一 ChatGLM-6B 介绍
ChatGLM-6B 是一个开源的、支持中英双语的对话语言模型,新一代开源模型 ChatGLM3-6B 已发布,拥有10B以下最强的基础模型,支持工具调用(Function Call)、代码执行(Code Interpreter)、Agent 任务等功能,结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。
二 在 window平台 搭建ChatGLM3-6B
1 在github下拉该项目代码:
1 下拉项目源代码:
https://github.com/THUDM/ChatGLM-6B
bash
git clone https://github.com/THUDM/ChatGLM-6B
cd ChatGLM-6B
2 下载项目数据模型
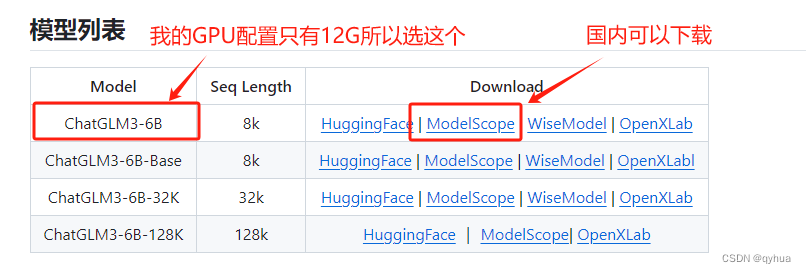
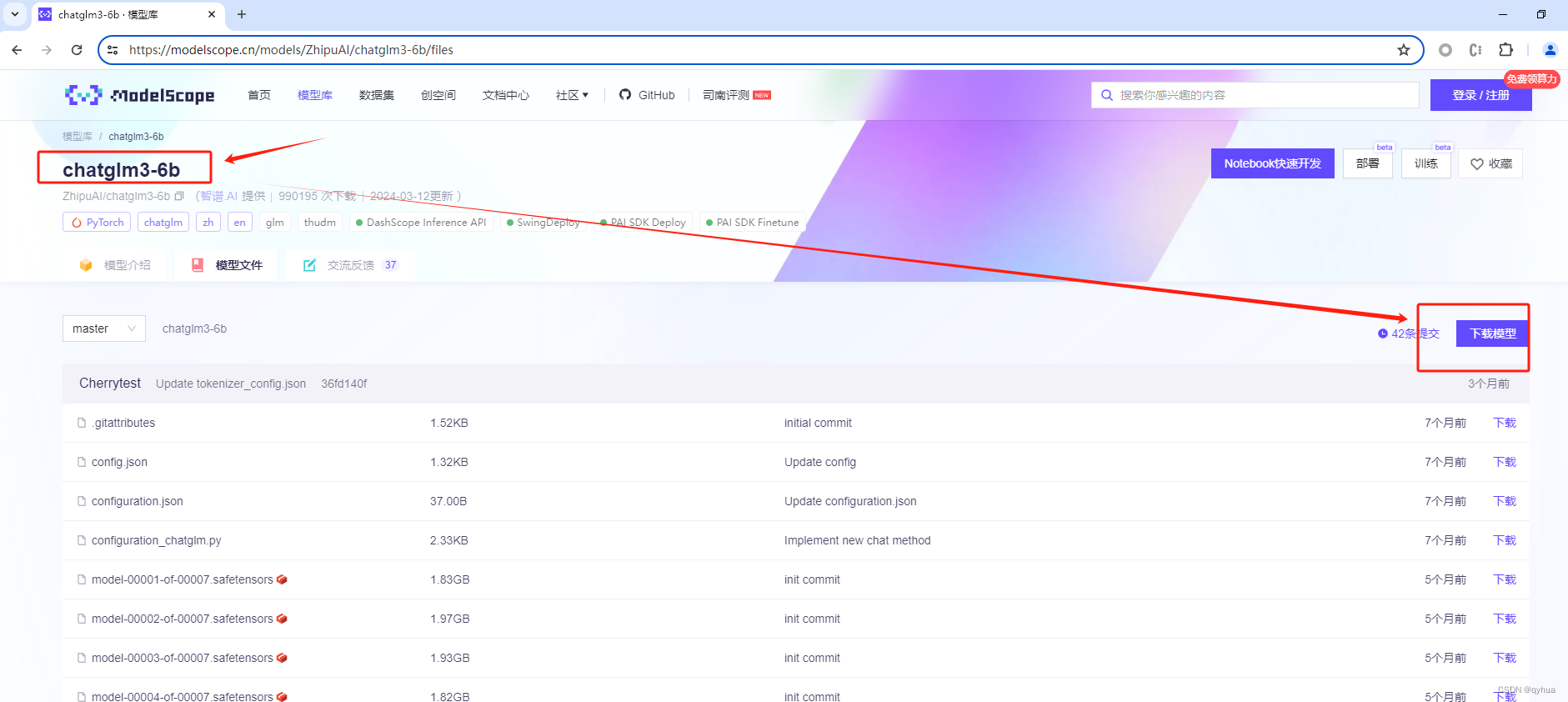
下载的模型数据保存位置:
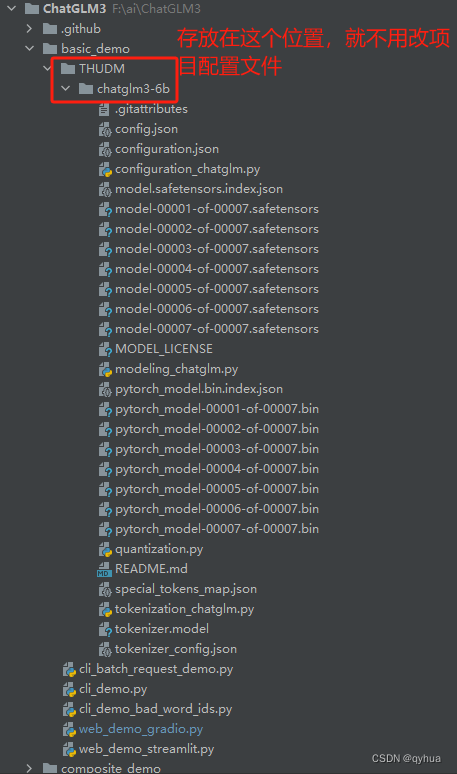
如果保存在别的地方需要指定配置模型路径的系统变量,也可以直接修改以下代码,如下图:
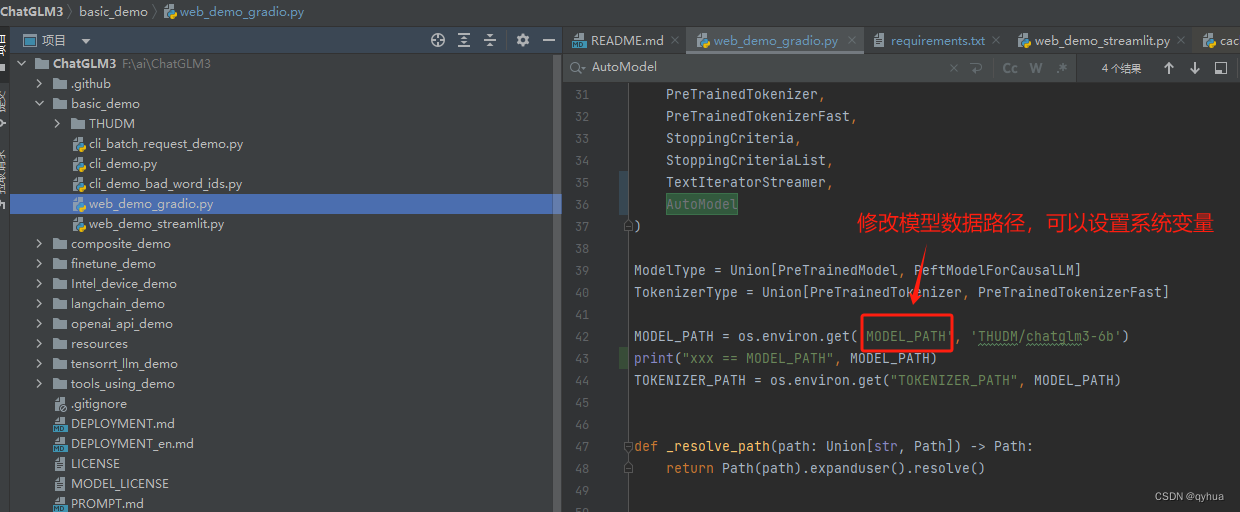
2 环境安装
使用 pip 安装依赖:pip install -r requirements.txt
bash
pip install -r requirements.txt**注意:**项目没有有明确说支持什么平台,当安装依赖时会报错,因为有一个vllm是不支持windows平台的,所以安装依赖时要注释掉一个依赖 vllm,其作用是加速推理项目可以不用,该框架的官方网站明确只支持linux,如下图:
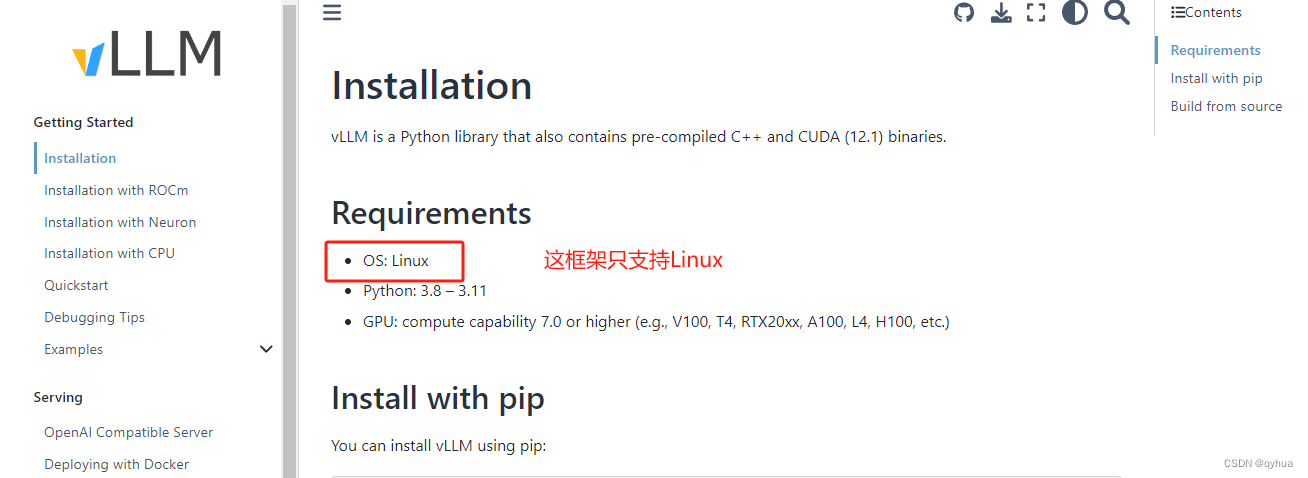
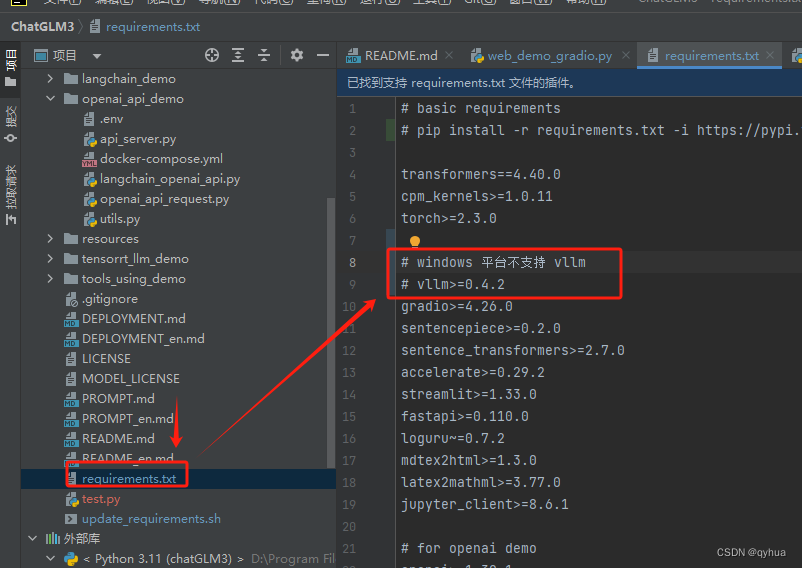
检查pytorch环境
python
import torch
if __name__ == '__main__':
# 检测cuda环境
print(torch.__version__)
print(torch.cuda.is_available())
print(torch.version.cuda)pytorch正常,cuda可用如下图:
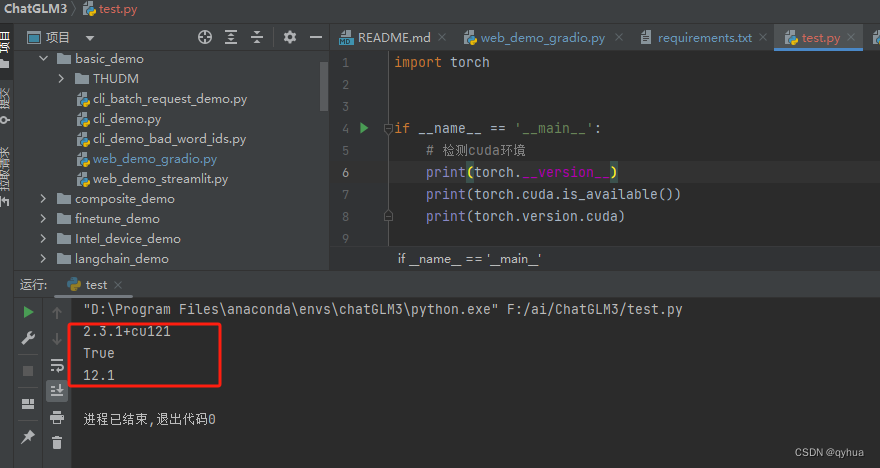
如果这一步有问题,请查看之前的文章:https://blog.csdn.net/qyhua/article/details/136248165
3 启动项目
启动演示项目:
bash
cd basic_demo
python web_demo_gradio.py启动过程中,大概要有4G左右的空闲内存,如果内存不够启动失败,且没有任何提示,如下图:
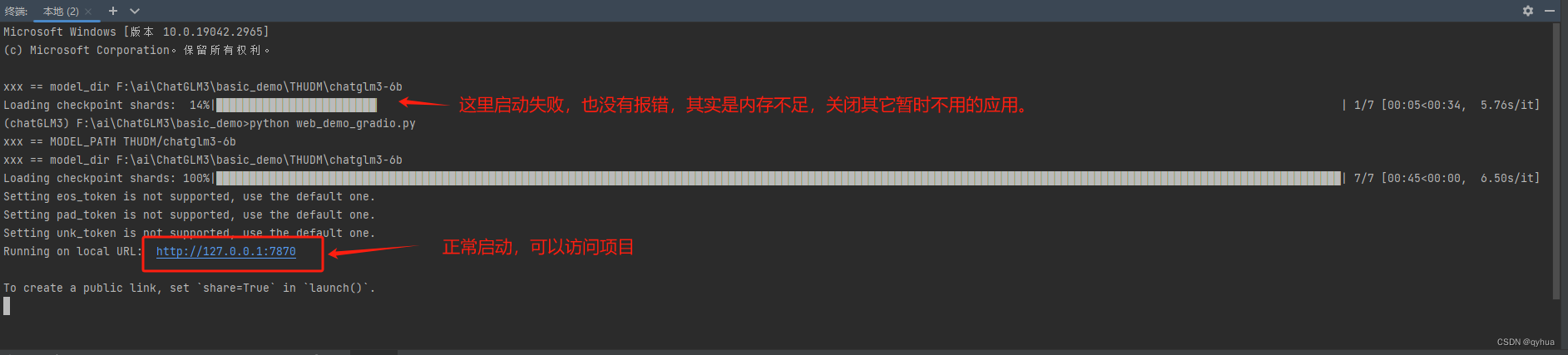
测试成功如下图:
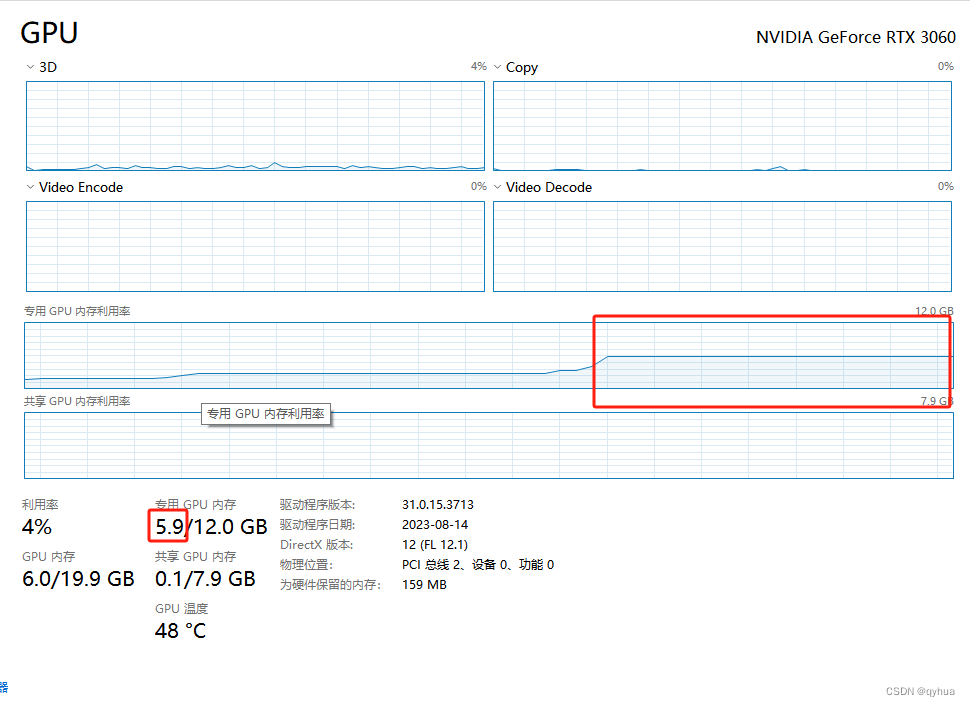
 由于我的电脑配置低,3060的显卡只有12G显存,所以这里改了一下代码。
由于我的电脑配置低,3060的显卡只有12G显存,所以这里改了一下代码。
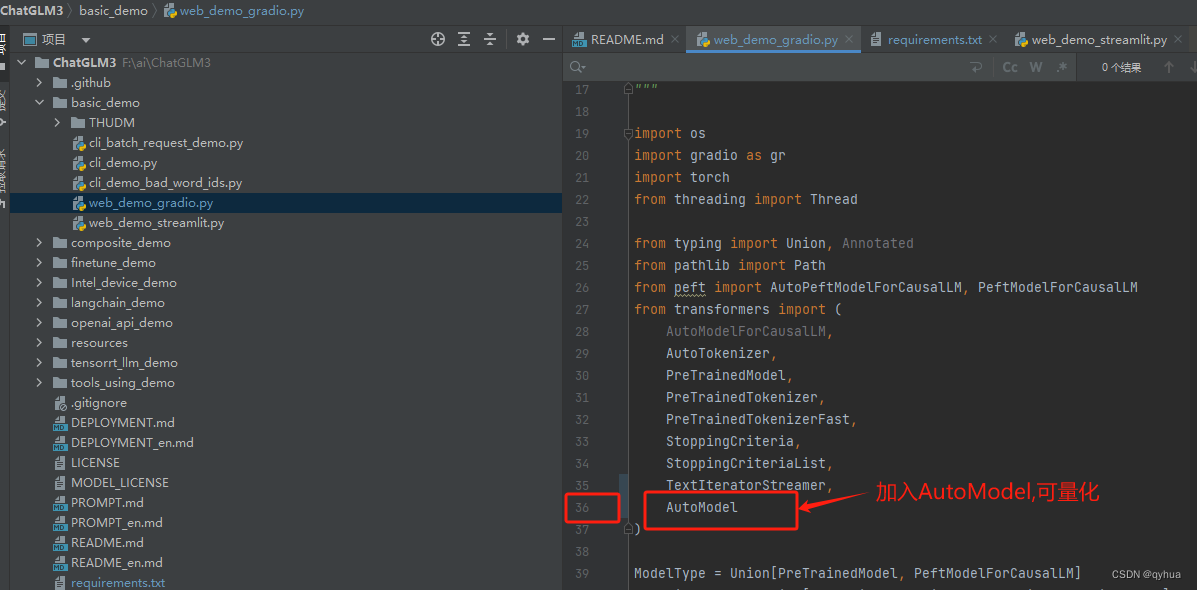
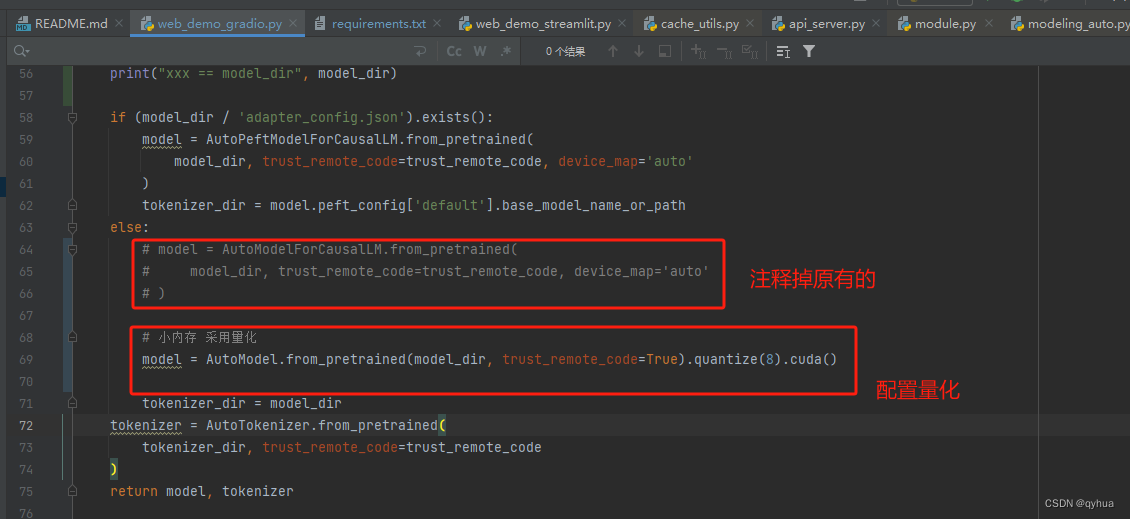
这里测试了一下,当量化参数设置成8 时GPU内存大概使用了8G多,当设置成4时,只用了4G多,如下图:
bash
model = AutoModel.from_pretrained(model_dir, trust_remote_code=True).quantize(8).cuda()量化参数设置成8时的效果图,回复比4快。
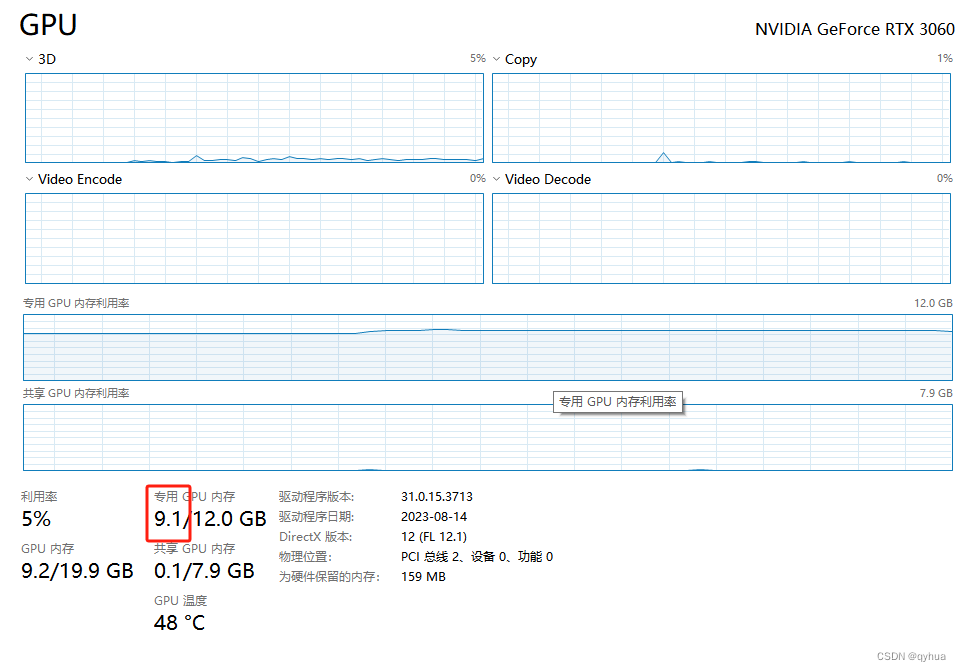
量化参数设置成4时 ,系统本身用了1.5G,模型大概使用了4G多。如下图: