
GPT-4o:大模型风向,OpenAI大更新
****
OpenAI震撼发布两大更新!桌面版APP与全新UI的ChatGPT上线,简化用户操作,体验更自然。同时,全能模型GPT-4o惊艳亮相,跨模态即时响应,性能卓越且性价比飙升。相较于GPT-4 Turbo,GPT-4o不仅性能卓越,更向用户免费开放,引领大模型新风向。不容错过,立即体验OpenAI的最新科技成果!
1. 桌面版及新 UI ChatGPT
ChatGPT 发布桌面版 APP,支持与计算机语音对话,提升用户与模型交互体验。对于免费和付费用户,OpenAI 推出了适用于 macOS 的新 ChatGPT 桌面应用程序,该应用程序旨在无缝集成到用户的计算机上执行的任何操作。通过简单的键盘快捷键(Option + Space),用户便可向 ChatGPT 提问,并支持直接在应用程序中截取屏幕截图进行讨论。与此同时,ChatGPT 支持与计算机直接语音对话,并在未来将推出新音频和视频功能。
OpenAI率先为Plus用户推出macOS应用程序,并计划在未来数周内全面上线,预计2024年晚些时候还将推出Windows版本,为用户提供更多选择。
OpenAI全面革新UI界面,以更友好、对话性的设计,增强用户与平台的自然互动,简化操作流程,提升用户体验。
2. GPT-4o 实现毫秒级视觉音频理解
GPT-4o,OpenAI新旗舰,兼具GPT-4强大模型能力与卓越推理速度,更拥有多模态处理文本、图像、音频的创新功能。发布会亮点纷呈,为您揭示AI新时代的无限可能。
GPT-4o引领人机交互新纪元,实现毫秒级响应,即时语音对话。它兼容文本、音频、图像多元输入,并灵活输出,全面升级交流体验。相较于GPT-3.5的2.8s和GPT-4的5.4s延迟,GPT-4o音频响应最短至232毫秒,平均仅320毫秒,媲美人类对话速度。这一革命性突破,极大地提升了人机交流的自然度和效率,开启了人机交互的新篇章。
GPT-4o彰显卓越视觉与音频理解力,实时感知语气语态。用户可随时打断对话,模型则能灵活生成多音调回复,富含人类情感。通过与AI视频通话,即时解答疑问,体验前所未有的智能交互。
GPT-4o API的性价比显著跃升,其速度翻倍,成本减半,同时速率限制提升5倍,相较于GPT-4 Turbo,展现出卓越的性能与价值。
3. 端到端多模态 GPT-4o,刷新 SOTA 性能飞跃
传统语音 AI 通常经过三步法实现对话功能,在这过程中会丢失很多信息且不能判断情绪变化。三步法具体为:1)语音识别或 ASR:音频到文本,类似 Whisper;2)LLM 计划下一步要说什么:文本 1 到文本 2;3)语音合成或 TTS:文本 2 到音频,类似 ElevenLabs 或 VALL-E。GPT-4 便采用该模式,在这过程中不仅响应速度更慢而且丢失了大量信息,无法直接观察语调、多个说话者或背景噪音,也无法输出笑声、歌唱或表达情感等。
GPT-4o,跨模态端到端新模型,实现多模态统一,性能飞跃。其响应迅捷,于文本、推理、编码智能方面均达GPT-4 Turbo水平,更在多语言、音频、视觉功能上刷新记录。GPT-4o,真正的多模态统一模型,引领智能技术新篇章。
GPT-4o在文本推理领域再创新高!在0-shot COT MMLU测试中,它斩获了88.7%的卓越成绩;在5-shot no-CoT MMLU测试中,也达到了87.2%的高分。相较于GPT-4 Turbo,GPT-4o的文本推理能力得到了显著增强,展现了其强大的语言理解和分析能力。

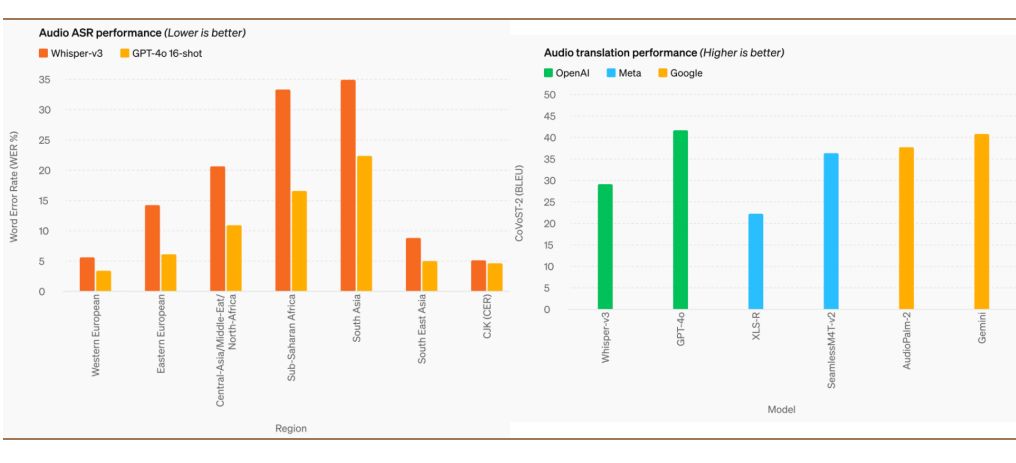
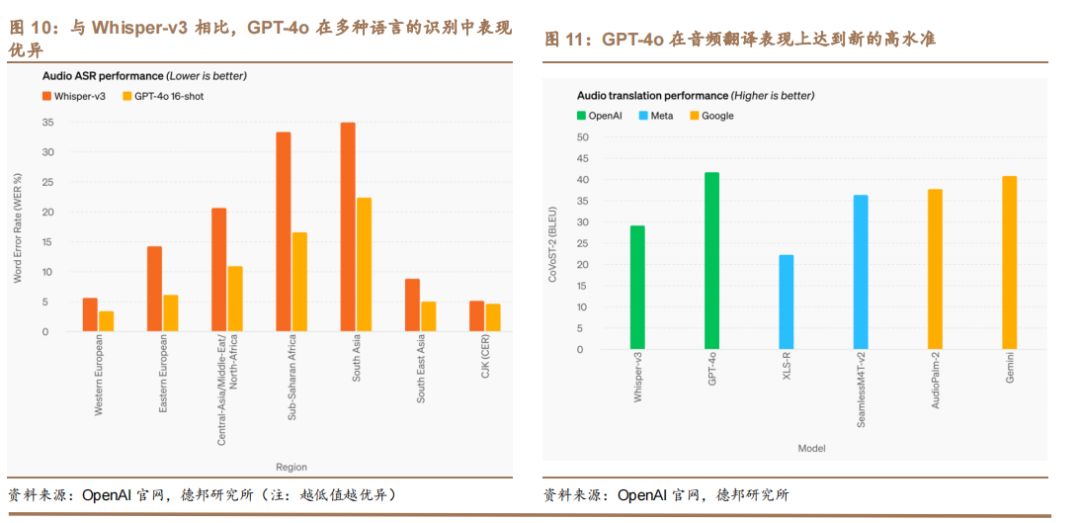
GPT-4o在多语言识别上卓越于Whisper-v3,尤其在资源匮乏语言上表现优异,展现出色的跨语言识别能力。
GPT-4o在音频翻译上表现卓越,达到新高度,MLS基准测试成绩超越Whisper-v3,展现强大实力。
M3Exam测试涵盖多语言与视觉评估,结合多国标准化测试的多选题与图形图表。在各类语言基准测试中,GPT-4o表现超越GPT-4,凸显其卓越性能。
GPT-4o在视觉感知领域大放异彩,其性能在基准测试中达到了顶尖水平。MMMU测试结果显示,GPT-4o以69.1的高分领跑,远超GPT-4 Turbo的63.1分,以及Gemini 1.0 Ultra、Gemini 1.5 Pro和Claude Opus的59.4分和58.5分。这一突破性的表现,再次彰显了GPT-4o在视觉理解领域的卓越实力。
GPT-4o在端到端多模态架构的加持下,其多模态能力得以显著增强。不仅涵盖文本、图像等经典功能,更拓展至3D物品合成、文本转字体等创新领域,功能多样且强大。
****
-对此,您有什么看法见解?-
-欢迎在评论区留言探讨和分享。-