十一 分布式爬虫爬虫原理
一个分布式爬虫,是需要有一个或多个发任务的程序,提取将来需要的任务,主要指的就是任务链接,存到任务队列(redis数据库中),还需要多个执行任务的程序,从任务队列(redis数据库)中,提取任务执行解析,然后把提取的数据,统一存储到特定的数据库。
十二 scrapy与scrapy-redis的区别
1.sheduler调度器方面
scrapy请求的处理在调度器中进行,scrapy-redis将数据放到redis数据库队列处理
- duplication Filter重复过滤器方面
scrapy请求指纹哈希处理,在python的set集合中处理,scrapy-redis在redis中set去重
- spider爬虫方面
scrapy的url 在本地,scrapy-redis可以从redis中获取url

十三 scrapy如何进行异常链接捕捉
使用下载中间件的process_response/peocess_exception预定义函数,该函数有异常和应答对象信息,获取错误信息,存储到redis或者mongodb数据库中,将来使用requests或者scrapy把之前出错的链接,在此进行访问。
十四 scrapy中如何处理异常状态码?
scrapy.downloadermiddlewares.retry.RetryMiddleware 会判断是否请求进入重试的逻辑
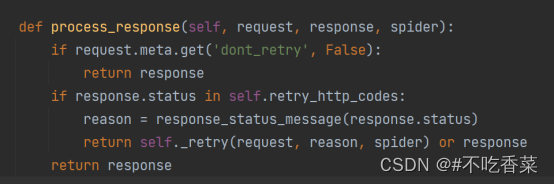
在scrapy的下载中间件中有一个预定义的中间件RetryMiddlewar,这个中间件在process_response方法中定义了如何处理异常状态码
1,首先判断meta里面有没有dont_retry特殊键,如果有且值为True的话,会忽略异常的状态码
2, 然后判断状态码是否在retry_http_codes里(RETRY_HTTP_CODE = 500, 502, 503 , 504, 522, 524, 408, 429), 如果在这个列表进行请求重试,如果不在,忽略重试,程序继续response对象。
scrapy.spidermiddlewares.httperror.HttpErrorMiddleware 会判断是否忽略错误的状态码
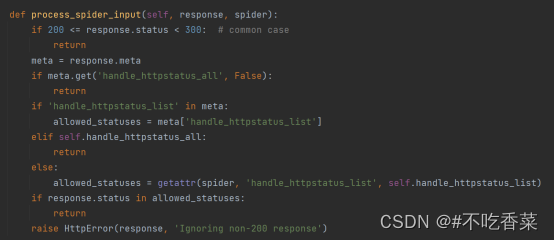
在scrapy的爬虫中间件中有一个预定义的中间件HTTPErrorMiddleware,这个中间件在process_spider_input方法中定义了如何处理异常状态码
1,首先判断状态码是不是在200~300之间,如果是的话,说明没有问题,程序继续处理应答。
2 , 然后使用meta中的handle_httpstatus_all和handle_httpstatus_list两个特殊键,进行判断,如果handle_httpstatus_all = true 或者 handle_httpstatus_list包含要处理的非200的状态码,程序继续处理应答。
3, 在判断spider对象有没有handle_httpstatus_list属性,如果有,判断非200状态码是否包含在这个列表,如果包含程序继续处理应答。
4,如果前面三个条件都不满足,则抛出HTTPError异常,显示忽略非200应答
十五 数据如何去重
数据使用哈希算法进行处理,把哈希值存入redis的set集合进行去重
如果有些网站的数据字段有类似数据库主键的数据,可以直接使用这个主键当做标识,利用set集合的特性进行去重。
也可以直接全部先存入数据库,执行完毕再读出来统一做一次去重
十六 什么是线程和进程/进程线程协程的区别
1,进程是操作系统资源分配的基本单位,而进程是任务调度和执行的基本单位。
2, 每个进程都有独立的代码和数据空间,同一类线程共享代码和数据空间
3, 在操作系统中能够同时运行多个进程(程序);而在同一的进程(程序)中有多个线程同时执行。
使用场景:多进程适合计算密集型任务, 多线程适合IO密集型任务
优缺点:
线程和进程在使用上各有各的优缺点,线程执行开销小,但不利于资源的管理和保护,而进程正相反。
进程:一个程序在操作系统汇中被执行以后就会创建一个进程,通过进程分配资源(cpu , 内存, I/O设备), 一个进程中会包含一到多个线程,其中有一个线程叫做主线程用于管理其他线程。一个正在运行的程序可以看做一个进程,进程拥有独立运行所需要的全部资源。(例如打开qq相当于开启一个进程)
线程:程序中独立运行的代码段。在一个进程执行的过程,一般会分为很多小的执行单位。线程就是这些执行单位;在处理机调度,以线程为单位,多个线程之间并发执行,线程占用的是CPu
一个程序至少拥有一个进程,一个进程至少拥有一个线程。进程负责资源的调度和分配,线程才是真正的执行单元,负责代码的执行。
协程,又称微线程或者叫做可暂停的函数
最大的优势就是协程极高的执行效率。因为子程序切换不是线程切换,而是由程序自身控制,因此,没有线程切换的开销,和多线程比,协程数量越多,协程的性能优势就越明显。
第二大优势就是不需要多线程的锁机制,因为只有一个线程,也不存在写变量冲突,在协程中控制共享资源不加锁,只需要判断状态就好了,所以执行效率比多线程高很多。
if 的效率 远大于 互斥锁lock的效率
十七 爬虫使用所线程好?还是多进程好?为什么
对于I/O密集型代码(文件处理,网络爬虫), 多线程能够有效的提升效率(单线程下有IO操作会进行IO等待,会造成不必要的时间等待,而开启多线程后, A线程等待时,会自动切换到线程B.可以不浪费CPU的资源,从而提升程序的执行效率)
十八 GIL是什么
GIL的全称是Global Interpreter Lock(全局解释锁), 来源是python设计之初的考虑,为了数据安全所做出的决定。
每个CPU在同一时间只能 执行一个线程,在单核CPU下多线程其实都只是并发,不是并行,并发和并行从宏观上来讲都是同时处理多路请求的概念。但并发和并行又有区别,并行是指两个或者多个事件在同一时刻发生;而并行是指两个或多个事件在同一时间间隔内发生
在python多线程下,每个线程的执行方式:
1,获取GIL
2, 执行代码知道sleep或者是python虚拟机将其挂起。
3, 释放GIL
可见,某个线程想要执行,必须先拿到GIL,我们可以吧GIL看做是"通行证",并且在一个python进程中,GIL只有一个,那不到通行证的线程,就不允许进入CPU执行
十九 模拟登录原理? Cookie的作用?
因为http请求是无状态的,网站为了识别用户身份,需要通过cookie记录用户信息(用户,密码)那么在爬虫的时候只需要将这些信息添加在请求头里即可
也可以使用selenium模拟表单填写,验证码处理,模拟登录,登录之后就可以
二十 列举爬虫都用过哪些工具模块
网络请求:request aiohttp
网页解析:ajax/json, lxml与xpath, bs4与css选择器, re 正则表达式
web自动化测试工具:selenium
分词: jieba, nlp(自验语言处理)
app抓包工具: fiddler. mitmproxy
app自动化测试工具: airtest
爬虫框架: scrapy
分布式爬虫框架: scrapy-redis
定时调度端架: apsheduler
爬虫加速: 多线程 多进程 异步协程
图片识别工具: OCR
独立的js环境: nodejs
加密: hash(md5, sha1) , 对称加密(AES, DES, 3DES), 非对称加密(RSA, ECC, DSA)
数据库操作: pymongo,redis, pymysql, sql, nosql, csv, clwt