一、RTOS是什么?
下面是网上搜索到的定义:

看到系统一般会想到window,linux这种,但是rtos区别于它们的是占用资源小,实时性强,可以运行在资源受限的mcu上。一些soc厂商编写的sdk里带有添加"任务"的功能,例如WCH(沁恒)这里以这篇文章里晒的沁恒ble的sdk代码【沁恒蓝牙mesh】数据收发接口与应用层模型传递_沁恒 mesh-CSDN博客作为例子,应用层的调用的接口如:tmos_start_task,命名虽然带有os跟task的字眼,但是严格上不属于rtos,因为其没有调度,类似的sdk还有onmicro(昂瑞微)这样的,都不属于rtos,更像是一个用户代码的管理模块。
个人理解只要支持多线程,存在调度管理都算rtos,笔者用过的有freertos、zephyr、rt-thread。github或者gitee上也有不少人以学习为目的自己写一个有基本功能的rtos,本文将以介绍rtos的一些基本功能的实现来介绍原理,rtos选用笔者使用比较多的freertos。对于freertos这里推荐一些资料:
1、如果从来没使用的rtos,只在mcu上跑过裸机的,可以看看野火写的freertos文档的前一半部分。
2、如果使用过rtos只是想了解rtos的可以看正点原子写的freertos文档。
3、csdn有个博主写的文章也写的不错:研究是为了理解-CSDN博客
4、官方的说明文档,不过我没看过多少,主要还是看源码。
5、具体处理器的硬件手册,例如我这里举例的是cortex-M3,所以我看的是《cortex-M3权威指南》,我看的是中文版。
但是资料始终还是资料,最后还是看源码,可以找一个自己熟悉soc+对应厂家移植好freertos源码。
如果大部分模块代码逻辑简单的话可以不上系统,在主循环里轮询一个个模块处理接口即可,特别是在一些资源非常有限的soc上。
1.2、为什么使用rtos:
下面举例表达rtos对比裸机的好处,假设裸机模块化做的较好且使用轮询的方式。
情况a:一些需要使用单总线来模拟时序的,模拟出一个这样的时序:io口拉低5ms,然后拉高10ms代表'1'bit,拉低5ms再拉高5ms代表'0'bit,需要写出一些接口来发送控制指令的时候,就会发现实现上没rtos很棘手,因为整个框架是轮询的方式,模拟时序的发送接口发送8个0bit的时候得就delay个80ms,这样其他模块的轮询就得被耽误80ms,当然也可以想办法解决让接口发送不使用delay的方式,但是这个实现就复杂的多了,并且写出来的接口也比较难读,如果没有注释估计看到这个代码的人会一脸懵逼。这时候如果有rtos,代码逻辑就简单了,因为使用os的delay接口,只是让执行这个函数的线程进入阻塞状态,但是并不影响其他线程的的执行。
情况b:处理一个逻辑需要占用10ms,但是在处理的时候,有按键按下,然后需要去执行其他逻辑,因为整体的业务框架是轮询的方式,不顺序执行完前面的业务没法处理这个紧急的业务,当然也可以用中断来处理这个事情,但是如果这个紧急的业务也耗费时间怎么办?总不能在中断里执行这个耗时间的业务吧?假如它不耗时,那这对模块化也不够友好,这时候如果有rtos,可以通过设置线程的优先级,让紧急业务在高优先级线程里执行。
1.3、本文的主要内容:
这里以freertos的代码作为主要的参考来介绍,代码这里找的是原子资料里的版本(版本是V9.0,其他官网上下的也一样,区别不大),芯片处理器内核则以cortex-M3作为例子,着重讲os功能实现的方式,不去讲freertos的使用,主要回答三个问题:1、os如何控制系统?2、多线程如何实现的。3、线程之间通信是如何实现的。4、freertos不同线程通讯方式在功能上和效率上的区别。
1.4、如何看待rtos:
它是一套工具代码,rtos没有高地之分,各有各的优点,熟悉一个,另一个也能较快上手。除了小部分硬件平台相关的内容,例如freertos会把一些硬件芯片架构相关的放在portable文件夹里实现。软件部分都是类似的,软件即是逻辑,将人的想法用代码控制硬件加以实现。
二、常见的名词
如果没有接触过os的可能对这些名词的概念比较模糊,这里大概解释一下,当做一个记录便于查询,后面介绍原理的时候用到这些名词就不解释了。
2.1、多线程
大白话的解释就是,在没有os的时候mcu上全部逻辑都在main函数里的一个大循环里被调用,多线程的就是可以写多个大循环,每个循环被各自的线程函数调用,每个线程可以写自己的初始化和业务逻辑,线程有自己的栈空间,就是说线程里定义的局部变量,函数调用所消耗的栈都是线程栈。相比裸机,多线程需要考虑并发、异步逻辑,因为没法预测下一时刻可能会执行哪个线程(线程很少且逻辑简单例外,可是太简单也可以不使用os,例如整个系统就一个线程为什么还需要用os?),裸机的时候大循环里的业务逻辑基本都是同步可控的,假如可以使用jlink或jtag等在线调试工具可以单步调试走到底但是多线程则不行。所以多线程环境下虽然功能更强大了,但是出问题的时候也相对更难定位。
2.2、线程栈
在裸机的时候,mcu启动文件里会定义栈的空间,例如会看到这样的代码:
cpp
Stack_Size EQU 0x400;
AREA STACK, NOINIT, READWRITE, ALIGN=3
Stack_Mem SPACE Stack_Size然后编译完看输出的map文件会看到内存最后会有个大小为0x400的内存占用,这个在这里称它为主栈,这段内存叫它栈内存,而在创建线程的时候,可以静态传递一段内存作为线程使用的栈,这里叫线程栈。在裸机的时候,所有的局部变量,函数调用都会消耗栈内存。例如在调用函数的时候调用之前的局部变量都会进栈,例如看反汇编代码的时候会看到push指令,函数传递参数的时候可能也会进栈,再函数返回的时候则会出栈,例如我们看反汇编代码会看到pop指令,如果把栈内存消耗完了那就栈溢出错误了这时候会出现hardfault之类的错误,如果不理解可以查询百度关于C语言这部分的内容。
同理在线程里也是一样,只是消耗的内存变成了线程的栈,rtos都会有线程栈溢出的检测机制但是也不一定能百分百检测正确。在cortex内核处理器里有两个栈指针寄存器:主堆栈指针 (Main Stack Pointer,MSP)和进程堆栈指针(Process Stack Pointer,PSP),默认使用MSP,例如中断产生的时候使用的是MSP,这个是硬件自动切换的,当执行的上下文是线程的时候则使用PSP。
2.3、堆栈指针
顾名思义就是指向栈内存的指针,但是这个是寄存器保存的,前面说到栈内存的消耗其实就是栈指针在栈内存上的移动,对于一些使用内部ram的mcu一般都是选择内存的最后一段为栈内存,这是链接脚本决定的。
压栈的时候栈指针从高地址向低地址移动,将一些需要进栈的数据按顺序压(写进)进栈内存同时移动,当栈指针一直移动到超过栈顶了也就是栈溢出了,栈指针破坏了栈内存之外的数据,这里描述的栈指针的逻辑不区分psp跟msp。一般是代码(看反汇编代码能看到)手动压栈,cortex-M3在中断产生的时候是处理器自动压栈。
2.4、上下文
在看os相关资料的时候可能会经常看到这个词语,这个是直接翻译过来的即context这个单词,在线程调度的代码也能看到这个单词,freertos就叫 vTaskSwitchContext,管他叫 切换上下文。这里为了有个感性的认知,使用一个单步debug的图片,使用过mcu在线仿真的对这图片应该不陌生,如下图(写本文的时候手上没现成的debug设备,借朋友一个设备跑的rt-thread代码):
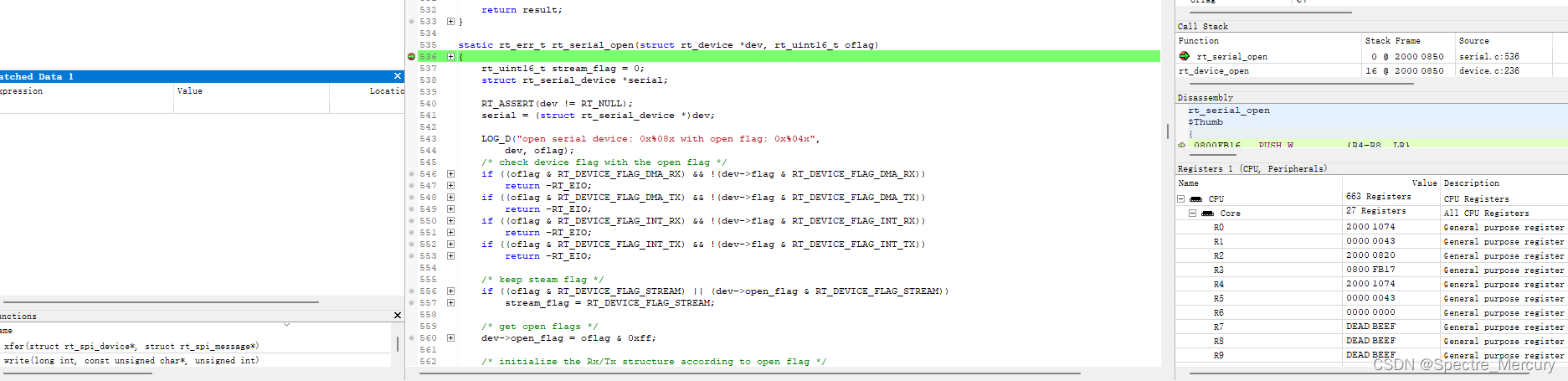
假如一个线程它调用了如图这个叫 rt_serial_open 这个函数,执行到图中断点位置的时候(图中红色点),即PC当前在这个行代码上的时候,它的环境如右边的所示,寄存器R0~Rn的值,它记录了当前线程的寄存器状态,如PC指针,堆栈指针,LR,状态寄存器等等,那这里统一管它们叫这个线程当前的环境。然后这时候CPU发现需要将它切换到另一个线程,同理另一个线程也有他的环境,所以系统调度切换线程做的工作内容实际上就是保存上一个线程的环境(保存上文),然后切换到下一个线程的环境(切换下文),这个就是 switch context。
只要有这个环境就能恢复到下一个线程然后切换到它原来被打断的那个点恢复执行,有单步调试过的应该会发现通过IDE能看到当前环境局部变量的内容。这个环境在定位一些死机问题的时候有时候很有用,通过一些工具或者手段,导出当前死机的设备的内存跟环境来恢复现场,定位为什么死机,又是执行到哪一行导致异常出现,但是有时候死机没法准确定位例如踩内存或者其他原因导致环境被破坏。
2.5、抢占式系统
rtos的rt是real-time的缩写,这里个人理解因为支持抢占所以才能更高效的实时,抢占的意思是高优先级的线程可以打断低优先级的执行,例如例如低优先级线程跑了一半cpu切换到另一个优先级更高的线程去执行,freertos是支持抢占式的。
2.6、调度
在freertos里,系统内核大部分代码做的事情就是保证同一时刻在执行的是当前优先级最高的线程,直到这个的线程主动阻塞(或者被挂起),或者被更高优先级的线程打断。为了保证公平,实时性,不同的rtos可能有不同的策略,这个管理过程叫系统调度,也是一个rtos最核心的东西。
2.7、优先级
这里指的是线程的优先级,本文如果没有特别指出,指的都是线程的优先级,需要跟freertos的宏定义configMAX_SYSCALL_INTERRUPT_PRIORITY区分,这宏定义指的是系统中断的优先级,这个说线程切换的流程会解释。这个是衡量当前线程的优先程度的标量,因为同一时刻CPU只会执行一个线程,这个值在创建线程的时候会传递这个值。
freertos的优先级是整数来表达,值越大优先级越高。也有一些和这个相反的例如zephyr和rt-thread则是越小优先级越高,zephyr的优先级还有负数的,这种线程不支持被抢占,不支持抢占就是说它不执行到主动阻塞或者被挂起让出cpu,其他线程是没法被执行的。
还有一种特殊的情况,就是两个线程优先级一样的情况,但是不能确定下次先执行哪个线程,对于这种不同的rtos有不同的策略,这部分freertos打开宏定义configUSE_TIME_SLICING的时候支持在系统时基中断(时间片)到来的轮流切换同样优先级的线程(如果他们都是就绪状态),这个有的rtos管它叫RR(Round-Robin),即罗宾循环,为调度策略的一种。
2.8、系统状态
上面提到的阻塞跟挂起都属于线程的状态,这里介绍几种状态的区别,状态图如下,图片来自正点原子的文档。
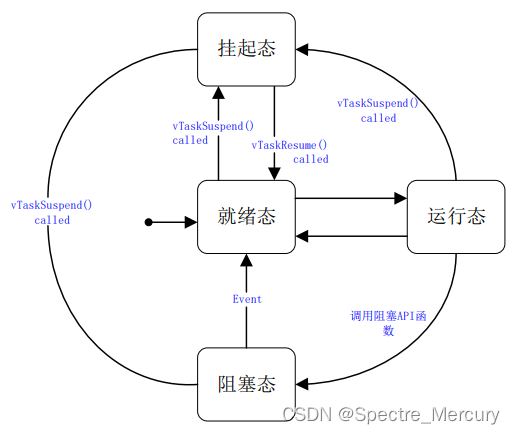
2.9、挂起状态
在这里说的挂起说的是一个状态,一般看资料都是叫挂起,用"暂停"去理解好一些,就像看网络电视的时候点了"pause"然后它停下来了,线程调用挂起接口就代表这个线程被移出就绪列表,不参与调度,在freertos里有个记录被挂起的线程句柄的链表,xSuspendedTaskList。
2.10、阻塞状态
例如调用系统提供的延时函数,例如延时5秒(vTaskDelay),那这个线程将挂起5秒,挂起也有个链表用来记录被阻塞的线程句柄,叫 pxDelayedTaskList(其实还有个pxOverflowDelayedTaskList用于系统时基溢出的时候),5秒后调度系统将让他退出阻塞列表进入就绪列表,如果这个线程是当前优先级最高的线程则产生一次线程切换让它进入运行状态。
2.11、就绪状态
当线程被创建并且启动的时候它就进入了就绪列表,这个也有个链表记录,叫 pxReadyTasksLists,调度切换线程的时候,它的逻辑就是从这个就绪列表里判断当前是否有线程优先级比当前在执行的的线程的优先级更高。
2.12、运行状态
当前得到cpu的线程状态。
2.13、线程句柄
创建线程的时候会得到一个句柄,这个句柄相当于一个指针,通过这个指针能访问到跟这个相关的一切内容,因为这个句柄指向一个记录线程信息的结构体,freertos里这个叫TCB,如下:
cpp
/*
* Task control block. A task control block (TCB) is allocated for each task,
* and stores task state information, including a pointer to the task's context
* (the task's run time environment, including register values)
*/
typedef struct tskTaskControlBlock
{
/* 略 */
} tskTCB;对于这个在其他rtos也一样有个一样功能的数据结构,例如zephyr的k_thread,rt-thread的rt_thread。freertos有个全局的指针用来指向当前执行的线程的TCB,叫 pxCurrentTCB。
2.14、系统时基
os的系统心跳,由主控提供,例如cortex-M3的可以使用systick,至于用什么硬件定时器取决于使用的平台有哪些定时器和实际的应用场景,当然也可以选择使用其他定时器能给系统提供时基就行。发现目前用过的cortex-M处理器的都是用这个做系统时基,可能是为了通用,另外这个功能相对硬件定时器弱一些可能功耗也能低一些。
一般这个速度设置为1000HZ,也就是1ms来一次系统时间中断,在freertos里使用的宏定义是configTICK_RATE_HZ,移植的时候初始化systick的时候可以根据这个宏来设置具体的平台系统定时器速度。这个定时器的速度可以说是这个rtos响应的最快速度,再快的则是os之外的东西了例如你加了其他中断,这个值设置的太慢那系统的响应速度也会变慢影响实时性,设置太快的话那systick中断会过于频繁进入浪费性能,因为cpu花了较多时间在这上面。
这个时基保存在一个变量里:
cpp
##tasks.c
static volatile TickType_t xTickCount
typedef uint32_t TickType_t;这里我看的代码都是无符号32bit的,当产生一次系统时间中断的时候,它就会加1,在BaseType_t xTaskIncrementTick( void ) 这个函数里实现,这个函数又在port.c里被系统时间中断调用。
三、硬件相关概念
freertos的内核代码是一个纯逻辑的东西,跟硬件架构相关的实现接口则放在 文件夹portable 里面,所以移植的工作实际上就是实现 portable 里相关的内容,里面可以看到一些汇编代码。这里关于cortex-M3为例子介绍一下几个寄存器的作用,便于后面介绍线程调度的过程。下面内容参考自 《cortex-M3权威指南》
3.1、处理器模式:
cortex-M3下有两种处理器级别,一个叫特权级一个叫用户级,特权级有更多的访问权限,例如一些寄存器必须在特权级模式下,正常的时候程序运行在用户级模式,可以通过产生可以异常或者进入中断来进入特权模式。
3.2、寄存器组:
如下图
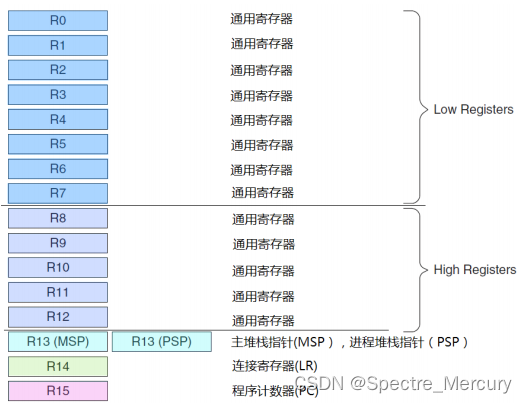
R0‐R12 都是 32 位通用寄存器,用于数据操作,这里说一下R0~R3,调用函数传参的时候会使用这4个寄存器,返回的参数也会用这几个寄存器,这个是arm规定的,用c写一个函数,传递4个参数然后看它的反汇编代码就能看到。
R13(SP):放栈指针的寄存器,同一时刻只能会其中一个指针,前面说栈指针的时候提到了两个指针 MSP 和 PSP,例如在中断函数里就是默认使用的MSP,也能使用特殊指令指名道姓的操作其中一个MSP。
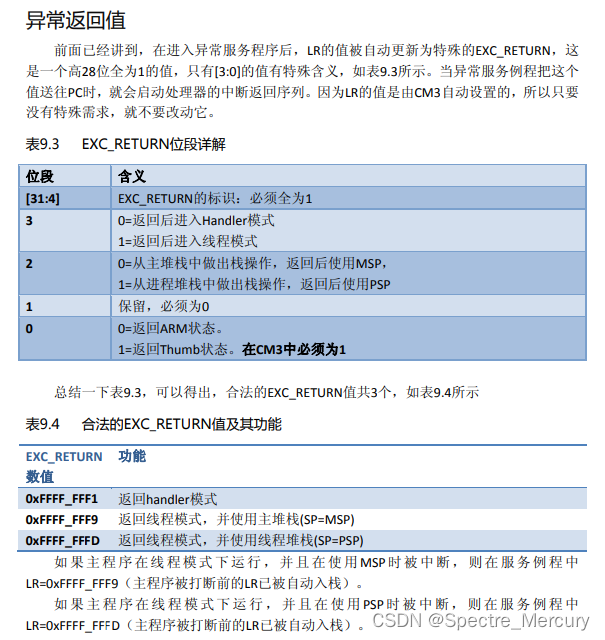
R14(LR): 链接寄存器,一般存储程序返回的地址,例如调用某个函数的时候,LR保存调用之前的下一行指令地址。在中断产生的时候这个寄存器会被自动加载一个特殊值 EXC_RETURN。具体细节如下内容
R15(PC): 指向当前指向的程序地址,修改它的值能改变程序的执行位置,例如你调用了一个为空的函数指针导致死机,此时coredump的时候PC就为0x00000000。
xPSR:状态寄存器,这个对运行环境的状态做个保存,汇编的一些带判断的指令就是根据这个寄存器来的,具体bit如下图:

中断屏蔽相关寄存器的使用可以在代码里看到,在freertos屏蔽某些中断的时候会看到用到了这几个寄存器。CONTROL寄存器需要特权模式访问,可以修改使用的sp指针是msp还是psp,这里不暂开讨论,感兴趣可以看《cortex-M3权威指南》。
四、多线程原理
这里举一个例子,假如现在有一份使用freertos的代码,mcu启动后在主main函数里创建了一个线程(取名线程1,线程2,线程3),启动了调度器,在第一个线程里又创建了两个其他线程,这三个线程有不同的优先级,线程之间可以通讯。现在以这个例子引出以下两个问题,通过解答问题对rtos的多线程原理有个理解。
**问题1:**程序跑起来后,创建了线程,启动了调度器,每个线程都是独立的一个函数,那程序又是怎么跑到这第一个线程的?
**问题2:**执行线程1的过程中,新创建的线程2的优先级比较它高,那高优先级线程打断低优先级线程得到执行,这个逻辑又是如何实现的?
4.1、系统管理线程使用的的链表结构
在回答问题之前,先了解下以下关于freertos内核代码相关的数据结构。创建线程后将得到一个句柄,启动后就是把它加到就绪列表里,在这里freertos管理线程实际上都是将它们的线程句柄(TCB,后面都以TCB来称这个)放在一个个表里,下面贴代码:
cpp
位置:tasks.c
/* Lists for ready and blocked tasks. --------------------*/
List_t pxReadyTasksLists[ configMAX_PRIORITIES ];/*< Prioritised ready tasks. */
List_t xDelayedTaskList1; /*< Delayed tasks. */
List_t xDelayedTaskList2; /*< Delayed tasks (two lists are used - one for delays that have overflowed the current tick count. */
List_t * volatile pxDelayedTaskList; /*< Points to the delayed task list currently being used. */
List_t * volatile pxOverflowDelayedTaskList; /*< Points to the delayed task list currently being used to hold tasks that have overflowed the current tick count. */
List_t xPendingReadyList; /*< Tasks that have been readied while the scheduler was suspended. They will be moved to the ready list when the scheduler is resumed. */
List_t xSuspendedTaskList; /*< Tasks that are currently suspended. */**List_t 结构:**类似双向链表,可以通过这几个链表的名字可知道,每个表对应了一种状态,下面介绍一下这几个表的作用。
**pxReadyTasksLists:**如注释这就是就绪列表,全部参与调度的线程都在这里,configMAX_PRIORITIES 是一个宏定义,代表当前freertos支持的最高优先级,所以这里是数组的原因就是同个优先级的链表会被挂在同一个的就绪列表下,数组的好处是访问的速度是O(1)。
**xDelayedTaskList1:**名字就是延时列表,所有需要阻塞一段时间的tcb都会加进这里,例如调用了系统延时api或者其他会导致延时的api,然后系统时基中断每次进来都会判断里面的线程的解除被阻塞时间是否过去,然后时间已经到达就把它挪到就绪列表里继续参与调度
**xDelayedTaskList2:**如注释所示这个是当系统时基溢出的时候用到的,这里判断是否挂在这里的线程是否已经到达需要解除阻塞的时间点是算出来的,如:当前系统时基的tick值为1000,需要阻塞1000个tick,那当tick增加到2000的时候就需要将这个线程解除阻塞,目标tick为2000,前面说这个系统时基的tick是保存在一个变量里,例如说他是uint32_t类型,那当它一直加到大于0xffffffff的时候就溢出了,这时候就会出现目标tick的值小于系统时基,这个表就是用于那时候用的。
**pxDelayedTaskList:**指针,初始化指向 xDelayedTaskList1,会发现注释写着"currently being used"。
**pxOverflowDelayedTaskList:**指针,初始化指向 xDelayedTaskList2。
这里解释一下,当系统时基溢出的时候且,pxDelayedTaskList 上已经没有挂着线程,就会做一个切换,本来初始化的时候 pxDelayedTaskList这个"currently delay list" 指向的是 xDelayedTaskList1,pxOverflowDelayedTaskList 指向 xDelayedTaskList2,当发送 系统时基溢出的时候会调用 taskSWITCH_DELAYED_LISTS,接下来 pxDelayedTaskList 指向xDelayedTaskList2,pxOverflowDelayedTaskList 指向 xDelayedTaskList1,再溢出就再切换一次。
**xPendingReadyList:**如注释所示,当系统调度器被 suspended(挂起) 的时候会把就绪列表里的线程都挪到这个表里,这样就它们不会参与调度了。跟着源代码看这个表更像一个临时用的表,即调度逻辑被关掉的时候,如果这时候有进入就绪的线程被挂到这里,其他场景没看到它被使用。
**xSuspendedTaskList:**如注释所示,当前被 suspended (挂起)的线程会挪到这个表上。目前有两种情况会被加入这个表,一种是线程被主动使用 suspend的api主动挂起,一种是使用线程通讯api的时候,如果条件不满足的时候线程能一直阻塞,例如是发送消息队列或者接收消息队列不成功的时候,传递的超时参数是 portMAX_DELAY(相当于永久等待的事件参数,在zephyr里好理解因为管它叫 wait forever)。
4.2、链表和链表节点的具体结构
为了理解这个表的使用方式,这里介绍一下表结构的的主要元素,代表链表结构体为List_t,前面说了它的作用类似双向链表,这里不介绍关于链表这种数据结构,这里感兴趣可以查资料或者了解一些开源代码的双向链表使用,如zephyr,rt-thread,linux内核下都有这样的api,实现方式基本都是一样的,了解这类链表实现便于阅读这部分代码。freertos里的链表部分实现方式和这些类似但是这里定义的结构是为了系统调度。
下面贴list_t跟list_item_t的定义代码:
cpp
位置:list.h 有删减
typedef struct xLIST
{
configLIST_VOLATILE UBaseType_t uxNumberOfItems;
ListItem_t * configLIST_VOLATILE pxIndex; /*< Used to walk through the list. Points to the last item returned by a call to listGET_OWNER_OF_NEXT_ENTRY (). */
MiniListItem_t xListEnd; /*< List item that contains the maximum possible item value meaning it is always at the end of the list and is therefore used as a marker. */
} List_t;
/* MiniListItem_t的结构体内容如下: */
struct xMINI_LIST_ITEM
{
configLIST_VOLATILE TickType_t xItemValue;
struct xLIST_ITEM * configLIST_VOLATILE pxNext;
struct xLIST_ITEM * configLIST_VOLATILE pxPrevious;
};
/* 另一个列表节点结构体的定义如下 */
struct xLIST_ITEM
{
configLIST_VOLATILE TickType_t xItemValue; /*< The value being listed. In most cases this is used to sort the list in descending order. */
struct xLIST_ITEM * configLIST_VOLATILE pxNext; /*< Pointer to the next ListItem_t in the list. */
struct xLIST_ITEM * configLIST_VOLATILE pxPrevious; /*< Pointer to the previous ListItem_t in the list. */
void * pvOwner; /*< Pointer to the object (normally a TCB) that contains the list item. There is therefore a two way link between the object containing the list item and the list item itself. */
void * configLIST_VOLATILE pvContainer; /*< Pointer to the list in which this list item is placed (if any). */
};
typedef struct xLIST_ITEM ListItem_t; /* For some reason lint wants this as two separate definitions. */List_t下面有个xMINI_LIST_ITEM, 相当于一个这个链表的头,xLIST_ITEM 则是这个链表上的节点结构,通过节点里的元素就能访问到对应的TCB,链表的头本身不需要携带多余的数据因此这个使用 xMINI_LIST_ITEM 而不是 xLIST_ITEM,目的可能是为了节省内存或者跟 链表节点的结构有区别。xMINI_LIST_ITEM上有一对指针 pxNext 跟 pxPrevious作为节点的'头'跟'尾',每个入表的 节点也带有一对这样的指针,入队的节点通过指针跟这个链表头通过指针形成一个环形双向链表,加入这个链表的节点如果已经入了三个节点的话大概长下面这样。
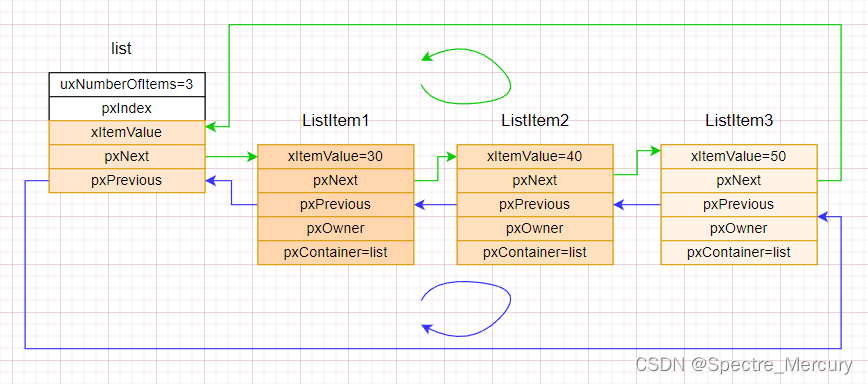
图中代表指针方向箭头都是指向item结构体的头,双向链表组成两个方向的环,系统跑起来的时候随着线程状态切换的时候可以想象为线程的tcb就是在上面介绍的几个链表之间挪来挪去。
4.3、链表和链表节点结构的相关元素作用
List_t:
**uxNumberOfItems:**代表该链表的元素个数,每次调用api: vListInsert() 和 vListInsertEnd()的时候它会加1,调用uxListRemove()则减1。
**pxIndex:**暂时理解为这个链表的操作节点索引;
xListEnd->pxNext 和 **xListEnd->pxPrevious:**前面说了主要是用来组成这个表的表头,带方向;
**xListEnd->xItemValue:**先暂时理解为这个节点的flag;
xLIST_ITEM:
**pxNext 和 pxPrevious:**同 xListEnd 一样,组成了这个链表;
xItemValue: 先暂时理解为这个节点的flag,在使用 vListInsert api将节点插入链表的时候以这个值的大小作为排序的依据;
pvOwner: 指向TCB,所以找到节点就能找到对应的TCB,这个对应的TCB在创建的时候就会初始化其下面的链表节点指向为TCB本身;
**pvContainer :**指向目标链表,当 使用链表插入 api的时候将这个指向目标链表,代表这个节点属于这个表;例如当线程调用系统delay的api后导致阻塞则这个将使用,链表节点 移除接口 将它挪出后,再使用 插入接口 插入到挂起链表。
4.4、tcb的结构
上面说到将 链表节点 插入到 链表,这里贴删减后部分tcb的结构的代码:
cpp
/*
* Task control block. A task control block (TCB) is allocated for each task,
* and stores task state information, including a pointer to the task's context
* (the task's run time environment, including register values)
*/
typedef struct tskTaskControlBlock
{
volatile StackType_t *pxTopOfStack; /*< Points to the location of the last item placed on the tasks stack. THIS MUST BE THE FIRST MEMBER OF THE TCB STRUCT. */
ListItem_t xStateListItem; /*< The list that the state list item of a task is reference from denotes the state of that task (Ready, Blocked, Suspended ). */
ListItem_t xEventListItem; /*< Used to reference a task from an event list. */
UBaseType_t uxPriority; /*< The priority of the task. 0 is the lowest priority. */
StackType_t *pxStack; /*< Points to the start of the stack. */
char pcTaskName[ configMAX_TASK_NAME_LEN ];/*< Descriptive name given to the task when created. Facilitates debugging only. */ /*lint !e971 Unqualified char types are allowed for strings and single characters only. */
UBaseType_t uxBasePriority; /*< The priority last assigned to the task - used by the priority inheritance mechanism. */
UBaseType_t uxMutexesHeld;
###volatile uint32_t ulNotifiedValue;
###volatile uint8_t ucNotifyState;
} tskTCB;当某个链表加入一个线程的时候实现方式则是将tcb结构里的里的一个 xLIST_ITEM 加入到这个链表,就是链表插入操作,例如线程创建的时候它的状态属于就绪状态,那就将它插入就绪链表,如下调用顺序:
cpp
xTaskCreate(xxx)
->prvAddTaskToReadyList( pxNewTCB );
->vListInsertEnd( &( pxReadyTasksLists[ ( pxTCB )->uxPriority ] ), &( ( pxTCB )->xStateListItem ) );下面解释一下TCB结构体的内容:
xStateListItem 作用如上述。
xEventListItem主要是是用在线程通讯的时候,后面会说它的作用。
pxTopOfStack 如命名,为栈顶指针。
uxPriority 线程实际的优先级,创建线程的时候的会赋值。
pxStack创建的时候指向栈内存的起始地址。
pcTaskName 线程名字,debug的时候会用到。
uxBasePriority 当出现需要临时修改线程优先级的时候这个会用到,作用类似于保存线程"原始的优先级",在下面提到 防止优先级反转的时候会用到。
uxMutexesHeld用于互斥量,后面再说明作用。
4.5、打开调度到第一个线程的启动
铺垫完这么多东西,现在可以根据前面的问题看代码了。这里插入一段示例代码,然后再解释一些api做了什么.
cpp
main函数,创建第一个线程并且打开调度
int main(void)
{
....
/* 创建用户的线程1 */
xTaskCreate((TaskFunction_t )task1_func, //线程函数
(const char* )"task1", //名称
(uint16_t )START_STK_SIZE, //线程栈大小
(void* )NULL, //传递给线程函数的参数
(UBaseType_t )4, //优先级
(TaskHandle_t* )&task1_handler); //线程句柄
/* 开启任务调度 */
vTaskStartScheduler();
}这里看看线程创建函数,这里只看动态分配的接口,静态的接口差不多区别在于是否传入使用的内存,这里省略掉这部分代码只关注需要讲解内容,完整代码可在正点原子的资料里下载或者找stm32官方移植的。
cpp
来自:task.c ,代码有删减
BaseType_t xTaskCreate( TaskFunction_t pxTaskCode,
const char * const pcName,
const uint16_t usStackDepth,
void * const pvParameters,
UBaseType_t uxPriority,
TaskHandle_t * const pxCreatedTask ) /*lint !e971 Unqualified char types are allowed for strings and single characters only. */
{
TCB_t *pxNewTCB;
/* 省略,主要是给创建的线程的TCB和栈分配内存 */
/* 初始化这个线程的TCB */
prvInitialiseNewTask( pxTaskCode, pcName, ( uint32_t ) usStackDepth, pvParameters, uxPriority, pxCreatedTask, pxNewTCB, NULL );
/* 将这个TCB挂到就绪链表里 */
prvAddNewTaskToReadyList( pxNewTCB );
/* 省略 */
}这里分析一下线程初始化接口 prvInitialiseNewTask 跟 prvAddNewTaskToReadyList.
cpp
来自:task.c ,代码有删减
static void prvInitialiseNewTask( TaskFunction_t pxTaskCode,
const char * const pcName,
const uint32_t ulStackDepth,
void * const pvParameters,
UBaseType_t uxPriority,
TaskHandle_t * const pxCreatedTask,
TCB_t *pxNewTCB,
const MemoryRegion_t * const xRegions ) /*lint !e971 Unqualified char types are allowed for strings and single characters only. */
{
StackType_t *pxTopOfStack;
UBaseType_t x;
/* 这里将栈内存初始化为一个已知的值0xA5,在检测栈水线接口prvTaskCheckFreeStackSpace里就是通过判断栈内存有多少不是0xA5来判断栈剩余多少 */
( void ) memset( pxNewTCB->pxStack, ( int ) tskSTACK_FILL_BYTE, ( size_t ) ulStackDepth * sizeof( StackType_t ) );
/* 这里cortex-M3的栈是从高地址向低地址增长的,所以这里是pxTopOfStack设置成栈内存最后的地址 */
pxTopOfStack = pxNewTCB->pxStack + ( ulStackDepth - ( uint32_t ) 1 );
/* 这里一段代码都是初始化TCB的内容如一些链表节点相关的初始化,线程名等等,这里省略, */
/* 初始化线程栈内存,然后将初始化后的实际栈顶地址返回 */
pxNewTCB->pxTopOfStack = pxPortInitialiseStack( pxTopOfStack, pxTaskCode, pvParameters );
}pxPortInitialiseStack 这个在port.c里实现,跟使用的硬件芯片架构相关,由于cortex-M3中断产生的时候会按顺序自动压8个寄存器到栈里,分别是:xPSR、PC、LR、R12、R3~R0,然后人为压R11~R4,看注释管这个叫栈帧
这里我们再看cortex-M3的pxPortInitialiseStack 函数.
cpp
来自:port.c
StackType_t *pxPortInitialiseStack( StackType_t *pxTopOfStack, TaskFunction_t pxCode, void *pvParameters )
{
/* 该函数是模拟一次中断入栈,当前是在栈顶地址 */
pxTopOfStack--; /* Offset added to account for the way the MCU uses the stack on entry/exit of interrupts. */
/* 入xPSR */
*pxTopOfStack = portINITIAL_XPSR;
pxTopOfStack--;
/* 入PC,指向线程的入口 */
*pxTopOfStack = ( ( StackType_t ) pxCode ) & portSTART_ADDRESS_MASK;
pxTopOfStack--;
/* 入LR,保存为一个error函数,如果线程这个函数退出了会执行这个错误函数,因为线程按理应该是一个死循环 */
*pxTopOfStack = ( StackType_t ) prvTaskExitError;
/* 偏移5个寄存器地址,相当于入R12,R3,R2,R1 */
pxTopOfStack -= 5;
/* 入R0,线程的第一个形参就是保存的这个,上面说过是ARM的编程规范决定,编译器翻译的时候会把第一个形参用R0传递 */
*pxTopOfStack = ( StackType_t ) pvParameters; /* R0 */
/* 手动入R11~R4,这里默认就是认为会用到这个8个寄存器 */
pxTopOfStack -= 8; /* R11, R10, R9, R8, R7, R6, R5 and R4. */
/* 返回当前栈顶 */
return pxTopOfStack;
}这里顺便看一下rt-thead的初始化线程栈的接口,同样的目的但是人家不需要加注释就能看明白。
cpp
来自:libcpu\arm\cortex-m3\cpuport.c
struct exception_stack_frame
{
rt_uint32_t r0;
rt_uint32_t r1;
rt_uint32_t r2;
rt_uint32_t r3;
rt_uint32_t r12;
rt_uint32_t lr;
rt_uint32_t pc;
rt_uint32_t psr;
};
struct stack_frame
{
/* r4 ~ r11 register */
rt_uint32_t r4;
rt_uint32_t r5;
rt_uint32_t r6;
rt_uint32_t r7;
rt_uint32_t r8;
rt_uint32_t r9;
rt_uint32_t r10;
rt_uint32_t r11;
struct exception_stack_frame exception_stack_frame;
};
rt_uint8_t *rt_hw_stack_init(void *tentry,
void *parameter,
rt_uint8_t *stack_addr,
void *texit)
{
struct stack_frame *stack_frame;
rt_uint8_t *stk;
unsigned long i;
stk = stack_addr + sizeof(rt_uint32_t);
stk = (rt_uint8_t *)RT_ALIGN_DOWN((rt_uint32_t)stk, 8);
stk -= sizeof(struct stack_frame);
/* 偏移m3需要入的栈 */
stack_frame = (struct stack_frame *)stk;
/* init all register */
for (i = 0; i < sizeof(struct stack_frame) / sizeof(rt_uint32_t); i ++)
{
((rt_uint32_t *)stack_frame)[i] = 0xdeadbeef;
}
stack_frame->exception_stack_frame.r0 = (unsigned long)parameter; /* r0 : argument */
stack_frame->exception_stack_frame.r1 = 0; /* r1 */
stack_frame->exception_stack_frame.r2 = 0; /* r2 */
stack_frame->exception_stack_frame.r3 = 0; /* r3 */
stack_frame->exception_stack_frame.r12 = 0; /* r12 */
stack_frame->exception_stack_frame.lr = (unsigned long)texit; /* lr */
stack_frame->exception_stack_frame.pc = (unsigned long)tentry; /* entry point, pc */
stack_frame->exception_stack_frame.psr = 0x01000000L; /* PSR */
/* return task's current stack address */
return stk;
}可以看到他们做的事情是一样的,在调用rt_hw_stack_init有个区别的是rt-thread的LR保存的不是一个错误处理函数而是 _thread_exit,这个函数做的主要是线程退出的一些收尾工作,这里也可以解释为什么freertos线程退出需要手动调用删除接口,而rt-thread不需要只需要线程这个函数退出,原因是因为退出的时候会执行LR寄存器保存_thread_exit接口。
prvAddNewTaskToReadyList除了加载线程到 就绪链表 pxReadyTasksLists 里之外,如果 pxCurrentTCB 为空的则会将 pxCurrentTCB指向 新创建的这个线程的 TCB,pxCurrentTCB是一个全局的指针在tasks.c里定义,指向当前得到CPU的线程TCB。所以我们创建的第一个线程task1的时候 pxCurrentTCB 就指向了 task1的TCB.
到这里我们使用freertos创建了线程task1,但是os还没跑起来,然后main函数执行了 vTaskStartScheduler.
cpp
来自:task.c,代码有删减
void vTaskStartScheduler( void )
{
BaseType_t xReturn;
/* 创建一个idle线程,这个后面再解释idle线程的作用 */
xReturn = xTaskCreate( prvIdleTask,
"IDLE", configMINIMAL_STACK_SIZE,
( void * ) NULL,
( tskIDLE_PRIORITY | portPRIVILEGE_BIT ),
&xIdleTaskHandle ); /*lint !e961 MISRA exception, justified as it is not a redundant explicit cast to all supported compilers. */
}
/* 如果打开了软件定时器的宏定义会执行这个 */
xReturn = xTimerCreateTimerTask();
/* 如果打开了软件定时器的宏定义会执行这个 */
portCONFIGURE_TIMER_FOR_RUN_TIME_STATS();
/* 真正启动调度,不同的芯片架构不一样实现有区别,这个xPortStartScheduler在port.c里实现 */
if( xPortStartScheduler() != pdFALSE )
{
/* 正常情况下系统启动后,接下来系统就由os接管了不会再返回这 */
}
else
{
/* Should only reach here if a task calls xTaskEndScheduler(). */
}
}然后又调用了xPortStartScheduler,再看看这个函数,这个是由具体的硬件平台实现。
cpp
来自:FreeRTOS\portable\RVDS\ARM_CM3\port.c,代码有删减
BaseType_t xPortStartScheduler( void )
{
#if( configASSERT_DEFINED == 1 )
{
/* 略,如果打开了 configASSERT_DEFINED才会执行 */
}
#endif /* conifgASSERT_DEFINED */
/* 设置pensv和systick为最低优先级中断以便不打断主控的其他中断函数. */
portNVIC_SYSPRI2_REG |= portNVIC_PENDSV_PRI;
portNVIC_SYSPRI2_REG |= portNVIC_SYSTICK_PRI;
/* 启动系统时基中断,即systick */
vPortSetupTimerInterrupt();
/* 启动第一个线程 */
prvStartFirstTask();
/* Should not get here! */
return 0;
}宏定义 configASSERT_DEFINED 部分的代码已省略,可去原子那或者官方找源代码,那里大篇幅是在获取中断最高优先级以便于在调用名字带fromISR的os api会判断中断优先级,如果出现在优先级比系统管理优先级高的中断函数调用带fromISR的os api 则会产生一次assert。
再看看实际上启动第一个线程的接口prvStartFirstTask,汇编写的也是由具体硬件平台实现。
来自:FreeRTOS\portable\RVDS\ARM_CM3\port.c
cpp
__asm void prvStartFirstTask( void )
{
PRESERVE8
/* 0xE000ED08地址处为VTOR(向量表偏移量)寄存器,存储向量表起始地址 */
ldr r0, =0xE000ED08
ldr r0, [r0]
ldr r0, [r0]
/* 向量表第一项存储主堆栈指针MSP的初始值,这里将这个值压到主栈里,相当于更新一次主栈的栈指针 */
msr msp, r0
/* 打开中断 */
cpsie i
cpsie f
dsb
isb
/* 触发一次svc中断 */
svc 0
nop
nop
}到这里系统需要的时基初始化有了,异常调度用的也初始化好了,中断也打开了,指令svc 0触发一次中断,中断函数如下:
cpp
__asm void vPortSVCHandler( void )
{
PRESERVE8
/* 这里我们知道前面初始化线程的时候pxCurrentTCB现在是task1的TCB */
ldr r3, =pxCurrentTCB /* Restore the context. */
/* pxCurrentTCB的第一个元素是栈顶指针,所以注释说pxTopOfStack作为TCB的第一元素不能改动 */
ldr r1, [r3] /* Use pxCurrentTCBConst to get the pxCurrentTCB address. */
ldr r0, [r1] /* The first item in pxCurrentTCB is the task top of stack. */
/* 手动栈顶的内容加载到这8个寄存器,因为前面task1创建的手动将r4-r11模拟入栈这个指令r0在加到到寄存器的过程中会跟着地址增加,所以这里是模拟一次中断退出 */
ldmia r0!, {r4-r11} /* Pop the registers that are not automatically saved on exception entry and the critical nesting count. */
/* 待会这个中断函数退出到时候sp会切换到PSP,这里手动更新一次psp */
msr psp, r0 /* Restore the task stack pointer. */
isb
mov r0, #0
/* 中断寄存器写0,清中断 */
msr basepri, r0
/* lr |= 0xd,前面说概念的时候说了进中断后LR的作用,接下来退出中断后会使用PSP */
orr r14, #0xd
bx r14
}具体过程如上面的代码解释,最后对LR和0xD做了一个或运算,对于LR寄存器在中断里的作用在前面讲硬件概念的时候说过了,接下来退出这个中断函数后将自动使用PSP,由于当前psp指向的是task1的栈顶,所以接下来退出中断函数cpu将执行task1的线程函数,看起来就像task1被中断vPortSVCHandler函数打断,然后中断返回回到task1。
到这里解答了第一个问题:程序跑起来后,创建了线程,启动了调度器,每个线程都是独立的一个函数,那程序又是怎么跑到这第一个线程的?
这里解释一下前面提到的如果出现在优先级比系统管理优先级高的中断函数调用带fromISR的os api 则会产生一次assert,
configMAX_SYSCALL_INTERRUPT_PRIORITY 这个宏定义规定系统能管理的最高中断优先级,这个能选的值取决于使用的具体处理器内核,可以理解为优先级高于这个的中断则可以打断系统;小于这个的中断则可能会因为系统导致挂起,由于受系统管理所以可以使用系统提供的api。
这里个人理解优先级高的不能使用系统的api(就那些函数名后缀为fromISR的)是因为这些api可能会影响系统管理的那些全局变量,这里为了保护系统管理的那些全局变量操作的原子性因此加了这个要求。
4.6、线程切换
接下来假如在task1中创建了task2,并且这个优先级比task1高.
cpp
static void task1_func(void* arg)
{
/* ..略.. */
xTaskCreate((TaskFunction_t )task2_func, //任务函数
(const char* )"task2", //任务名称
(uint16_t )START_STK_SIZE, //任务堆栈大小
(void* )NULL, //传递给任务函数的参数
(UBaseType_t )5, //任务优先级
(TaskHandle_t* )&task2_handler); //任务句柄
/* ..略.. */
}关于xTaskCreate大部分内容前面已经介绍过,创建成功后会调用函数 prvAddNewTaskToReadyList 来将它插入到就绪链表,这里贴一下这个函数:
cpp
来自 task.c 代码有删减
static void prvAddNewTaskToReadyList( TCB_t *pxNewTCB )
{
/* 进入临界段,理解为关闭优先级小于等于系统能管理的中断,因为接下来会操作系统管理的全局变量 */
taskENTER_CRITICAL();
{
/* 记录线程数量 */
uxCurrentNumberOfTasks++;
/* 这个条件成立就是前面说pxCurrentTCB指向第一个线程的逻辑 */
if( pxCurrentTCB == NULL )
{
/* There are no other tasks, or all the other tasks are in
the suspended state - make this the current task. */
pxCurrentTCB = pxNewTCB;
/* 略 */
}
else
{
/* 调度器还没启动的情况下 */
if( xSchedulerRunning == pdFALSE )
{
/* 如果创建的新线程优先级 >= 当前运行的线程则 pxCurrentTCB指向这个新线程 */
if( pxCurrentTCB->uxPriority <= pxNewTCB->uxPriority )
{
pxCurrentTCB = pxNewTCB;
}
}
}
/* 记录创建的线程数量 */
uxTaskNumber++;
/* tcb插入到就绪链表 */
prvAddTaskToReadyList( pxNewTCB );
}
/* 退出临界段 */
taskEXIT_CRITICAL();
if( xSchedulerRunning != pdFALSE )
{
/* 如果创建的新线程优先级 小于 当前运行的线程则 pxCurrentTCB指向这个新线程 */
if( pxCurrentTCB->uxPriority < pxNewTCB->uxPriority )
{
/* 进行一次抢占,其实就是触发一次调度 */
taskYIELD_IF_USING_PREEMPTION();
}
}
}在插入就绪列表这里 prvAddTaskToReadyList,这是个宏定义,下面是宏定义的代码:
cpp
#define prvAddTaskToReadyList( pxTCB ) \
traceMOVED_TASK_TO_READY_STATE( pxTCB ); \
taskRECORD_READY_PRIORITY( ( pxTCB )->uxPriority ); \
vListInsertEnd( &( pxReadyTasksLists[ ( pxTCB )->uxPriority ] ), &( ( pxTCB )->xStateListItem ) ); \
tracePOST_MOVED_TASK_TO_READY_STATE( pxTCB )
#define taskRECORD_READY_PRIORITY( uxPriority ) portRECORD_READY_PRIORITY( uxPriority, uxTopReadyPriority )
#define portRECORD_READY_PRIORITY( uxPriority, uxReadyPriorities ) ( uxReadyPriorities ) |= ( 1UL << ( uxPriority ) ) 可以看到实际上是对插入的优先级然后在全局变量 uxTopReadyPriority 上置位,这个在cortex-M3里是个32bit的整数,可以理解为什么在cortex-M3里freertos定义的最高支持的优先级是0~31了,例如这个新创建的线程优先级是5,那调用了 taskRECORD_READY_PRIORITY( ( pxTCB )->uxPriority ); 后, uxTopReadyPriority的第五个bit就会置1,例如这里我们前面创建了优先级4的task1,跟现在优先级5的task2,那 uxTopReadyPriority 应该为:(1
在函数prvAddNewTaskToReadyList里 可看到如果调度已经启动则会调用 taskYIELD_IF_USING_PREEMPTION(),这是个宏定义,在cortex-m3这里就是产生一次系统调度,其实就是主动触发一次pensv异常中断,在中断函数里做一次线程切换,下面看看pensv异常中断函数。
cpp
__asm void xPortPendSVHandler( void )
{
extern uxCriticalNesting;
extern pxCurrentTCB;
extern vTaskSwitchContext;
PRESERVE8
/*** 前面介绍上下文概念的时候,这块就是保存上文 ***/
/* 现在sp使用的是MSP,所以这里手动读取psp指向的地址 */
mrs r0, psp
isb
/* r2保存栈顶指向的地址指向栈地址 */
ldr r3, =pxCurrentTCB /* Get the location of the current TCB. */
ldr r2, [r3]
/* r0现在指向psp的地址,这里手动对r4-r11进行入栈 */
stmdb r0!, {r4-r11} /* Save the remaining registers. */
/* 前面r0在使用stmdb压栈的时候会跟着一起减减,这里更新栈顶地址, */
str r0, [r2] /* Save the new top of stack into the first member of the TCB. */
/* 因为待会需要调用c函数,pensv中断这里后半段还要用到r3跟r14原来的内容所以这里对R3和R14临时入栈 */
stmdb sp!, {r3, r14}
/* 屏蔽中断,这里只会屏蔽优先级小于等于系统管理的中断优先级,相当于临界段 */
mov r0, #configMAX_SYSCALL_INTERRUPT_PRIORITY
msr basepri, r0
dsb
isb
/* 调用vTaskSwitchContext,找到优先级最高的tcb更新到pxCurrentTCB指针 */
bl vTaskSwitchContext
/* 开中断,相当于退出临界段 */
mov r0, #0
msr basepri, r0
/* 把前面压的两个再弹出 */
ldmia sp!, {r3, r14}
/*** 前面介绍上下文概念的时候,这块就是恢复下文 ***/
/* pxCurrentTCB指针现在指向的是新的线程的TCB了 */
ldr r1, [r3]
ldr r0, [r1] /* The first item in pxCurrentTCB is the task top of stack. */
/* 新线程的栈指针在线程初始化的时候已经有一次手动入栈,现在手动出栈,以后线程都跑起来切换的时候这里就是正常的手动出栈 */
ldmia r0!, {r4-r11} /* Pop the registers and the critical nesting count. */
/* 更新栈顶指针到 */
msr psp, r0
isb
/* 从异常中断返回,由于r14进中断后会知道返回的是psp还是msp,加上现在psp已经更新为新线程的栈指针 */
/* 因此执行了这个指令后将回到了新线程 task2上执行 */
bx r14
nop
}上面函数的分析如注释,在pensv中断函数里,主要有3步:,
**1、保存上文:**进中断前硬件会自动压栈,压的内容和线程创建模拟入栈的那里一样:xPSR,PC,PC,R12,R3~R0。然后中断了SP自动切换成了MSP,因此这里需要指名道姓的操作psp指针,手动对r4~r11入栈。
**2、找到最高优先级线程的TCB:**C函数 vTaskSwitchContext 会找到最新优先级线程的 TCB然后更新到 pxCurrentTCB ,这里后面再讲实现细节。
**3、恢复下文:**r3代表pxCurrentTCB指针,现在r3指向的是新线程的TCB了,手动对r4~r11出栈到r3指向的栈顶,然后指名道姓的操作更新psp指针,现在psp指向的是最新的线程栈顶了,最后调用bx r14退出中断,sp将自动切换成psp,硬件将自动出前面的栈,pc回到task2_func里,线程2得到cpu开始执行。
到这里实现了一次线程1到线程2的切换,后面其他原因导致线程2挂起的话,线程1得到cpu,调度这里也是一样的流程。到这里回答了第二个问题:执行线程1的过程中,新创建的线程2的优先级比较它高,那高优先级线程打断低优先级线程得到执行,这个逻辑又是如何实现的?
到这里实现了一次线程1到线程2的切换,后面其他原因导致线程2挂起的话,线程1得到cpu,调度这里也是一样的流程。到这里回答了第二个问题:执行线程1的过程中,新创建的线程2的优先级比较它高,那高优先级线程打断低优先级线程得到执行,这个逻辑又是如何实现的?
这里大概对 vTaskSwitchContext 做一个简单讲解,代码解析如下:
cpp
来自task.c 代码有删减
void vTaskSwitchContext( void )
{
if( uxSchedulerSuspended != ( UBaseType_t ) pdFALSE )
{
/* 调度器挂起了这里就不做调度了 */
xYieldPending = pdTRUE;
}
else
{
xYieldPending = pdFALSE;
#if ( configGENERATE_RUN_TIME_STATS == 1 )
{
/* 略,统计cpu使用占比用到 */
}
#endif /* configGENERATE_RUN_TIME_STATS */
/* 打开了对应宏定义的话这里会检测栈是否溢出,实现原理前面讲线程创建的时候提过 */
taskCHECK_FOR_STACK_OVERFLOW();
/* 宏定义找到最高优先级的线程更新到pxCurrentTCB */
taskSELECT_HIGHEST_PRIORITY_TASK();
}
}
宏定义:
#define taskSELECT_HIGHEST_PRIORITY_TASK() \
{ \
UBaseType_t uxTopPriority; \
\
/* 找到当前就绪表里的线程里优先级的值 */ \
portGET_HIGHEST_PRIORITY( uxTopPriority, uxTopReadyPriority ); \
/* 异常检查,判断这个表里是否插入的TCB为0 */
configASSERT( listCURRENT_LIST_LENGTH( &( pxReadyTasksLists[ uxTopPriority ] ) ) > 0 ); \
/* */
listGET_OWNER_OF_NEXT_ENTRY( pxCurrentTCB, &( pxReadyTasksLists[ uxTopPriority ] ) ); \
}
/* 这里对上面的宏定义都做一个展开讲解 */
代码来自:FreeRTOS\portable\RVDS\ARM_CM3\portmacro.h
/*
这里cortex-M3支持前导0指令 __clz ,这个返回的是整数从最高位往最低位开始找,找到第一个为1的bit,然后返回找到1之前为bit0的位个数,例如二进制的 0x8000 0000,31bit为1,前导这个数返回0;而0x4000 0000的bit31为0,bit30为1,那前导这个返回的就是1.
我们这里 uxTopReadyPriority的值为0x30,前导0后返回的应该是26,所以返回的 uxTopPriority为5。
*/
#define portGET_HIGHEST_PRIORITY( uxTopPriority, uxReadyPriorities ) uxTopPriority = ( 31UL - ( uint32_t ) __clz( ( uxReadyPriorities ) ) )
/* 前面得到 uxTopPriority 为 5,代表当前就绪表里优先级最高的是5 */
/* pxReadyTasksLists[ uxTopPriority ] 则是优先级为5的就绪链表 */
#define listGET_OWNER_OF_NEXT_ENTRY( pxTCB, pxList ) \
{ \
List_t * const pxConstList = ( pxList ); \
/* 找到链表的索引指针指向的链表节点 */ \
( pxConstList )->pxIndex = ( pxConstList )->pxIndex->pxNext; \
/* 如果当前指向的是链表头(即list_t结构本身,没有意义)则指找链表头的下一个指向的节点 */ \
if( ( void * ) ( pxConstList )->pxIndex == ( void * ) &( ( pxConstList )->xListEnd ) ) \
{ \
( pxConstList )->pxIndex = ( pxConstList )->pxIndex->pxNext; \
}
/* 根据前面分析,这里找到的( pxConstList )->pxIndex 就是前面线程2的tcb里的xStateListItem */ \
/* pvOwner指向TCB本身 */ \
( pxTCB ) = ( pxConstList )->pxIndex->pvOwner; \
}补充:
在xPortPendSVHandler 这里,有个疑问,cortex-M3在中断产生的时候不会对 r4~r11做压栈,所以需要手动入栈。那中断函数从c翻译成汇编的时候为什么不全部都加上这个动作?
这里在《cortex-M3权威指南》里看到如下内容。

**这里个人的理解是:**如果中断函数全部都需要做这个动作,一个是降低了中断的效率,另外编译出一些没用的代码,除非确实有需要编译器就会做这个事情,例如c写的中断函数里调用了很复杂的函数,且使用了较多的局部变量,那编译器则可能会根据实际在中断函数进来的时候压了部分r4~r11寄存器。如果说中断函数很简单,根本不需要用到r4~r11寄存器,那中断函数进来再返回到用户线程的时候也没影响因为它们的值还是入中断之前的值。然后调度这里,一个是不知道 vTaskSwitchContext 会翻译成什么样,可能破坏了原来的r4~r11的内容,也不知道原来线程是否复杂到会使用用到 r4~r11,保险起见,进来之前都对原来线程的 r4~r11 做一个保存。如果不保存的话,例如线程1很复杂 编译后用到了r4~r11,这时候产生一次调度切换到了线程2,刚好线程2也很复杂 也用到了r4~r11,那cpu再回到线程1手上的时候,局部变量就被破坏了,所以最保险的就是每次进来都手动压r4~r11入栈,既然有入栈了每次到切下文的时候也需要做一个出栈。
本文介绍了freertos接管mcu的cpu和freertos的线程切换的过程,具体的要点理解了后去看其他rtos也可以举一反三,根据这些要点去看它们是如何实现的。