Elasticsearch
ES简介

Elasticsearch(简称ES)是一个开源的分布式搜索和分析引擎,常用于全文搜索、日志存储和分析等场景。它构建在Apache Lucene搜索引擎库之上,提供了一个分布式的多租户能力,支持大规模的数据处理。
主要特性和用途
-
全文搜索: Elasticsearch 是为了高效地进行全文搜索而设计的。它支持快速的文本搜索、复杂的查询、高亮显示匹配文本等功能。这使得它在许多应用中被广泛应用,例如电子商务平台的产品搜索、新闻网站的文章检索等。
-
实时数据分析: Elasticsearch 可以处理大规模的实时数据分析任务。通过将结构化和非结构化数据索引到Elasticsearch中,用户可以执行复杂的数据分析、聚合和可视化操作,支持企业的数据分析需求。
-
分布式和高可用性: Elasticsearch 是一个分布式系统,数据被分布在多个节点上,每个节点可以处理部分查询和数据操作。它具有内置的容错和高可用机制,通过复制和分片技术实现数据的高可用性和水平扩展。
-
实时数据处理: Elasticsearch 支持实时数据写入和检索,因此非常适合需要快速存储和检索数据的应用场景,如实时日志处理和监控系统。
-
多种数据类型支持: Elasticsearch 不仅仅支持文本数据的索引和搜索,还可以处理地理空间数据、结构化数据等。它提供了丰富的数据类型和灵活的映射机制,使得能够存储和处理各种类型的数据。
-
开放的生态系统: Elasticsearch 生态系统丰富,与许多常见的数据存储、数据处理工具和流行的编程语言集成良好。它还支持插件系统和强大的API,使得可以轻松扩展和定制功能。
应用场景
- 搜索引擎:用于构建复杂的全文搜索引擎,如电商平台的产品搜索、新闻聚合网站的内容搜索等。
- 日志和指标分析:通过存储和分析大量的日志数据,支持实时监控和分析系统性能和运行状况。
- 业务分析:支持企业对大数据的实时查询和分析,帮助做出数据驱动的决策。
- 安全分析:用于实时分析网络安全事件和入侵检测。
- 地理信息系统:处理和分析地理空间数据,支持地理位置查询和可视化分析。
总之,Elasticsearch 是一个功能强大的搜索和分析引擎,适用于处理大规模数据的搜索、分析和实时数据处理需求。
分布式全文搜索引擎
我们天天在用ES
搜索的时候
要与多个信息进行匹配查找
然后返回给用户

首先
ES会将数据库中的信息
先进行一个拆分
这个叫做分词
是按照词语关键词拆的
然后就能进行搜索的时候匹配对应的id
每一个关键字对应若干id
每一个id对应数据
然后搜索的时候展示简化版数据
点击简化版数据反映全部信息属于的是全文搜索

在数据库中有索引
在ES中也有索引
但是根据关键字查ID 再由ID查数据
这个在全文搜索里叫倒排索引
倒排索引是怎么出现的呢
是根据创建文档 出现一个一个的库
然后我们进行查找的时候就是在使用这个库,使用文档

ES的下载和安装
下载地址
Download Elasticsearch | Elastic
下载好了

内置
有个jdk17
250MB左右
总大小600MB
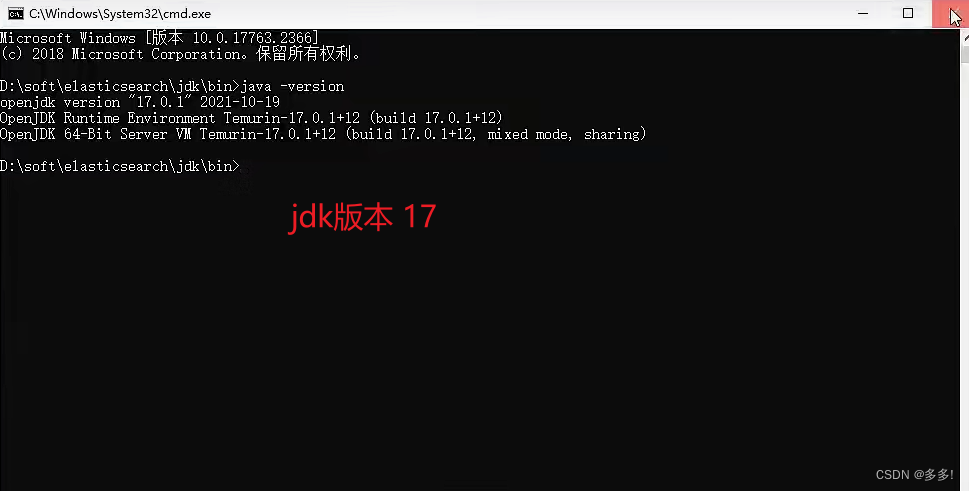
双击初始化
文件: elasticsearch.bat

查找端口

访问本地地址
http://localhost:9200/即可访问到
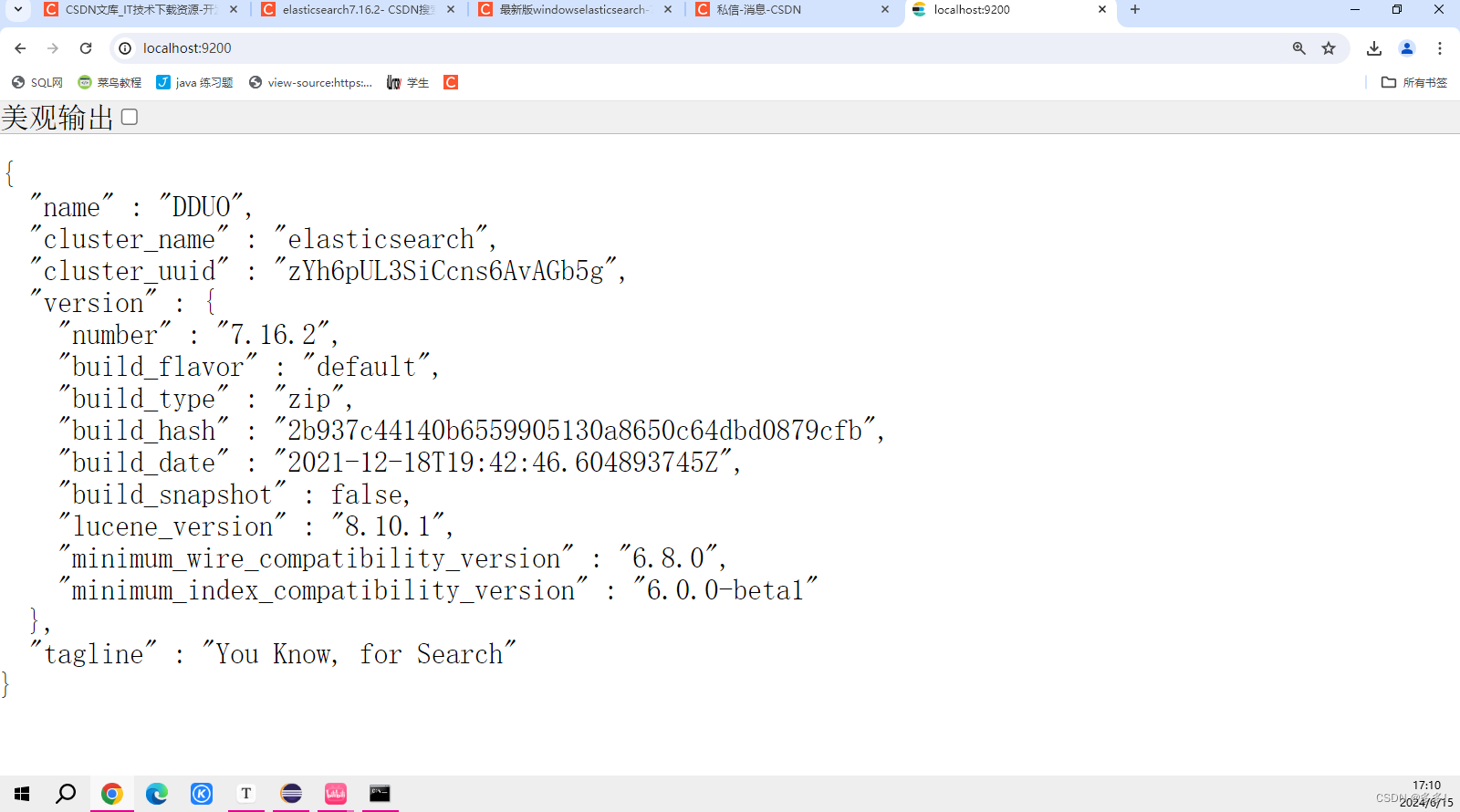
成功监测访问成功 部署成功
ES索引操作
ES没有数据库的概念
只有索引
我们可以把ES里的索引理解成数据库
用postman进行测试操作

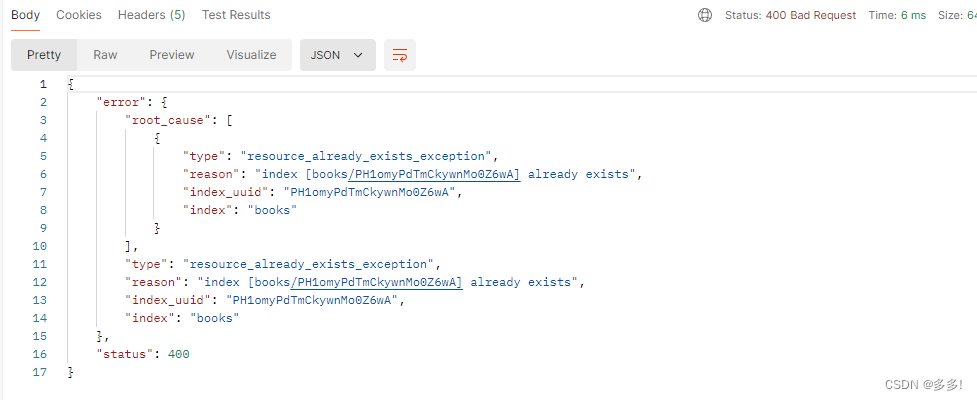
创建一个名字叫books的索引
数据库

表示本次操作成功

索引不允许重复创建
如果再次创建就会报错
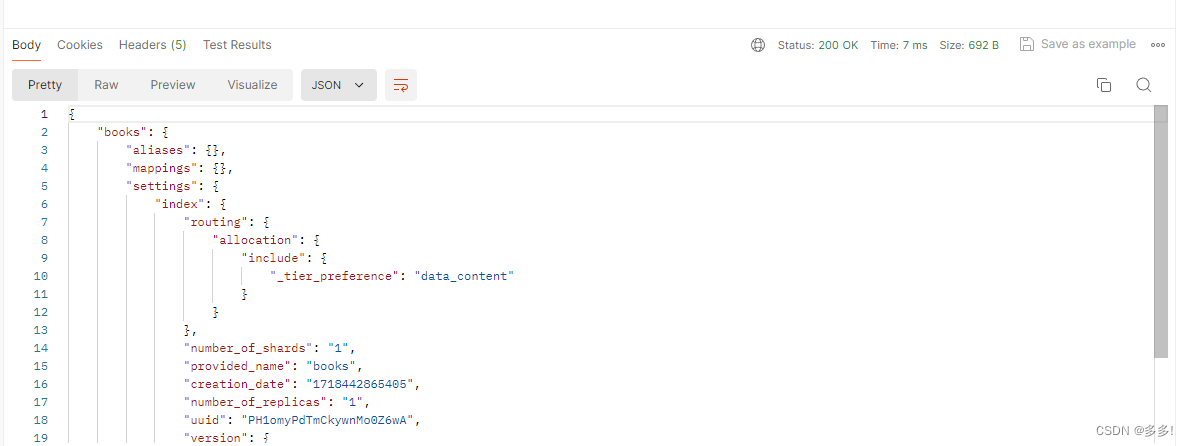
我们可以进行查询
用get进行查询

返回结果
代表查询成功
同样的我们通过不同的请求操作
能完成对索引的不同操作
需要的是路径和请求一一对应
幂等性是指一个操作或函数被多次应用后所产生的效果与一次应用时的效果相同的性质。换句话说,如果对同一个对象或系统进行一次或多次操作,最终的状态或结果都是一致的,那么这个操作就是幂等的。
在Web开发中,HTTP方法如GET、PUT、DELETE等应该是幂等的。例如,无论你调用一次还是多次相同的HTTP PUT请求,资源的状态应该是相同的。
这个地方就是放索引的分词信息的

我们下载一个分词器
 看看
看看
我们把他放到es的plugins目录下
相当于是装了一个插件

这时候我们要重新启动我们的ES
如果版本一致并且plugins文件夹下只有ik文件夹 即可启动成功
接下来我们就要去使用了
我们在postman里指定路径 在后面跟上一请求体的信息
在postman里写请求体

{
"mappings":{
"properties":{
"id":{
"type":"keyword",
"analyzer":"ik_max_word"
},
"name":{
"type":"text",
"analyzer":"ik_max_word"
},
"type":{
"type":"keyword"
}
}
}
}发送后即创建成功

让索引挂上设定
然后数据进来的时候就会进行操作
小结


实际操作
添加依赖
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.17.0</version> <!-- 替换为您使用的 Elasticsearch 版本 -->
</dependency>总结
这段代码是一个 Maven 依赖配置,用于在 Java 项目中引入 Elasticsearch 的高级 REST 客户端库。让我们逐行解释每个部分的含义:
-
<dependency>: 这是 Maven POM 文件中用来声明项目依赖的标签,告诉 Maven 构建工具需要获取和管理哪些库和版本。 -
<groupId>: 指定了依赖库的组织或者项目组的唯一标识符。在这里,org.elasticsearch.client表示 Elasticsearch 官方客户端的组织。 -
<artifactId>: 指定了具体的库或者项目的名称。在这里,elasticsearch-rest-high-level-client是 Elasticsearch 的高级 REST 客户端库,它提供了更高级别的 API 接口来与 Elasticsearch 集群进行交互。 -
<version>: 指定了要使用的库的版本号。在这里,7.17.0是 Elasticsearch 高级 REST 客户端库的版本号。根据您实际使用的 Elasticsearch 版本,可以将这个版本号替换为适合的版本。
通过这些配置,您的 Maven 项目就能够使用 Elasticsearch 高级 REST 客户端库,从而方便地与 Elasticsearch 进行索引、搜索和管理数据的操作。
连接到 Elasticsearch
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
public class ElasticsearchExample {
public static void main(String[] args) {
// 连接本地 Elasticsearch 服务,默认端口为9200
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(new HttpHost("localhost", 9200, "http")));
// 在这里进行索引文档和查询的操作
}
}这段代码是一个简单的 Java 示例,演示了如何使用 Elasticsearch 的高级 REST 客户端连接到本地的 Elasticsearch 服务,并进行基本的索引文档和查询操作。让我们逐行解释代码的各个部分:
-
import org.apache.http.HttpHost;- 这是导入了 Apache 的
HttpHost类,用于指定 Elasticsearch 服务的主机名、端口和协议。
- 这是导入了 Apache 的
-
import org.elasticsearch.client.RestClient;- 这是导入了 Elasticsearch 的低级 REST 客户端类
RestClient,用于构建连接 Elasticsearch 的客户端。
- 这是导入了 Elasticsearch 的低级 REST 客户端类
-
import org.elasticsearch.client.RestHighLevelClient;- 这是导入了 Elasticsearch 的高级 REST 客户端类
RestHighLevelClient,它提供了更加友好和面向对象的 API 接口,方便进行索引、搜索和管理操作。
- 这是导入了 Elasticsearch 的高级 REST 客户端类
-
public class ElasticsearchExample {- 定义了一个名为
ElasticsearchExample的公共类。
- 定义了一个名为
-
public static void main(String[] args) {- 这是 Java 程序的入口点,
main方法是程序执行的起点。
- 这是 Java 程序的入口点,
-
RestHighLevelClient client = new RestHighLevelClient(- 创建了一个
RestHighLevelClient对象client,用于与 Elasticsearch 服务进行交互。
- 创建了一个
-
RestClient.builder(new HttpHost("localhost", 9200, "http")));- 使用
RestClient.builder方法构建了一个RestClient实例,参数new HttpHost("localhost", 9200, "http")指定了 Elasticsearch 服务的主机名为localhost,端口为9200,协议为http。
- 使用
-
// 在这里进行索引文档和查询的操作- 这是一个注释,表明在这个代码块内可以添加实际的索引文档和查询操作代码。
总结
这段代码的主要作用是建立了与本地 Elasticsearch 服务的连接,并创建了一个高级 REST 客户端 RestHighLevelClient 对象 client。通过这个客户端对象,您可以使用 Elasticsearch 的高级 API 进行索引、搜索和管理数据的操作。
索引文档
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.common.xcontent.XContentType;
public class ElasticsearchExample {
public static void main(String[] args) {
// 索引文档示例
String jsonString = "{" +
"\"title\":\"Elasticsearch Basics\"," +
"\"content\":\"Elasticsearch is a distributed search and analytics engine.\"" +
"}";
IndexRequest request = new IndexRequest("my_index")
.id("1")
.source(jsonString, XContentType.JSON);
try {
IndexResponse indexResponse = client.index(request);
System.out.println("文档索引成功,文档 ID: " + indexResponse.getId());
} catch (IOException e) {
e.printStackTrace();
}
}
}总结
当然!这段示例代码演示了如何使用 Elasticsearch 的高级 REST 客户端来索引一个文档到指定的索引中。
-
准备索引文档的数据: 在示例中,我们定义了一个 JSON 字符串来表示要索引的文档内容。这个文档包括两个字段:
title和content。title字段包含了文档的标题,而content字段描述了 Elasticsearch 是一个分布式搜索和分析引擎。 -
创建 IndexRequest 对象: 使用 Elasticsearch 的 Java 客户端,我们创建了一个
IndexRequest对象。这个对象指定了要将文档索引到的目标索引名称(在示例中是"my_index")和文档的唯一标识符(ID)。此外,我们使用source方法将之前准备的 JSON 字符串和指定的内容类型(XContentType.JSON)添加到请求中。 -
执行索引操作: 调用 Elasticsearch 客户端的
index方法并传递IndexRequest对象。这个操作将会把文档发送给 Elasticsearch 集群进行索引。如果索引操作成功,将返回一个IndexResponse对象,其中包含了有关索引操作结果的信息,比如索引的文档 ID。 -
处理索引响应: 在示例中,我们捕获可能抛出的
IOException异常,这可能由于网络问题或 Elasticsearch 服务不可用等原因造成。如果索引操作成功,我们通过IndexResponse对象获取文档的 ID,并将其打印输出。
这个示例展示了如何利用 Elasticsearch 的 Java 客户端,通过简单的 API 调用,将结构化数据索引到 Elasticsearch 中。这种方式非常适合构建应用程序,将搜索和分析功能集成到应用中,并利用 Elasticsearch 的强大搜索引擎能力来快速检索和分析数据。
查询文档
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.common.unit.TimeValue;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import java.io.IOException;
public class ElasticsearchExample {
public static void main(String[] args) {
// 查询文档示例
SearchRequest searchRequest = new SearchRequest("my_index");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.matchQuery("title", "Elasticsearch"));
searchRequest.source(searchSourceBuilder);
try {
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
System.out.println("搜索到 " + searchResponse.getHits().getTotalHits().value + " 个文档:");
searchResponse.getHits().forEach(hit -> {
System.out.println("文档 ID: " + hit.getId() + ", 标题: " + hit.getSourceAsMap().get("title"));
});
} catch (IOException e) {
e.printStackTrace();
}
}
}总结
这段代码演示了如何使用 Elasticsearch 的 Java 客户端来执行搜索请求并处理搜索结果。以下是关键步骤的解释:
-
创建 SearchRequest 对象: 首先,通过
SearchRequest类创建了一个搜索请求对象searchRequest,指定了要搜索的索引名称为"my_index"。 -
构建查询条件: 使用
SearchSourceBuilder对象searchSourceBuilder构建查询条件。在这个例子中,使用QueryBuilders.matchQuery("title", "Elasticsearch")创建了一个匹配查询,用于搜索包含指定标题("Elasticsearch")的文档。 -
配置搜索请求: 将构建好的查询条件设置到搜索请求对象中,通过
searchRequest.source(searchSourceBuilder)方法实现。 -
执行搜索请求: 使用 Elasticsearch 客户端执行搜索请求,并通过
client.search(searchRequest, RequestOptions.DEFAULT)方法发送请求。这里假设client是已经初始化好的 Elasticsearch 客户端对象。 -
处理搜索响应: 在
try-catch块中,捕获可能抛出的IOException异常,这是因为执行 Elasticsearch 操作时可能会涉及到网络通信。如果搜索操作成功,会得到一个SearchResponse对象searchResponse。- 使用
searchResponse.getHits().getTotalHits().value获取搜索到的文档总数,并打印出来。 - 使用
searchResponse.getHits().forEach(...)迭代处理每个搜索到的文档结果。hit.getId()获取文档的 ID。hit.getSourceAsMap().get("title")获取文档的标题字段。
- 使用
-
异常处理: 在
catch块中,打印出任何发生的IOException异常信息。
这段代码展示了如何利用 Elasticsearch 的 Java 客户端进行简单的文档搜索操作,并处理搜索结果。通过这种方式,可以轻松地集成 Elasticsearch 的搜索功能到 Java 应用程序中,实现快速、灵活的文档检索。
关闭客户端连接
import java.io.IOException;
public class ElasticsearchExample {
public static void main(String[] args) {
// 关闭客户端连接
try {
client.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}总结
这段代码展示了如何关闭 Elasticsearch 客户端连接。以下是关键点的解释:这行代码导入了 IOException 类,用于处理在关闭客户端连接时可能抛出的异常。
-
关闭客户端连接: 在
main方法中,通过调用client.close()方法来关闭 Elasticsearch 客户端连接。这里假设client是一个已经初始化和配置好的 Elasticsearch 客户端对象。 -
异常处理: 使用
try-catch块来捕获可能抛出的IOException异常。在catch块中,通过e.printStackTrace()打印异常堆栈信息,以便查看问题所在。 -
作用: 关闭 Elasticsearch 客户端连接是一个良好的实践,特别是在应用程序即将退出时或者不再需要连接 Elasticsearch 服务时。关闭连接可以释放资源并确保不会出现连接泄漏或资源浪费。
-
注意事项:
- 确保
client对象在调用close()方法之前已经正确初始化和配置。 - 处理
IOException是为了在关闭连接时处理可能出现的网络或IO异常,确保程序能够在异常情况下正常退出或给予适当的反馈。
- 确保
总结来说,这段代码展示了如何安全地关闭 Elasticsearch 客户端连接,并提供了基本的异常处理以应对可能出现的异常情况。
总结
这些示例展示了如何使用 Java 客户端连接到 Elasticsearch、索引文档以及执行简单的查询操作。您可以根据实际需求和场景进一步扩展这些操作,例如添加更复杂的查询、处理搜索结果等。请确保根据您的具体情况调整代码,包括替换索引名称、文档内容和查询条件。
个人号推广
博客主页
Web后端开发
https://blog.csdn.net/qq_30500575/category_12624592.html?spm=1001.2014.3001.5482
Web前端开发
https://blog.csdn.net/qq_30500575/category_12642989.html?spm=1001.2014.3001.5482
数据库开发
https://blog.csdn.net/qq_30500575/category_12651993.html?spm=1001.2014.3001.5482
项目实战
https://blog.csdn.net/qq_30500575/category_12699801.html?spm=1001.2014.3001.5482
算法与数据结构
https://blog.csdn.net/qq_30500575/category_12630954.html?spm=1001.2014.3001.5482
计算机基础
https://blog.csdn.net/qq_30500575/category_12701605.html?spm=1001.2014.3001.5482
回忆录
https://blog.csdn.net/qq_30500575/category_12620276.html?spm=1001.2014.3001.5482