联结
本文介绍什么是联结,为什么要使用联结,如何编写使用联结的SELECT语句。介绍如何对被联结的表使用表别名和聚集函数。
SQL最强大的功能之一就是能在数据检索查询的执行中联结(join)表。联结是利用SQL的SELECT能执行的最重要的操作,很好地理解联结及其语法是学习SQL的一个极为重要的组成部分。
目录
关系表
让我们用一个例子来了解一下什么是关系表
假如有一个包含员工信息的数据库表,其中每格员工的信息占一行。对于每种员工要存储的信息包含了部门id。现在,假如同一个部门有多个员工,那么在何处存储部门信息(如,部门名称,部门办公地点等)呢?将这些数据与员工信息分开存储的理由如下。
- 因为同一部门员工所使用到的部门信息都是相同的,对每个员工重复此信息既浪费时间又浪费存储空间。
- 如果部门信息改变(例如,搬家或电话号码变动),只需改动一次即可。
- 如果有重复数据(即每个员工都存储部门信息),很难保证每次输入该数据的方式都相同。不一致的数据在报表中很难利用。
关键是,相同数据出现多次决不是一件好事,此因素是关系数据库设计的基础。关系表的设计就是要保证把信息分解成多个表,一类数据一个表。各表通过某些常用的值(即关系设计中的关系(relational))互相关联。
在这个例子中,可建立两个表,一个存员工信息,另一个存储部门信息。deparnments表包含所有部门信息,每个供应商占一行,每个供应商具有唯一的标识。此标识称为主键(primary key),可以是部门ID或任何其他唯一值。
外键:(foreign key) 外键为某个表中的一列,它包含另一个表的主键值,定义了两个表之间的关系。关于外键的详细讲解会放在后面的文章中。
可伸缩性(scale) 能够适应不断增加的工作量而不失败。设计良好的数据库或应用程序称之为可伸缩性好(scale well)。
使用联结的原因
正如所述,分解数据为多个表能更有效地存储,更方便地处理,并且具有更大的可伸缩性。但这些好处是有代价的。如果数据存储在多个表中,怎样用单条SELECT语句检索出数据?比如在上述例子中,查询某个员工和其所属部门信息。
答案是使用联结。简单地说,联结是一种机制,用来在一条SELECT语句中关联表,因此称之为联结。使用特殊的语法,可以联结多个表返回一组输出,联结在运行时关联表中正确的行。
重要的是,要理解联结不是物理实体。换句话说,它在实际的数据库表中不存在。联结由MySQL根据需
要建立,它存在于查询的执行当中。
创建联结
联结的创建非常简单,规定要联结的所有表以及它们如何关联即可。
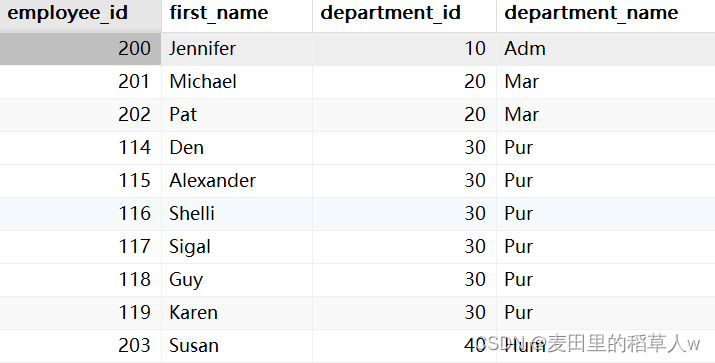
【示例】联结employees和departments表,查询员工及其所属部门信息
sql
SELECT employee_id, first_name, employees.department_id, department_name
FROM employees, departments
WHERE employees.department_id = departments.department_id;运行结果:
完全限定列名 在引用的列可能出现二义性时,必须使用完全限定列名(用一个点分隔的表名和列名)。如果引用一个没有用表名限制的具有二义性的列名,MySQL将返回错误。
where子句的重要性
在一条SELECT语句中联结几个表时,相应的关系是在运行中构造的。在数据库表的定义中不存在能指MySQL如何对表进行联结的东西。你必须自己做这件事情。在联结两个表时,你实际上做的是将第一个表中的每一行与第二个表中的每一行配对。WHERE子句作为过滤条件,它只包含那些匹配给定条件(这里是联结条件)的行。没有WHERE子句,第一个表中的每个行将与第二个表中的每个行配对,而不管它们逻辑上是否可以配在一起,结果就会形成两张表的笛卡尔积
内部联结
上个例子所用的联结称为等值联结(equijoin),它基于两个表之间的相等测试。这种联结也称为内部联结 。其实,对于这种联结可以使用稍微不同的语法来明确指定联结的类型。下面的SELECT语句返回与前面例
子完全相同的数据:
sql
SELECT employee_id, first_name, employees.department_id, department_name
FROM employees INNER JOIN departments
WHERE employees.department_id = departments.department_id;ANSI SQL规范首选INNER JOIN语法。此外,尽管使用WHERE子句定义联结的确比较简单,但是使用明确的
联结语法能够确保不会忘记联结条件,有时候这样做也能影响性能。
SQL对一条SELECT语句中可以联结的表的数目没有限制。创建联结的基本规则也相同。首先列出所有表,然后定义表之间的关系。MySQL在运行时关联指定的每个表以处理联结。这种处理可能是非常耗费资源的,因此应该仔细,不要联结不必要的表。联结的表越多,性能下降越厉害。
表别名
表和列都可以起别名,起别名的好处如下:
- 缩短SQL语句;
- 允许在单条SELECT语句中多次使用相同的表。
【示例】使用表别名,联结employees和departments表,查询员工及其所属部门信息
sql
SELECT employee_id, first_name, e.department_id, department_name
FROM employees AS e INNER JOIN departments as d
WHERE e.department_id = d.department_id;其它类型的联结
自联结
多张相同的表进行连接
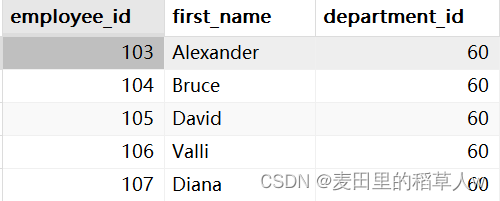
【示例】查询某个员工所在部门的所有员工信息
sql
SELECT e1.employee_id, e1.first_name, e1.department_id
FROM employees AS e1 , employees AS e2
WHERE e1.employee_id = e2.employee_id
AND e2.department_id = 60;运行结果:
自然联结
无论何时对表进行联结,应该至少有一个列出现在不止一个表中(被联结的列)。标准的联结(前一章中介绍的内部联结)返回所有数据,甚至相同的列多次出现。自然联结排除多次出现,使每个列只返回一次。怎样完成这项工作呢?答案是,系统不完成这项工作,由你自己完成它。自然联结是这样一种联结,其中你只能选择那些唯一的列。这一般是通过对表使用通配符(SELECT *),对所有其他表的列使用明确的子集来完成的。
事实上,迄今为止我们建立的每个内部联结都是自然联结,很可能我们永远都不会用到不是自然联结的内部联结。
外部联结
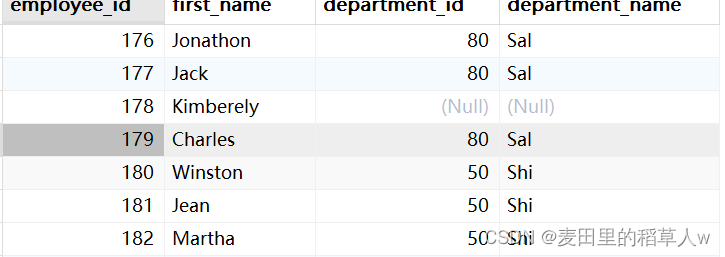
【示例】查询employees表中所有员工及其所属部门信息,包括没有分配部门的员工
sql
SELECT e.employee_id, e.first_name, e.department_id, d.department_name
FROM employees AS e LEFT JOIN departments as d
ON e.department_id = d.department_id;运行结果:
类似于上一章中所看到的内部联结,这条SELECT语句使用了关键字OUTER JOIN来指定联结的类型。但是,与内部联结关联两个表中的行不同的是,外部联结还包括没有关联行的行。在使用OUTER JOIN语法时,必须使用RIGHT或LEFT关键字指定包括其所有行的表(RIGHT指出的是OUTER JOIN右边的表,而LEFT指出的是OUTER JOIN左边的表)。
使用联结的要点
- 注意所使用的联结类型。一般我们使用内部联结,但使用外部联结也是有效的。
- 保证使用正确的联结条件,否则将返回不正确的数据。
- 应该总是提供联结条件,否则会得出笛卡儿积。
- 在一个联结中可以包含多个表,甚至对于每个联结可以采用不同的联结类型。虽然这样做是合法的,一般也很有用,但应该在一起测试它们前,分别测试每个联结。这将使故障排除更为简单。