一、OrangePi AIpro介绍
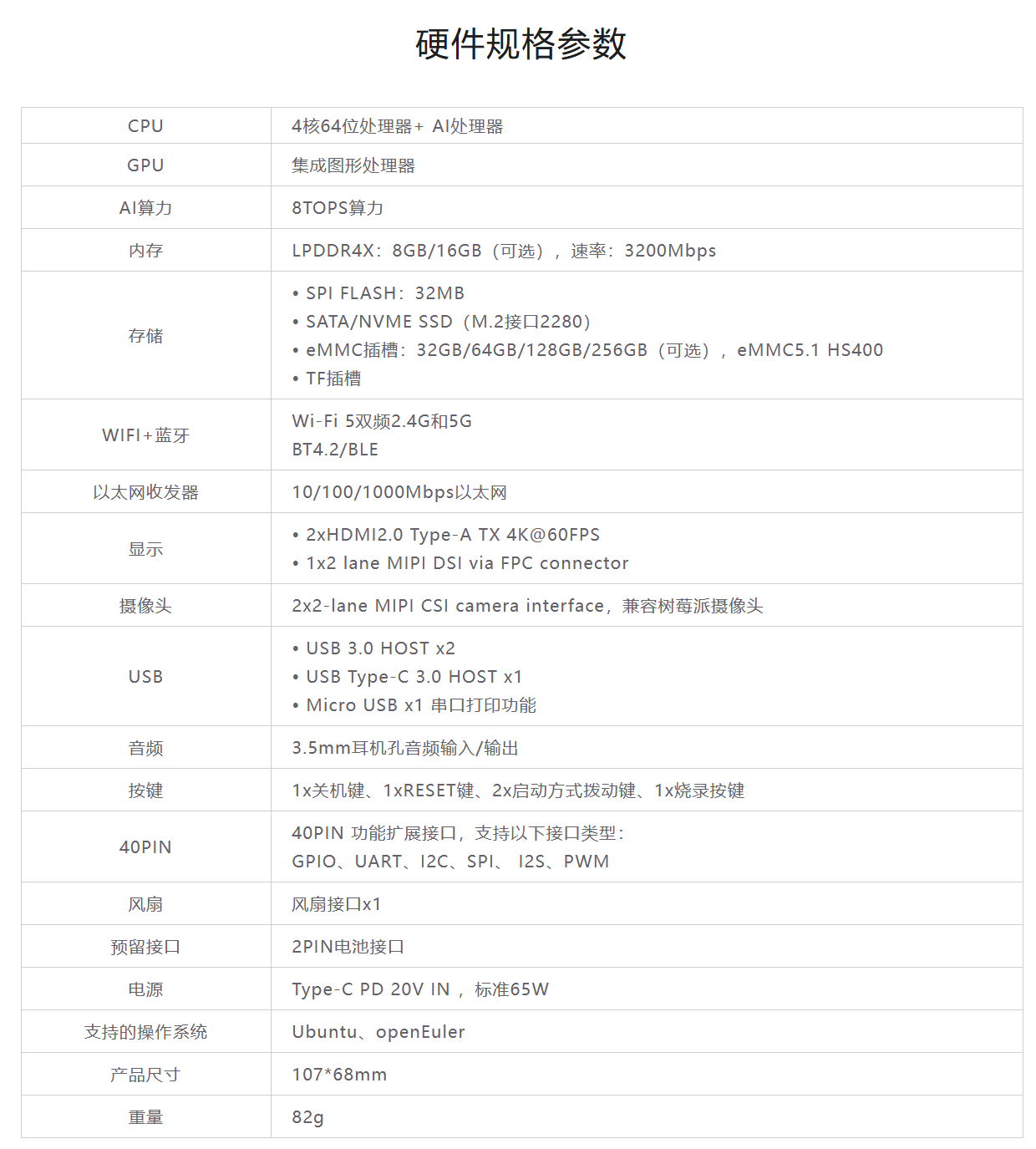
OrangePi AIpro(8T)采用昇腾AI技术路线,具体为4核64位处理器+AI处理器,集成图形处理器,支持8TOPS AI算力,拥有8GB/16GB LPDDR4X,可以外接32GB/64GB/128GB/256GB eMMC模块,支持双4K高清输出。 Orange Pi AIpro引用了相当丰富的接口,包括两个HDMI输出、GPIO接口、Type-C电源接口、支持SATA/NVMe SSD 2280的M.2插槽、TF插槽、千兆网口、两个USB3.0、一个USB Type-C 3.0、一个Micro USB(串口打印调试功能)、两个MIPI摄像头、一个MIPI屏等,预留电池接口,可广泛适用于AI边缘计算、深度视觉学习及视频流AI分析、视频图像分析、自然语言处理、智能小车、机械臂、人工智能、无人机、云计算、AR/VR、智能安防、智能家居等领域,覆盖 AIoT各个行业。 Orange Pi AIpro支持Ubuntu、openEuler操作系统,满足大多数AI算法原型验证、推理应用开发的需求。
应用场景广泛,可广泛适用于AI教学实训、AI算法验证、智能小车、机械臂、边缘计算、无人机、人工智能、云计算、AR/VR、智能安防、智能家居、智能交通等领域。
产品详细图如下:
正面:

背面:

二、 基础功能测试
收的OrangePi AIpro套装里面只有开发板、充电器、内存卡,为了方便测试,自己额外配置了显示器、鼠标、键盘、USB摄像头,下图是完整搭建好的实物图。
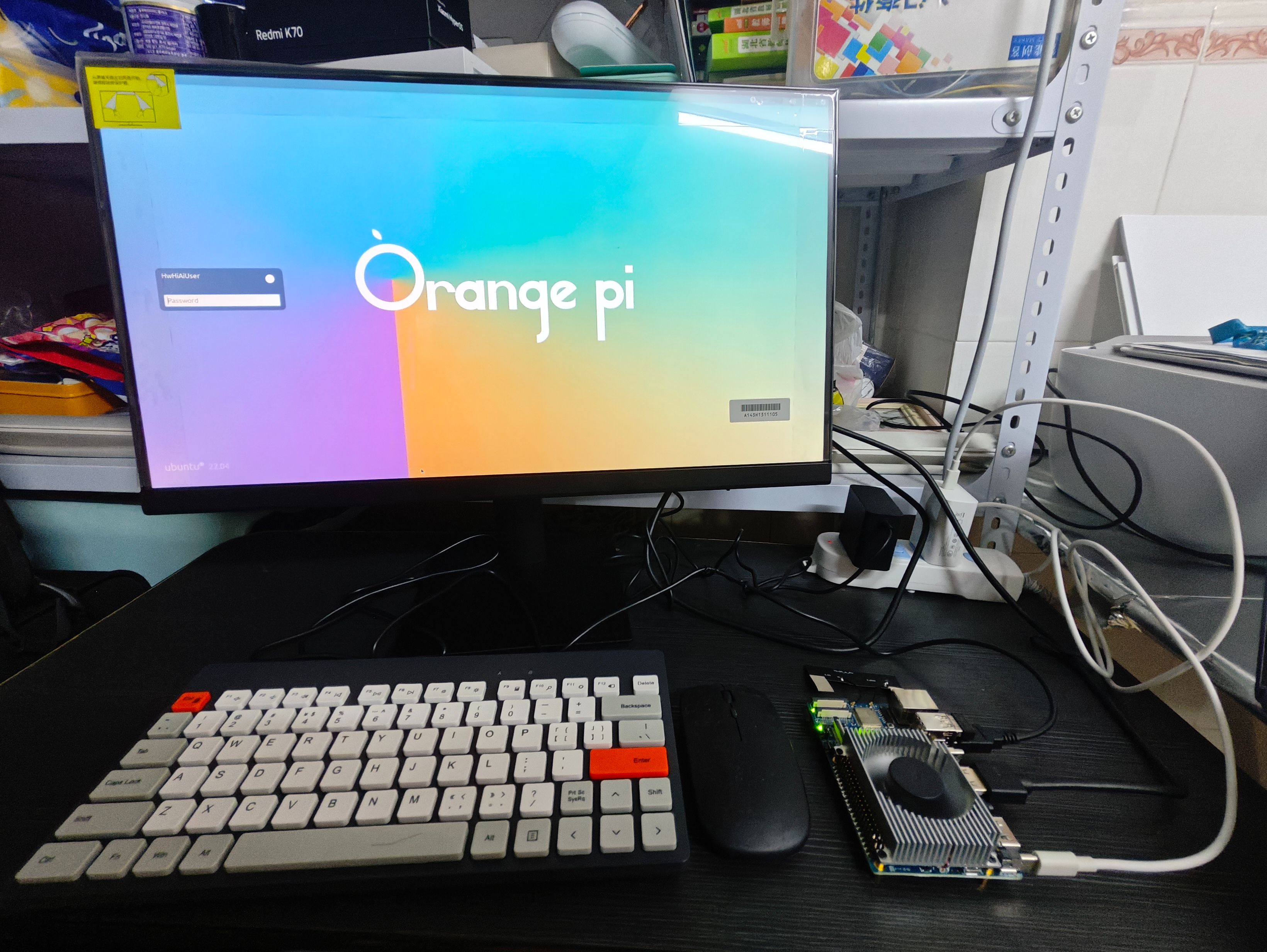
1、开机:充电器要插入PWR标识的接口,显示器要插到HDMI0接口(另一个插入不生效),键盘鼠标插入USB接口,连接标识图如下:

2、登录:开机之后会进入一个ubuntu22.04的系统登录界面,默认用户名HwHiAiUser,输入密码Mind@123,进入桌面。
3、网络连接测试:桌面右上角连接wifi,输入密码。然后打开终端输入ping www.orangepi.cn,能ping通说明wifi连接正常。

4、蓝牙测试:桌面右上角连接蓝牙,经过测试发现,支持与手机蓝牙连接并成功发送一个文件,但不支持与笔记本蓝牙连接。
5、VNC远程连接测试:
开发板上默认已经安装好tightvncserver,只需要本地安装一个VNC客户端,下载https://www.realvnc.com/en/connect/download/viewer/
新建一个连接,输入ip+端口(5901),输入用户名,连接时输入密码。
本人也尝试了window自带的远程桌面工具没有成功。

成功连接

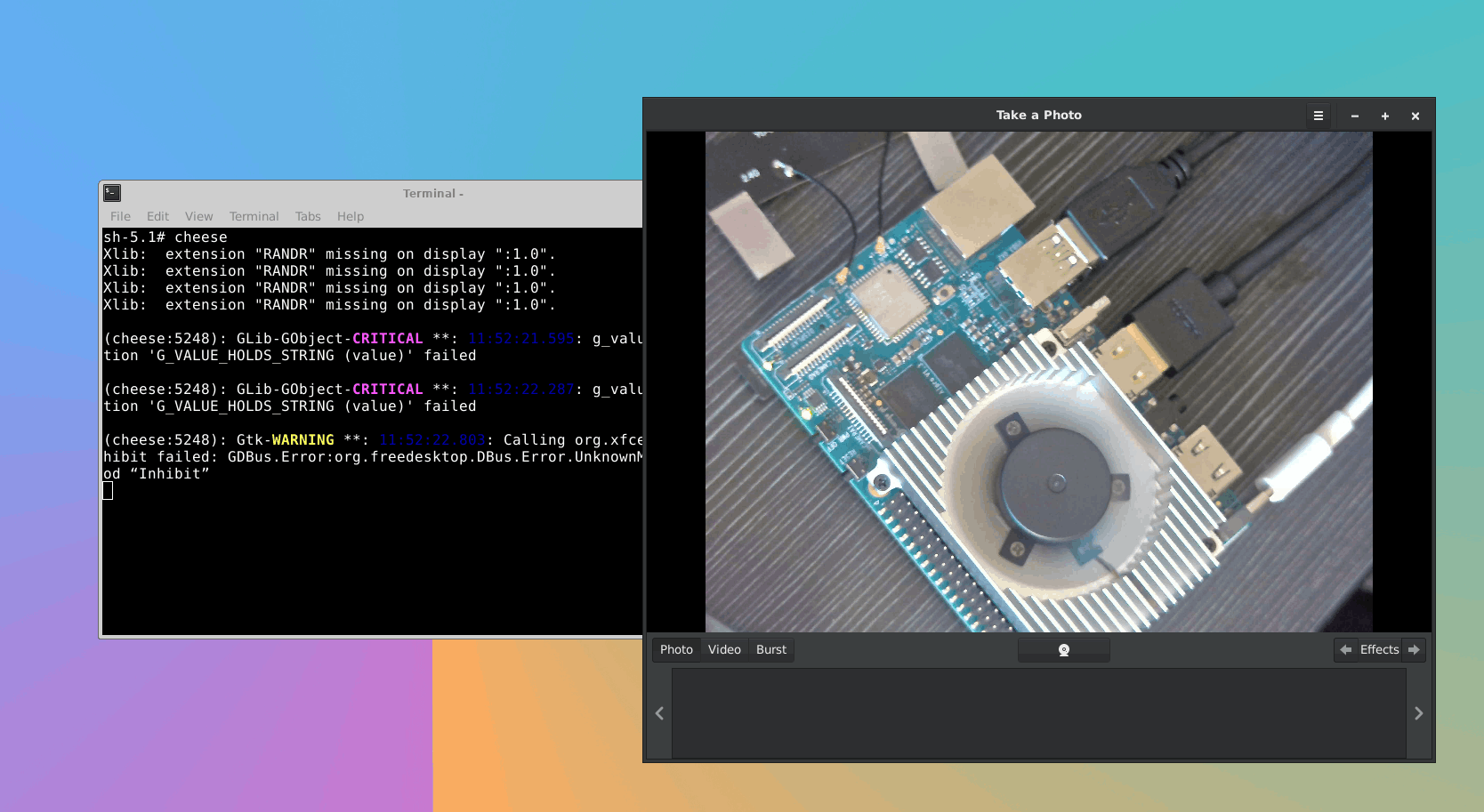
6、USB摄像头测试:
选用了USB500万工业相机,输出格式为MJPJ/YUY2。

插入USB摄像头,终端输入cheese,出现相机画面。
三、体验AI应用案例
3.1启动
进入目录
bash
cd ~/samples/notebooks执行sh脚本启动,局域网内的其他设备访问可以加IP地址
bash
./start_notebook.sh 192.168.31.111浏览器输入ip:port即可访问 ,http://192.168.31.111:8888/

3.2 样例说明
|-------------------------------------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 目录 | 样例介绍 |
| 01-yolov5 | YOLOv5是一种单阶段目标检测算法,在这个样例中,我们选取了YOLOv5s,它是YOLOv5系列中较为轻量的网络,适合在边缘设备部署,进行实时目标检测。 |
| 02-ocr | 传统定义的Optical Character Recognition(光学字符识别)主要完成文档扫描类的工作。 如今,OCR一般指Scene Text Recognition (场景文字识别),主要面向自然场景。 OCR两阶段方法一般包含两个模型,检测模型负责找出图像或视频中的文字位置,识别模型负责将图像信息转换为文本信息。 此样例中,我们使用的检测模型为CTPN,识别模型则是SVTR。 CTPN模型基于Faster RCNN模型修改而来,而SVTR则基于近几年十分流行的Vision Transformer模型。 |
| 03-resnet | ResNet是最经典的视觉分类网络之一,在这个样例中我们选取了ResNet50,也是ResNet最常用的变体。 |
| 04-image-HDR-enhance | 功能介绍:使用模型对曝光不足的输入图片进行HDR效果增强。 样例输入:png图像。 样例输出:增强后png图像 |
| 05-cartoonGAN_picture | 功能:使用cartoonGAN模型对输入图片进行卡通化处理。 样例输入:原始图片jpg文件。 样例输出:卡通图象。 |
| 06-human_protein_map_classification | 功能:对蛋白质图像进行自动化分类评估 样例输入:未标注的蛋白质荧光显微图片 样例输出:已经标注分类的蛋白质图谱 |
| 07-Unet++ | 功能:对图像中的细胞核进行分割 样例输入:未标注的生物细胞图像 样例输出:已经分割的细胞核图像 |
| 08-portrait_pictures | 目前工业界通用的人像分割主要采用绿屏技术,需要专门的绿屏设备及环境,不利于普通用户的广泛使用。在这个样例中,我们使用了一个深度学习神经网络PortraitNet,能够实时地进行人像分割和背景替换。 |
| 09-speech-recognition | 自动语音识别,即ASR,指借助计算机将语音转换为文本。在这个样例中,我们使用了基于深度学习的语音识别模型WeNet,借助我们的昇腾Atlas 200I DK A2,可以进行高性能推理。 |
3.3 yolov5样例
运行yolov5样例,打开main.ipynb文件
选择推理模式。"infer_mode"有三个取值:image, camera, video,分别对应图片推理、摄像头实时推理和视频推理。前面已经测试USB相机ok,这里就选择摄像头实时推理。
python
infer_mode = 'camera' //这里选择摄像头实时推理
if infer_mode == 'image':
img_path = 'world_cup.jpg'
infer_image(img_path, model, labels_dict, cfg)
elif infer_mode == 'camera':
infer_camera(model, labels_dict, cfg)
elif infer_mode == 'video':
video_path = 'racing.mp4'
infer_video(video_path, model, labels_dict, cfg)识别效果如下:能够正确识别剪刀scissors和键盘keyboard

再修改infer_camera函数,打印下推理时间
python
while True:
start_time = time.time() # 开始计时
# 对摄像头每一帧进行推理和可视化
_, img_frame = cap.read()
image_pred = infer_frame_with_vis(img_frame, model, labels_dict, cfg)
image_widget.value = img2bytes(image_pred)
end_time = time.time() # 结束计时
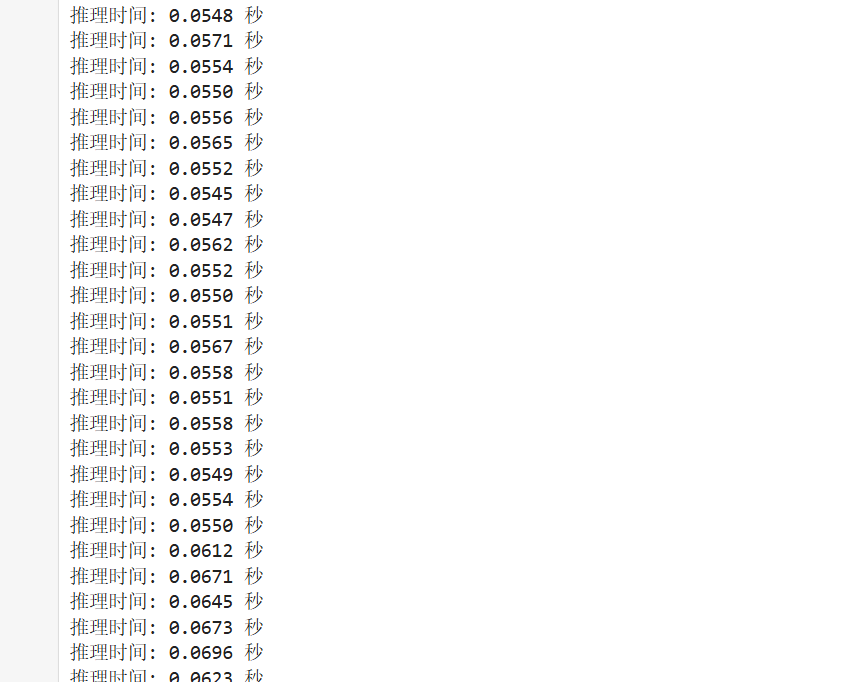
print(f"推理时间: {end_time - start_time:.4f} 秒") # 打印每一帧的推理时间平均每帧0.06s,fps为16.66,速度非常快
四、总结
有幸受到官方的邀请,评测开发板Orange Pi AIpro,由于时间有限测试了开发板部分基础功能、运行了AI应用案例。
优势:
1、接口丰富:HDMI显示、键鼠、WIFI、蓝牙、USB摄像头等功能运行正常。
2、推理速度快:处理图像分类、目标检测效率高,fps能够达到16.66,
3、资料详细,案例丰富,社区和论坛比较完善,有助于快速学习
不足:
1、更改密码后系统进入有问题(目前解决方案是先选择ubuntu on Xorg进入,再退出,再选择Xfce Session(Default))
2、两个HDMI接口只有一个可以使用