背景
Clickhouse集群版本为 Github Clickhouse 22.3.5.5, clickhouse-jdbc 版本为 0.2.4。
问题表现
随着业务需求的扩展,基于Clickhouse 需要支持更多任务在期望的时效内完成,于是将业务系统和Clickhouse交互的部分都提交给可动态调整核心参数的线程池去执行,尽量可控的利用Clickhouse集群的计算资源。
然后一测试就出现了高频的异常:ru.yandex.clickhouse.except.ClickHouseUnknownException: ClickHouse exception, code: 1002, host: 192.168.1.1, port: 8123; 192.168.1.1:8123 failed to respond
搜索发现有比较多类似问题
- clickhouse分析:clickhouse jdbc返回failed to respond问题排查
- Retry for NoHttpResponseException
- Issue with driver not honoring the server keep-alive timeout settings
解决经历
首先问题就指向了驱动版本, 社区在0.2.5优化了这个问题, 那就只能升级驱动版本了, 由于这个项目也是接手的,通常来说遇到性能问题,不会第一时间考虑升级依赖版本除非找到确认的依据是版本有缺陷,因为风险不可控.
但是社区还有类似问题反馈,BatchUpdateException during inserts with jdbc driver 于是直接跨多个版本升到了0.6.0
升级后使用线程池跑确实就不会出现高频的报错了,但是仍偶现有1002报错,当时加了重试逻辑,赶业务进度,测试后就上线了,但是遇到了一个不大不小的坑: Druid管理的JDBC Connection 在调用getConnection().getSchema(); 时,0.2.4版本的驱动正常返回了连接所在的数据库名,但是0.6.0返回了null,导致部分业务场景出错了,只好紧急修复了。
过了一段时间,业务又发生了扩展,要跑的任务更多了,每到高频的跑任务时,就可能会看到告警群会来几条1002的报错告警。然后开始新一轮找问题了
BatchUpdateException during inserts with jdbc driver
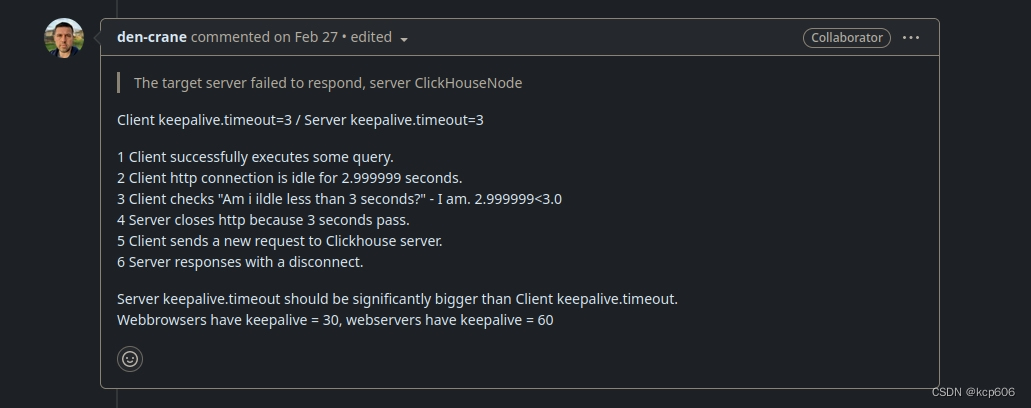 由于升级驱动到0.6.0时也调整了JDBC的参数, 那时只看到了客户端的值远大于服务端的值,就只想着尽量复用连接少建立连接的开销
由于升级驱动到0.6.0时也调整了JDBC的参数, 那时只看到了客户端的值远大于服务端的值,就只想着尽量复用连接少建立连接的开销实际上不是重点,就把客户端设置为了和服务端的 tcp_keep_alive_timeout保持一致为 290s,注意默认值是3s 部署时调整了参数 。
按这个场景来说,当客户端的一个连接到了超时的边界值时,考虑到网络延迟的开销,客户端会认为是有效的,但是服务端认为超时了,就会关闭连接, 就又会抛出1002了,如果SQL的提交是低频的就不容易出现这个情况,当有多个线程并发跑1小时以上时概率就大大增加了。
通过这个PR Validate stale connection to fix the bug: failed to respond 同时发现了项目内没有设置合理的检查连接活跃性的配置。
综上,将客户端超时调整为140s,并设置客户端检查连接策略和sql 通常默认是 select 1.
目前1002问题尚未出现