这篇论文题为"Towards a Personal Health Large Language Model"(迈向个人健康大语言模型),由Justin Cosentino等人撰写。以下是对其摘要和主要内容的评论:
摘要原文
大型语言模型(llm)可以对广泛的信息进行检索、推理和推断。在健康方面,迄今为止,大多数LLM工作都集中在临床任务上。然而,很少整合到临床任务中的移动和可穿戴设备为个人健康监测提供了丰富、连续和纵向的数据来源。本文提出一个新模型,个人健康大型语言模型(PH-LLM),一个经过微调的Gemini版本,用于对数字时间序列个人健康数据的文本理解和推理,用于睡眠和健身应用。为了系统地评估PH-LLM,我们创建并策划了三个新的基准数据集,以测试1)从测量的睡眠模式、身体活动和生理反应中产生的个性化见解和建议,2)专家领域知识,以及3)自我报告的睡眠质量结果的预测。对于洞察和建议任务,我们创建了857个关于睡眠和健身的案例研究。这些案例研究是与领域专家合作设计的,代表了现实世界的场景,并强调了模型在理解和指导方面的能力。通过对特定领域rubrics的人工和自动综合评估,我们观察到Gemini Ultra 1.0和PH-LLM与专家在健身方面的表现没有统计学差异,虽然专家在睡眠方面仍然优于专家,但微调PH-LLM在利用相关领域知识和个性化信息方面有显著提升。为了进一步评估专家领域知识,我们评估了PH-LLM在睡眠医学和健身多项选择题考试中的表现。phd - llm在睡眠(N=629个问题)和健身(N=99个问题)方面取得了79%的成绩,两者都超过了人类专家样本的平均分数,以及在这些领域获得持续信用的基准。为了使PH-LLM能够预测睡眠质量的自我报告评估,我们对模型进行了训练,以从可穿戴传感器数据的文本和多模态编码表示中预测自我报告的睡眠中断和睡眠损害结果。证明了多模态编码对于匹配一套判别模型的性能来预测这些结果既是必要的,也是充分的。尽管在安全关键的个人健康领域需要进一步的开发和评估,但这些结果证明了Gemini模型的广泛知识库和能力,以及与PH-LLM一样,将生理数据用于个人健康应用的好处。

图1:PH-LLM:个人健康大型语言模型。(A)我们提出phd - llm, Gemini的一个版本微调个人健康和健康。我们在个人健康的三个方面评估了PH-LLM:生成针对睡眠和健身领域的用户目标的个性化见解和建议,评估专家水平从认证考试类型的多项选择题中获得知识,并预测患者报告的结果从详细的传感器信息中获得睡眠质量。(B) PH-LLM的性能与专家人类语境相关响应。误差条表示95%的置信区间。"∗"表示在统计学上有显著差异两种响应类型。"朴素性能"是指随机分类器实现的性能。人类的专家表现不是
可用于从传感器特征预测患者报告的结果,因为这是不常用的在评估患者报告的36结果的研究中,对健康相关结果进行了测量。
摘要解析
- 研究背景:
- 大语言模型(LLMs)能够检索、推理和推断各种信息。在健康领域,目前大部分LLM的研究都集中在临床任务上。然而,移动和可穿戴设备提供了丰富的、连续的和长期的数据源,这些数据对个人健康监测非常有价值,但很少被整合到临床任务中。
- 研究目标:
- 本研究介绍了一个新模型,即个人健康大语言模型(PH-LLM)。该模型是对Gemini模型进行微调,以便更好地理解文本和对数值时间序列的个人健康数据进行推理,主要应用于睡眠和健身领域。
- 数据集和评估:
- 为了系统地评估PH-LLM,研究人员创建和整理了三个新的基准数据集,分别用于测试:从测量的睡眠模式、身体活动和生理反应中生成个性化的见解和建议,专家领域知识,以及自我报告的睡眠质量结果的预测。
- 在个性化见解和建议任务中,创建了857个睡眠和健身案例研究,这些案例与领域专家合作设计,代表了现实场景,展示了模型在理解和指导方面的能力。
- 实验结果:
- 在健身方面,PH-LLM和Gemini Ultra 1.0的表现与专家表现没有显著差异;在睡眠方面,专家表现更优越,但微调后的PH-LLM在使用相关领域知识和个性化信息方面有显著改进。
- 在专家领域知识评估中,PH-LLM在睡眠医学和健身领域的多项选择题考试中分别达到了79%和88%的得分,这些得分均超过了人类专家的平均分数。
- 为了预测自我报告的睡眠质量评估,研究人员训练模型预测从可穿戴传感器数据中获得的睡眠中断和睡眠障碍结果,展示了多模态编码在匹配这些结果预测性能方面的必要性和充分性。
方法与贡献
- 模型:
- 介绍了PH-LLM,一个从Gemini微调而来的新模型,旨在生成关于个人健康行为(如睡眠和健身模式)的见解和建议。
- 数据集创建:
- 研究人员创建了首个详细的个人健康案例研究数据集,涵盖睡眠和健身领域,包含个性化的可穿戴传感器数据和相应的长篇见解和建议。
- 基准和上下文化个人健康问答:
- 研究整理了一套验证的领域特定多项选择考试题,用于测试模型的专家知识,并通过一组人类专家的考试成绩来提供上下文。
- 多模态传感器数据的自我报告结果预测:
- 成功整合了纵向时间序列传感器特征,以解释用户的主观体验,并展示了在睡眠领域预测自我报告结果的准确模型性能需要原生多模态数据集成。
实验分析
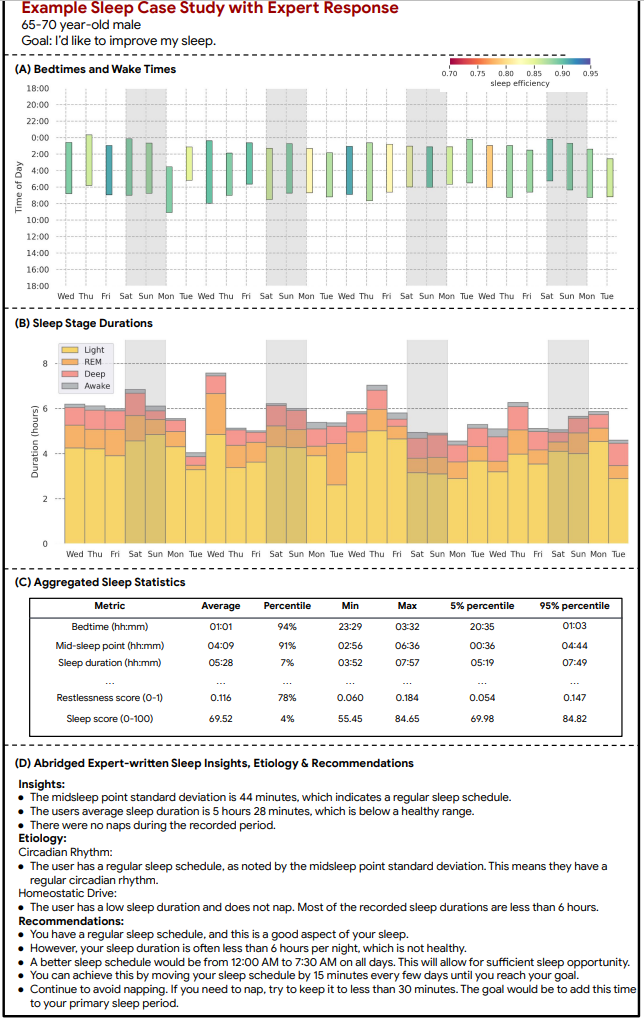
- 图2:睡眠案例研究示例:使用可穿戴传感器数据作为输入,并进行相应的专家分析和改善睡眠质量的建议。专家考虑了个体的基本情况和可穿戴传感器数据(最长达29天),包括每日的(A)入睡和起床时间,以及(B)各个睡眠阶段和清醒时间的分布。所有每日指标详见表A.4。专家还分析了(C)各种睡眠指标的汇总统计数据。完整的汇总统计列表详见表A.5。专家基于这些数据编写了相应的分析报告,包括(D)关于个体睡眠的见解、潜在病因及改善睡眠质量的建议。
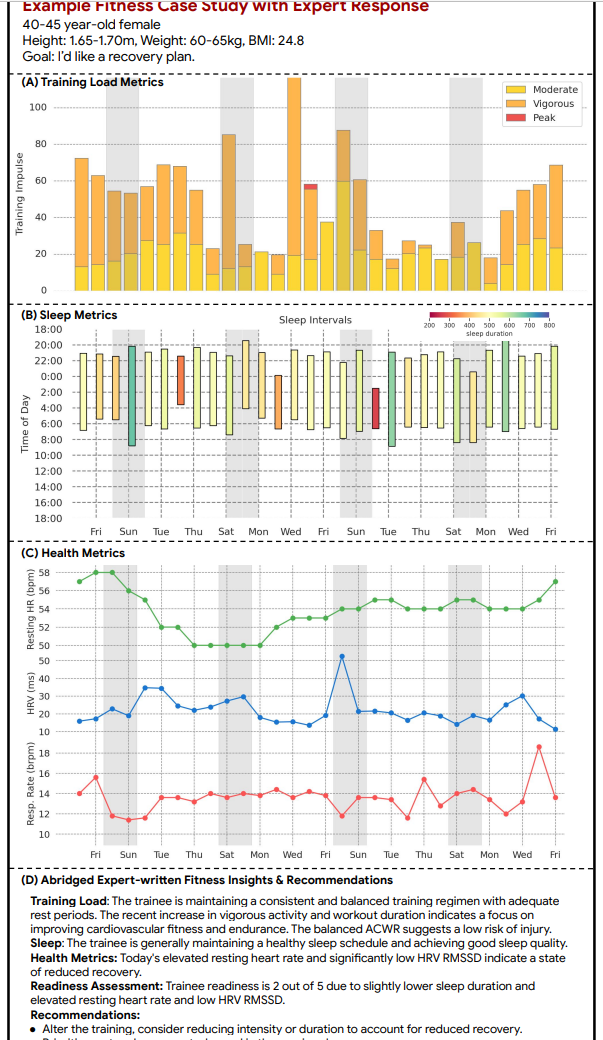
图3:健身案例研究示例:使用可穿戴传感器数据作为输入,并进行相应的专家分析和建议。专家考虑了个体的基本情况和为期30天的可穿戴传感器数据,包括每日的(A)心血管训练负荷(如训练冲量),(B)睡眠指标(如入睡和起床时间),以及(C)健康指标(如静息心率、心率变异性和呼吸频率)。所有每日和汇总指标详见表A.11-A.17。专家基于这些数据编写了相应的分析报告,包括(D)关于个体训练负荷、睡眠、健康指标的见解,并提供了锻炼准备评估和健身建议。
创新与贡献
- 本研究创新性地将LLM应用于个人健康领域,尤其是结合可穿戴设备数据来进行个性化健康监测和建议。
- 提供了详尽的基准数据集和评估标准,为未来相关研究提供了重要的参考和基础。
方法优缺点
优点:
- 通过微调模型提升了其在个人健康数据解读和建议生成方面的性能。
- 创建了详细的、专家标注的个人健康数据集,有助于模型的训练和评估。
- 展示了多模态数据集成在预测个人健康结果方面的有效性。
缺点:
- 尽管模型在许多任务上表现良好,但在一些特定领域(如睡眠建议)上仍与专家有一定差距。
- 数据集和评估的结果依赖于专家的标注和评估,存在一定的主观性。
综上所述,这篇论文在探索将大语言模型应用于个人健康领域方面做出了重要贡献,并通过详尽的实验和数据集创建展示了模型的潜力和当前的局限性。