您好,我是@iFeng的小屋,一枚4年程序猿。
一、爬取目标
很多做运营、电商数据分析或内容研究的朋友,都需要批量获取xhs笔记数据。但xhs反爬比较严格,手动翻页效率太低,而且单个Cookie很容易失效。
所以,我写了这个小红书关键词笔记爬虫,它能:
-
从Excel文件里批量读取搜索词,自动循环爬取
-
支持多个Cookie轮换使用,失效自动切换,提高稳定性
-
不仅能拿到笔记的标题、内容、发布时间,还能获取点赞、收藏、评论、分享数
-
异步下载笔记中的所有高清图片,以最高质量保存为JPG
-
所有数据安全追加到Excel文件,即使中途出错也能保留已爬数据。
二、展示爬取结果
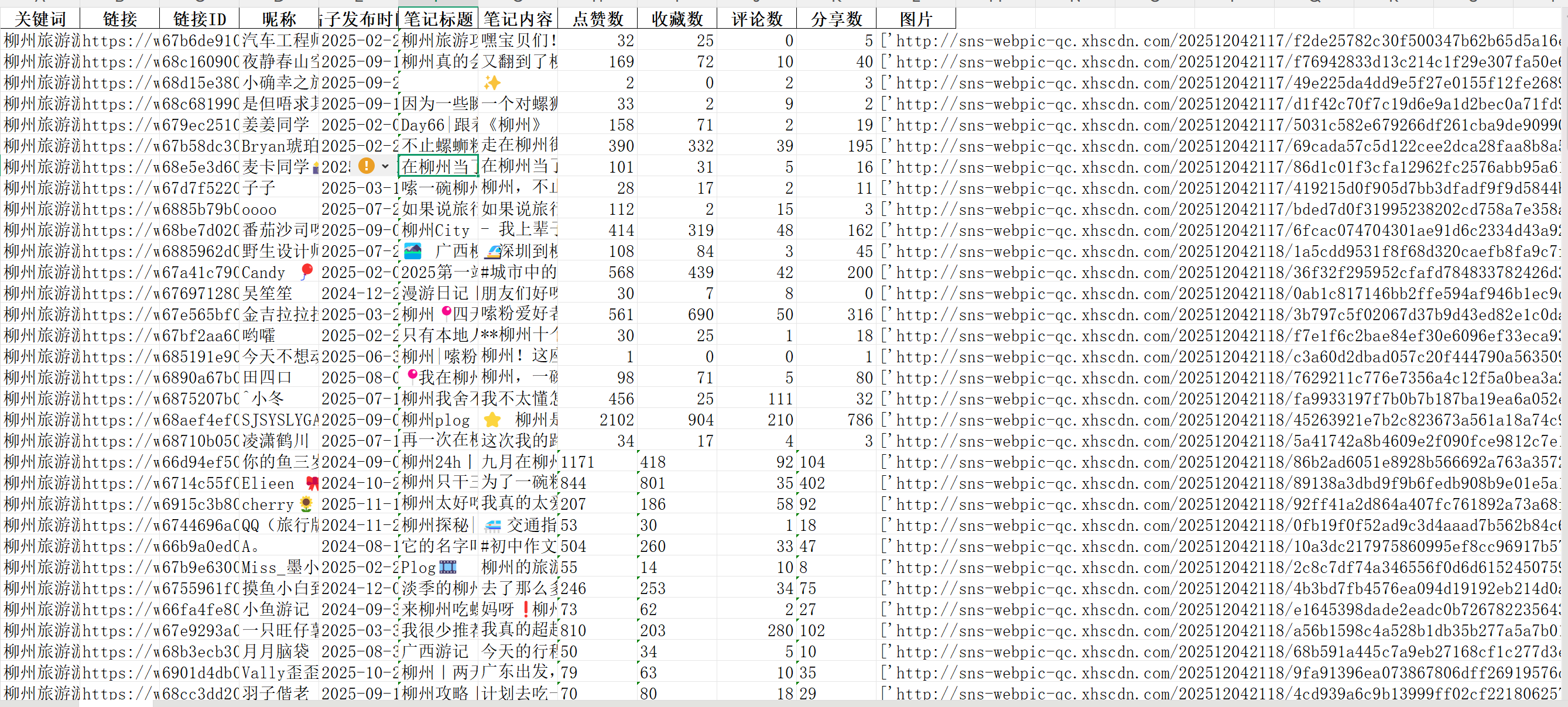
爬取结果包含以下字段,一键存入Excel:
-
关键词(搜索词)
-
链接 & 链接ID(笔记唯一标识)
-
昵称(发布者)
-
帖子发布时间(精确到秒)
-
笔记标题 & 内容(正文)
-
点赞数、收藏数、评论数、分享数(互动核心指标)
-
图片链接列表(可一键下载到本地)
所有数据自动保存为关键词.xlsx文件,图片保存在图片/关键词/文件夹内
三、原理讲解
-
数据准备:从Excel文件中读取搜索词和Cookie列表,每个搜索词独立保存,支持多Cookie轮换。
-
搜索接口 :模拟小红书网页版搜索接口
edith.xiaohongshu.com/api/sns/web/v1/search/notes,POST请求,携带加密参数(x-s, x-t等),返回笔记列表。 -
翻页控制 :通过
page参数循环请求,直到无数据或达到用户设置的上限。 -
详情页解析 :对每个笔记ID,请求详情页
explore/{id},从HTML中提取window.__INITIAL_STATE__变量,里面包含了完整笔记数据和图片列表。 -
数据提取:解析JSON,取出互动数、发布时间、图片高清链接等。
-
图片下载 :使用
aiohttp异步并发下载图片,自动处理RGBA转RGB,统一保存为JPG格式。 -
安全存储 :通过
safe_read_excel和save_to_excel函数处理文件损坏、读取失败等异常,保证数据不丢。
三、爬虫代码讲解
导入库:
python
import requests
import pandas as pd
import json
import time
from datetime import datetime
from lxml import etree
import asyncio
import aiohttp
from DrissionPage import ChromiumPage
# 其他库用于文件处理和异常处理3.1 核心思路与配置
整个爬虫最核心的难点在于签名参数(x-s, x-s-common) 和 多Cookie轮换。这些参数必须从浏览器真实请求中复制,过期后需要重新获取。
为了方便使用,我把Cookie和搜索词都放在Excel文件里管理:
-
搜索词.xlsx:第一列放关键词,一行一个。
-
cookie.xlsx:第一列放完整的cookie字符串,一行一个(可以放多个,程序自动轮换)。
python运行
3.1 关键模块:搜索接口与翻页
搜索接口返回的是笔记列表,包含笔记ID、作者信息、xsec_token等关键字段。
python
json_data = {
'keyword': keyword,
'page': page,
'page_size': 20,
'sort': 'time_descending', # 按最新排序
'note_type': 0, # 普通笔记
'filters': [{'tags': ['半年内'], 'type': 'filter_note_time'}] # 时间筛选
}
response = requests.post(url, json=json_data, headers=headers, cookies=cookies1)
items = response.json()['data']['items']注意 :这里使用了 sort 参数控制排序方式(综合/最新/最热),以及 filters 限定时间范围(半年内)。你可以根据自己的需求调整这些值。
3.2 关键模块:详情页解析(提取完整数据)
从搜索列表拿到笔记ID和xsec_token后,构造详情页URL:
python
url = f'https://www.xiaohongshu.com/explore/{id}?xsec_token={xsec_token}'
response_detail = requests.get(url, headers=headers_detail, cookies=cookies1)
content_raw = response_detail.text.split('window.__INITIAL_STATE__=')[1].split('</script>')[0]
if content_raw.endswith(';'):
content_raw = content_raw[:-1]
content_raw = content_raw.replace('undefined', 'null')
parsed_data = json.loads(content_raw)提取图片列表:
python
image_url_all = []
for image in parsed_data['note']['noteDetailMap'][id]['note']['imageList']:
# 原图链接在 infoList[0]['url'],有些图片还有第二张、第三张尺寸
image_url = image['infoList'][0]['url'] # 取最高清
image_url_all.append(image_url)提取互动数据:
python
interact_info = note_data['note']['interactInfo']
liked_count = interact_info['likedCount']
collected_count = interact_info['collectedCount']
comment_count = interact_info['commentCount']
shared_count = interact_info['shareCount']3.3 关键模块:异步下载图片
小红书图片比较多,如果用同步下载会非常慢。我用了 aiohttp 异步并发下载,速度提升好几倍:
python
async def download_single_image_async(session, image_url, save_path, filename):
async with session.get(image_url) as response:
content = await response.read()
image = Image.open(io.BytesIO(content))
# 处理RGBA透明图,转为RGB保存为JPG
image.save(full_path, 'JPEG', quality=95)
async def download_multiple_images_async(image_urls, save_path):
tasks = [download_single_image_async(...) for ...]
await asyncio.gather(*tasks)
def download_multiple_images_fast(image_urls, save_path):
asyncio.run(download_multiple_images_async(image_urls, save_path))3.4 主循环逻辑
主函数 main() 整合以上所有模块,流程如下:
-
调用
initialize_data_files()读取搜索词和Cookie。 -
对每个关键词,让用户输入想爬取的数量。
-
对每个排序方式(默认只启用了"最新"),开始分页循环:
-
构建搜索请求,如果失败则切换Cookie。
-
遍历笔记列表,对每个笔记请求详情页,提取数据。
-
如果详情页解析失败(可能Cookie失效),切换Cookie并重试。
-
达到数量上限或没有更多数据时停止。
-
每页数据调用
save_to_excel追加保存。 -
图片链接存入Excel,但不自动下载(可选,需要下载可调用
download_multiple_images_fast)。
-
四、如何运行?
-
准备文件:
-
创建
搜索词.xlsx,第一列放你想搜的关键词。 -
创建
cookie.xlsx,第一列放你的小红书网页版Cookie(可从浏览器开发者工具复制)。
-
-
安装依赖:
python
pip install requests pandas lxml openpyxl aiohttp aiofiles pillow DrissionPage3.运行脚本。输入每个关键词想爬取的数量(最多220条,建议小批量测试)。
- 查看结果 :每个关键词生成一个
关键词.xlsx文件,图片(如果启用下载)保存在图片/关键词/文件夹。
五、说明
-
Cookie 和签名时效性:小红书的Cookie和签名有效期较短,如果出现大量请求失败,请重新抓取并替换。
-
请求频率 :代码中已加入
time.sleep(5)等延迟,请勿修改过短,否则容易触发封IP。 -
图片下载 :默认不自动下载图片,如需下载,请在代码中取消注释
download_multiple_images_fast的调用。 -
完整源码 :上述代码为关键模块展示,完整可运行的源码包含了更多细节(如路径处理、异常重试、参数校验等),已打包整理。
需要本文完整可运行Python源码的小伙伴,我都放在了与此号同名的公主号里,大家自行获取。
持续分享Python干货中!更多爬虫源码干货,请前往主页查看.