一、项目背景与需求
【打怪升级 - 07】基于 YOLO12 的车辆与人员数量统计系统:从理论到代码实战,零基础实现你的第一个深度学习应用
在智能安防、交通管理、停车场调度等场景中,实时统计监控区域内的车辆与人员数量是核心需求。传统方案依赖人工计数或单一目标检测模型,存在精度低、实时性差、易受复杂环境(如遮挡、光照变化)干扰等问题。
二、技术选型:为什么选择 YOLO12?
YOLO12 作为 2025 年发布的新一代实时目标检测模型, 融合了几项关键创新,在速度和准确性之间取得了平衡。与标准的自我注意相比,区域注意机制能有效处理大型感受野,从而降低计算成本。(区域注意力采用最直接的均匀划分方式,将特征图在垂直或水平方向上划分为l个区域(默认值为4)。这样在确保大感受野的同时避免了复杂操作,从而实现了高效率。 )

剩余高效层聚合网络(R-ELAN)改进了特征聚合,解决了以注意力为中心的大型模型中的优化难题。优化注意力架构,包括使用 FlashAttention 和取消位置编码,进一步提高了效率。这些功能使 YOLO12 在保持对许多应用至关重要的实时推理速度的同时,实现了最先进的准确性。

YOLO12在所有模型尺度上都展现出显著的精度提升,与之前最快的YOLO模型相比,在速度上有一些权衡。以下是COCO验证数据集上目标检测的定量结果:
| Model | size (pixels) | mAPval 50-95 | Speed CPU ONNX (ms) | Speed T4 TensorRT (ms) | params (M) | FLOPs (B) | Comparison (mAP/Speed) |
|---|---|---|---|---|---|---|---|
| YOLO12n | 640 | 40.6 | - | 1.64 | 2.6 | 6.5 | +2.1%/-9% (vs. YOLOv10n) |
| YOLO12s | 640 | 48.0 | - | 2.61 | 9.3 | 21.4 | +0.1%/+42% (vs. RT-DETRv2) |
| YOLO12m | 640 | 52.5 | - | 4.86 | 20.2 | 67.5 | +1.0%/-3% (vs. YOLO11m) |
| YOLO12l | 640 | 53.7 | - | 6.77 | 26.4 | 88.9 | +0.4%/-8% (vs. YOLO11l) |
| YOLO12x | 640 | 55.2 | - | 11.79 | 59.1 | 199.0 | +0.6%/-4% (vs. YOLO11x) |
三、系统设计方案(完整代码在B站视频评论区)
系统整体架构分为 4 个模块,流程如下:
视频流输入 → 预处理 → YOLO12推理 → 目标计数 → 结果可视化
1. 模块详解
-
视频流输入 :支持本地视频文件、本地图片,通过 OpenCV 读取帧数据(帧率默认 25fps)。
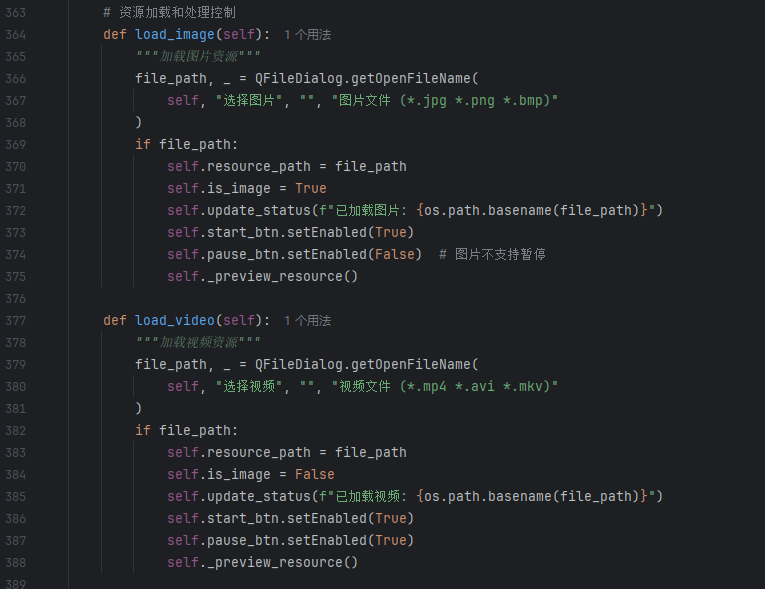
-
预处理 :对输入帧进行 Resize(默认 640×640)、归一化(像素值缩放到 0-1)和 BGR 转 RGB(适配 YOLO12 输入格式)。
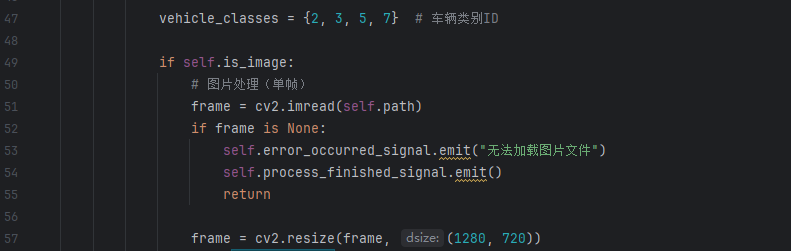
-
YOLO12 推理 :加载预训练模型,输出目标的类别(person/car/truck 等)、边界框坐标和置信度(过滤阈值默认 0.5)。
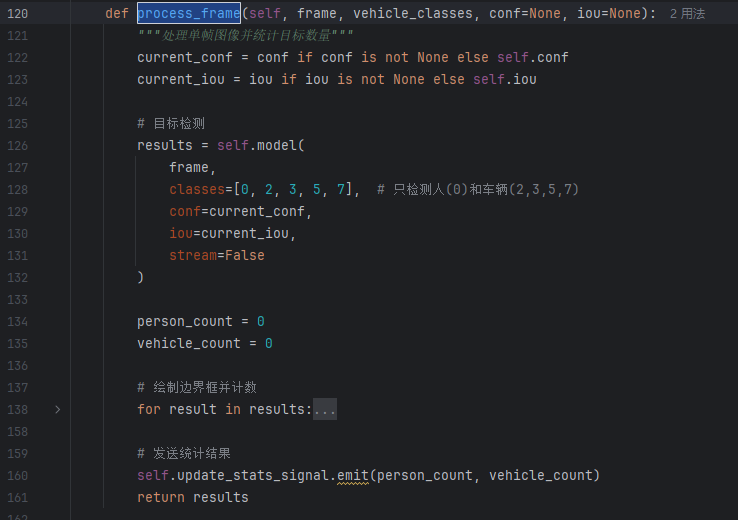
-
目标计数
:采用 "单帧计数 + 去重优化" 策略:
- 单帧计数:统计当前帧中 "person""car""truck" 的数量。
- 去重优化:对连续帧中重叠度 > 0.7 的目标(如移动的行人 / 车辆),通过 IOU 匹配避免重复计数。
-
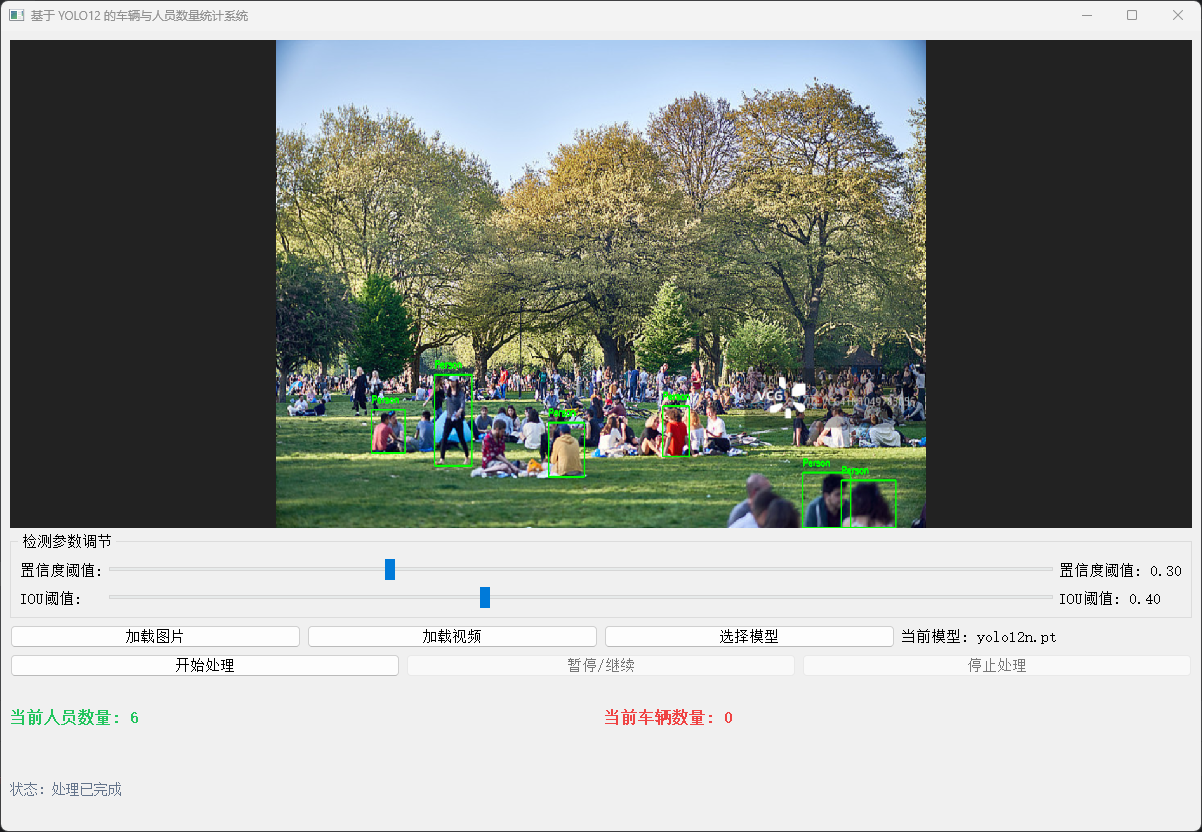
结果可视化:我们的可视化使用PyQt5这个可视化工具,能够在可视化页面上绘制边界框、类别标签和实时计数,输出带统计信息的视频流。此外,还能够在可视化界面上进行图片或视频的加载、模型的选择、置信度和IOU的实时调整、模型推理的暂停/继续、推理。
四、实战实现:从 0 到 1 搭建系统
1. 环境配置
【打怪升级 - 03】YOLO11/YOLO12/YOLOv10/YOLOv8 完全指南:从理论到代码实战,新手入门必看教程(文末有视频介绍)
2. 数据集准备与模型微调
【打怪升级 - 06】YOLO 全家桶人体姿态识别完全指南:从 YOLOv8 到 YOLO12 核心原理 + 代码实战,新手入门保姆级教程(附视频详解)
-
数据集:使用 COCO2017 的 "person""car""truck""bus" 类别(约 5 万张图像),补充自定义场景数据(如停车场、路口监控)。
-
数据增强:启用 Mosaic、MixUp、随机翻转和亮度调整,提升模型泛化能力。
-
微调训练
python# 训练命令(epochs=50,batch=16,输入尺寸640) model.train(data='custom_data.yaml', epochs=50, imgsz=640, batch=16, device=0)其中
custom_data.yaml需指定训练集路径和类别(nc=4,names='person', 'car', 'truck', 'bus')。
3. 核心代码实现
完整代码在B站视频评论区
五、性能优化与场景适配
- 实时性优化 :
- 对边缘设备(如 Jetson Nano),使用
yolov12n.pt(nano 模型),并启用 FP16 推理,帧率可达 15fps 以上。 - 降低输入尺寸(如 480×480),牺牲少量精度换取速度提升。
- 对边缘设备(如 Jetson Nano),使用
- 复杂场景适配 :
- 遮挡场景:调大
conf_threshold至 0.6,减少低置信度目标干扰;启用 YOLO12 的--imgsz 1280提升分辨率。 - 夜间场景:预处理时增加对比度增强,或加载专门训练的夜间数据集模型。
- 遮挡场景:调大
- 计数准确性提升 :
- 结合 SORT 追踪算法,对目标进行 ID 追踪,避免重复计数(适合动态场景)。
- 划定 ROI 区域(如停车场入口),仅统计区域内目标,过滤背景干扰。