Python武器库开发-武器库篇之链接提取器(六十)
链接提取器介绍
链接提取器(Link Extractor)是一种用于从网页中提取链接的工具。它可以从网页的源代码中识别出所有的链接,并将这些链接提取出来。链接提取器可以用于各种目的,例如抓取网页数据、建立网站地图、搜索引擎优化等。
链接提取器通常使用正则表达式或HTML解析器来识别和提取链接。正则表达式是一种强大的模式匹配工具,它可以根据特定的模式来匹配和提取字符串。HTML解析器可以解析网页的HTML代码,并从中提取出链接。
链接提取器可以提取各种类型的链接,包括文本链接、图片链接、音视频链接等。它可以提取出绝对链接(包含完整的URL)和相对链接(相对于当前网页的URL)。
使用链接提取器可以简化从网页中提取链接的过程,并提高提取链接的效率。它可以帮助我们快速获取所需的链接,并进行后续的处理和分析。
链接提取器代码实现
接下来我们就用python开发一段 链接提取器,代码内容如下:
python
#!/usr/bin/env python
from functools import total_ordering
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin, urlparse
import logging
# 内链
internal_urls = set()
# 外链
external_urls = set()
total_urls_visited = 0
def is_valid(url):
# 检查url
# 协议(scheme) 网络位置(netloc) 路径(path)查询参数(query)
parsed = urlparse(url)
loc = bool(parsed.netloc)
sche = bool(parsed.scheme)
return loc and sche
def get_all_website_links(url):
urls = set()
# 提取域名,用来判断是外链还是内链
domain_name = urlparse(url).netloc
soup = BeautifulSoup(requests.get(url).content, "lxml")
# 获取所有的a标签
for a_tag in soup.find_all("a"):
href = a_tag.attrs.get("href")
if not href or href == "":
continue
href = urljoin(url, href)
# 剔除get请求后面的参数
parsed_href = urlparse(href)
href = parsed_href.scheme + "://" + parsed_href.netloc + parsed_href.path # 后面的get参数给过滤掉了
if not is_valid(href) or href in internal_urls:
continue
# 判断是否为外链
if domain_name not in href:
print(f"外部链接:{href}")
external_urls.add(href)
continue
print(f"内部链接:{href}")
urls.add(href)
internal_urls.add(href)
return urls
# 递归
def crawl(url, max_url=15):
global total_urls_visited
total_urls_visited += 1
print(f"正在爬取:{url}")
links = get_all_website_links(url)
for link in links:
if total_urls_visited > max_url:
break
crawl(link, max_url=max_url)
if __name__ == "__main__":
url = "https://www.baidu.com/"
crawl(url=url, max_url=30)
domain_name = urlparse(url).netloc
print("总内部连接数为:", len(internal_urls))
print("总外部连接数为:", len(external_urls))
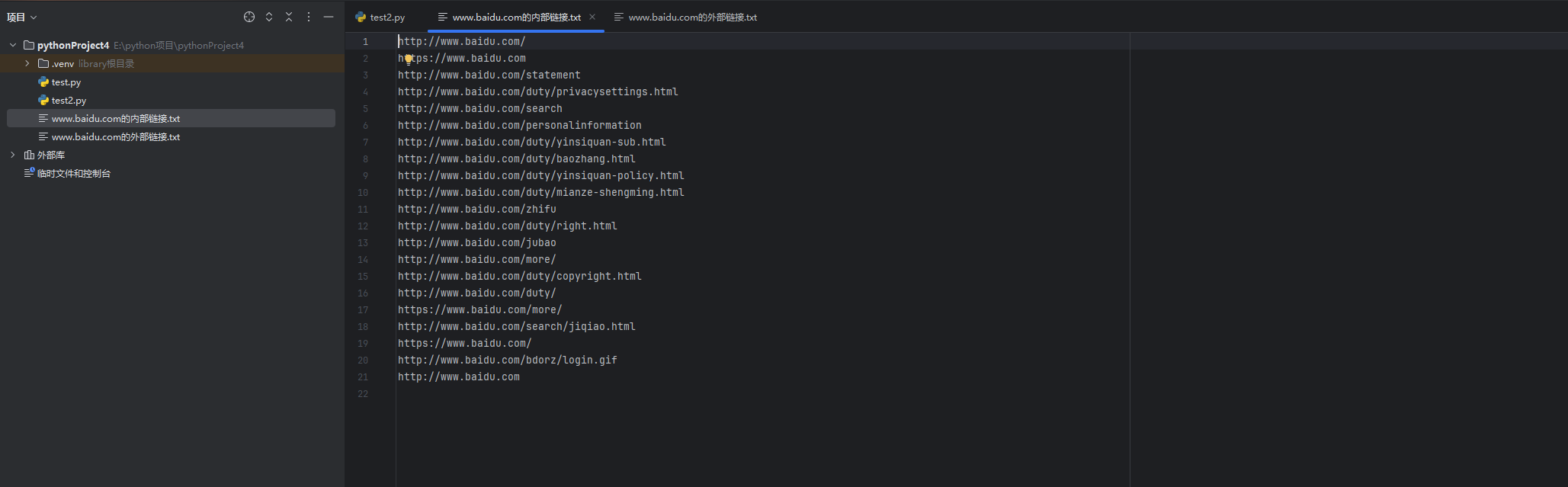
with open(f"{domain_name}的内部链接.txt", "w") as f:
for internal_url in internal_urls:
print(internal_url.strip(), file=f)
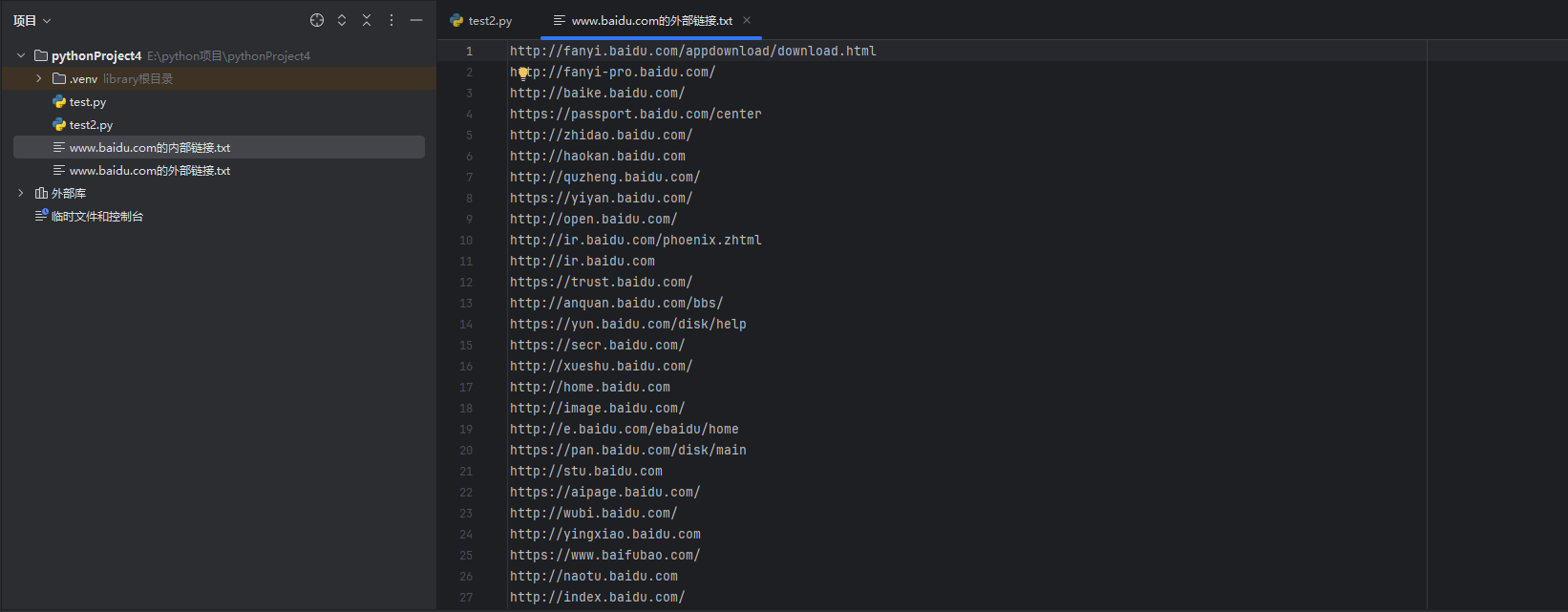
with open(f"{domain_name}的外部链接.txt", "w") as f:
for external_url in external_urls:
print(external_url.strip(), file=f)代码逻辑分析
这段代码是一个简单的网页爬虫,用于爬取指定网页的内部链接和外部链接。
首先,在代码中导入了一些必要的模块,包括functools、requests、bs4、urllib.parse和logging。
然后,定义了一些全局变量,包括内链集合internal_urls、外链集合external_urls和已访问的链接总数total_urls_visited。
接下来,定义了一个is_valid函数,用于检查一个链接是否合法。函数中使用urlparse对链接进行解析,判断是否具有有效的网络位置(netloc)和协议(scheme)。
然后,定义了一个get_all_website_links函数,用于获取指定网页的所有链接。函数中使用urlparse获取域名,然后使用requests.get获取网页内容,再使用BeautifulSoup对网页进行解析。然后,遍历所有的<a>标签,提取href属性,并进行一系列处理,包括合并相对链接为绝对链接、剔除链接中的查询参数等。最后,判断链接是否合法,以及是内链还是外链,将链接分别添加到内链集合和外链集合中,并返回所有的链接。
接下来,定义了一个递归函数crawl,用于递归爬取链接。函数中先增加已访问的链接总数,并打印正在爬取的链接。然后,调用get_all_website_links函数获取链接,并遍历链接,递归调用crawl函数。当已访问的链接总数超过指定的最大链接数时,跳出循环。
最后,在main函数中,指定要爬取的初始链接和最大链接数,并调用crawl函数进行爬取。最后,输出总内部链接数和总外部链接数,并将内链集合和外链集合分别写入文件中。
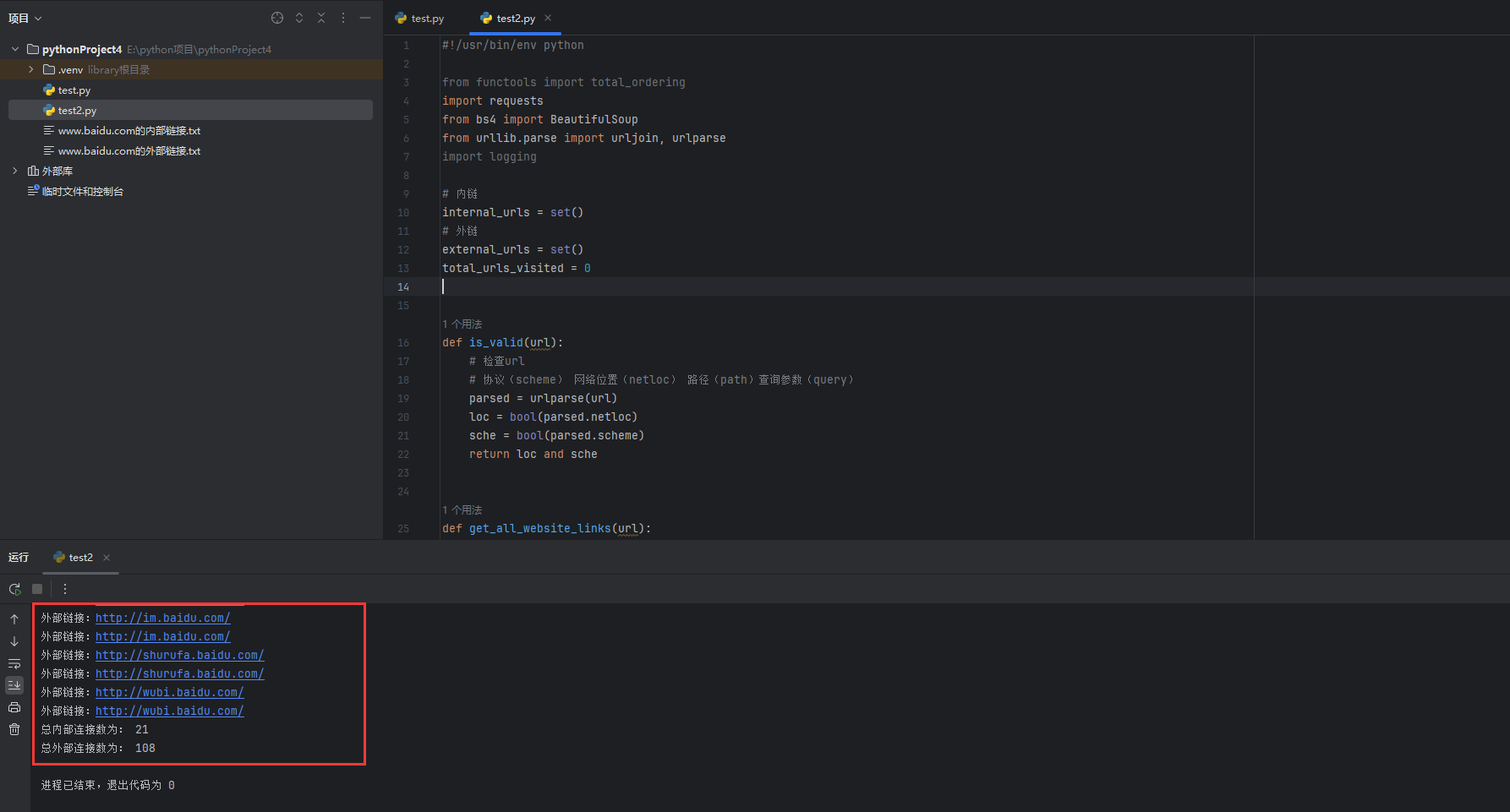
运行效果图
如下是我们这串代码的实际运行效果图: