今天在处理接口请求速度慢的问题,惊奇的发现加了索引,但还是请求很忙。由于card_stop_info表有300w条数据,这时候关联查询非常慢,于是我加上匹配项索引,但是发现依然没有改变速度。。这时候去搜了一下才知道pgsql的to_char函数可能会导致索引无法充分利用,也就是说必须把to_char改成TIMESTAMP去定义日期。。。反正使用函数的话都有可能会导致索引无法充分利用,像DATE()、TO_CHAR()函数等等。。


使用 to_char 函数可能会导致索引无法充分利用的情况,因为函数会改变列的数据类型,这样就无法使用索引来加速查询。在某些情况下,数据库可能无法优化这类查询,尤其是当对列进行转换或者应用函数后。
在我的SQL语句中,to_char(c1.binder_gen_time, 'YYYY-MM-DD') 会将 binder_gen_time 转换为字符串,这会导致无法使用日期列上的索引。同样地,TO_CHAR(c1.binder_gen_time, 'HH24:MI:SS') 也会导致相同的问题。
为了让索引得到充分利用,应该尽量避免在查询条件中对列使用函数,特别是在大数据量的情况下。如果可能的话,应该直接使用列的原始值进行比较,以便数据库能够利用索引来加速查询。
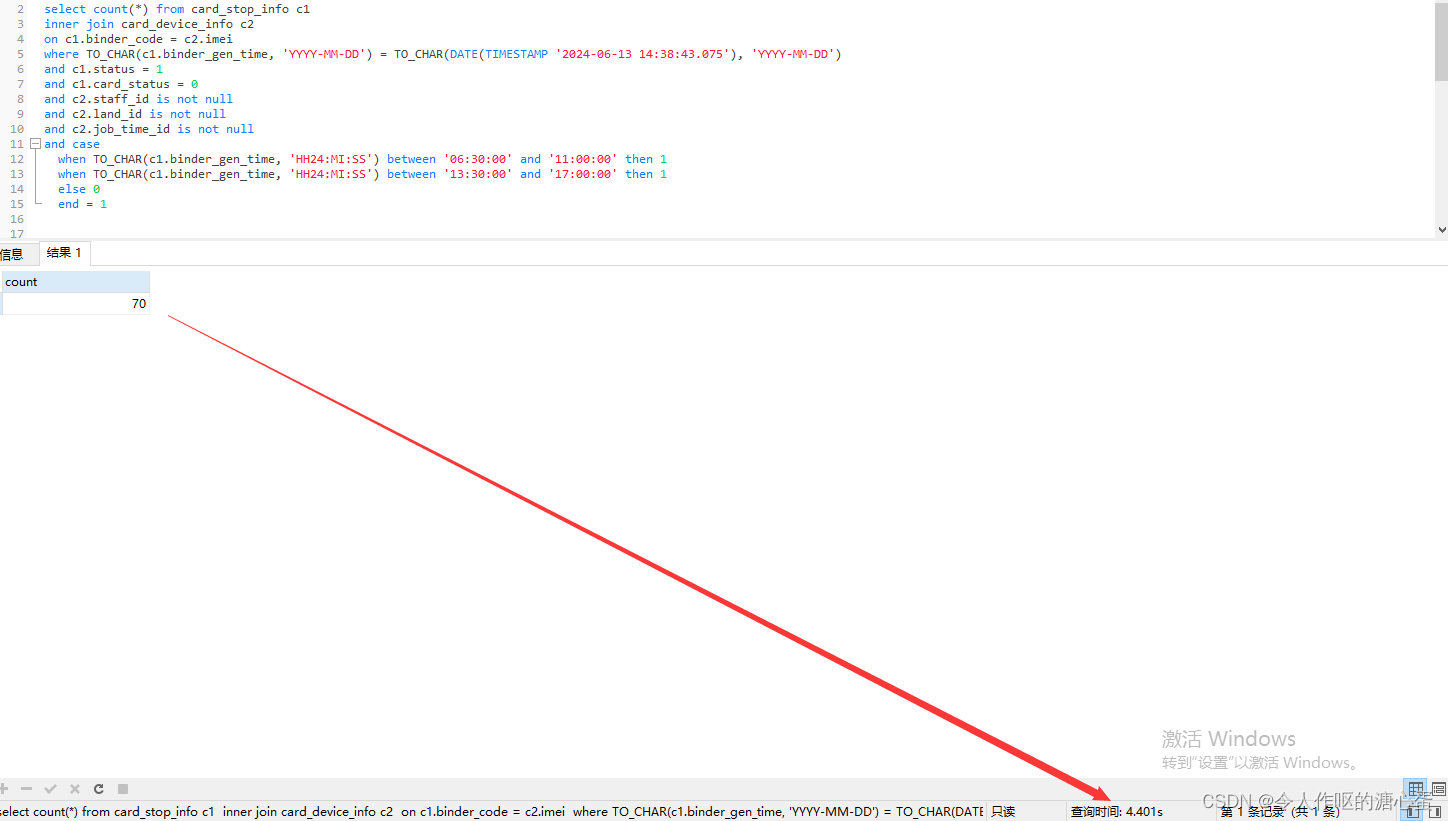
修改前我的sql语句
sql
select count(*) from card_stop_info c1
inner join card_device_info c2
on c1.binder_code = c2.imei
where TO_CHAR(c1.binder_gen_time, 'YYYY-MM-DD') = TO_CHAR(DATE(TIMESTAMP '2024-06-13 14:38:43.075'), 'YYYY-MM-DD')
and c1.status = 1
and c1.card_status = 0
and c2.staff_id is not null
and c2.land_id is not null
and c2.job_time_id is not null
and case
when TO_CHAR(c1.binder_gen_time, 'HH24:MI:SS') between '06:30:00' and '11:00:00' then 1
when TO_CHAR(c1.binder_gen_time, 'HH24:MI:SS') between '13:30:00' and '17:00:00' then 1
else 0
end = 1
查询时间花费了4s左右。。
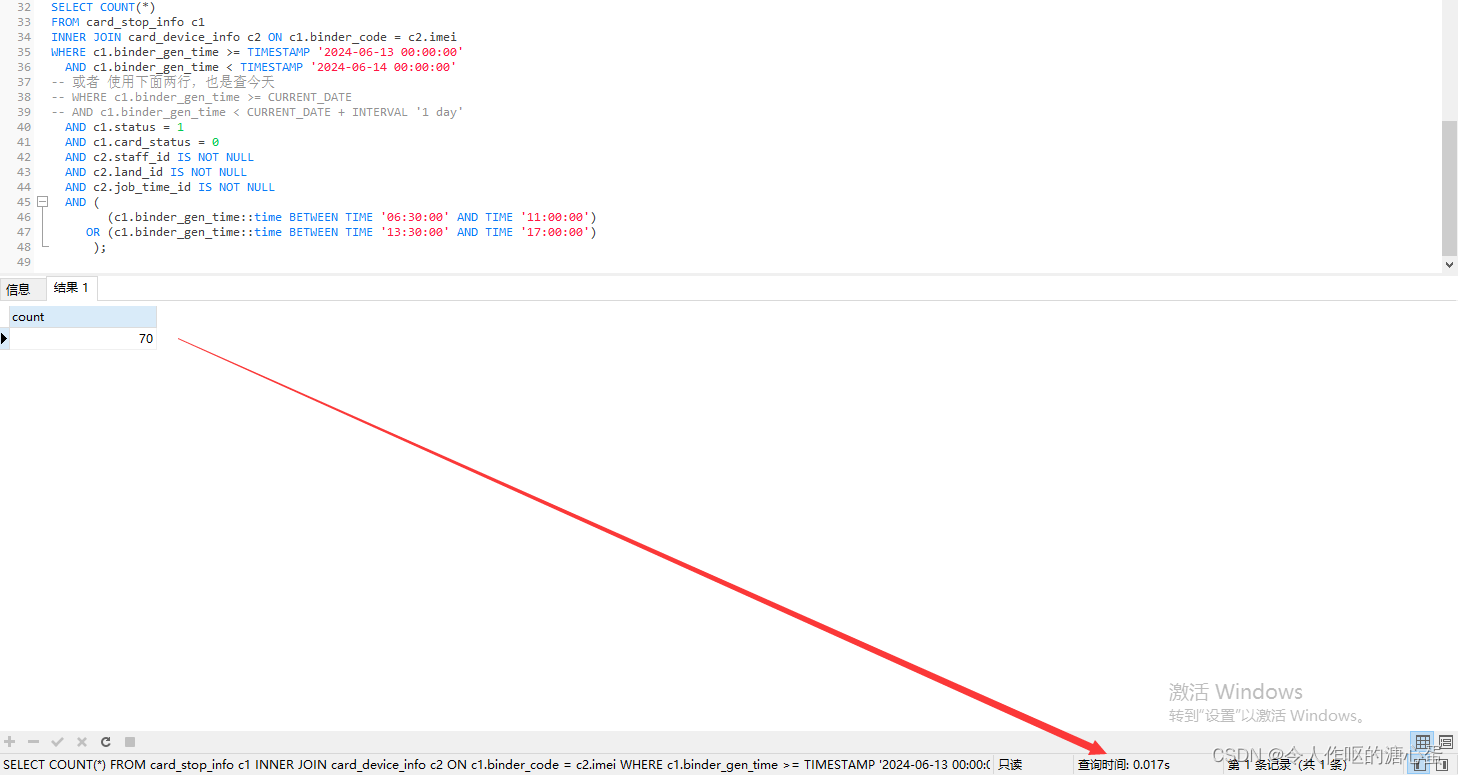
修改后我的sql语句
sql
SELECT COUNT(*)
FROM card_stop_info c1
INNER JOIN card_device_info c2 ON c1.binder_code = c2.imei
WHERE c1.binder_gen_time >= TIMESTAMP '2024-06-13 00:00:00'
AND c1.binder_gen_time < TIMESTAMP '2024-06-14 00:00:00'
-- 或者 使用下面两行,也是查今天
-- WHERE c1.binder_gen_time >= CURRENT_DATE
-- AND c1.binder_gen_time < CURRENT_DATE + INTERVAL '1 day'
AND c1.status = 1
AND c1.card_status = 0
AND c2.staff_id IS NOT NULL
AND c2.land_id IS NOT NULL
AND c2.job_time_id IS NOT NULL
AND (
(c1.binder_gen_time::time BETWEEN TIME '06:30:00' AND TIME '11:00:00')
OR (c1.binder_gen_time::time BETWEEN TIME '13:30:00' AND TIME '17:00:00')
);