编译器:Pycharm

效果展示如图
简单原理描述:模拟人工动作爬取页面信息,运行脚本后代码自动打开浏览器获取相关信息,模拟人工进行页面跳转并自动抓取页面信息记录到表格中。
深入原理描述:页面翻转的时候会调用接口,接口中含有数据信息,定义数组存储需要的信息
需要引入的包
from DrissionPage import ChromiumPage import csv import time
这边模拟的是抓取浙江-建筑设计相关的岗位信息
如图总共抓取了3000多条岗位信息
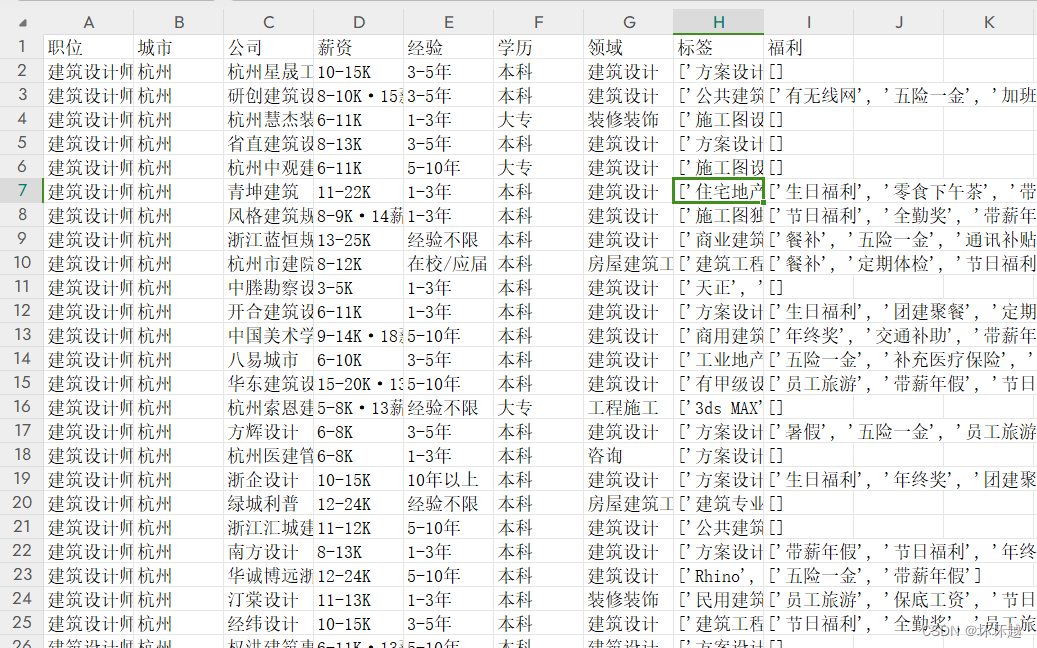
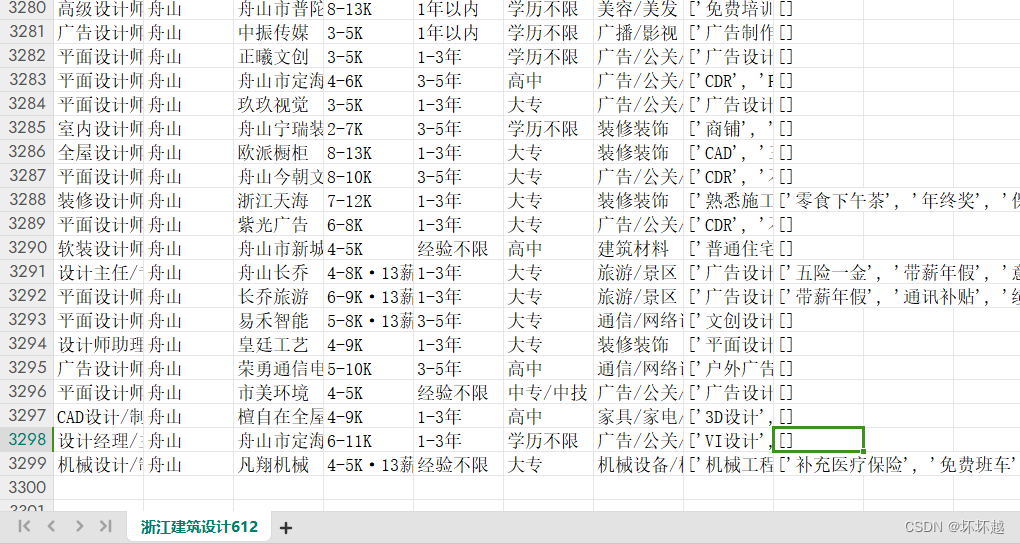
代码
from DrissionPage import ChromiumPage
import csv
import time
f = open('浙江建筑设计612.csv', mode='w', encoding='utf-8', newline='')
csv_write = csv.DictWriter(f, fieldnames=[
'职位', '城市', '公司', '薪资', '经验', '学历', '领域', '标签', '福利'
])
csv_write.writeheader()
driver = ChromiumPage()
driver.listen.start('/wapi/zpgeek/common/data/city/site.json')
driver.get('https://www.zhipin.com/web/geek/job?query=建筑设计&city=101210400')
resp = driver.listen.wait()
time.sleep(2)
json_data = resp.response.body
print(json_data)
time.sleep(2)
areaList = json_data['zpData']['siteList']
for area in areaList:
if area['name'] == '浙江':
subLevelModelList = area['subLevelModelList']
for city in subLevelModelList:
city_code = city['code']
city_name = city['name']
url = f'https://www.zhipin.com/web/geek/job?query=建筑设计&city={city_code}'
driver.listen.start('/wapi/zpgeek/search/joblist.json')
time.sleep(2)
driver.get(url)
for page in range(10): # 可根据实际情况修改页数
time.sleep(1)
driver.scroll.to_bottom()
resp = driver.listen.wait()
json_data = resp.response.body
if json_data==None:
print(str(city_code) + 'fail')
break
jobList = json_data['zpData']['jobList']
for job in jobList:
dit = {
'职位': job['jobName'],
'城市': job['cityName'],
'公司': job['brandName'],
'薪资': job['salaryDesc'],
'经验': job['jobExperience'],
'学历': job['jobDegree'],
'领域': job['brandIndustry'],
'标签': job['skills'],
'福利': job['welfareList'],
}
csv_write.writerow(dit)
print(dit)
element = driver.ele('css:.ui-icon-arrow-right').parent()
print(driver.ele('css:.ui-icon-arrow-right').parent().__getattr__('class'))
if element.__getattr__('class') is not None:
if 'disabled' in element.__getattr__('class'):
print("上一页按钮被禁用,跳出循环")
break
else:
print("元素未找到,正常运行")
driver.ele('css:.ui-icon-arrow-right').click()
f.close()代码讲解:
开头定义了个csv文件供数据存储并定义了首行内容
然后打开了浏览器制定页面,获取需要的信息,为了便于其他省份的同学们查找,增强复用性,我这边是先抓取了地址areaList,然后找到对应的省份,你要找别的省份修改省名就好了。在url中设定了岗位。实现抓取某省份-某岗位的信息。
这边是对每个城市模拟了10次翻页记录
考虑了某些岗位可能某城市都没10页,设定了不足10页,比如你到了第八页没下一页了,自动退出循环进行下一个城市的查询~
总体来说操作还是比较简单的,但是如果你没有用过pycharm的话,在环境搭建上你可能会遇到一些问题,这块的话就需要查略其他资料进行解决了~