1 引言
突触可塑性 (Synaptic plasticity)指经验能够修改神经回路功能的能力。特指基于活动修改突触传递强度的能力,是大脑适应新信息的主要调查机制。分为短期和长期突触可塑性,分别作用于不同时间尺度,对感官刺激的短期适应和长期行为改变及记忆存储至关重要。
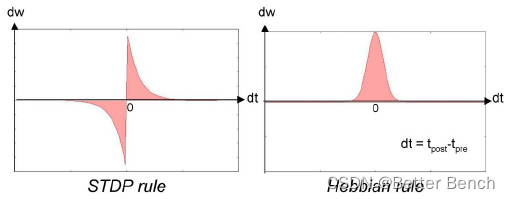
非对称 STDP 学习规则与对称 Hebbian 学习规则的区别
2 Hebbian学习规则
(1)数学模型
Hebbian学习是一种神经网络学习理论,它基于Donald Hebb在1949年提出的假设,即"神经元的联合使用会导致它们之间的连接增强"。这种学习规则通常被称为Hebbian规则或Hebbian学习理论,是神经科学和机器学习中理解和模拟大脑学习机制的基础之一。
Hebbian学习的核心思想是,如果两个神经元经常同时活动,它们之间的突触连接会变得更强壮。这可以用以下简单的数学形式表达:
Δ w i j = η x i x j \Delta w_{ij} = \eta x_i x_j Δwij=ηxixj
其中:
- Δ w i j \Delta w_{ij} Δwij 是连接权重的增量。
- η \eta η 是一个表示学习速率的小正数。
- x i x_i xi 和 x j x_j xj 分别是前一个神经元和后一个神经元的激活值。
原始的Hebbian学习规则可以进一步扩展,包括考虑权重的饱和和遗忘机制。例如,引入一个遗忘因子(forgetting factor) γ \gamma γ,可以使得权重随时间衰减,从而模拟短期记忆的遗忘过程:
w i j ( t + 1 ) = γ w i j ( t ) + η x i ( t ) x j ( t ) w_{ij}(t+1) = \gamma w_{ij}(t) + \eta x_i(t) x_j(t) wij(t+1)=γwij(t)+ηxi(t)xj(t)
其中,
- w i j ( t ) w_{ij}(t) wij(t) 是在时间 ( t ) 时的权重。
- w i j ( t + 1 ) w_{ij}(t+1) wij(t+1) 是更新后的权重。
这种形式的Hebbian学习规则可以模拟神经元之间的长期增强(Long-Term Potentiation, LTP),这是学习和记忆形成过程中的关键机制之一。
Hebbian学习规则在神经网络中的实现通常涉及突触权重的更新,以响应输入模式的激活。这种学习机制在多种类型的神经网络中都有应用,包括但不限于Hopfield网络、Boltzmann机、以及某些类型的递归神经网络(RNN)和长短期记忆网络(LSTM)。Hebbian学习是无监督学习的一种形式,因为它不需要外部的误差信号来指导学习过程。
(2)Hebbian学习规则的局限性
基本的Hebbian规则可能导致不稳定,因为如果两个神经元的激活水平最初只是弱正相关,规则会增加它们之间的权重,进而强化这种相关性,导致权重进一步增加。为了解决这个问题,可以采用一些稳定化方法,如限制权重的增长或采用更复杂的规则。
(3)改进的Hebbian学习
算法思想是将Hebbian学习规则与奖励机制结合起来以实现强化学习。首先将Hebbian更新与奖励直接相乘,但这种方法存在稳定性问题,因为它不能可靠地跟踪输入、输出和奖励之间的实际协方差。为了解决这个问题,然后提出了节点扰动规则,该规则通过引入随机扰动到神经激活中,并使用这些扰动而不是原始激活来进行权重更新,从而推动网络朝着奖励方向学习。这种方法不仅能够在生物学上合理地实现,而且还能够使网络从稀疏和延迟的奖励中学习复杂的认知或运动任务,实际上实现了REINFORCE算法,为强化学习提供了一种有效的解决方案。
3 STDP
STDP(Spike-Timing Dependent Plasticity)是一种理论模型,它允许基于神经元脉冲的相对时间来修改它们之间连接的强度。与Hebbian学习规则不同,STDP考虑了前突触和后突触脉冲的精确时间。STDP建议,如果前突触神经元在后突触神经元之前脉冲,它们之间的连接应该被加强;反之,则应该被削弱。STDP在多种生物系统中被观察到,并在神经回路的发展和可塑性中,包括学习和记忆过程中发挥关键作用。
当前突触神经元的脉冲出现在后突触神经元脉冲之前(即 Δ t = t post − t pre > 0 \Delta t = t_{\text{post}} - t_{\text{pre}} > 0 Δt=tpost−tpre>0),突触权重会增加,这种现象称为长时程增强(Long-Term Potentiation, LTP)。
当前突触神经元的脉冲出现在后突触神经元脉冲之后(即 Δ t = t post − t pre < 0 \Delta t = t_{\text{post}} - t_{\text{pre}} < 0 Δt=tpost−tpre<0),突触权重会减小,这种现象称为长时程抑制(Long-Term Depression, LTD)。
STDP的数学表达式比Hebbian学习规则更复杂,常见的公式是:
Δ w i j = { A + exp ( − Δ t / τ + ) if Δ t > 0 − A − exp ( Δ t / τ − ) if Δ t < 0 \Delta w_{ij}=\begin{cases}A_+\exp(-\Delta t/\tau_+)&\text{if }\Delta t>0\\-A_-\exp(\Delta t/\tau_-)&\text{if }\Delta t<0\end{cases} Δwij={A+exp(−Δt/τ+)−A−exp(Δt/τ−)if Δt>0if Δt<0
其中, Δ w i j \Delta w{ij} Δwij是神经元i和j之间权重的变化, Δ t \Delta t Δt是前突触和后突触脉冲之间的时间差异, A + A+ A+和 A − A- A−分别是增强和抑制的幅度, τ + \tau+ τ+和 τ − \tau- τ−分别是增强和抑制的时间常数。