背景
MongoDB 从 3.0版本引入 WiredTiger 存储引擎之后开始支持事务,MongoDB 3.6之前的版本只能支持单文档的事务,从 MongoDB 4.0版本开始支持复制集部署模式下的事务,从 MongoDB 4.2版本开始支持分片集群中的事务。
根据官方文档介绍:
- 从 MongoDB 4.2 开始,分布式事务和多文档事务在 MongoDB 中是一个意思。分布式事务是指分片集群和副本集上的多文档事务。在大多数情况下,多文档事务比单文档写入会产生更大的性能成本。对于大部分场景来说, 适当地对数据进行建模可以最大限度地减少对多文档事务的需求。
- 从 MongoDB 4.2 开始,多文档事务支持副本集和分片集群,其中:主节点使用 WiredTiger 存储引擎,同时从节点使用 WiredTiger 存储引擎或 In-Memory 存储引擎。在 MongoDB 4.0 中,只有使用 WiredTiger 存储引擎的副本集支持事务。在 MongoDB 4.2 及更早版本中,你无法在事务中创建集合。从 MongoDB 4.4 开始,您可以在事务中创建集合和索引。
MongoDB的事务
与关系型数据库一样,MongoDB 事务同样具有 ACID 特性:
- 原子性(Atomicity):事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部完成,要么完全不起作用。
- 一致性(Consistency):执行事务前后,数据保持一致,例如转账业务中,无论事务是否成功,转账者和收款人的总额应该是不变的。
- 隔离性(Isolation):并发访问数据库时,一个用户的事务不被其他事务所干扰,各并发事务之间数据库是独立的。WiredTiger 存储引擎支持读未提交( read-uncommitted )、读已提交( read-committed )和快照( snapshot )隔离,MongoDB 启动时默认选快照隔离。在不同隔离级别下,一个事务的生命周期内,可能出现脏读、不可重复读、幻读等现象。
- 持久性(Durability):一个事务被提交之后。它对数据库中数据的改变是持久的,即使数据库发生故障也不应该对其有任何影响。
在不同隔离级别下,一个事务的生命周期内,可能出现脏读、不可重复读、幻读等现象。
对于不同的现象就不过多介绍了。
WiredTiger 存储引擎支持 read-uncommitted 、read-committed 和 snapshot3 种事务隔离级别,MongoDB 启动时默认选择 snapshot 隔离。
MVCC机制
要实现事务之间的并发操作,做到snapshot隔离,可以使用锁机制或 MVCC 控制等。对于 WiredTiger 来说,使用 MVCC 控制来实现并发操作,相较于其他锁机制的并发,MVCC 实现的是一种乐观并发机制。
事务开始时,系统会创建一个快照,从已提交的事务中获取行版本数据,如果行版本数据标识的事务尚未提交,则从更早的事务中获取已提交的行版本数据作为其事务开始时的值。
通过事务可以看到其他还未提交的事务修改的行版本数据,但不会看到事务 id 大于 snap_max 的事务修改的数据。
假设有ABCD四个事务对同一条库存记录进行操作。
- A事务开始拿到快照数据,行版本是0记录为Q,且读到库存是2,提交时检查行版本0==Q,提交成功
- B事务开始,拿到行版本0记录为Q,读到库存是2,扣除库存为1,提交时检查行版本0<Q+1,提交成功,修改库存为1,行版本为1
- C事务开始,读到库存均为1,行版本都是1
- D事务在C还未提交时,也开始执行,也拿到快照数据,库存为1,行版本是1
此时,如果CD俩个事务都是读库存,那最后提交都可成功。如果有一个事务进行了写操作,例如C事务执行了写,扣除库存为0,先触发提交时冲突检测,此时行版本1<Q+1,提交成功,售卖成功,记录行版本为2,库存为0。
D提交时,发现行版本数2>=Q+1,以防止对过期数据的修改,保证数据的一致性,会提交失败,重新执行事务,拿到库存为0,此时D事务返回的结果,便是库存不足。
事务日志
Journal 是一种 WAL( Write Ahead Log )事务日志,目的是实现事务提交层面的数据持久化。
Journal 持久化的对象不是修改的数据,而是修改的动作,以日志形式先保存到事务日志缓存中,再根据相应的配置按一定的周期,将缓存中的日志数据写入日志文件中。
事务日志落盘的规则如下。
(1)按时间周期落盘。
在默认情况下,以50毫秒为周期,将内存中的事务日志同步到磁盘中的日志文件。
(2)提交写操作时强制同步落盘。
当设置写操作的写关注为 j:true 时,强制将此写操作的事务日志同步到磁盘中的日志文件。
(3)事务日志文件的大小达到100MB。
MongoDB 一致性模型设计
在学术中,对一致性模型有一些标准的划分和定义,比如我们听到过的线性一致性、强一致性、因果一致性、最终一致性等都在这个标准当中,MongoDB 的一致性模型设计自然也不能脱离这个标准。
MongoDB选择了三种模型作为实现:线性一致性、因果一致性、最终一致性。至于最终一致性就不过多概述,靠日志做主从同步就可做到,我们主要学习前俩个。
可调一致性模型功能接口
在 MongoDB 中,writeConcern 是针对写操作的配置,readConcern 是针对读操作的配置,而且都支持在单操作粒度上调整这些配置,使用起来非常的灵活。writeConcern 和 readConcern 互相配合,共同构成了 MongoDB 可调一致性模型的对外功能接口。
writeConcern
针对写操作的 writeConcern,写操作改变了数据库的状态,才有了读操作的一致性问题。
MongoDB writeConcern 包含如下选项,
{ w: <value>, j: <boolean>, wtimeout: <number> }- w,指定了这次的写操作需要复制并应用到多少个副本集成员才能返回成功,可以为数字或 "majority"。w:0 时比较特殊 ,即客户端不需要收到任何有关写操作是否执行成功的确认,具有最高性能。w: majority 需要收到多数派节点(含 Primary)关于操作执行成功的确认,具体个数由 MongoDB 根据副本集配置自动得出。
- j,额外要求节点回复确认时,写操作对应的修改已经被持久化到存储引擎日志中。
- wtimeout,Primary 节点在等待足够数量的确认时的超时时间,超时返回错误,但并不代表写操作已经执行失败。
从上面的定义我们可以看出,writeConcern 唯一关心的就是写操作的持久性,这个持久性不仅仅包含由 j 决定、传统的单机数据库层面的持久性,更重要的是包含了由 w 决定、整个副本集(Cluster)层面的持久性。w 决定了当副本集发生重新选主时,已经返回写成功的修改是否会"丢失",在 MongoDB 中,我们称之为被回滚。w 值越大,对客户端来说,数据的持久性保证越强,写操作的延迟越大。
readConcern
在 MongoDB 4.2 中包含 5 种 readConcern 级别,我们先来看前 4 种:「local」, 「available」, 「majority」, 「linearizable」,它们对一致性的承诺依次由弱到强。其中,「linearizable」即对应我们前面提到的标准一致性模型中的线性一致性,另外 3 种 readConcern 级别代表了 MongoDB 在最终一致性模型下,对延迟和一致性的取舍。
下面我们结合一个三节点副本集复制架构图,来简要说明这几个 readConcern 级别的含义。在这个图中,oplog 代表了MongoDB 的复制日志,类似于 MySQL 中的 binlog,复制日志上最新的x=,表示了节点的复制进度。
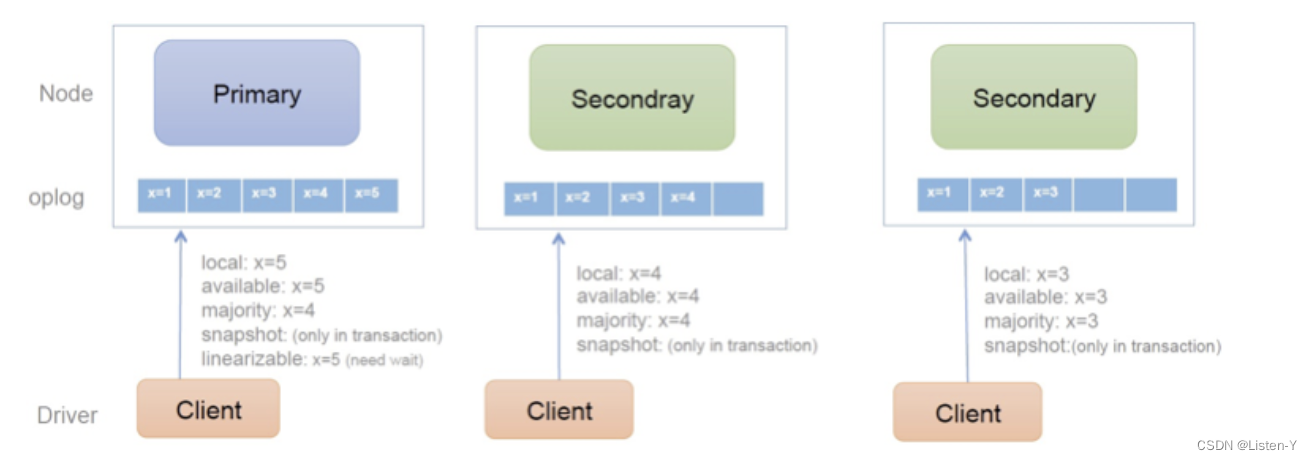
- local/available:local 和 available 的语义基本一致,都是读操作直接读取本地最新的数据。但是,available 使用在 MongoDB 分片集群场景下,含特殊语义(为了保证性能,可以返回孤儿文档),这个特殊语义和本文的主题关联不大,所以后面我们只讨论 local readConcern。在这个级别下,发生重新选主时,已经读到的数据可能会被回滚掉。
- majority:读取大部分提交后「majority committed」的数据,可以保证读取的数据不会被回滚,但是并不能保证读到本地最新的数据。比如,对于上图中的 Primary 节点读,虽然 x=5 已经是最新的已提交值,但是由于不是「majority committed」,所以当读操作使用 majority readConcern 时,只返回x=4。
- linearizable:承诺线性一致性,即,既保证能读取到最新的数据,也保证读到数据不会被回滚。前面我们说了,线性一致性在真实系统中很难实现,MongoDB 在这里采用了一个相当简化的设计,当读操作指定 linearizable readConcern level 时,读操作只能读取 Primary 节点,而考虑到写操作也只能发生在 Primary,相当于 MongoDB 的线性一致性承诺被限定在了单机环境下,而非分布式环境,实现上自然就简单很多。考虑到会有重新选主的情况,MongoDB 在这个 readConcern level 下唯一需要解决的问题就是,确保每次读发生在真正的 Primary 节点上,解决这个问题是以增加读延迟为代价的。
那readConcern和writeConcern的关系是什么呢?
在分布式系统中,当我们讨论一致性的时候,通常指的是读操作对数据的关注,那为什么在 MongoDB 中我们还要单独讨论 writeConcern 呢?从一致性承诺的角度来看,writeConcern 从如下两方面会对 readConcern 产生影响。
-
「majority readConcern」读取的数据需要是以「majority writeConcern」写入且持久化到日志中,才能提供真正的「线性一致性」语义。
-
「linearizable readConcern」读取的数据需要是以「majority writeConcern」写入且持久化到日志中,才能提供真正的「线性一致性」语义。考虑如下情况,数据写入到 majority 节点后,没有在日志中持久化,当 majority 节点发生重启恢复,那么之前使用 「linearizable readConcern」读取到的数据就可能丢失,显然和「线性一致性」的语义不相符。在 MongoDB 中,writeConcernMajorityJournalDefault 参数控制了,当写操作指定 「majority writeConcern」的时候,是否保证写操作在日志中持久化,该参数默认为 true。另外一种情况是,写操作持久化到了日志中,但是没有复制到 majority 节点,在重新选主后,同样可能会发生数据丢失,违背一致性承诺。
所以,writeConcern 虽然只关注了写入数据的持久化程度,但是作为读操作的数据来源,也间接的也影响了 MongoDB 对读操作的一致性承诺。
实际业务中的应用
统计数据来自于 MongoDB 自己的 Atlas 云服务中用户 Driver 上报的数据,统计样本在百亿量级,所以准确性是可以保证的,从数据中我们可以分析出如下结论:
- 大部分的用户实际上只是单纯的使用默认值
- 在读取数据时,99% 以上的用户都只关心能否尽可能快的读取数据,即使用 local readConcern
- 在写入数据时,虽然大部分用户也只要求写操作在本地写成功即可,但仍然有不小的比例使用了 majority writeConcern(16%,远高于使用 majority readConcern 的比例),因为写操作被回滚对用户来说通常都是更影响体验的。
此外,MongoDB 的默认配置({w:1} writeConcern, local readConcern)都是更倾向于保护 延迟 的,主要是基于这样的一个事实:主备切换事件发生的概率比较低,即使发生了丢数据的概率也不大。
MongoDB 因果一致性模型功能接口
相比于 writeConcern/readConcern 构建的可调一致性模型,MongoDB 的因果一致性模型是另外一块相对比较独立的实现,有自己专门的功能接口。MongoDB 的因果一致性是借助于客户端的 causally consistent session (因果一致性会话)来实现的,causally consistent session 可以理解为,维护一系列存在因果关系的读写操作在同一个会话内执行。
针对 causally consistent session,我们可以看一个简单的例子,比如现在有一个订单集合 orders,用于存储用户的订单信息,为了扩展读流量,客户端采用主库写入从库读取的方式,用户希望自己在提交订单之后总是能够读取到最新的订单信息(Read Your Write),为了满足这个条件,客户端就可以通过 causally consistent session 来实现这个目的。
关于分布式系统中的事件如何定序的论述,最有影响力的当属 Leslie Lamport 的这篇 《 Time, Clocks, and the
Ordering of Events in a Distributed System》,其中提到了一种 Logical Clock时钟
用来确定不同事件的全序,后人也把它称为 Lamport Clock。
基于 ClusterTime 混合逻辑时钟机制
如果要实现 Causal Consistency(因果一致) 的承诺,显然我们需要 Client 也知道写操作在主节点执行完后对应的 ClusterTime。
所以 MongoDB 在请求的回复中除了带上 clusterTIme 用于帮助推进混合逻辑时钟,还会带上另外一个字段 operationTime 用来表明这个请求包含的操作对应的 ClusterTime,operationTime 在 MongoDB 中也被称之为 「Stable ClusterTime」,它的准确含义是操作执行完成时 ,当前最新的 Oplog 时间戳(OpTime)。所以对于写操作来说,operationTime 就是这个写操作本身对应的 Oplog 的 OpTime,而对于读操作,取决于并发的写操作的执行情况。
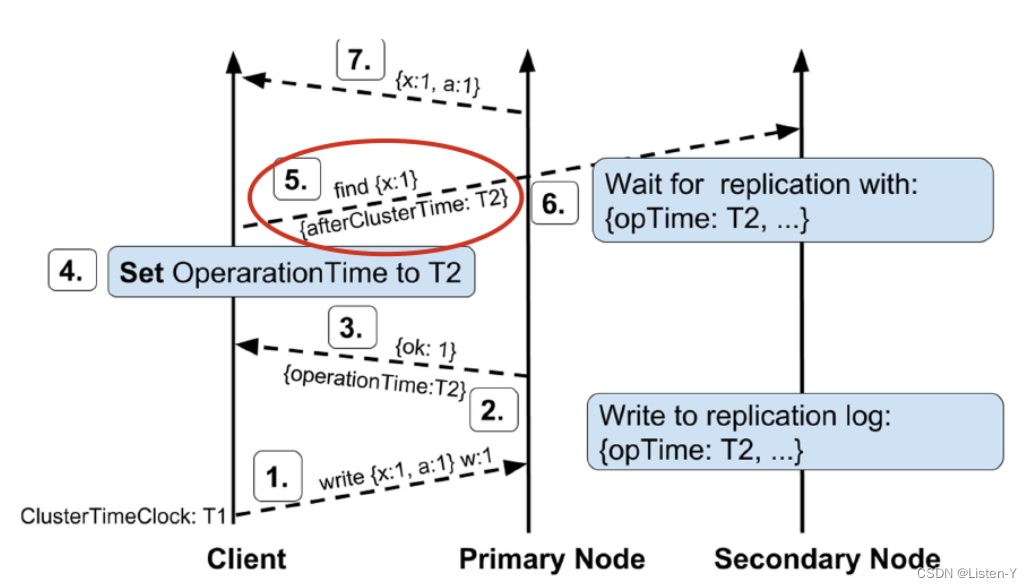
Client 在收到这个 operationTime 后,如果要实现因果一致,就会在发送给其他节点的请求的 afterClusterTime 字段中带上这个 operationTime ,其他节点在处理这个请求时,只会读取 afterClusterTime 之后的数据状态,这个过程是通过显式的等待同步位点推进来实现的,等待的逻辑和前面提到的 speculative "majority" readConcern 实现类似。上图是 MongoDB 副本集实现「Read Your Own Write」的基本流程。
如果是在分片集群形态下,由于混合逻辑时钟的推进依赖于各个参与方:客户端、proxy、主节点、从节点的交互,所以会暂时出现不同server间的逻辑时钟不一致的情况,所以在这个架构下,我们需要解决某个分片的逻辑时钟滞后于 afterClusterTime 而且一直没有新的写入,导致请求持续被阻塞的问题。MongoDB 的做法是,在这种情况,系统内部会监控识别,主动触发主节点noop操作,显式的写一条 noop 操作到 oplog 中,相当于强制把这个分片的数据状态推进到 afterClusterTime 之后,从而确保操作能够尽快返回,同时也符合因果一致性的要求。故称为混合逻辑时钟。