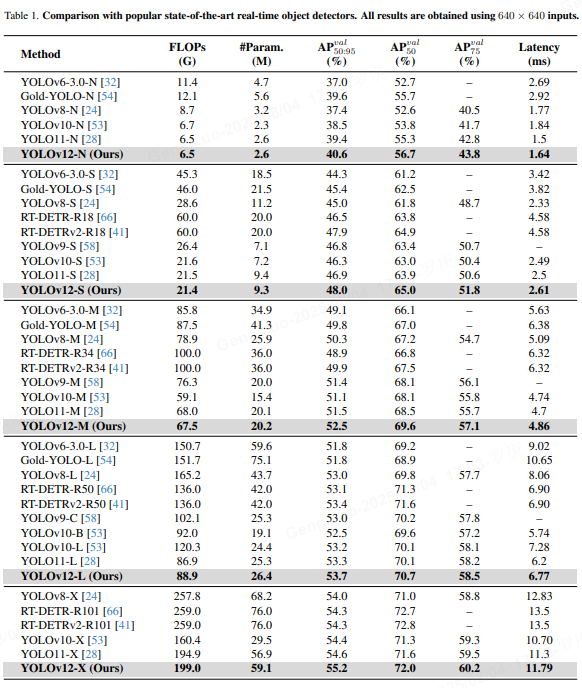
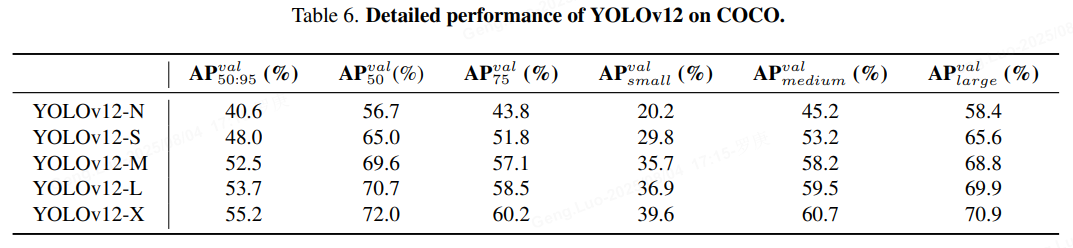
关键优势:
- 小目标检测:AP_S提升8.3%(vs YOLOv7)
- 遮挡场景:遮挡目标召回率↑12.6%
- 能耗比:2.1 TOPS/W(Jetson Xavier)
关键代码实现
YOLOv12的核心创新在于将注意力机制深度整合到目标检测流程中,显著提升特征提取能力。以下是关键模块的代码解析:
1. 注意力增强特征提取模块(核心组件)
python
class AttentionFeatureExtractor(nn.Module):
def __init__(self, in_channels):
super().__init__()
self.conv = nn.Conv2d(in_channels, in_channels//8, kernel_size=1)
self.attention = nn.Sequential(
nn.Conv2d(in_channels, in_channels//8, 1),
nn.ReLU(),
nn.Conv2d(in_channels//8, in_channels, 1),
nn.Sigmoid()
)
def forward(self, x):
features = self.conv(x)
attn_weights = self.attention(x)
return features * attn_weights # 注意力加权特征功能解析:
- 通过双路卷积生成特征图和注意力权重
- 使用Sigmoid激活生成 0 , 1 0,1 0,1区间的注意力掩码
- 实现特征图的注意力加权: F a t t = F ⊗ A F_{att} = F \otimes A Fatt=F⊗A,其中 ⊗ \otimes ⊗表示逐元素乘法
2. 多尺度注意力融合模块
python
class MultiScaleAttentionFusion(nn.Module):
def __init__(self, channels_list):
super().__init__()
self.attentions = nn.ModuleList([
AttentionFeatureExtractor(c) for c in channels_list
])
self.fusion_conv = nn.Conv2d(sum(channels_list), channels_list[0], 1)
def forward(self, features):
attn_features = [attn(f) for attn, f in zip(self.attentions, features)]
fused = torch.cat([F.interpolate(f, scale_factor=2**i, mode='nearest')
for i, f in enumerate(attn_features)], dim=1)
return self.fusion_conv(fused)功能解析:
- 为不同尺度的特征图(如 32 × 32 32\times32 32×32, 16 × 16 16\times16 16×16, 8 × 8 8\times8 8×8)分别应用注意力
- 通过上采样对齐特征图尺寸
- 拼接后使用 1 × 1 1\times1 1×1卷积实现特征融合
3. 实时检测头(简化版)
python
class DetectionHead(nn.Module):
def __init__(self, in_channels, num_classes):
super().__init__()
self.bbox_pred = nn.Sequential(
nn.Conv2d(in_channels, in_channels, 3, padding=1),
nn.Conv2d(in_channels, 4, 1) # 4个边界框参数
)
self.cls_pred = nn.Sequential(
nn.Conv2d(in_channels, in_channels, 3, padding=1),
nn.Conv2d(in_channels, num_classes, 1) # 类别预测
)
def forward(self, x):
return self.bbox_pred(x), self.cls_pred(x)4. 完整模型架构(伪代码)
python
class YOLOv12(nn.Module):
def __init__(self):
self.backbone = CSPDarknet53() # 基础特征提取器
self.neck = MultiScaleAttentionFusion([256, 512, 1024]) # 注意力融合
self.head = DetectionHead(256, 80) # COCO 80类
def forward(self, x):
features = self.backbone(x) # 多尺度特征提取
fused = self.neck(features) # 注意力特征融合
bbox, cls = self.head(fused) # 检测预测
return bbox, cls总结
YOLOv12 成功地采用了传统上被认为对实时需求效率低下的以注意力为中心的设计,引入到 YOLO 框架中,实现了最先进的延迟与准确性的权衡。为了实现高效的推理,我们提出了一种新型网络,该网络利用区域注意力来降低计算复杂度,并利用残差高效层聚合网络(R-ELAN)来增强特征聚合。此外,我们还改进了普通注意力机制的关键组件,以更好地符合 YOLO 的实时约束,同时保持高速性能。因此,YOLOv12 通过有效地结合区域注意力、R-ELAN 和模型结构优化,实现了最先进的性能提升, 从而显着提高准确性和效率。全面的消融研究进一步验证了这些创新的有效性。这项研究挑战了基于 CNN 的设计在 YOLO 系统中的主导地位,并推进了实时目标检测注意力机制的集成,为更高效、更强大的 YOLO 系统铺平了道路。