目录
[3. MySQL常用的存储引擎](#3. MySQL常用的存储引擎)
[2.MyISAM 表支持 3 种不同的存储格式](#2.MyISAM 表支持 3 种不同的存储格式)
[3.MyISAM 和 InnoDB 的区别?](#3.MyISAM 和 InnoDB 的区别?)
[4.总结一下 MySQL 整个查询执行过程,总的来说分为五个步骤:](#4.总结一下 MySQL 整个查询执行过程,总的来说分为五个步骤:)
一、存储引擎
1.概念
● MySQL中的数据用各种不同的技术存储在文件中,每一种技术都使用不同的存储机制、索引技巧、锁定水平并最终提供不同的功能和能力,这些不同的技术以及配套的功能在MySQL中称为存储引擎
● 存储引擎是MySQL将数据存储在文件系统中的存储方式或者存储格式
总结:MySQL数据库中的组件,负责执行实际的数据I/O操作MySQL系统中,存储引擎处于文件系统之上,在数据保存到数据文件之前会传输到存储引擎,之后按照各个存储引擎的存储格式进行存储
2.MySQL逻辑架构
MySQL逻辑架构整体分为三层,最上层为客户端层,并非MySQL所独有,诸如:连接处理、授权认证、安全等功能均在这一层处理。
MySQL大多数核心服务均在中间这一层,包括查询解析、分析、优化、缓存、内置函数(比如:时间、数学、加密等函数)。所有的跨存储引擎的功能也在这一层实现:存储过程、触发器、视图等。
最下层为存储引擎,其负责MySQL中的数据存储和提取。和Linux下的文件系统类似,每种存储引擎都有其优势和劣势。中间的服务层通过API与存储引擎通信,这些API接口屏蔽了不同存储引擎间的差异。

3. MySQL常用的存储引擎
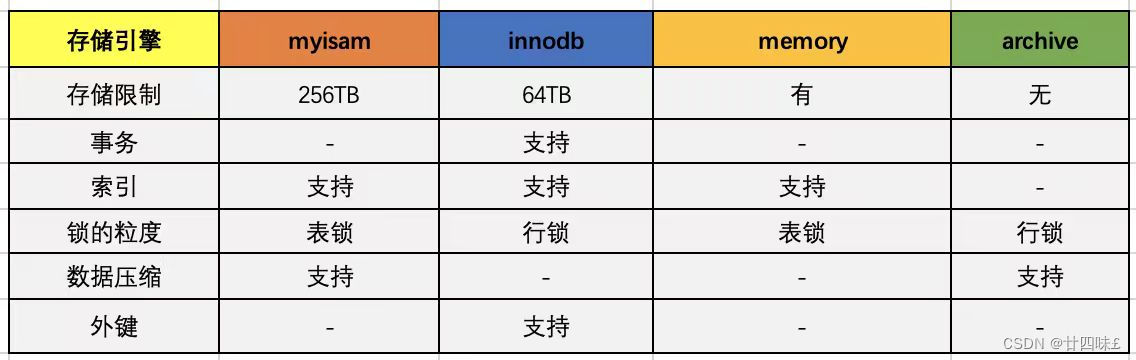
**1)MyISAM:**不支持事务和外键约束,占用资源较小,访问速度快,表级锁定,支持全文索引,适用于不需要事务处理,单独写入或查询的应用场景。
**2)InnoDB:**支持事务处理、外键约束,缓存能力较好,支持行级锁定,读写并发能力较好,5.5版本后支持全文索引,适用于一致性要求高、数据更新频繁的应用场景。
二、MyISAM
1.特点
1)MyISAM不支持事务,也不支持外键约束,只支持全文索引,数据文件和索引文件是分开保存的
2)访问速度快,对事务完整性没有要求MyISAM 适合查询、插入为主的应用
3)MyISAM在磁盘上存储成三个文件,文件名和表名都相同,但是扩展名分别为:
●.frm 文件存储表结构的定义
●数据文件的扩展名为.MYD(MYData)
●索引文件的扩展名是.MYI(MYIndex)
4)表级锁定形式,数据在更新时锁定整个表
5)数据库在读写过程中相互阻塞
●会在数据写入的过程阻塞用户数据的读取
●也会在数据读取的过程中阻塞用户的数据写入数据单独写入或读取,速度过程较快且占用资源相对少
6)MyIAM支持的存储格式
●静态表
●动态表
●压缩表
2.MyISAM 表支持 3 种不同的存储格式
1)静态(固定长度)表
静态表是默认的存储格式。静态表中的字段都是非可变字段,这样每个记录都是固定长度的,这种存储方式的优点是存储非常迅速,容易缓存,出现故障容易恢复;缺点是占用的空间通常比动态表多。
2)动态表
动态表包含可变字段,记录不是固定长度的,这样存储的优点是占用空间较少,但是频繁的更新、删除记录会产生碎片,需要定期执行 OPTIMIZE TABLE 语句或 myisamchk -r 命令来改善性能,并且出现故障的时候恢复相对比较困难。
3)压缩表
压缩表由 myisamchk 工具创建,占据非常小的空间,因为每条记录都是被单独压缩的,所以只有非常小的访问开支。
3.MyISAM适用的生产场景
●公司业务不需要事务的支持
●单方面读取或写入数据比较多的业务
●MyISAM存储引擎数据读写都比较频繁场景不适合
●使用读写并发访问相对较低的业务
●数据修改相对较少的业务
●对数据业务一致性要求不是非常高的业务
●服务器硬件资源相对比较差
三、InnoDB
1.InnoDB特点
●支持事务,支持4个事务隔离级别
●MySQL从5.5.5版本开始,默认的存储引擎为InnoDB
●读写阻塞与事务隔离级别相关
●能非常高效的缓存索引和数据
●表与主键以簇的方式存储
●支持分区、表空间,类似oracle数据库
●支持外键约束,5.5前不支持全文索引,5.5后支持全文索引
●对硬件资源要求还是比较高的场合
●行级锁定,但是全表扫描仍然会是表级锁定
●InnoDB 中不保存表的行数,如select count(*)from table; 时InnoDB 需要扫描一遍整个表来计算有多少行,但是MyISAM 只要简单的读出保存好的行数即可。需要注意的是当 count(*)语句包含 where 条件时 MyISAM 也需要扫描整个表
●对于自增长的字段,InnoDB 中必须包含只有该字段的索但是在 MyISAM 表中可以和其他字段一起建立组合索引
●清空整个表时,InnoDB 是一行一行的删除,效率非常慢MyISAM 则会重建表
2.InnoDB适用生产场景分析
●业务需要事务的支持
●行级锁定对高并发有很好的适应能力,但需确保查询是通过索引来完成
●业务数据更新较为频繁的场景,如:论坛,微博等
●业务数据一致性要求较高,如:银行业务
●硬件设备内存较大,利用InnoDB较好的缓存能力来提高内存利用率,减少磁盘I0的压力
3.MyISAM 和 InnoDB 的区别?
MyISAM:不支持事务、外键约束,只支持表级锁定,适合单独的查询和插入的操作,读写会相互阻塞,支持全文索引,硬件资源占用较少,数据文件和索引文件是分开存储的(表结构文件.frm ,数据文件MYD,索引文件.MYI)
InnoDB:支持事务、外键约束,只支持行级锁定(在全表扫描时仍会表级锁定),读写并发能力好,也支持全文索引,缓存能力较好可以减少磁盘IO的压力,数文件也是索引文件,存储成:
4.总结一下 MySQL 整个查询执行过程,总的来说分为五个步骤:
1)客户端向 MySQL 服务器发送一条查询请求
2)服务器首先检查查询缓存,如果命中缓存,则立刻返回存储在缓存中的结果,否则进入下一阶段。
3)服务器进行 SQL 解析、预处理、再由优化器生成对应的执行计划。
4)MySQL 根据执行计划,调用存储引擎的 API 来执行查询。
5)将结果返回给客户端,同时缓存查询结果。
四、存储引擎管理操作
1.查看表使用的存储引擎
方法一:
show table status from 库名 where name='表名'\G
方法二:
use 库名;
show create table 表名;
2.修改存储引擎
1)通过 alter table 修改
use 库名;
alter table 表名 engine=MyISAM;
2)通过修改 /etc/my.cnf 配置文件,指定默认存储引擎并重启服务
vim /etc/my.cnf
......
mysqld
......
default-storage-engine=INNODB
systemctl restart mysql.service
注意:此方法只对修改了配置文件并重启mysql服务后新创建的表有效,已经存在的表不会有变更。
3)通过 create table 创建表时指定存储引擎
use 库名;
create table 表名(字段1 数据类型,...) engine=MyISAM;
//InnoDB行锁与索引的关系
InnoDB行锁是通过给索引项加锁来实现的。
delete from t1 where id=1;
如果id字段是主键,innodb对于主键索引,会直接锁住整行记录。
delete from t1 where name='aaa';
如果name字段是普通索引,会锁住索引的两行记录。
delete from t1 where age=23;
如果age字段没有索引,会使用全表扫描过滤,这时表上的各行记录都将加上锁。
五、死锁现象
1.概念
死锁:是指两个或两个以上的事务在执行过程中,因争夺锁资源而造成的一种互相等待的现象,若无外力作用,事务都将无法继续运行。此时称系统处于死锁状态或系统产生了死锁。
例如,如果事务A锁住了记录1并等待记录2,而事务B锁住了记录2并等待记录1,这样两个事务就发生了死锁现象。计算机系统中,如果系统的资源分配策略不当,更常见的可能是程序员写的程序有错误等,则会导致进程因竞争资源不当而产生死锁的现象。
2.死锁导致长时间阻塞的危害
众所周知,数据库的连接资源是很珍贵的,如果一个连接因为事务阻塞长时间不释放,那么后面新的请求要执行的sql也会排队等待,越积越多,最终会拖垮整个应用。一旦你的应用部署在微服务体系中而又没有做熔断处理(当某服务出现不可用或响应超时的情况时,会暂时停止对该服务的调用),由于整个链路被阻断,那么就会引发雪崩效应,导致很严重的生产事故。
案例
create table t1(id int primary key, name char(3), age int);
insert into t1 values(1,'aaa',22);
insert into t1 values(2,'bbb',23);
insert into t1 values(3,'aaa',24);
insert into t1 values(4,'bbb',25);
insert into t1 values(5,'ccc',26);
insert into t1 values(6,'zzz',27);
session 1 session 2
begin;
select * from t1 where id=1 for update; begin;
select * from t1 where id=2 for update;
select * from t1 where id=2 for update;#等待
select * from t1 where id=1 for update;#死锁发生3.如何尽可能避免死锁?
1)设置锁等待超时时间:即两个事务相互等待时,一旦等待时间超过了这个时间之后,那么超时事务回滚释放资源,另一个事务就能正常执行了。
在 InnoDB 存储引擎中,参数 innodb_lock_wait_timeout 是用来设置超时时间的,默认值为 50 秒。 show VARIABLES like 'innodb_lock_wait_timeout';
参数 innodb_rollback_on_timeout 表示是否在等待超时时对进行中的事务进行回滚操作(默认是OFF,代表不回滚)。
2)主动开启死锁检测:当 innodb 检测发现死锁之后,就会进行回滚死锁的事物。
show VARIABLES like 'innodb_deadlock_detect'; #查看当前死锁检测是否开启
set global innodb_deadlock_detect = ON; #ON为开启死锁检测,OFF为关闭
3)使用更合理的业务逻辑。对于数据库的多表操作时,尽量按照相同的顺序进行处理,尽量避免同时锁定多个资源。
4)保持事务简短。减少对资源的占用时间和占用范围,避免长事务,减少完成事务可能的延迟并释放锁。
5)为表添加合理的索引。如果不使用索引将会发生全表扫描,扫描时间长,占用资源多,且耗时,会导致死锁的概率大大增加。
6)降低隔离级别。如果业务允许,将隔离级别调低也是较好的选择,比如将隔离级别从RR调整为RC,可以避免掉很多因为间隙锁造成的死锁。
7)多读写少的场景下使用乐观锁机制,读取数据不上锁,在读的情况下可以共享资源,这样可以省去了锁的开销,提高了吞吐量。
4.乐观锁
乐观锁在操作数据时非常乐观,认为别人不会同时修改数据。因此乐观锁不会上锁,只是在执行更新的时候判断一下在此期间别人是否修改了数据,如果别人修改了数据则放弃操作,否则执行操作。适用于读多写少的场景。
SELECT * from t1 where id = 1 lock in share MODE;
5.悲观锁
悲观锁在操作数据时比较悲观,认为别人会同时修改数据。因此操作数据时直接把数据锁住,直到操作完成后才会释放锁;上锁期间其他人不能修改数据。一般适用于写多的场景。
SELECT * from t1 where id = 1 for update;
总结
主流的存储引擎技术
查看和修改存储引擎的方法
死锁