1.引入依赖(pox.xml)
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.13.6</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>1.13.6</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.12</artifactId>
<version>1.13.6</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.12</artifactId>
<version>1.13.6</version>
</dependency>
</dependencies>2.创建日志配置文件
把$FLINK_HOME/conf/log4j.properties 内容复制粘贴过来
bash
# This affects logging for both user code and Flink
rootLogger.level = INFO
rootLogger.appenderRef.file.ref = MainAppender
# Uncomment this if you want to _only_ change Flink's logging
#logger.flink.name = org.apache.flink
#logger.flink.level = INFO
# The following lines keep the log level of common libraries/connectors on
# log level INFO. The root logger does not override this. You have to manually
# change the log levels here.
logger.akka.name = akka
logger.akka.level = INFO
logger.kafka.name= org.apache.kafka
logger.kafka.level = INFO
logger.hadoop.name = org.apache.hadoop
logger.hadoop.level = INFO
logger.zookeeper.name = org.apache.zookeeper
logger.zookeeper.level = INFO
logger.shaded_zookeeper.name = org.apache.flink.shaded.zookeeper3
logger.shaded_zookeeper.level = INFO
# Log all infos in the given file
appender.main.name = MainAppender
appender.main.type = RollingFile
appender.main.append = true
appender.main.fileName = ${sys:log.file}
appender.main.filePattern = ${sys:log.file}.%i
appender.main.layout.type = PatternLayout
appender.main.layout.pattern = %d{yyyy-MM-dd HH:mm:ss,SSS} %-5p %-60c %x - %m%n
appender.main.policies.type = Policies
appender.main.policies.size.type = SizeBasedTriggeringPolicy
appender.main.policies.size.size = 100MB
appender.main.policies.startup.type = OnStartupTriggeringPolicy
appender.main.strategy.type = DefaultRolloverStrategy
appender.main.strategy.max = ${env:MAX_LOG_FILE_NUMBER:-10}
# Suppress the irrelevant (wrong) warnings from the Netty channel handler
logger.netty.name = org.apache.flink.shaded.akka.org.jboss.netty.channel.DefaultChannelPipeline
logger.netty.level = OFF3.flink生产者api
java
package com.ljr.flink;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import java.util.ArrayList;
import java.util.Properties;
public class MyFlinkKafkaProducer {
//输入main tab 键 即创建入main 方法
public static void main(String[] args) throws Exception {
//1.获取环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//设置的槽数与分区相等
env.setParallelism(3);
//2.准备数据源
ArrayList<String> wordlist = new ArrayList<>();
wordlist.add("zhangsan");
wordlist.add("lisi");
DataStreamSource<String> stream = env.fromCollection(wordlist);
//创建kafka生产者
Properties pros = new Properties();
pros.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"node1:9092,node2:9092");
FlinkKafkaProducer kafkaProducer = new FlinkKafkaProducer("customers", new SimpleStringSchema(), pros);
//3.添加数据源
stream.addSink(kafkaProducer);
//4.执行代码
env.execute();
}
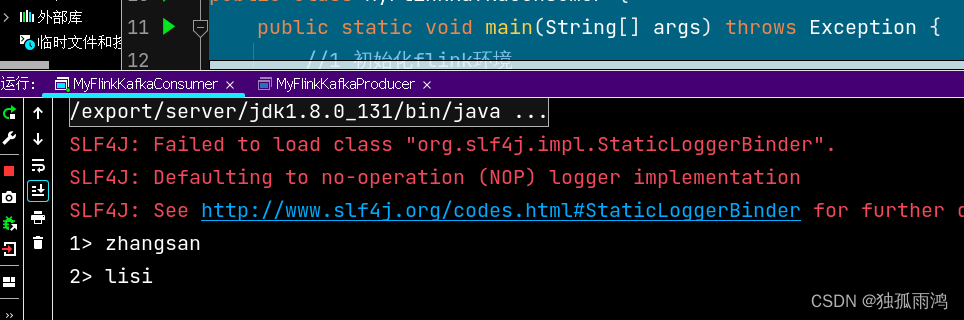
}运行;kafka消费者消费结果

4.flink消费者api
java
package com.ljr.flink;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import java.util.Properties;
public class MyFlinkKafkaConsumer {
public static void main(String[] args) throws Exception {
//1 初始化flink环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(3);
//2 创建消费者
Properties pros = new Properties();
pros.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"node1:9092,node2:9092");
//pros.put(ConsumerConfig.GROUP_ID_CONFIG,"hh")
FlinkKafkaConsumer<String> flinkKafkaConsumer = new FlinkKafkaConsumer<>("customers", new SimpleStringSchema(), pros);
//3 关联消费者和flink流
env.addSource(flinkKafkaConsumer).print();
//4 执行
env.execute();
}
}运行,用3中的生产者生产数据,消费结果