2003年USENIX,出自谷歌,开启分布式大数据时代的三篇论文之一,作者是 Jeffrey 和 Sanjay,两位谷歌巨头。
Abstract
MapReduce 是一种变成模型,用于处理和生成大规模数据。用户指定 map 函数处理每一个 key/value 对来产生中间结果的 key/value 对;reduce 函数合并每一个相同中间 key 的 value。
这种编程风格能自动获得并行在大型集群上运行的便利。这套运行时系统则帮助用户接管来数据分片分发,机器通讯,节点失败等问题。无需用户了解并行分布式系统的知识就能利用好大型分布式系统。
1 Introduction
以往做大型分布式处理的时候,大家都是简单直白的方式开发实现。这往往要处理很多分布式的情况,比如数据划分,传输,失败节点处理等。这一大堆事情要求的技术复杂,而且反而淹没了最初的业务目的。
为了应对上述情况,开发了这套系统。受到 map reduce 这种函数式编程原语的启发。把大部分操作拆分成 map 阶段和 reduce 阶段,并且可以用户自定义的实现 map 函数和 reduce 函数,这样可以进行大规模并行计算,也能够用重新执行作为失败处理。
作者给出了这套系统的接口以及实现的细节。
2 Programming Model
整体计算的输入是一堆 key/value 对,产生的输出也是 key/value 对,用户使用 MapReduce 要实现两个函数:Map 和 Reduce。
Map 函数由用户开发,输入 kv 对,产生中间 kv 对。MapReduce 系统把中间 kv 对里有相同中间 key I 的 value 聚集到一起,然后传给 Reduce 函数。
Reduce 函数也有用户开发,接受 key I 和 这个 key 的 value 集合。Reduce 操作合并相同 key 下的所有 value,产生更少的 value。中间 value 是通过迭代器的方式支撑 Reduce 函数,因此能借助磁盘,处理超过内存大小的数据量。
2.1 Example
作者举例了一个单词统计的伪代码:
cpp
map(String key, String value):
// key: document name
// value: document contents
for each word w in value:
EmitIntermediate(w, "1");
reduce(String key, Iterator values):
// key: a word
// values: a list of counts
int result = 0;
for each v in values:
result += ParseInt(v);
Emit(AsString(result));用户写代码填充 MapReduce 的特定对象,比如特定的参数和自定义参数,然后调用 MapReduce,把这两个对象出给系统,就结束了。
2.2 Types
2.3 More Example
Distributed Grep(分布式正则):
map 函数对满足条件的数据行发射出去,作为输出,reduce 是个恒等函数,直接复制输入到输出
Count of URL Access Frequency:
map 函数处理处理访问日志,输出<url, 1>,reduce 函数把 url 相同的加起来,输出 <url, total count>
3 Implementation
对于定义的接口有很多不同的实现,但具体怎么实现要依赖运行服务的环境,是小内存机器、多核机器、大型网络机器等。作者给出了Google环境的设计目标:大集群普通机器,以太网交换机相连。双核x86 CPU,2~4G内存的Linux服务器...100Mbit/s 或 1Gbit/s 的网卡...一个集群几百上千台吧,节点故障比较常见...每个机器都有独立的 IDE 磁盘,上面部署着 GFS...用户会提交作业给调度系统,每个作业里面又包含几个任务,调度系统会调度到可用机器上执行。
3.1 Execution Overview
Map 操作分布式的在多机上执行,执行前,输入数据会被划分成 M 的子集。Reduce 操作也可以根据中间数据 key 划分成多个子集分布式的处理。这里的划分函数可以被用户指定,例如 hash(key) mod R。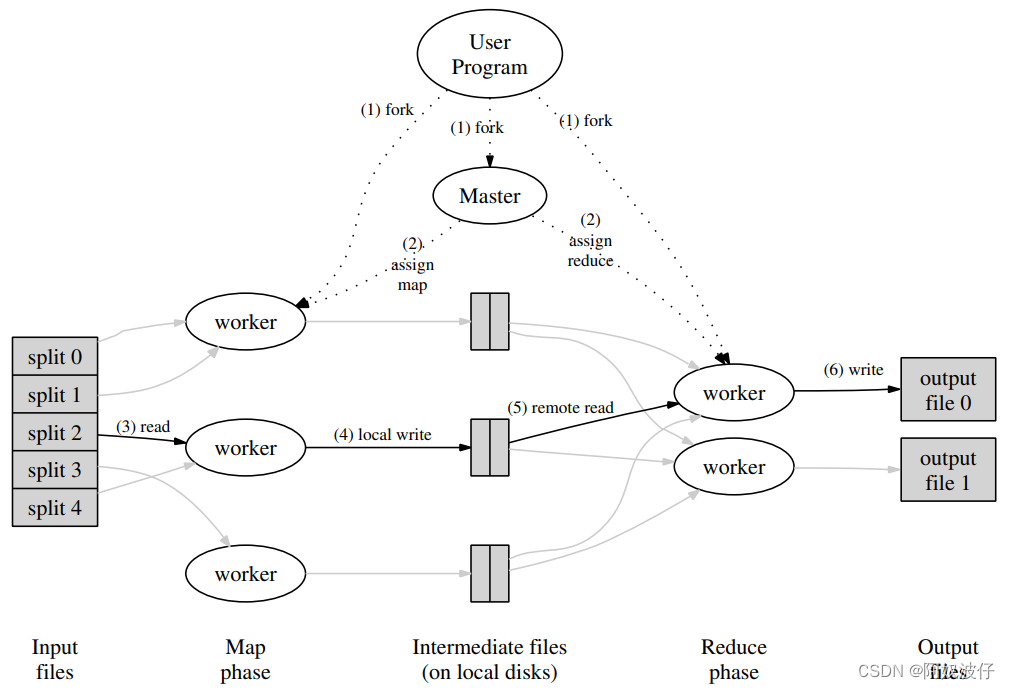
MapReduce 流程:
- 先将数据分片,16~64M一份,然后把程序拷贝到集群
- 其中的一份程序是 master,其余是 worker。共有 M 个 map 任务和 R 个 reduce任务。master 给空闲的 worker 分配 Map 任务或者 Reduce 任务
- map 任务的读取分片的数据,处理之后缓存在内存中
- 内存中的数据被划分函数拆分成 R 个部分,然后写入本地磁盘。接着上报本地磁盘中的位置给 master,master 会把这些地址传递给 reduce workers
- reduce worker 收到 master 通知的数据地址,就通过RPC读取 map worker 机器上的数据,读完后排序,使得所有想通 key 的数据在一起。因为会有很多不同 key 的任务给同一个 reduce worker
- reduce worker 把想通 key 和对应的 value 传递给 Reduce 函数,函数的输出结果存放到输出文件中,这里是个全局文件系统
- 所有 map 操作和 reduce 操作都执行完,MapReduce 调用返回用户程序
MapReduce 执行的结果是若干个输出文件,一个 reduce task 一个输出。通常用户不需要拼接这些输出,而是作为下一个 MapReduce 操作的输入。
3.2 Master Data Structures
master 存储了一些数据结构,例如 map task 和 reduce task 的状态(空闲、处理中、处理完成)以及机器的情况。
master 还存储每个 map 任务完成后,输出的文件位置和大小。这些信息会推送给准备好的 reduce 任务。
3.3 Fault Tolerance
Worker Failure
master 周期性的 ping 一下 worker,如果一段时间内,没有收到响应,则标记为 worker 故障。任何在这台 worker 上面完成的 map 任务都标记为初始化状态,等待重新调度。任何在这台 worker 上面正在执行的 map 和 reduce 任务也都标记初始化状态,等待调度。完成了的 map 任务如果是在故障机器上,只能重新执行,因为存储在故障机器本地。执行完成的 reduce 任务如果在故障机器上则不需要重新执行,因为结果存放在全局文件系统中。
当 map 任务在A上执行,然后因为A故障而调度到B执行时,所有执行 reduce 任务的 worker 会被通知到,同时没有获取结果数据的 worker 会从 B获取相应的这部分数据。
此外,整个集群因为这种简单的重复执行机制,能从大规模的故障中恢复。只要重新能探活到,就有机器能执行,整个进程就会向前推进。
Master Failure
master 的数据很容易就写到 checkpoint 中,这意味着一旦 master 故障,副本可以从 checkpoint 中很快的恢复。不过作者认为只有一个 master,所以不太可能故障。如果故障了,整个计算过程就失败了,客户端可以选择重做。
Semantics in the Presenceof Failures
当用户提供的map和reduce运算符是其输入值的确定函数时,我们的分布式实现产生的输出与整个程序的非错误顺序执行产生的输出相同。
reduce 任务在输出时,先写到临时文件中,等一个任务完全结束的时候,立刻改名成最终文件名。这个操作是原子的。
因为绝大多数 map 和 reduce 操作都是确定性函数,并且等价于顺序执行,开发人员也很容易保证其行为。但是对于非确定性函数的 map 和 reduce,结果就比较难保证了。
3.4 Locality
网络带宽是相对稀缺的资源,所以输入数据读取的是提交任务机器本地磁盘上的文件。然后GFS会把这个文件分成64MB一个的块,备份存储到不同的机器上。master 有这些存储信息,调度的时候会优先调度到有数据分片的机器上执行任务。即使 work 失败了,也会调度到距离数据副本比较近位置的机器上,例如同一个机架或者交换机下的机器。要考虑网络带宽这种资源。
3.5 TaskGranularity
任务分片的粒度也是个值得考究的点。map 任务分成M个,reduce任务分成R个,通常来说,M和R的个数远大于机器数量,这样能执行得比较快,并发度高,且失败了容易恢复。但是大的M和R也有成本,就是 master 要存储 O(M×R) 个状态,以及做 O(M+R) 次调度计算。一般来说,R 的数量会被用户决定。一般来说,就是把输入数据划分成 16MB 或者 64MB 大小的文件分片决定 M 个数。R 总数就是机器数量的一个固定倍数。作者举例 2000台机器,5000个R任务,200000个M任务。
3.6 BackupTasks
一个 MapReduce 任务被其中几个分片的 map 任务或 reduce 任务整体拖慢的情况也有发生,这种称为 straggler。一般都是执行慢的机器有点问题,例如磁盘坏了,读取速度下降。或者调度了多个任务,使得计算资源不太足够,还有一类是程序 bug,遇到过 bug 使得缓存失效...
有策略缓解这类情况。对快要结束的任务,master 调度一个备份任务,不管是主任务执行完,还是备份任务执行完,都算整个任务执行完了。同时通过控制这个机制中的快要结束的认定,能让系统增加资源消耗不太多的情况下,极大缩短 straggler 的影响。
4 Refinements
4.1 Partitioning Function
用户自定义要切分成多少份的输出,可以自定义分片函数
4.2 Ordering Guarantees
系统保证,在一个输出的分片里面,键值对按照 key 的升序排列
4.3 Combiner Function
对于 map 操作中很多重复的键值对,可以在发往 reduce操作前通过 Combiner function 进行合并,粒度是每一个 map 任务。
4.4 Input and Output Types
MapReduce 系统支持一些定义好的输入输出格式,例如文件输入,一行一对 key value。此外,还支持用户自定义 reader,读取不同格式,比如数据库读取,内存映射等多种形式的数据。
4.5 Side-effects
没看懂
4.6 Skipping Bad Records
对于一些错误记录来说,可能会引起 MapReduce 系统崩溃,但这些错误记录来自难以修复的问题,例如使用第三方库...而且有时候错误记录对整体影响不大,例如大数据量统计和个位数的记录错误...所以 MapReduce 系统支持选项,探测坏记录以及是否跳过。
实现方式是,在所有的 worker 上有信号处理代码(signal handler)用来捕获段错误和错误信息。全局有一套错误错误码表。当用户代码触发错误的时候,信号处理器会发送包含错误码的信息 "last gasp" 给 master。当 master 看到某个特定记录上的错误超过1次时,会决定跳过此记录。
4.7 Local Execution
分布式的调试很困难,所以 MapReduce 有本地运行测试版,串行执行每一个任务,方便调试。
4.8 Status Information
master 内部有个 HTTP 服务,对外暴露状态信息页。top-level 页是一些统计信息,例如哪些任务成功,哪些失败。其他更细节的信息在更底层的页面,包含已完成的任务,进行中的任务,输入数据量,输出数据量,任务进行进度等。这些都是阅读友好的形式。
4.9 Counters
一个内置的工具函数,不过在实现的时候,会周期性的向 master 汇报当前计数,master 会做聚合,并展示在状态页上。
6 Experience
最后作者在这一章列举了一个使用 MapReduce 的例子,大规模索引
6.1 Large-ScaleIndexing
是 google 搜索引擎的索引,产生自爬虫服务,大约20T数据。用了 MapReduce 有几个好处:
- 代码变简单,去掉了故障处理,分布式、并行处理,失败恢复等逻辑,被 MapReduce 隐藏了。代码量从3700行--> 700行
- 性能好,使得可以独立开发建索引的每个阶段,而不必耦合。这样改动建索引的流程也方便
- 操作性和扩展性强,故障被 MapReduce 屏蔽了,想提速加机器就行
8 Conclusions
作者认为 MapReduce 能成功,第一是简单好用,对于开发者来说,无需理解太多分布式,并行的概念也能很好的使用;第二是适用性广,绝大多数问题都可以归结为 map-reduce 这个范式;第三是有分布式的实现,在 google 内部真的用了起来。
作者还总结出:
- 对编程范式做约束,使得分布式并行计算,故障忍耐都变得容易
- 带宽是稀缺资源,用本地磁盘做替换是个不错的选择
- 冗余的操作可以减少慢机器的影响,也可以用来处理机器故障和数据丢失