大小端
什么是大小端
大端模式(Big-endian),是指数据的高字节,保存在内存的低地址中,而数据的低字节,保存在内存的高地址中;
小端模式(Little-endian),是指数据的高字节保存在内存的高地址中,而数据的低字节保存在内存的低地址中.
unsigned int a = 0x12345678;
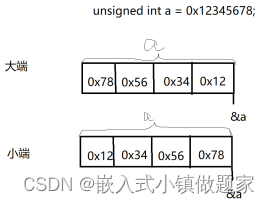
为什么会有大小端模式之分呢?
这是因为在计算机系统中,我们是以字节为单位的,每个地址单元都对应着一个字节,一个字节为 8bit。但是在C语言中除了8bit的char之外,还有16bit的short型,32bit的long型(要看具体的编译器),另外,对于位数大于 8位的处理器,例如16位或者32位的处理器,由于寄存器宽度大于一个字节,那么必然存在着一个如何将多个字节安排的问题。因此就导致了大端存储模式和小端存储模式。
我们常用的X86结构是小端模式,而KEIL C51则为大端模式,很多的ARM,DSP都为小端模式。
怎么判断大小端
获取一个数据的低地址上的数据看是高字节还是低字节,
如果是高字节就是大端否则就是小端。
第一种:共用体声明
union data
{
int a;
char b;
};
int main()
{
union data t;
t.a = 0x12345678;
if(t.b == 0x78)
{
printf("小端");
}
else
{
printf("大端");
}
}第二种:指针证明
int main()
{
int a = 0x12345678;
char *p = (char *)&a;
if(*p = 0x78)
{
printf("小端");
}
else
{
printf("大端");
}
}大小端的数据转换
unsigned int reversebytes_uint32t(unsigned int value)
{
return (value & 0x000000FFU) << 24 | (value & 0x0000FF00U) << 8 | (value & 0x00FF0000U) >> 8 | (value & 0xFF000000U) >> 24);
}
int main()
{
unsigned int v = 0x12345678;
unsigned int t = reversebytes_uint32t(v);
printf("%u",t);
}