Hbase布隆过滤器
小白的Hbase学习笔记
目录
[1.过滤表中所有Value中 >23 的内容](#1.过滤表中所有Value中 >23 的内容)
2.获取表中age列大于23的所有RowKey值(1的改进)
[4.按前缀 准确值 后缀查找](#4.按前缀 准确值 后缀查找)
5.获取RowKey中包含15001000的所有RowKey(速度更快)
[7.获取列名称以 na 开头的所有RowKey](#7.获取列名称以 na 开头的所有RowKey)
[8.对学生表中的信息进行过滤 条件有:1.所有性别为男性 2.所有文科班 3.年龄大于23岁](#8.对学生表中的信息进行过滤 条件有:1.所有性别为男性 2.所有文科班 3.年龄大于23岁)
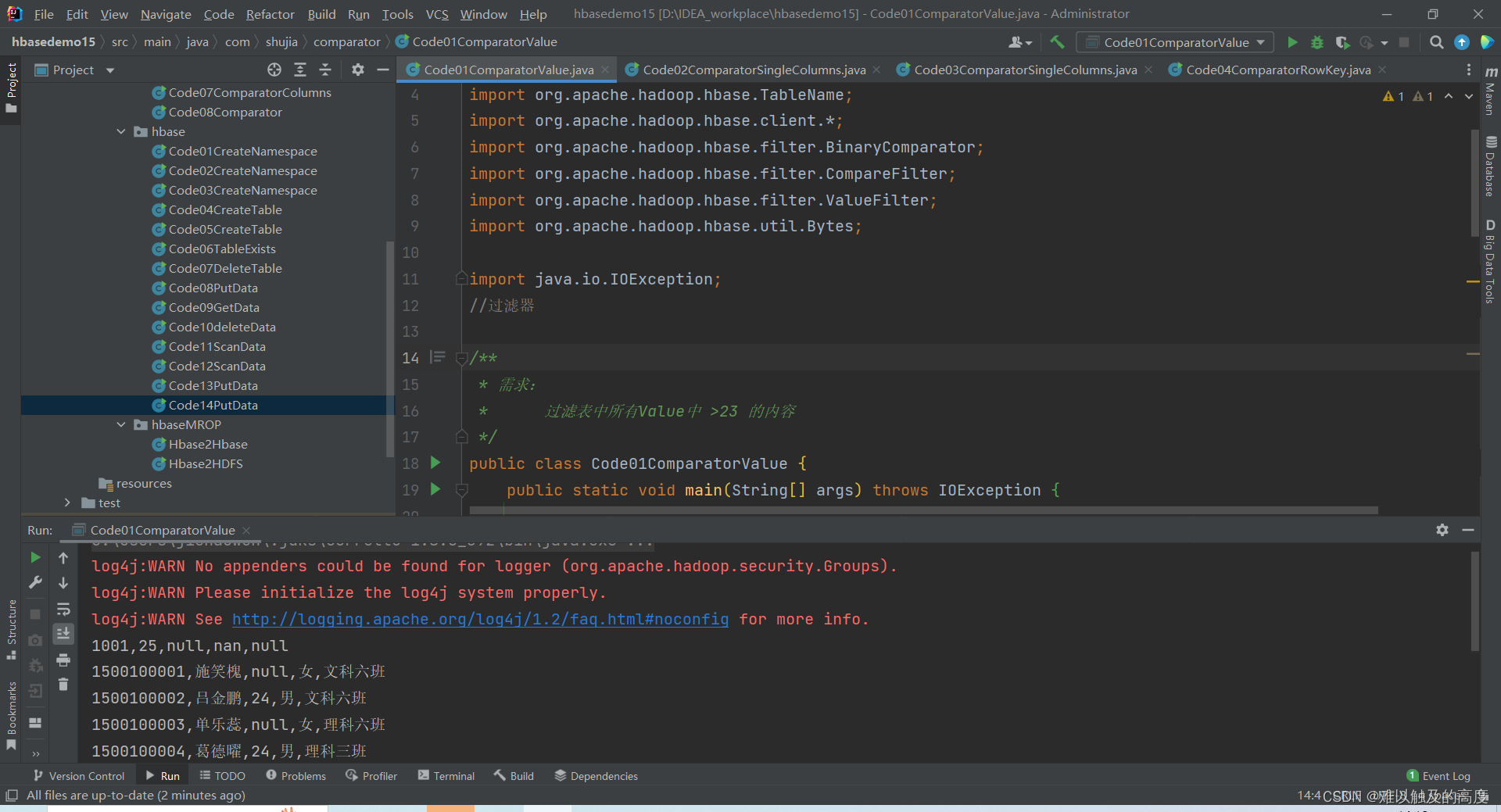
1.过滤表中所有Value中 >23 的内容
java
package com.shujia.comparator;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.filter.BinaryComparator;
import org.apache.hadoop.hbase.filter.CompareFilter;
import org.apache.hadoop.hbase.filter.ValueFilter;
import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException;
//过滤器
/**
* 需求:
* 过滤表中所有Value中 >23 的内容
*/
public class Code01ComparatorValue {
public static void main(String[] args) throws IOException {
Configuration conf = new Configuration();
conf.set("hbase.zookeeper.quorum","node1,node2,master");
Connection conn = ConnectionFactory.createConnection(conf);
Table table = conn.getTable(TableName.valueOf("jan:tbl1"));
Scan scan=new Scan();
/**
* (CompareOp valueCompareOp, ByteArrayComparable valueComparator)
*/
//创建字节比较器 参数传入具体比较的值
BinaryComparator binaryComparator = new BinaryComparator(Bytes.toBytes("23"));
//该过滤器是针对于当前表中所有的值进行过滤 只要满足则返回一行 并且 如果不满足返回NULL
//put 'jan:tbl1','1001','info:name','25'
ValueFilter filter = new ValueFilter(CompareFilter.CompareOp.GREATER, binaryComparator);
//设置过滤器
scan.setFilter(filter);
//获取扫描器对象
ResultScanner scanner = table.getScanner(scan);
for (Result result : scanner) {
String rowKey = Bytes.toString(result.getRow());
String name = Bytes.toString(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("name")));
String age = Bytes.toString(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("age")));
String gender = Bytes.toString(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("gender")));
String clazz = Bytes.toString(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("clazz")));
System.out.println(rowKey+","+name+","+age+","+gender+","+clazz);
}
table.close();
conn.close();
}
}
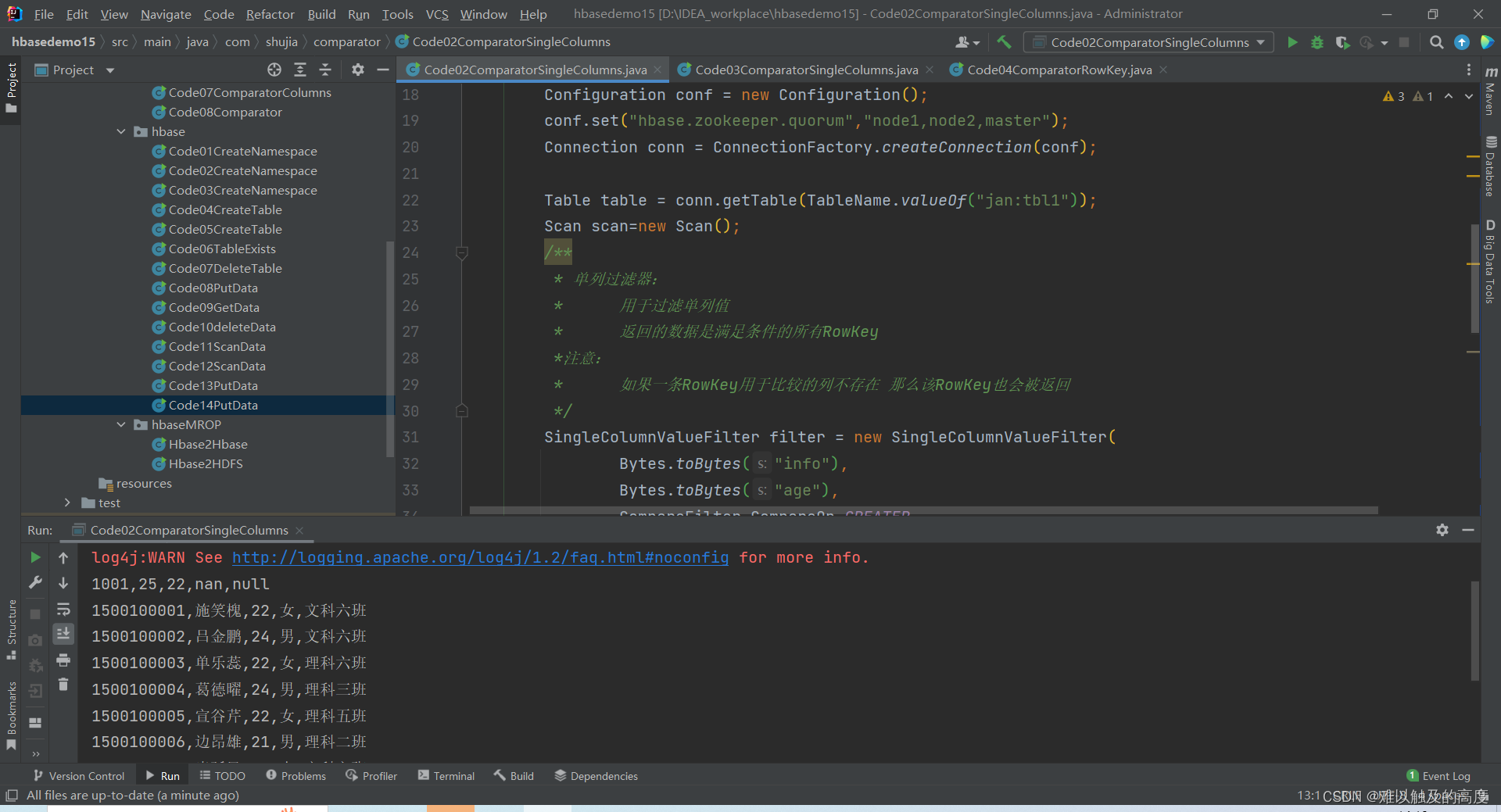
2.获取表中age列大于23的所有RowKey值(1的改进)
java
package com.shujia.comparator;
//需求:获取表中age列大于23的所有RowKey值
//01的改进代码
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.filter.BinaryComparator;
import org.apache.hadoop.hbase.filter.CompareFilter;
import org.apache.hadoop.hbase.filter.SingleColumnValueFilter;
import org.apache.hadoop.hbase.filter.ValueFilter;
import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException;
public class Code02ComparatorSingleColumns {
public static void main(String[] args) throws IOException {
Configuration conf = new Configuration();
conf.set("hbase.zookeeper.quorum","node1,node2,master");
Connection conn = ConnectionFactory.createConnection(conf);
Table table = conn.getTable(TableName.valueOf("jan:tbl1"));
Scan scan=new Scan();
/**
* 单列过滤器:
* 用于过滤单列值
* 返回的数据是满足条件的所有RowKey
*注意:
* 如果一条RowKey用于比较的列不存在 那么该RowKey也会被返回
*/
SingleColumnValueFilter filter = new SingleColumnValueFilter(
Bytes.toBytes("info"),
Bytes.toBytes("age"),
CompareFilter.CompareOp.GREATER,
Bytes.toBytes(23));
//设置过滤器
scan.setFilter(filter);
//获取扫描器对象
ResultScanner scanner = table.getScanner(scan);
for (Result result : scanner) {
String rowKey = Bytes.toString(result.getRow());
String name = Bytes.toString(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("name")));
String age = Bytes.toString(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("age")));
String gender = Bytes.toString(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("gender")));
String clazz = Bytes.toString(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("clazz")));
System.out.println(rowKey+","+name+","+age+","+gender+","+clazz);
}
table.close();
conn.close();
}
}
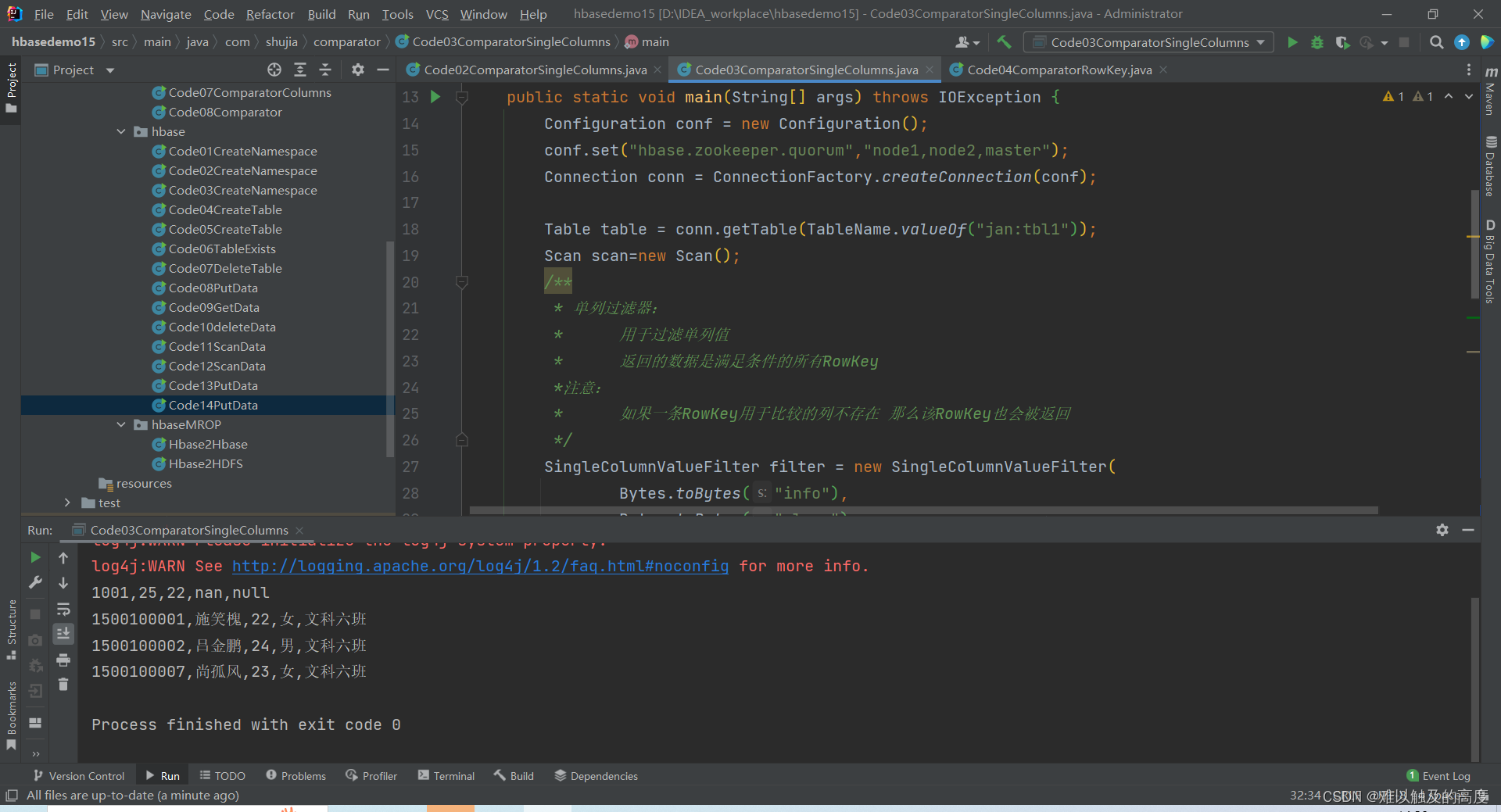
3.比较以某个Value值开头的列
java
package com.shujia.comparator;
//该比较器用于比较以某个Value值开头的列
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.filter.*;
import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException;
public class Code03ComparatorSingleColumns {
public static void main(String[] args) throws IOException {
Configuration conf = new Configuration();
conf.set("hbase.zookeeper.quorum","node1,node2,master");
Connection conn = ConnectionFactory.createConnection(conf);
Table table = conn.getTable(TableName.valueOf("jan:tbl1"));
Scan scan=new Scan();
/**
* 单列过滤器:
* 用于过滤单列值
* 返回的数据是满足条件的所有RowKey
*注意:
* 如果一条RowKey用于比较的列不存在 那么该RowKey也会被返回
*/
SingleColumnValueFilter filter = new SingleColumnValueFilter(
Bytes.toBytes("info"),
Bytes.toBytes("clazz"),
CompareFilter.CompareOp.EQUAL,
//该比较器用于比较以某个Value值开头的列
new BinaryPrefixComparator(Bytes.toBytes("文科")));//二进制前缀比较器
//new BinaryPrefixComparator(Bytes.toBytes("文科六")));
//设置过滤器
scan.setFilter(filter);
//获取扫描器对象
ResultScanner scanner = table.getScanner(scan);
for (Result result : scanner) {
String rowKey = Bytes.toString(result.getRow());
String name = Bytes.toString(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("name")));
String age = Bytes.toString(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("age")));
String gender = Bytes.toString(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("gender")));
String clazz = Bytes.toString(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("clazz")));
System.out.println(rowKey+","+name+","+age+","+gender+","+clazz);
}
table.close();
conn.close();
}
}
4.按前缀 准确值 后缀查找
java
package com.shujia.comparator;
//需求:获取RowKey中包含15001000的所有RowKey
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.filter.*;
import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException;
public class Code04ComparatorRowKey {
public static void main(String[] args) throws IOException {
Configuration conf = new Configuration();
conf.set("hbase.zookeeper.quorum","node1,node2,master");
Connection conn = ConnectionFactory.createConnection(conf);
Table table = conn.getTable(TableName.valueOf("jan:tbl1"));
Scan scan=new Scan();
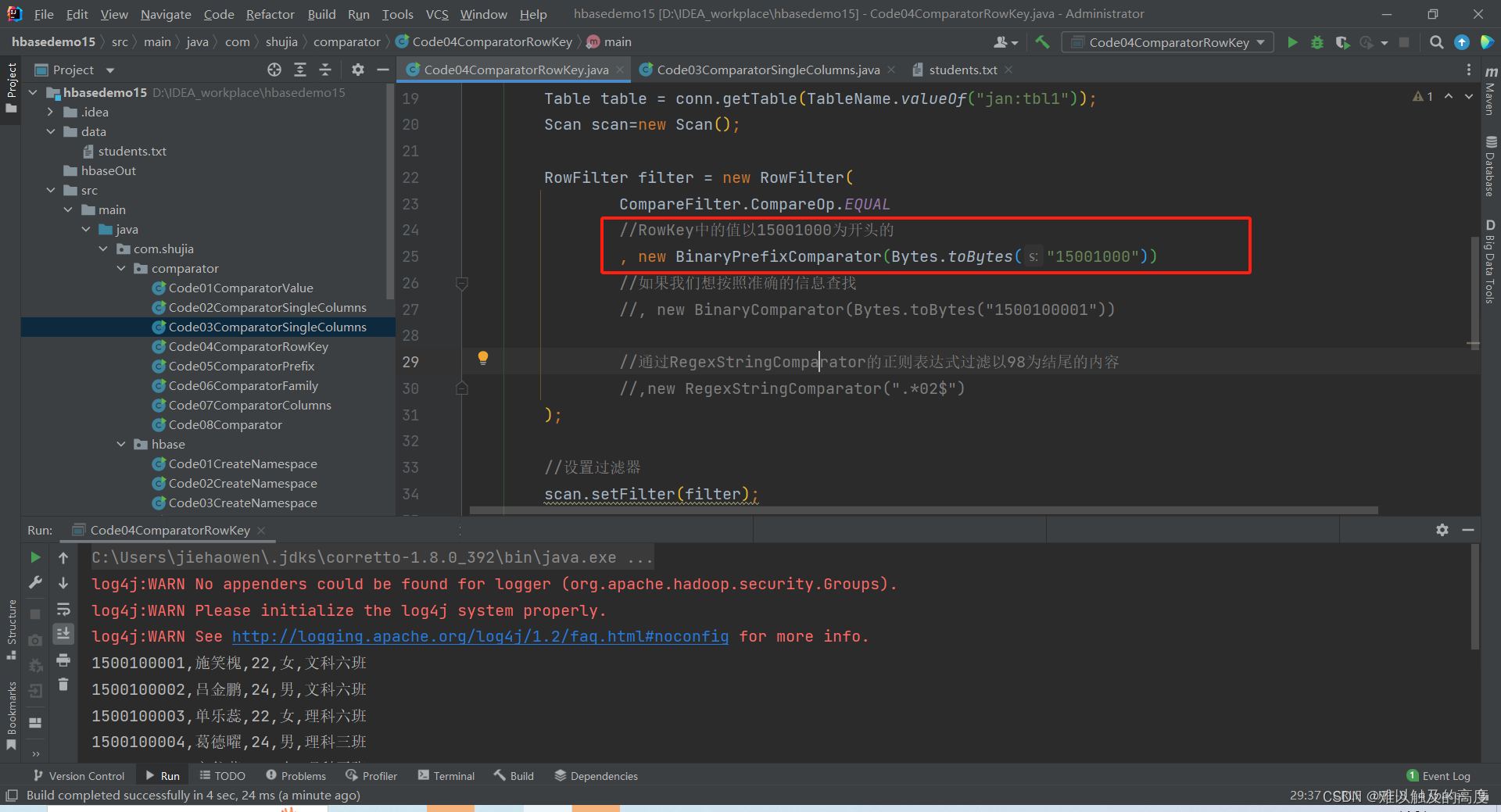
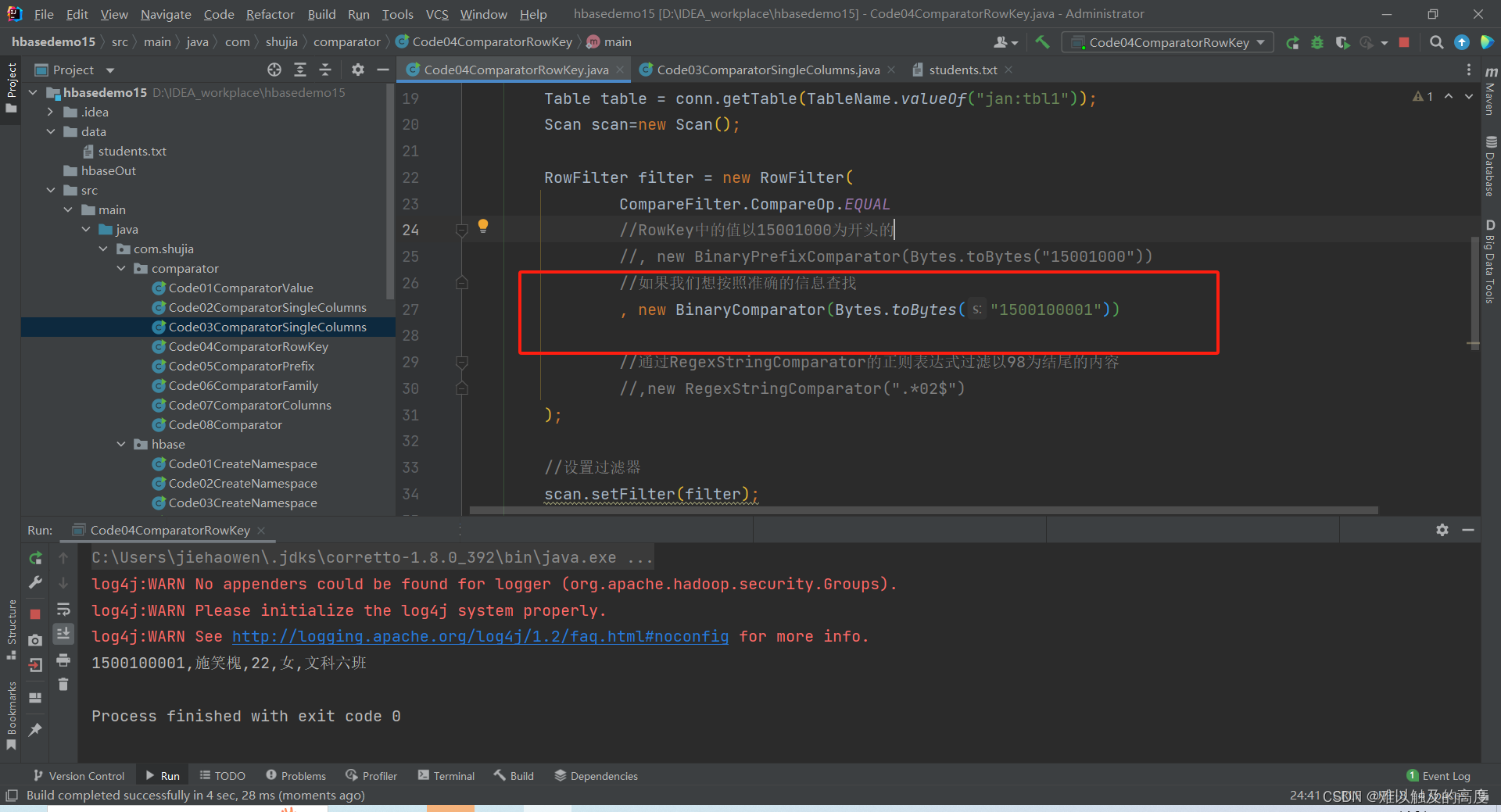
RowFilter filter = new RowFilter(
CompareFilter.CompareOp.EQUAL
//RowKey中的值以15001000为开头的
, new BinaryPrefixComparator(Bytes.toBytes("15001000"))
//如果我们想按照准确的信息查找
//, new BinaryComparator(Bytes.toBytes("1500100001"))
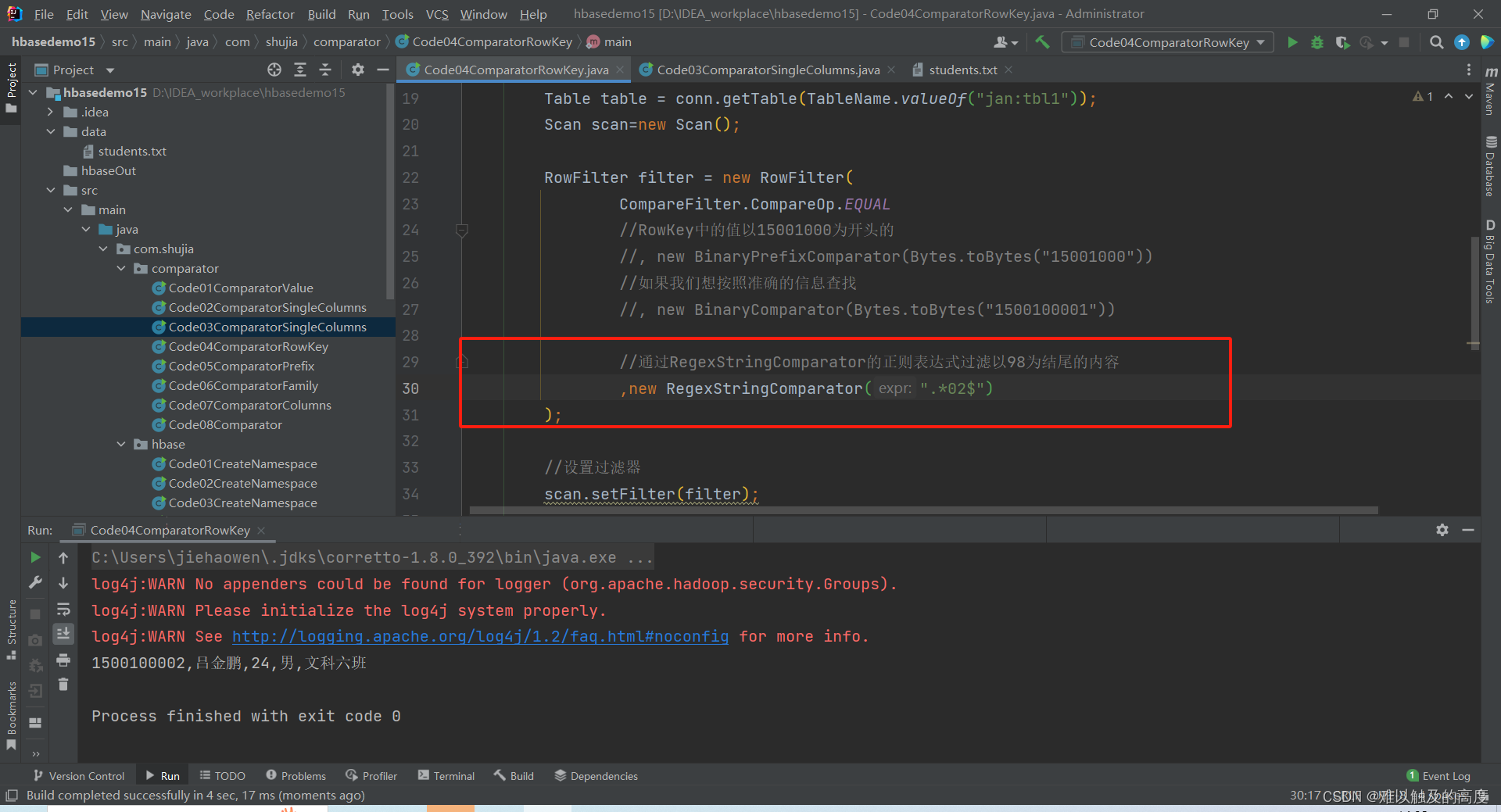
//通过RegexStringComparator的正则表达式过滤以98为结尾的内容
//,new RegexStringComparator(".*02$")
);
//设置过滤器
scan.setFilter(filter);
//获取扫描器对象
ResultScanner scanner = table.getScanner(scan);
for (Result result : scanner) {
String rowKey = Bytes.toString(result.getRow());
String name = Bytes.toString(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("name")));
String age = Bytes.toString(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("age")));
String gender = Bytes.toString(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("gender")));
String clazz = Bytes.toString(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("clazz")));
System.out.println(rowKey+","+name+","+age+","+gender+","+clazz);
}
table.close();
conn.close();
}
}
5.获取RowKey中包含15001000的所有RowKey(速度更快)
java
package com.shujia.comparator;
//需求:获取RowKey中包含15001000的所有RowKey
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.filter.*;
import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException;
public class Code05ComparatorPrefix {
public static void main(String[] args) throws IOException {
Configuration conf = new Configuration();
conf.set("hbase.zookeeper.quorum","node1,node2,master");
Connection conn = ConnectionFactory.createConnection(conf);
Table table = conn.getTable(TableName.valueOf("jan:tbl1"));
Scan scan=new Scan();
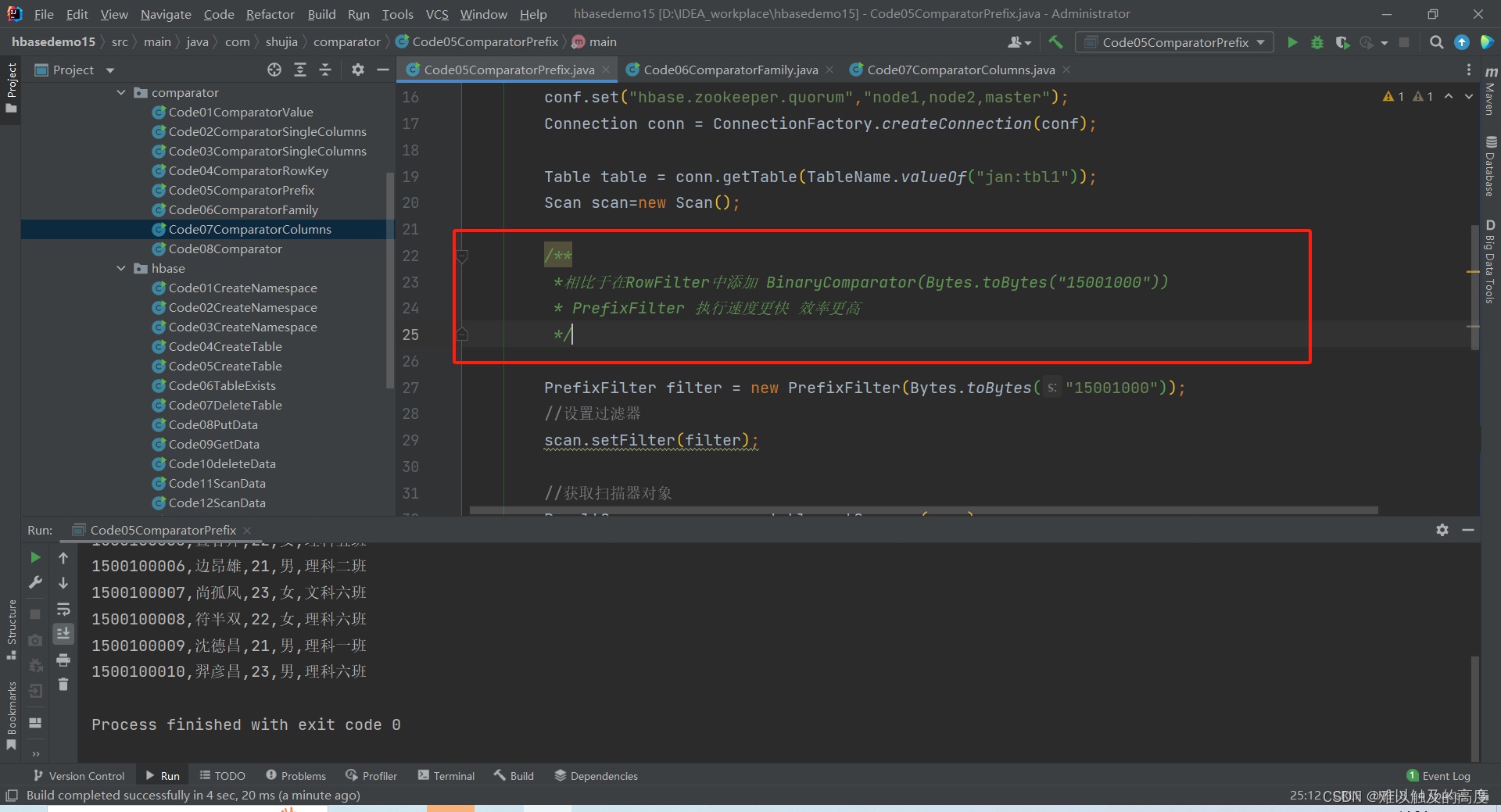
/**
*相比于在RowFilter中添加 BinaryComparator(Bytes.toBytes("15001000"))
* PrefixFilter 执行速度更快 效率更高
*/
PrefixFilter filter = new PrefixFilter(Bytes.toBytes("15001000"));
//设置过滤器
scan.setFilter(filter);
//获取扫描器对象
ResultScanner scanner = table.getScanner(scan);
for (Result result : scanner) {
String rowKey = Bytes.toString(result.getRow());
String name = Bytes.toString(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("name")));
String age = Bytes.toString(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("age")));
String gender = Bytes.toString(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("gender")));
String clazz = Bytes.toString(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("clazz")));
System.out.println(rowKey+","+name+","+age+","+gender+","+clazz);
}
table.close();
conn.close();
}
}
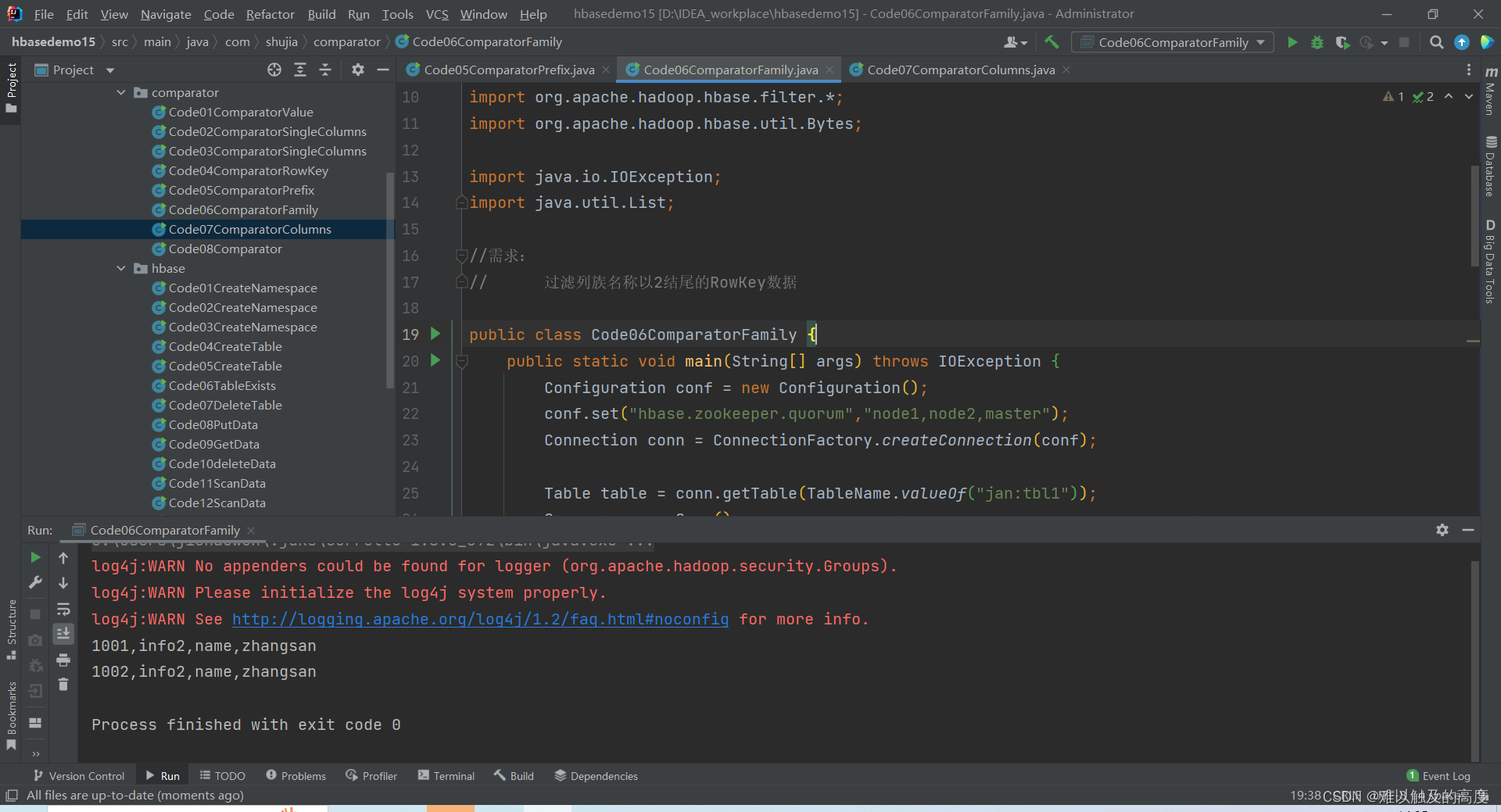
6.过滤列族名称以2结尾的RowKey数据
java
package com.shujia.comparator;
//需求:获取RowKey中包含15001000的所有RowKey
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.filter.*;
import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException;
import java.util.List;
//需求:
// 过滤列族名称以2结尾的RowKey数据
public class Code06ComparatorFamily {
public static void main(String[] args) throws IOException {
Configuration conf = new Configuration();
conf.set("hbase.zookeeper.quorum","node1,node2,master");
Connection conn = ConnectionFactory.createConnection(conf);
Table table = conn.getTable(TableName.valueOf("jan:tbl1"));
Scan scan=new Scan();
FamilyFilter filter = new FamilyFilter(
CompareFilter.CompareOp.EQUAL
, new RegexStringComparator(".*2$")
);
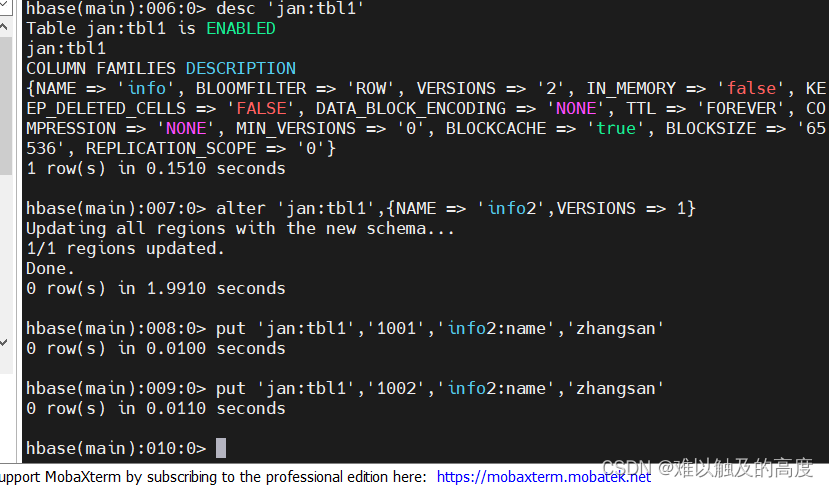
//desc 'jan:tbl1'
//添加列族 alter 'jan:tbl1',{NAME => 'info2',VERSIONS => 1}
//put 'jan:tbl1','1001','info2:name','zhangsan'
//put 'jan:tbl1','1002','info2:name','zhangsan'
//设置过滤器
scan.setFilter(filter);
//获取扫描器对象
ResultScanner scanner = table.getScanner(scan);
for (Result result : scanner) {
List<Cell> cells = result.listCells();
String rowKey = Bytes.toString(result.getRow());
for (Cell cell : cells) {
String family = Bytes.toString(CellUtil.cloneFamily(cell));
String qualifier = Bytes.toString(CellUtil.cloneQualifier(cell));
String value = Bytes.toString(CellUtil.cloneValue(cell));
System.out.println(rowKey+","+family+","+qualifier+","+value);
}
}
table.close();
conn.close();
}
}
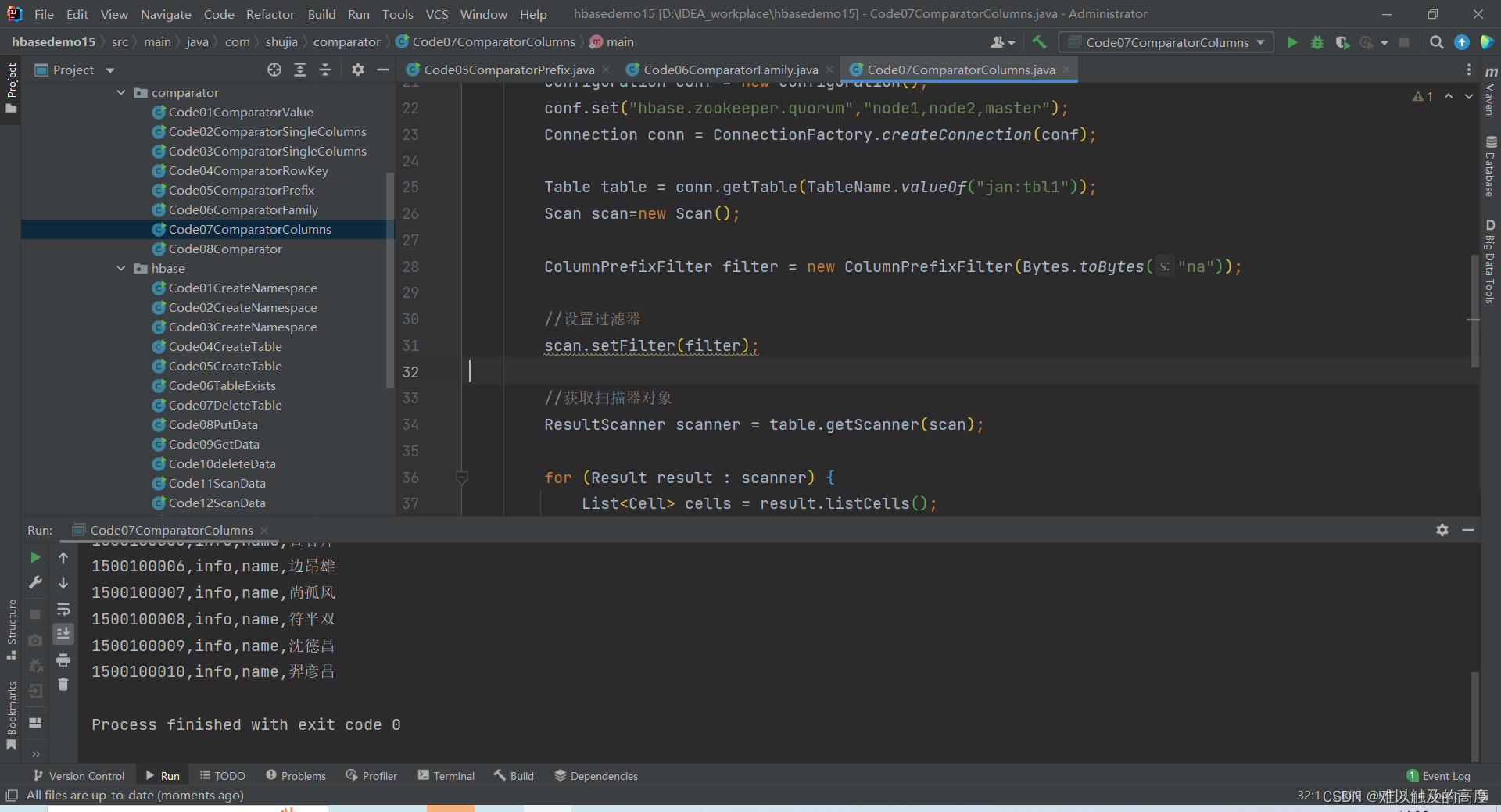
7.获取列名称以 na 开头的所有RowKey
java
package com.shujia.comparator;
//需求:获取RowKey中包含15001000的所有RowKey
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.filter.*;
import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException;
import java.util.List;
//需求:
// 获取列名称以 na 开头的所有RowKey
public class Code07ComparatorColumns {
public static void main(String[] args) throws IOException {
Configuration conf = new Configuration();
conf.set("hbase.zookeeper.quorum","node1,node2,master");
Connection conn = ConnectionFactory.createConnection(conf);
Table table = conn.getTable(TableName.valueOf("jan:tbl1"));
Scan scan=new Scan();
ColumnPrefixFilter filter = new ColumnPrefixFilter(Bytes.toBytes("na"));
//设置过滤器
scan.setFilter(filter);
//获取扫描器对象
ResultScanner scanner = table.getScanner(scan);
for (Result result : scanner) {
List<Cell> cells = result.listCells();
String rowKey = Bytes.toString(result.getRow());
for (Cell cell : cells) {
String family = Bytes.toString(CellUtil.cloneFamily(cell));
String qualifier = Bytes.toString(CellUtil.cloneQualifier(cell));
String value = Bytes.toString(CellUtil.cloneValue(cell));
System.out.println(rowKey+","+family+","+qualifier+","+value);
}
}
table.close();
conn.close();
}
}
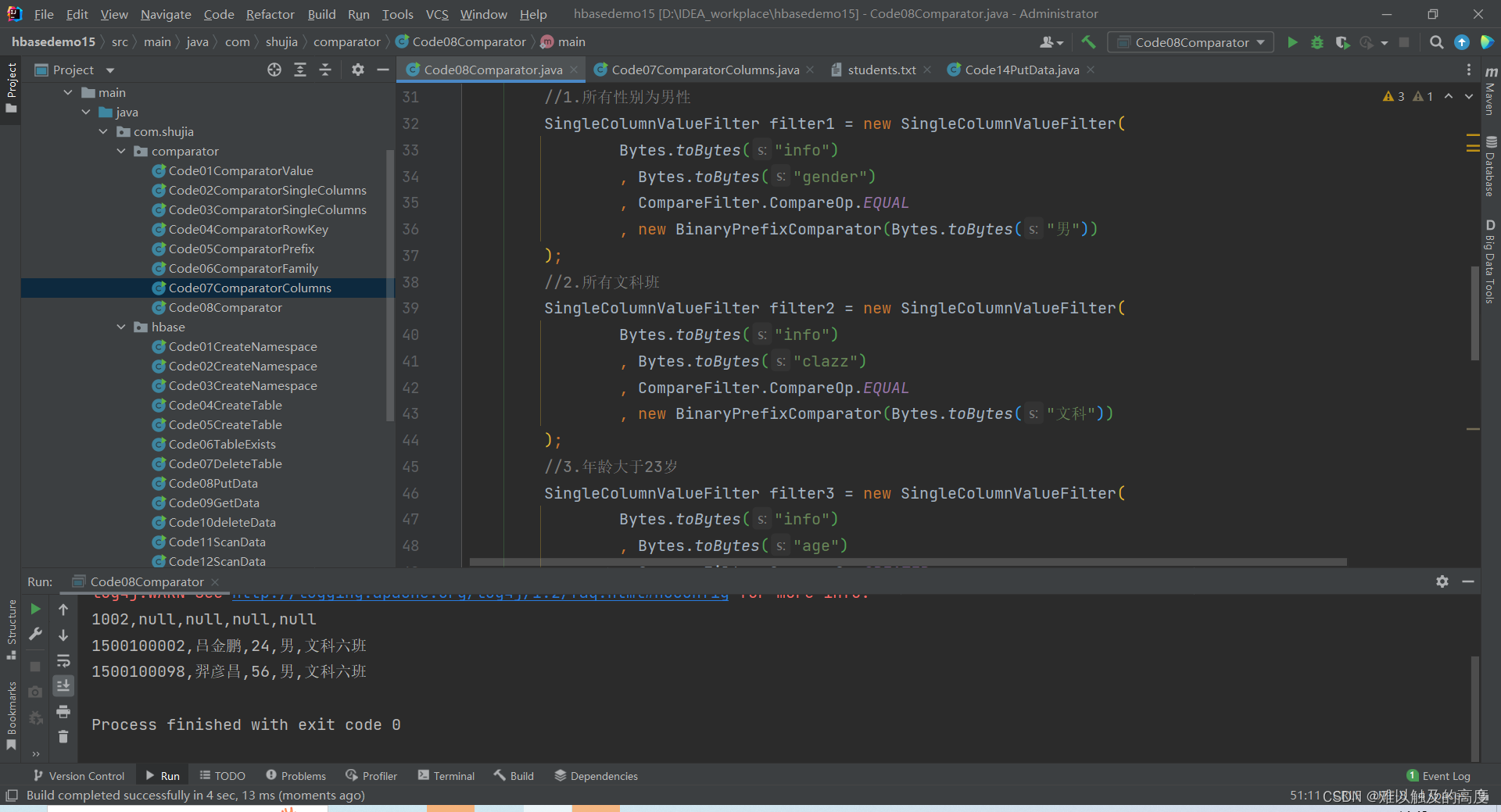
8.对学生表中的信息进行过滤 条件有:1.所有性别为男性 2.所有文科班 3.年龄大于23岁
java
package com.shujia.comparator;
//需求:
// 对学生表中的信息进行过滤 条件有:1.所有性别为男性 2.所有文科班 3.年龄大于23岁
import com.sun.xml.internal.bind.v2.runtime.unmarshaller.XsiNilLoader;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.filter.*;
import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
//需求:
// 获取列名称以 na 开头的所有RowKey
public class Code08Comparator {
public static void main(String[] args) throws IOException {
Configuration conf = new Configuration();
conf.set("hbase.zookeeper.quorum","node1,node2,master");
Connection conn = ConnectionFactory.createConnection(conf);
Table table = conn.getTable(TableName.valueOf("jan:tbl1"));
Scan scan=new Scan();
//1.所有性别为男性
SingleColumnValueFilter filter1 = new SingleColumnValueFilter(
Bytes.toBytes("info")
, Bytes.toBytes("gender")
, CompareFilter.CompareOp.EQUAL
, new BinaryPrefixComparator(Bytes.toBytes("男"))
);
//2.所有文科班
SingleColumnValueFilter filter2 = new SingleColumnValueFilter(
Bytes.toBytes("info")
, Bytes.toBytes("clazz")
, CompareFilter.CompareOp.EQUAL
, new BinaryPrefixComparator(Bytes.toBytes("文科"))
);
//3.年龄大于23岁
SingleColumnValueFilter filter3 = new SingleColumnValueFilter(
Bytes.toBytes("info")
, Bytes.toBytes("age")
, CompareFilter.CompareOp.GREATER
, new BinaryPrefixComparator(Bytes.toBytes("23"))
);
List<Filter> filters = new ArrayList<>();
filters.add(filter1);
filters.add(filter2);
filters.add(filter3);
FilterList filter = new FilterList(filters);
//设置过滤器
scan.setFilter(filter);
//获取扫描器对象
ResultScanner scanner = table.getScanner(scan);
for (Result result : scanner) {
String rowKey = Bytes.toString(result.getRow());
String name = Bytes.toString(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("name")));
String age = Bytes.toString(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("age")));
String gender = Bytes.toString(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("gender")));
String clazz = Bytes.toString(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("clazz")));
System.out.println(rowKey+","+name+","+age+","+gender+","+clazz);
}
table.close();
conn.close();
}
}