在这个数据如潮的时代,SQL 已远远超越了简单的查询语言范畴,它已成为数据分析和决策制定的基石,成为撬动企业智慧决策的关键杠杆。SQL 的编写和执行效率直接关系到数据处理的速度和分析结果的深度,对企业洞察市场动态、优化业务流程、提升决策质量起着至关重要的作用。
如何在浩瀚的数据海洋中快速捕捞到价值信息,考验着每一个企业的数据处理能力。正是洞察到这一核心需求,数栈通过将前沿的人工智能技术融入到我们的大数据开发套件中,彻底革新了 SQL 开发的传统模式。
最新发布的「数栈V6.2」,以"Data+AI"为核心理念,不仅仅提供了强大的大数据平台基础服务,更通过与AI技术的深度融合,为企业提供数据智能分析与应用。这意味着企业可以通过数栈平台,实现行业内容体系的集成、灵活便捷的数据洞察、极速分析引擎的计算以及数据安全的全方位管控。
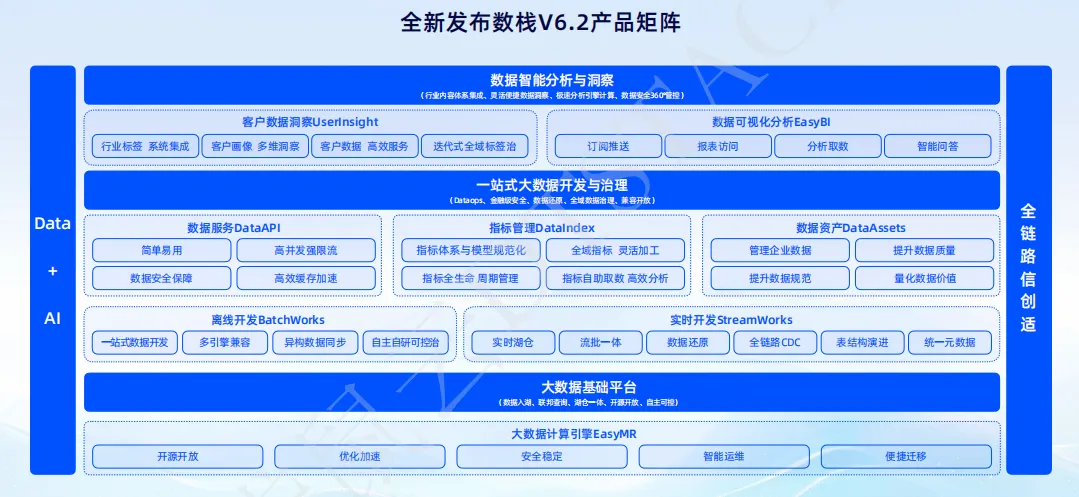
下文将为大家详细讲述 AI 在数栈中的应用。
AI 在数栈应用中的优势
AI 在数栈领域的应用可归纳为三个核心优势:轻量化、专业化和模块化。
· 轻量化:AI 通过精简算法和降低计算需求,确保在资源受限的数栈环境中也能高效运行,实现效能与资源的最佳平衡
· 专业化:针对特定数栈任务进行优化的 AI 模型,提供更加精准的分析和预测,满足不同行业的特定需求,助力企业实现更深层次的数据洞察
· 模块化:数栈采用模块化设计,不仅便于集成和扩展,还支持灵活定制与快速迭代,确保了适应多变的数栈应用场景的能力
Text to SQL
Text to SQL是一种通过自然语言处理(NLP)和机器学习(ML)将用户的自然语言查询自动转换为 SQL 查询语句的技术。这项技术使即使不具备 SQL 知识的用户也能够从数据库中获取所需的数据。
数栈目前支持对接开源或闭源模型,实现复杂场景下的 Text to SQL 功能,并支持关联平台的表结构作为 prompt,可更准确地生成 SQL 语句,提升开发效率。
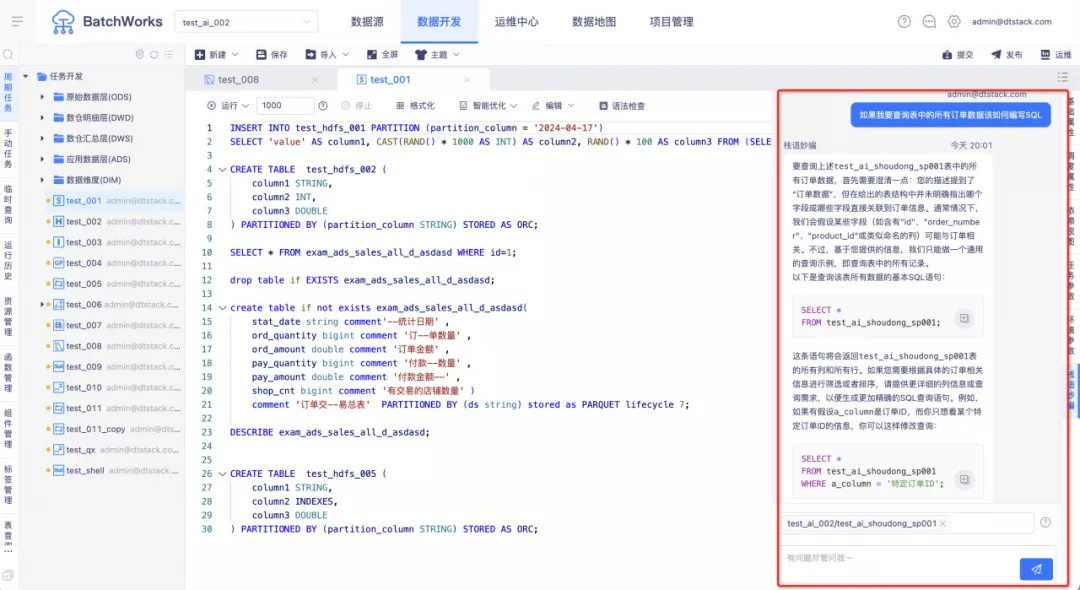
随着数栈模型调优能力和应用能力的不断发展,Text to SQL 的准确性和一致性正不断迈上新台阶,其应用范围亦日益广泛。目前,已经支持了 Hive、Spark、MySQL、Oracle、StarRocks、Doris 等计算引擎的 Test to SQL 能力。
未来,数栈的 Text to SQL 会更好地理解上下文和处理复杂查询,使人与数据的互动更加自然和高效。
智能调优
在现代软件开发中,代码质量和开发效率是关键因素。智能调优功能利用 AI 智能技术,自动化和智能化地提升代码的质量和性能,使开发过程更加高效和可靠。在数据开发中,数栈的 IDE 提供了三大智能功能:
· 智能优化:自动分析和优化用户编写的代码,提高代码执行效率和质量
· 智能注释:自动生成详细注释,帮助开发者和团队成员更容易理解代码逻辑和意图
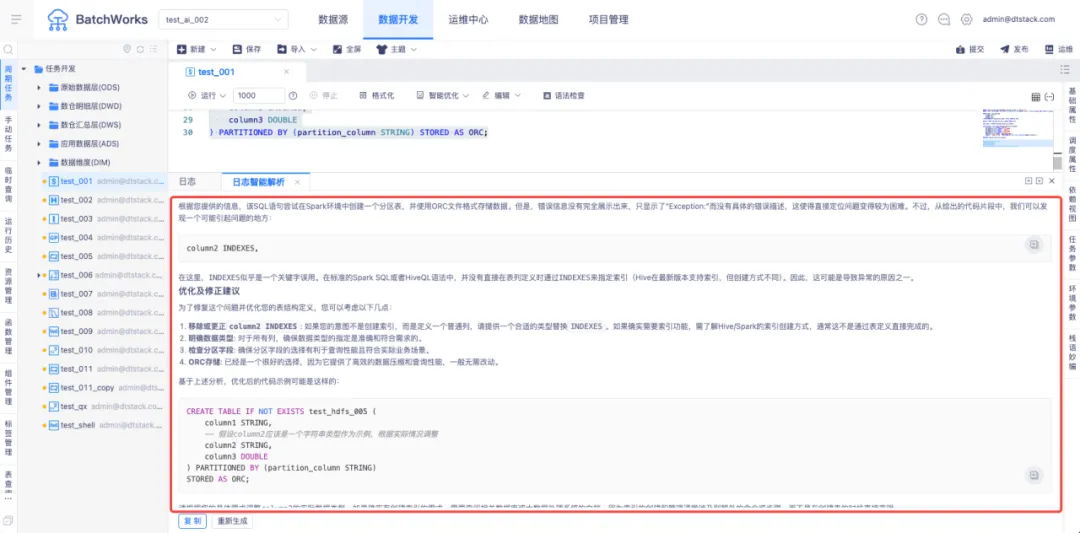
· 智能解释:实时解释代码功能,提供语法和逻辑的详细说明,方便开发者学习和调试

此外,编辑器还支持原代码与优化后代码的对比,方便开发者审阅和修改优化结果,确保代码质量。这些功能的结合,使得数据开发的效率有了质的飞跃,大幅提升了开发者的生产力和代码的可靠性。
日志智能解析
在数据开发和运维中,日志解析和分析是关键环节。日志智能解析功能通过机器学习和自然语言处理技术,自动解析各种类型的日志文件,提取关键信息,并进行结构化和语义化分析,帮助用户更高效地从日志中获取有价值的信息。
数栈目前已经支持了 Hive、Spark、数据同步、Python、Shell、MySQL、Oracle、StarRocks、Doris 等任务类型的日志智能解析能力。降低了数据开发同学开发复杂任务的门槛,极大提升了日志解析和异常检测的准确性和全面性。
指标归因分析
在数据驱动的决策过程中,理解各类业务指标的变化原因至关重要。数栈的指标归因分析功能通过 AI 和大模型技术,自动分析各类业务数据,识别影响指标变化的主要因素,并提供可操作的洞察,帮助企业更精确地制定策略和优化业务流程。
其主要功能包括:因果关系分析、多维度分析、自动化报告生成、实时监控、可视化分析。
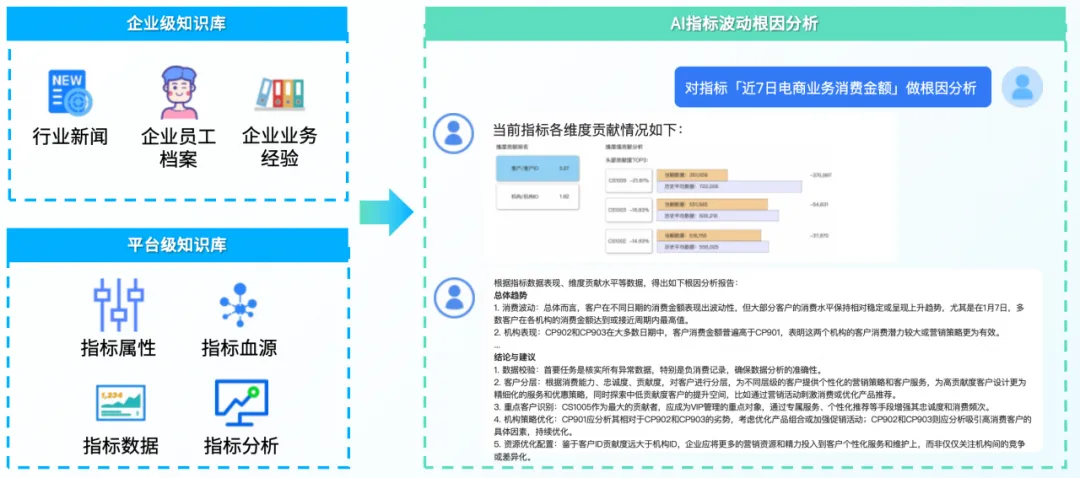
随着数栈 AI 技术和模型能力的增强,指标归因分析功能更加智能化和精准化。未来的发展方向包括:
· 增强的自学习能力:通过不断学习和积累经验,系统能够更加准确地进行归因分析
· 深度语义理解:提高对业务逻辑和数据语义的理解,提供更有针对性的分析结果
· 跨领域支持:扩展对更多业务领域和应用场景的支持,满足多样化的分析需求
· 智能预测:结合预测分析技术,不仅分析过去的指标变化,还能预测未来趋势和变化原因
通过指标归因分析功能,企业能够更加精准地理解业务指标变化的原因,制定科学的策略和措施,提升业务决策的质量和效率。
总结
数栈通过与 AI 技术的深度融入,致力于为企业数据管理与决策分析带来了改变。在这个数据无处不在的时代,数栈希望和各位一起迈向一个更智能、更高效的数据应用新纪元。
《行业指标体系白皮书》下载地址:https://www.dtstack.com/resources/1057?src=szsm
《数栈产品白皮书》下载地址:https://www.dtstack.com/resources/1004?src=szsm
《数据治理行业实践白皮书》下载地址:https://www.dtstack.com/resources/1001?src=szsm
想了解或咨询更多有关大数据产品、行业解决方案、客户案例的朋友,浏览袋鼠云官网:https://www.dtstack.com/?src=szcsdn