1. 检查点的描述
- 为了便于数据库系统的复原和逻辑恢复,数据库服务器生成的一致性标志点,称为检查点,其是建立在数据库系统的已知和一致状态时日志中的某个时间点
- 检查点的目的在于定期将逻辑日志中的重新启动点向前移动
-
- 如果存在检查点,数据库只需要完成检查点之后的逻辑日志的恢复即可完成数据库的重启和恢复
- 如果不存在检查点,则需要重新读取自数据库重启以来的所有逻辑日志才可完成数据库的重启和恢复
- 数据库服务为为逻辑日志空间的每个范围生成至少一个自动检查点,保证可以开始快速恢复的检查点存在
- 检查点在infomix9.2版本中增加了fuzzy checkpoint的概念
-
- 检查点分为full checkpoint和fuzzy checkpoint两种
- full checkpoint会把所有的脏页刷新到磁盘
- fuzzy checkpoint不会刷新所有页
- 在informix11.5版本中又取消了fuzzy checkpoint
- 逻辑日志是循环的,数据库保证在每个循环周期内,数据库保证至少做一次checkpoint,当下一个日志包含最后的checkpoint时(代表次周期只做了一次检查点),数据库会做一次检查点操作
2. 检查点的作用
- 数据从磁盘读取到缓冲池中后被修改后,内存中的数据和缓冲池中的数据会出现差异,检查点会将共享内存缓冲池中的脏页数据全部刷新到磁盘上,使所修改的数据固化到硬盘上
- 检查点除了刷新数据到磁盘,还起到了有助恢复的作用,数据库down机恢复时,会找到最后一个检查点的位置,然后动态恢复检查点之后的逻辑日志,如果没有检查点,需要恢复所有的逻辑日志,需要的时间会较长
3. 检查点针对的数据
- checkpoint时,内存中的LRU队列会存在两种数据
-
- 一种是从磁盘读出来没有发生更改的数据,FLRU队列
- 一种是从磁盘读出来后发生了更改的数据,MLRU队列
- 检查点刷新的数据只针对MLRU队列的数据,即只需要将内存中修改的数据同步到磁盘,而不需要将所有的信息写到磁盘,如果只有一个page脏页,则只同步一个page页到磁盘,其他page不需要
- 写磁盘的脏页数据虽然同步到了磁盘,但是仍然在内存中存在
4. 检查点的种类
- 阻塞检查点
-
- 改检查点操作时会加上数据库级别的锁,他是一个完全检查点,必须保证事务的一致性
- 非阻塞检查点
-
- 模糊检查点,这些检查点的频率可以通过应用程序进行调整
- 非阻塞检查点,不需要数据库级别的锁,因此在检查点正在进行时,多个应用程序可以在同一个数据库上异步提交或回滚事务,他是一个不完全检查点不必保证事务的一致性
- 非阻塞检查点不是说全部过程都不阻塞,其是会存在一段阻塞的过程:检查点执行之前,需要在阻塞状态下等待用户离开critical section,然后将系统恢复需要的逻辑日志、物理日志等刷新,此阶段为阻塞阶段
5. 阻塞的种类
|--------------|----------------------------------------------------------------------------------|-------------|
| 事件 | 描述 | 是否阻塞 |
| 管理类 | 1.dbspace的创建、删除和改名 | 阻塞 |
| 管理类 | 2.增加或删除chunk | 阻塞 |
| 管理类 | 3.增加或删除一个逻辑日志文件 | 阻塞 |
| 管理类 | 4.修改物理日志的位置和大小 | 阻塞 |
| 管理类 | 5.在不记日志的分区上执行shrink(碎片整理)操作 | 阻塞 |
| 管理类 | 6.打开或关闭镜像 | 阻塞 |
| 备份 | 假备份 | 阻塞 |
| 备份 | 开始归档时 | 阻塞 |
| 备份 | 物理恢复结束之后 | 阻塞 |
| CDR(数据库同步程序) | 第一次启动ER的子系统或者所有参与者被删除之后重启了复制 | 阻塞 |
| 升级转换/升级回退 | 在检查转换结束和真正的磁盘结构转换开始之前会执行一次checkpoint;如果升级失败,回退成功之后会执行一次checkpoint | 阻塞 |
| 高可用性 | 1.增加一个新的RSS或者SDS系节点 1.secondary server被升级为主服务器 | 根据场景进行区分 |
| HDR | 1.服务器的模式发生了变化 2.HDR安装结束之后的第一次传输 3.primary或secondary servers上潜在的物理日志溢出 | 情景不同,结果不同 |
| 恢复点 | 恢复开始和结束之后都会执行checkpoint,当设置了CONVERSION_GUARD,并且指定了RESTORE_POINT_DIR配置参数时,恢复点才会生效 | 阻塞 |
| Pload | 以快速模式启动Pload(HPL) | 阻塞 |
| 恢复 | 快速恢复开始时 | 阻塞 |
| 重组 | 在线创建索引 碎片整理 | 阻塞 |
| 用户操作 | 用户执行checkpoint | 阻塞(除外部备份期间) |
|------------|------------------------------------------------------------------------------------------------------------------------------------------------------|------|
| 事件 | 描述 | 是否阻塞 |
| CKPTINTVL | 当CKPTINTVL间隔时间到了之后,数据库会检查是否需要做checkpoint,满足下列条件,需要做: * 当MLRU队列中的缓冲页达到了BUFFERPOOL中定义的lru_max_dirty参数后 * 清页线索过于繁忙。即一个用户需要获得一个可用的缓冲页,但是所有的缓冲页的指针都在MLRU内 | 不阻塞 |
| LongTX | 长事务:发现长事务,且事务没有停止,会执行一个checkpoint来停止这个长事务 回滚过程中,如果长事务被终止,当长事务仍然没有回滚结束,此时执行一个checkpoint | 不阻塞 |
| Llog | 逻辑日志用完 | 不阻塞 |
| Misc | 因IO错误导致dbspace或chunk处于PD状态 | 不阻塞 |
| 物理日志 | 物理日志所处条件: 1.物理日志写到75% 2.物理日志加上脏页的容量大于物理日志总空间的90% | 不阻塞 |
| RTO | 定义最长的数据恢复时间,正常操作系统崩溃,重启的时间不会超过TRO_SERVER_RESTART配置的时间 | 不阻塞 |
| stamp wrap | 如果新的检查点时间戳在最后一个检查点之前,会触发另外一个检查点 | 不阻塞 |
| startup | 数据库穷的那个 | 不阻塞 |
| 解压 | 在不及日志的表或者数据库上执行解压操作 | 不阻塞 |
6. 检查点的场景
- 阻塞检查点:数据库空间添加到服务器或执行数据库备份时,检查点将出现
- 非阻塞检查点:资源限制发生时,如逻辑日志空间的每个范围需要检查点来保证日志具有快速开始恢复的检查点;如数据库服务器将在物理日志达到总大小的75%时触发检查点,以避免物理日志移除,这种检查点不会阻塞事务
-
- 如果检查点期间,资源将要耗尽,则会为了保证有足够的资源保证检查点的完成,则会阻塞其他事务
- 如果事务被阻塞,则服务器会更频繁的触发检查点,以避免检查点处理期间的事务阻塞
- 自动检查点引起数据库更频繁的触发检查点,以避免事务阻塞,自动检查点尝试监视系统活动和资源使用情况(物理和逻辑日志使用情况以及缓冲池脏的程度),以能够及时触发检查点,这样检查点的处理就可在物理日志或逻辑日志耗尽前完成、3
7. 检查点的参数
- auto_ckpts:配置参数设置启动时启用或禁用自动检查点
- RTO_SERVER_RESTART:配置参数可指定快速恢复需要的时间
-
- 配置此参数将忽略参数CKPTINTVL
- 此参数配置后,数据库服务器将会监视物理日志和逻辑日志使用情况,以估计快速恢复的持续时间。如果服务器估计快速恢复将超出RTO_SERVER_RESTART时间,将会触发检查点
- RTO_SERVER_RESTART指定的是目标时间量,不能是保证的时间量
8. 检查点的执行过程
- 第一步:检查点执行开始时关于用户线索的要求:
-
- 检查点发生时,会检查所有数据库线索的状态,而此时数据库线索(用户执行sql的进程)的状态可以分为三种:将要执行、执行中和执行结束
- 针对执行中的线索,根据其执行过程的节点位置将会划分出检查点执行的两种行为,而针对线索的某部分节点我们称之为关键部分代码,根据线索是否进入到关键部分代码,检查点的两种行为如下:
-
-
- 线索还没有进入关键代码部分的执行,此时检查点可以阻塞线程的后续执行
- 如果线索执行节点进入了关键部分代码,则检查点需要等待线索执行完成后再进行检查点
-
-
- 关键部分代码的描述
-
-
- 关键部分的代码主要是做磁盘的更新,为了保证数据物理的一致性,所以针对这部分要么全部完成,要么全部不完成
- 关键部分的线索会持有完成数据修改所需要的共享内存资源,而针对这部分资源,做checkpoint操作时,必须获得这部分共享内存资源,所以检查点执行时要求关键部分代码中没有用户线索在执行
-
-
- checkpoint会等待所有进入关键部分代码的用户线索执行完毕释放资源会,才会继续执行,将缓冲池的数据同步到磁盘
- 第二步:将物理日志缓冲刷新到物理日志文件
-
- 当没有用户线索处于关键部分代码中,检查点将继续执行
- 清页线索会把物理日志缓冲中的信息刷新到物理日志文件中

- 第三步:将缓冲池中的所有脏页写入到磁盘,这一步被称之为chunk write,仅需要刷新脏页,不需要刷新所有页
- 第四步:将检查点的信息写入到几个关键文件中
-
- 清页线索会在逻辑日志中写一个checkpoint记录,他提供了一个系统失败之后的一个恢复点
- 清页线索还会在rootdbs的保留页中(page_1CKPT和page_2CKPT)进行更新状态
- 将checkpoint完成的记录写到消息日志文件中
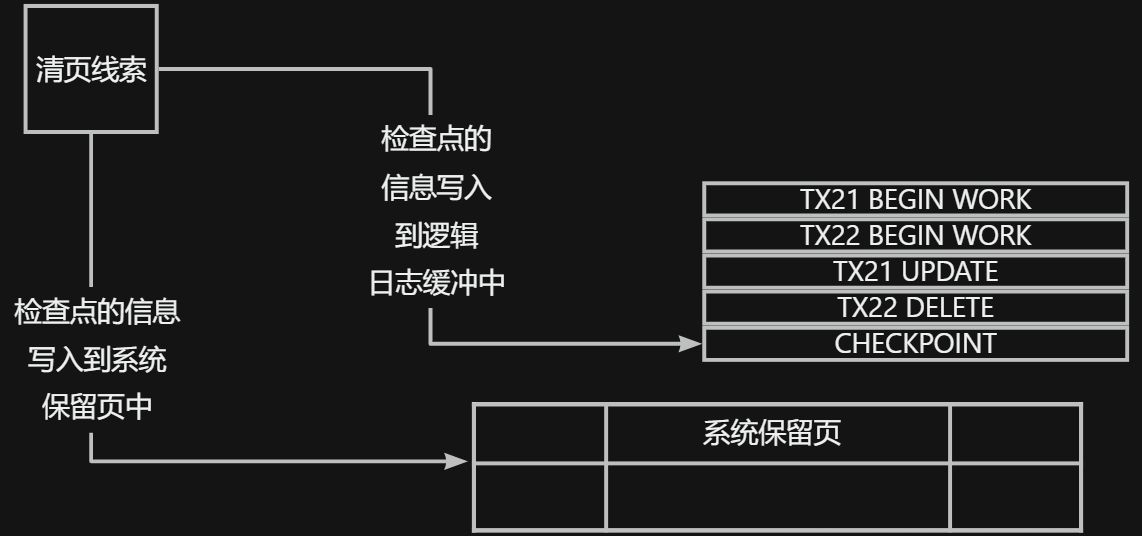
- 第五步:将逻辑日志缓冲区的内容刷新到逻辑日志文件中
- 第六步:逻辑上将物理日志文件清空
-
- 物理日志主要是数据库异常崩溃恢复时,可以在此基础上进行恢复,防止块断裂问题,所以检查点完成后,之前的物理日志已经失效了
- 对于已经失效的物理日志,gbase8s采用的是逻辑删除:即checkpoint记录写到消息日志文件后,物理日志上的文件不会被移走(移动删除开销较大)。而是以在物理日志后面的地址作为新一轮物理日志的写入的开始地址,继续往后写,而物理日志使用完毕后,将会从物理日志文件开头进行覆盖写
- 可以把物理日志文件看成循环文件,没有起始点,没有结束点,每次checkpoint,物理日志的起始点都在变化
9. 非阻塞检查点的特殊说明
- 检查点分为阻塞检查点和非阻塞检查点,非阻塞检查点并不是完全不阻塞,其也会出现一部分阻塞时间,只是时间相比较会非常短暂
- 步骤如下:
-
- 检查点开始执行时,会阻塞新的线索进入到关键代码区域,等待进入到关键部分代码的线索离开
- 将缓存中的系统目录表信息写入到磁盘中
- 将物理、逻辑日志缓冲区刷新到日志文件中
- 将检查点写入到逻辑日志和消息日志文件中
- 完成上述步骤后,将不再阻塞新的线索进入到关键代码部分
- 将缓冲区中的脏页写入到磁盘中
- 结束检查点操作,在保留页中更新检查点记录,检查点完成
- 从上可知非阻塞检查点将会存在一段阻塞时间