一,如何抓取一个网站?
1,去百度和谷歌搜一下这个网站有没有分享要爬取数据的API
2, 看看电脑网页有没有所需要的数据,写代码测试调查好不好拿,如果好拿直接开始爬取
3,看看有没有电脑能打开的手机网页,一般格式为http://m.xxx.com或http://mobile.xxx.com, 有的话用F12检查抓一下包,看一下抓取的难易程度
4, 使用fiddler, 看看有没有手机APP,抓下APP的包,看能不能抓到接口,如果新版抓不到,可以尝试旧版本。
5, 尝试分析app的一些分享外链
6, 模拟器自动化控制 + 中间人攻击(mitmproxy)
7, 都能不好的话尝试selenium/airtest
8, 最后web端破解js(移动端逆向破解)
二, 常见的反爬措施以及如何解决?
1, UA检测
使用UA池,替代UA为正常的浏览器身份
2, IP封禁
使用代理ip, 构建ip池
3, 频率限制
减低频率,考虑对方的代码
4, Referer防盗链
在请求头中referer添加和网站对应的访问链
5, 登录限制
模拟登录,使用cookie 或借助selenium等自动化工具
6, 验证码
OCR光学字符识别, 打码平台能绕过就尽量绕过
7, js加密
js逆向, 分析网页源代码,找出加密规则,使用python, nodejs模拟加解密
8, CSS反爬
分析网页源代码, 避免抓取脏数据,或者请求时发送多余参数
9, 字体反爬
找到对应的字体文件, 使用FontCreator 和 fontTools,找出编码和数据文字的对应关系
三 如何提高爬虫速度
模拟请求,页面解析, 数据存储的时候,可以使用多线程,多进程
模拟请求(减少请求次数,设置合适的timeout超时参数)
页面解析(正则re> lxml xpath > beautifulsoup css 选择器)
数据存储(excute--> excutr_many / 数据缓存)
提供更好的网络
提供质量更好的Ip
提供性能更好的硬件环境
使用分布式技术
四 如何进行大数据量爬虫(一千万一亿怎么办)
使用scrapy框架,修改设置里面的并发量参数
使用scrapy-redis分布式技术提高爬取效率
分析网站尽量少发送无用请求或者减少请求次数
使用多线程多进程异步的技术,提高请求效率,测试多少个线程爬取效果最好
ip代理池,花钱购买高质量ip,测试多久切换一次ip效果好
网络性能,抓取技术细节调优
测试超过时间这就多久效果最好
五 介绍一下scrapy框架以及有哪些优点
scrapy是一个快速(fast), 高层次(high-level)的基于python的web爬虫框架,用于爬取web站点并从页面中提取结构化数据。scrapy使用了Twisted异步网络库来处理网络通讯
请求多级页面,结构清晰
它容易构建大规模的抓取项目
它异步处理请求,速度非常快
它可以使用自动调节机制自动调整爬行速度
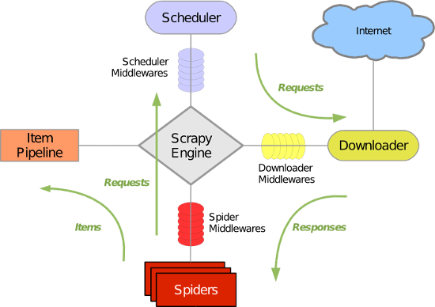
六 scrapy框架有哪几个组件、模块
scrapy Engine(引擎):负责 spider, ItemPipeline, Downloader, Scheduler 中间的通讯,信号,数据传递等
(DTO 数据传输对象)
Spider(爬虫): 它负责处理所有Responses ,从中分析提取数据, 获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入scheduler(调度器),
(双向队列)
Scheduler(调度器):它负责接收引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时, 交还给引擎。
Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests 请求,并将其获取到的Responses交还给Scrapy Engine引擎, 由引擎交给Spider 来处理
Item Pipeline(管道):它负责处理Spider中获取到的Item,并且经过后期处理(详细分析,过滤, 存储等)的地方。
Downloader Middlewares(下载中间件): 一个可以自定义扩展下载功能的组件。
Spider Middlewares (Spider中间件): 可以扩展操作引擎和spider中间通讯的功能组件。
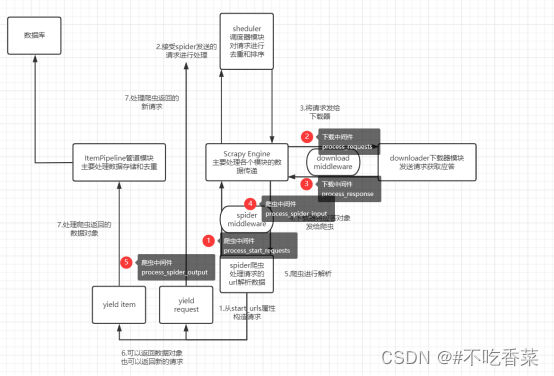
七 scrapy的工作流程
1, 爬取中起始的url构造成request对象,并传递给调度器。
2, 引擎从调度器中获取request对象,然后交给下载器
3, 由下载器来获取到页面源代码,并封装成Response对象,并反馈给引擎。
4, 引擎将获取到的Response对象传递给spider,由spider对数据进行解析(parse),并反馈给引擎。
5, 引擎将数据传递给pipeline进行数据持久化保存或进一步的数据处理
6, 再次期间如果spider中提取到的并不是数据,而是子页面url,可以进一步提交给调度器,进而重复步骤2的过程。
八 scrapy的去重原理(请求去重)
将请求相关信息进行sha1哈希处理,将四个字段(请求方法, 请求链接, post参数,请求头)进行信息摘要,摘要结果在使用set集合进行去重
python
fingerprint_data = {
'method' : to_unicode(request.method),
'url': canonicalize_url(request.url, keep_fragments=keep_fragments),
'body':(request.body or b'').hex(),
'headers' : headers,
}
fingerprint_json = json.dumjps(fingerprint_data, sort_key=True)
cache[cache_key] = hashlib.sha1(fingerprint_json.encode()).digest()九 scrapy如何设置代理IP
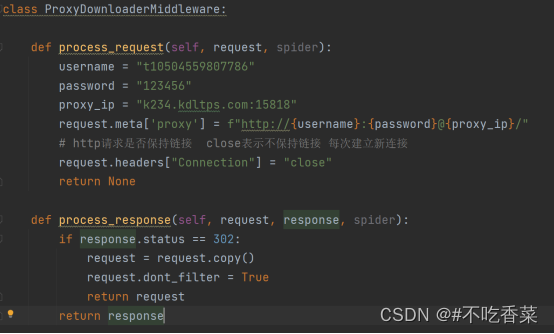
在下载中间件的process_requests方法中进行处理,利用scrapy的meta参数的特殊键proxy,再使用代理IP服务商提供的动态代理或者隧道代理,proxy的值设置为代理服务器地址就可以了
 、
、
十 什么是分布式
分布式系统是由一组通过网络进行通信,为了完成共同的任务而协调工作的计算机节点组成的系统。分布式系统的出现是为了用廉价的,普通的机器完成单个计算机无法完成的计算,存储任务。其目的是利用更多的机器,处理更多的数据。
分布式爬虫则是将多台主机组合起来,共同完成爬取任务,这将大大提高爬取效率。