正则表达式和Python 语言
在了解了关于正则表达式的全部知识后,开始查看Python 当前如何通过使用re 模块来
支持正则表达式,re 模块在古老的Python 1.5 版中引入,用于替换那些已过时的regex 模块
和regsub 模块------这两个模块在Python 2.5 版中移除,而且此后导入这两个模块中的任意一
个都会触发ImportError 异常。
re 模块支持更强大而且更通用的Perl 风格(Perl 5 风格)的正则表达式,该模块允许多
个线程共享同一个已编译的正则表达式对象,也支持命名子组。
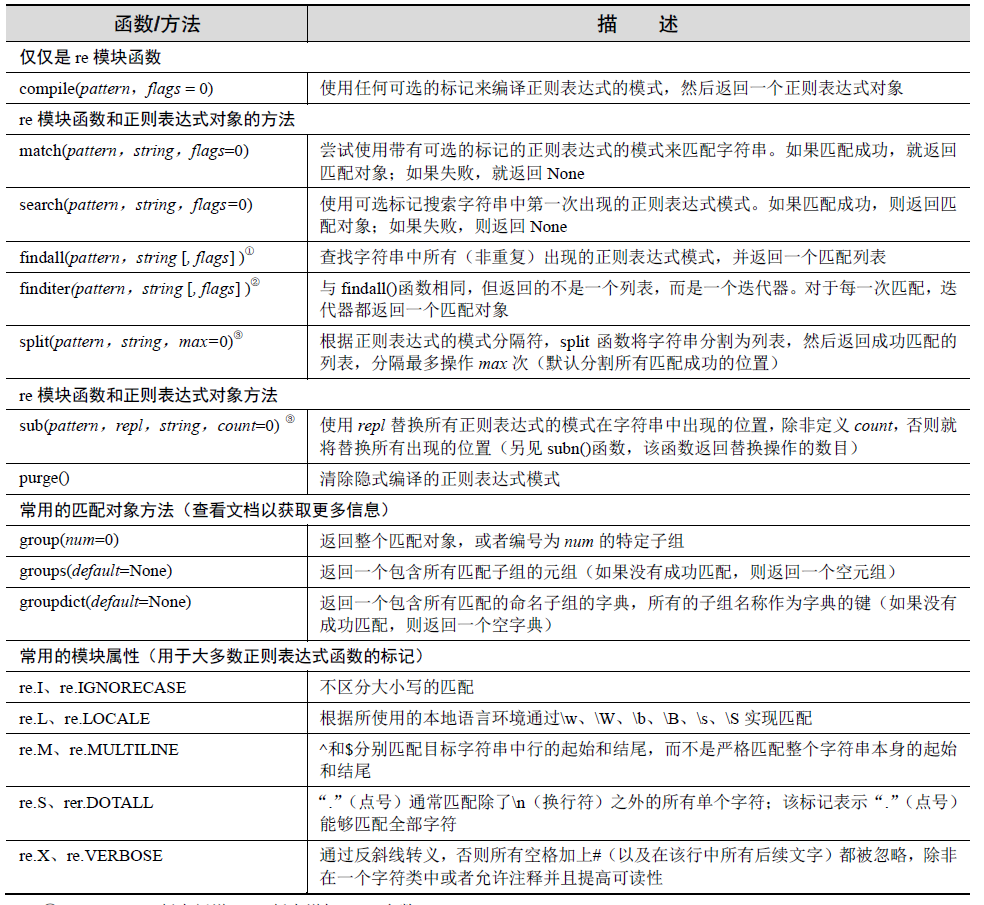
re 模块:核心函数和方法
表1-2 列出了来自re 模块的更多常见函数和方法。它们中的大多数函数也与已经编译的
正则表达式对象(regex object)和正则匹配对象(regex match object)的方法同名并且具有
相同的功能。本节将介绍两个主要的函数/方法------match()和search(),以及compile()函数。
下一节将介绍更多的函数,但如果想进一步了解将要介绍或者没有介绍的更多相关信息,请
查阅Python 的相关文档。
使用compile()函数编译正则表达式
后续将扼要介绍的几乎所有的re 模块函数都可以作为regex 对象的方法。注意,尽管推
荐预编译,但它并不是必需的。如果需要编译,就使用编译过的方法;如果不需要编译,就
使用函数。幸运的是,不管使用函数还是方法,它们的名字都是相同的(也许你曾对此感到
好奇,这就是模块函数和方法的名字相同的原因,例如,search()、match()等)。因为这在大
多数示例中省去一个小步骤,所以我们将使用字符串替代。我们仍将会遇到几个预编译代码
的对象,这样就可以知道它的过程是怎么回事。
对于一些特别的正则表达式编译,可选的标记可能以参数的形式给出,这些标记允许不
区分大小写的匹配,使用系统的本地化设置来匹配字母数字,等等。请参考表1-2 中的条目
以及在正式的官方文档中查询关于这些标记(re.IGNORECASE、re.MULTILINE、re.DOTALL、
re.VERBOSE 等)的更多信息。它们可以通过按位或操作符(|)合并。
这些标记也可以作为参数适用于大多数re 模块函数。如果想要在方法中使用这些标记,它
们必须已经集成到已编译的正则表达式对象之中,或者需要使用直接嵌入到正则表达式本身的
(?F)标记,其中F 是一个或者多个i(用于re.I/IGNORECASE)、m(用于re.M/MULTILINE)、s(用于re.S/DOTALL)等。如果想要同时使用多个,就把它们放在一起而不是使用按位或操作,
例如,(?im)可以用于同时表示re.IGNORECASE 和re.MULTILINE。
匹配对象以及group()和groups()方法
当处理正则表达式时,除了正则表达式对象之外,还有另一个对象类型:匹配对象。这
些是成功调用match()或者search()返回的对象。匹配对象有两个主要的方法:group()和
groups()。
group()要么返回整个匹配对象,要么根据要求返回特定子组。groups()则仅返回一个包含
唯一或者全部子组的元组。如果没有子组的要求,那么当group()仍然返回整个匹配时,groups()
返回一个空元组。
Python 正则表达式也允许命名匹配,这部分内容超出了本节的范围。建议读者查阅完整
的re 模块文档,里面有这里省略掉的关于这些高级主题的详细内容。
使用match()方法匹配字符串
match()是将要介绍的第一个re 模块函数和正则表达式对象(regex object)方法。match()
函数试图从字符串的起始部分对模式进行匹配。如果匹配成功,就返回一个匹配对象;如果
匹配失败,就返回None,匹配对象的group()方法能够用于显示那个成功的匹配。下面是如
何运用match()(以及group())的一个示例:
python
>>> m = re.match('foo', 'foo') # 模式匹配字符串
>>> if m is not None: # 如果匹配成功,就输出匹配内容
... m.group()
...
'f oo'模式"foo"完全匹配字符串"foo",我们也能够确认m 是交互式解释器中匹配对象的示例。
python
>>> m # 确认返回的匹配对象
<re.MatchObject instance at 80ebf48>如下为一个失败的匹配示例,它返回None。
python
>>> m = re.match('foo', 'bar')# 模式并不能匹配字符串
>>> if m is not None: m.group() # (单行版本的if 语句)
...
>> >因为上面的匹配失败,所以m 被赋值为None,而且以此方法构建的if 语句没有指明
任何操作。对于剩余的示例,如果可以,为了简洁起见,将省去if 语句块,但在实际操作
中,最好不要省去以避免 AttributeError 异常(None 是返回的错误值,该值并没有group()
属性方法)
只要模式从字符串的起始部分开始匹配,即使字符串比模式长,匹配也仍然能够成功。
例如,模式"foo"将在字符串"food on the table"中找到一个匹配,因为它是从字符串的起
始部分进行匹配的。
python
>>> m = re.match('foo', 'food on the table') # 匹配成功
>>> m.group()
'f oo'可以看到,尽管字符串比模式要长,但从字符串的起始部分开始匹配就会成功。子串"foo"
是从那个比较长的字符串中抽取出来的匹配部分。
甚至可以充分利用Python 原生的面向对象特性,忽略保存中间过程产生的结果。
python
>>> re.match('foo', 'food on the table').group()
'foo'注意,在上面的一些示例中,如果匹配失败,将会抛出AttributeError 异常。
使用search()在一个字符串中查找模式(搜索与匹配
的对比)
其实,想要搜索的模式出现在一个字符串中间部分的概率,远大于出现在字符串起始部
分的概率。这也就是search()派上用场的时候了。search()的工作方式与match()完全一致,不
同之处在于search()会用它的字符串参数,在任意位置对给定正则表达式模式搜索第一次出现
的匹配情况。如果搜索到成功的匹配,就会返回一个匹配对象;否则,返回None。
我们将再次举例说明match()和search()之间的差别。以匹配一个更长的字符串为例,这
次使用字符串"foo"去匹配"seafood":
python
>>> m = re.match('foo', 'seafood') # 匹配失败
>>> if m is not None: m.group()
...
>> >可以看到,此处匹配失败。match()试图从字符串的起始部分开始匹配模式;也就是说,
模式中的"f"将匹配到字符串的首字母"s"上,这样的匹配肯定是失败的。然而,字符串
"foo"确实出现在"seafood"之中(某个位置),所以,我们该如何让Python 得出肯定的结
果呢?答案是使用search()函数,而不是尝试匹配。search()函数不但会搜索模式在字符串中
第一次出现的位置,而且严格地对字符串从左到右搜索。
python
>>> m = re.search('foo', 'seafood') # 使用 search() 代替
>>> if m is not None: m.group()
...
'foo' # 搜索成功,但是匹配失败
>> >此外,match()和search()都使用在1.3.2 节中介绍的可选的标记参数。最后,需要注意的
是,等价的正则表达式对象方法使用可选的pos 和endpos 参数来指定目标字符串的搜索范围。
本节后面将使用match()和search()正则表达式对象方法以及group()和groups()匹配对象
方法,通过展示大量的实例来说明Python 中正则表达式的使用方法。我们将使用正则表达式
语法中几乎全部的特殊字符和符号。
匹配多个字符串
在1.2 节中,我们在正则表达式bat|bet|bit 中使用了择一匹配(|)符号。如下为在Python
中使用正则表达式的方法。
python
>>> bt = 'bat|bet|bit' # 正则表达式模式: bat、bet、bit
>>> m = re.match(bt, 'bat') # 'bat' 是一个匹配
>>> if m is not None: m.group()
...
'bat'
>>> m = re.match(bt, 'blt') # 对于 'blt' 没有匹配
>>> if m is not None: m.group()
...
>>> m = re.match(bt, 'He bit me!') # 不能匹配字符串
>>> if m is not None: m.group()
...
>>> m = re.search(bt, 'He bit me!') # 通过搜索查找 'bit'
>>> if m is not None: m.group()
...
'b it'匹配任何单个字符
在后续的示例中,我们展示了点号(.)不能匹配一个换行符\n 或者非字符,也就是说,
一个空字符串。
python
>>> anyend = '.end'
>>> m = re.match(anyend, 'bend') # 点号匹配 'b'
>>> if m is not None: m.group()
...
'bend'
>>> m = re.match(anyend, 'end') # 不匹配任何字符
>>> if m is not None: m.group()
...
>>> m = re.match(anyend, '\nend') # 除了 \n 之外的任何字符
>>> if m is not None: m.group()
...
>>> m = re.search('.end', 'The end.')# 在搜索中匹配 ' '
>>> if m is not None: m.group()
...
' end'下面的示例在正则表达式中搜索一个真正的句点(小数点),而我们通过使用一个反斜线
对句点的功能进行转义:
python
>>> patt314 = '3.14' # 表示正则表达式的点号
>>> pi_patt = '3\.14' # 表示字面量的点号 (dec. point)
>>> m = re.match(pi_patt, '3.14') # 精确匹配
>>> if m is not None: m.group()
...
'3.14'
>>> m = re.match(patt314, '3014') # 点号匹配'0'
>>> if m is not None: m.group()
...
'3014'
>>> m = re.match(patt314, '3.14') # 点号匹配 '.'
>>> if m is not None: m.group()
...
'3 .14'创建字符集( )
前面详细讨论了cr23dpo2,以及它们与r2d2|c3po 之间的差别。下面的示例将说明
对于r2d2|c3po 的限制将比cr23dpo2更为严格。
python
>>> m = re.match('[cr][23][dp][o2]', 'c3po')# 匹配 'c3po'
>>> if m is not None: m.group()
...
'c3po'
>>> m = re.match('[cr][23][dp][o2]', 'c2do')# 匹配 'c2do'
>>> if m is not None: m.group()
...
'c2do'
>>> m = re.match('r2d2|c3po', 'c2do')# 不匹配 'c2do'
>>> if m is not None: m.group()
...
>>> m = re.match('r2d2|c3po', 'r2d2')# 匹配 'r2d2'
>>> if m is not None: m.group()
...
'r 2d2'重复、特殊字符以及分组
正则表达式中最常见的情况包括特殊字符的使用、正则表达式模式的重复出现,以及使用
圆括号对匹配模式的各部分进行分组和提取操作。我们曾看到过一个关于简单电子邮件地址的
正则表达式(\w+@\w+.com)。或许我们想要匹配比这个正则表达式所允许的更多邮件地址。
为了在域名前添加主机名称支持,例如www.xxx.com,仅仅允许xxx.com 作为整个域名,必须
修改现有的正则表达式。为了表示主机名是可选的,需要创建一个模式来匹配主机名(后面跟
着一个句点),使用"?"操作符来表示该模式出现零次或者一次,然后按照如下所示的方式,
插入可选的正则表达式到之前的正则表达式中:\w+@(\w+.)?\w+.com。从下面的示例中可见,
该表达式允许.com 前面有一个或者两个名称:
python
>>> patt = '\w+@(\w+\.)?\w+\.com'
>>> re.match(patt, 'nobody@xxx.com').group()
'nobody@xxx.com'
>>> re.match(patt, 'nobody@www.xxx.com').group()
'n obody@www.xxx.com'接下来,用以下模式来进一步扩展该示例,允许任意数量的中间子域名存在。请特别注
意细节的变化,将"?"改为". : \w+@(\w+.)\w+.com"。
python
>>> patt = '\w+@(\w+\.)*\w+\.com'
>>> re.match(patt, 'nobody@www.xxx.yyy.zzz.com').group()
'n obody@www.xxx.yyy.zzz.com'但是,我们必须要添加一个"免责声明",即仅仅使用字母数字字符并不能匹配组成电子
邮件地址的全部可能字符。上述正则表达式不能匹配诸如xxx-yyy.com 的域名或者使用非单
词\W 字符组成的域名。
之前讨论过使用圆括号来匹配和保存子组,以便于后续处理,而不是确定一个正则表达
式匹配之后,在一个单独的子程序里面手动编码来解析字符串。此前还特别讨论过一个简单
的正则表达式模式\w±\d+,它由连字符号分隔的字母数字字符串和数字组成,还讨论了如何
添加一个子组来构造一个新的正则表达式 (\w+)-(\d+)来完成这项工作。下面是初始版本的正
则表达式的执行情况。
python
>>> m = re.match('\w\w\w-\d\d\d', 'abc-123')
>>> if m is not None: m.group()
...
'abc-123'
>>> m = re.match('\w\w\w-\d\d\d', 'abc-xyz')
>>> if m is not None: m.group()
...
>> >在上面的代码中,创建了一个正则表达式来识别包含3 个字母数字字符且后面跟着3 个
数字的字符串。使用abc-123 测试该正则表达式,将得到正确的结果,但是使用abc-xyz 则不
能。现在,将修改之前讨论过的正则表达式,使该正则表达式能够提取字母数字字符串和数
字。如下所示,请注意如何使用group()方法访问每个独立的子组以及groups()方法以获取一
个包含所有匹配子组的元组。
python
>>> m = re.match('(\w\w\w)-(\d\d\d)', 'abc-123')
>>> m.group() # 完整匹配
'abc-123'
>>> m.group(1) # 子组 1
'abc'
>>> m.group(2) # 子组 2
'123'
>>> m.groups() # 全部子组
(' abc', '123')在上面的代码中,创建了一个正则表达式来识别包含3 个字母数字字符且后面跟着3 个
数字的字符串。使用abc-123 测试该正则表达式,将得到正确的结果,但是使用abc-xyz 则不
能。现在,将修改之前讨论过的正则表达式,使该正则表达式能够提取字母数字字符串和数
字。如下所示,请注意如何使用group()方法访问每个独立的子组以及groups()方法以获取一
个包含所有匹配子组的元组。
python
>>> m = re.match('(\w\w\w)-(\d\d\d)', 'abc-123')
>>> m.group() # 完整匹配
'abc-123'
>>> m.group(1) # 子组 1
'abc'
>>> m.group(2) # 子组 2
'123'
>>> m.groups() # 全部子组
(' abc', '123')由以上脚本内容可见,group()通常用于以普通方式显示所有的匹配部分,但也能用于获
取各个匹配的子组。可以使用groups()方法来获取一个包含所有匹配子字符串的元组。
如下为一个简单的示例,该示例展示了不同的分组排列,这将使整个事情变得更加清晰。
python
>>> m = re.match('ab', 'ab') # 没有子组
>>> m.group() # 完整匹配
'ab'
>>> m.groups() # 所有子组
()
>>>
>>> m = re.match('(ab)', 'ab') # 一个子组
>>> m.group() # 完整匹配
'ab'
>>> m.group(1) # 子组 1
'ab'
>>> m.groups() # 全部子组
('ab',)
>>>
>>> m = re.match('(a)(b)', 'ab') # 两个子组
>>> m.group() # 完整匹配
'ab'
>>> m.group(1) # 子组 1
'a'
>>> m.group(2) # 子组 2
'b'
>>> m.groups() # 所有子组
('a', 'b')
>>>
>>> m = re.match('(a(b))', 'ab') # 两个子组
>>> m.group() # 完整匹配
'ab'
>>> m.group(1) # 子组 1
'ab'
>>> m.group(2) # 子组 2
'b'
>>> m.groups() # 所有子组
('ab', 'b')匹配字符串的起始和结尾以及单词边界
匹配字符串的起始和结尾以及单词边界
如下示例突出显示表示位置的正则表达式操作符。该操作符更多用于表示搜索而不是匹
配,因为match()总是从字符串开始位置进行匹配。
python
>>> m = re.search('^The', 'The end.') # 匹配
>>> if m is not None: m.group()
...
'The'
>>> m = re.search('^The', 'end. The') # 不作为起始
>>> if m is not None: m.group()
...
>>> m = re.search(r'\bthe', 'bite the dog') # 在边界
>>> if m is not None: m.group()
...
'the'
>>> m = re.search(r'\bthe', 'bitethe dog') # 有边界
>>> if m is not None: m.group()
...
>>> m = re.search(r'\Bthe', 'bitethe dog') # 没有边界
>>> if m is not None: m.group()
...
't he'读者将注意到此处出现的原始字符串。你可能想要查看本章末尾部分的核心提示"Python
中原始字符串的用法"(Using Python raw strings),里面提到了在此处使用它们的原因。通常
情况下,在正则表达式中使用原始字符串是个好主意。
读者还应当注意其他4 个re 模块函数和正则表达式对象方法:findall()、sub()、subn()和
split()。
使用findall()和finditer()查找每一次出现的位置
findall()查询字符串中某个正则表达式模式全部的非重复出现情况。这与search()在执行
字符串搜索时类似,但与match()和search()的不同之处在于,findall()总是返回一个列表。如
果findall()没有找到匹配的部分,就返回一个空列表,但如果匹配成功,列表将包含所有成
功的匹配部分(从左向右按出现顺序排列)。
python
>>> re.findall('car', 'car')
['car']
>>> re.findall('car', 'scary')
['car']
>>> re.findall('car', 'carry the barcardi to the car')
[' car', 'car', 'car']子组在一个更复杂的返回列表中搜索结果,而且这样做是有意义的,因为子组是允许从
单个正则表达式中抽取特定模式的一种机制,例如匹配一个完整电话号码中的一部分(例如
区号),或者完整电子邮件地址的一部分(例如登录名称)。
对于一个成功的匹配,每个子组匹配是由findall()返回的结果列表中的单一元素;对于
多个成功的匹配,每个子组匹配是返回的一个元组中的单一元素,而且每个元组(每个元组
都对应一个成功的匹配)是结果列表中的元素。这部分内容可能第一次听起来令人迷惑,但
是如果你尝试练习过一些不同的示例,就将澄清很多知识点。
finditer()函数是在Python 2.2 版本中添加回来的,这是一个与findall()函数类似但是更节
省内存的变体。两者之间以及和其他变体函数之间的差异(很明显不同于返回的是一个迭代
器还是列表)在于,和返回的匹配字符串相比,finditer()在匹配对象中迭代。如下是在单个
字符串中两个不同分组之间的差别。
python
>>> s = 'This and that.'
>>> re.findall(r'(th\w+) and (th\w+)', s, re.I)
[('This', 'that')]
>>> re.finditer(r'(th\w+) and (th\w+)', s,
... re.I).next().groups()
('This', 'that')
>>> re.finditer(r'(th\w+) and (th\w+)', s,
... re.I).next().group(1)
'This'
>>> re.finditer(r'(th\w+) and (th\w+)', s,
... re.I).next().group(2)
'that'
>>> [g.groups() for g in re.finditer(r'(th\w+) and (th\w+)',
... s, re.I)]
[( 'This', 'that')]在下面的示例中,我们将在单个字符串中执行单个分组的多重匹配。
python
>>> re.findall(r'(th\w+)', s, re.I)
['This', 'that']
>>> it = re.finditer(r'(th\w+)', s, re.I)
>>> g = it.next()
>>> g.groups()
('This',)
>>> g.group(1)
'This'
>>> g = it.next()
>>> g.groups()
('that',)
>>> g.group(1)
'that'
>>> [g.group(1) for g in re.finditer(r'(th\w+)', s, re.I)]
[' This', 'that']注意,使用finditer()函数完成的所有额外工作都旨在获取它的输出来匹配findall()的输出。
最后,与match()和search()类似,findall()和finditer()方法的版本支持可选的pos 和endpos
参数,这两个参数用于控制目标字符串的搜索边界,这与本章之前的部分所描述的类似。
使用sub()和subn()搜索与替换
有两个函数/方法用于实现搜索和替换功能:sub()和subn()。两者几乎一样,都是将某字
符串中所有匹配正则表达式的部分进行某种形式的替换。用来替换的部分通常是一个字符串,
但它也可能是一个函数,该函数返回一个用来替换的字符串。subn()和sub()一样,但subn()
还返回一个表示替换的总数,替换后的字符串和表示替换总数的数字一起作为一个拥有两个
元素的元组返回。
python
>>> re.sub('X', 'Mr. Smith', 'attn: X\n\nDear X,\n')
'attn: Mr. Smith\012\012Dear Mr. Smith,\012'
>>>
>>> re.subn('X', 'Mr. Smith', 'attn: X\n\nDear X,\n')
('attn: Mr. Smith\012\012Dear Mr. Smith,\012', 2)
>>>
>>> print re.sub('X', 'Mr. Smith', 'attn: X\n\nDear X,\n')
attn: Mr. Smith
Dear Mr. Smith,
>>> re.sub('[ae]', 'X', 'abcdef')
'XbcdXf'
>>> re.subn('[ae]', 'X', 'abcdef')
(' XbcdXf', 2)前面讲到,使用匹配对象的group()方法除了能够取出匹配分组编号外,还可以使用\N,
其中N 是在替换字符串中使用的分组编号。下面的代码仅仅只是将美式的日期表示法
MM/DD/YY{,YY}格式转换为其他国家常用的格式DD/MM/YY{,YY}。
python
>>> re.sub(r'(\d{1,2})/(\d{1,2})/(\d{2}|\d{4})',
... r'\2/\1/\3', '2/20/91') # Yes, Python is...
'20/2/91'
>>> re.sub(r'(\d{1,2})/(\d{1,2})/(\d{2}|\d{4})',
... r'\2/\1/\3', '2/20/1991') # ... 20+ years old!
'20/2/1991'在限定模式上使用split()分隔字符串
re 模块和正则表达式的对象方法split()对于相对应字符串的工作方式是类似的,但是与
分割一个固定字符串相比,它们基于正则表达式的模式分隔字符串,为字符串分隔功能添加
一些额外的威力。如果你不想为每次模式的出现都分割字符串,就可以通过为max 参数设定
一个值(非零)来指定最大分割数。
如果给定分隔符不是使用特殊符号来匹配多重模式的正则表达式,那么re.split()与
str.split()的工作方式相同,如下所示(基于单引号分割)。
python
>>> re.split(':', 'str1:str2:str3')
[' str1', 'str2', 'str3']这是一个简单的示例。如果有一个更复杂的示例,例如,一个用于Web 站点(类似于
Google 或者Yahoo! Maps)的简单解析器,该如何实现?用户需要输入城市和州名,或者城
市名加上ZIP 编码,还是三者同时输入?这就需要比仅仅是普通字符串分割更强大的处理方
式,具体如下。
python
>>> import re
>>> DATA = (
... 'Mountain View, CA 94040',
... 'Sunnyvale, CA',
... 'Los Altos, 94023',
... 'Cupertino 95014',
... 'Palo Alto CA',
... )
>>> for datum in DATA:
... print re.split(', |(?= (?:\d{5}|[A-Z]{2})) ', datum)
...
['Mountain View', 'CA', '94040']
['Sunnyvale', 'CA']
['Los Altos', '94023']
['Cupertino', '95014']
[' Palo Alto', 'CA']上述正则表达式拥有一个简单的组件:使用split 语句基于逗号分割字符串。更难的部分是
最后的正则表达式,可以通过该正则表达式预览一些将在下一小节中介绍的扩展符号。在普通的
英文中,通常这样说:如果空格紧跟在五个数字(ZIP 编码)或者两个大写字母(美国联邦州缩
写)之后,就用split 语句分割该空格。这就允许我们在城市名中放置空格。
通常情况下,这仅仅只是一个简单的正则表达式,可以在用来解析位置信息的应用中作
为起点。该正则表达式并不能处理小写的州名或者州名的全拼、街道地址、州编码、ZIP+4
(9 位ZIP 编码)、经纬度、多个空格等内容(或者在处理时会失败)。这仅仅意味着使用re.split()
能够实现str.split()不能实现的一个简单的演示实例。
通常情况下,这仅仅只是一个简单的正则表达式,可以在用来解析位置信息的应用中作
为起点。该正则表达式并不能处理小写的州名或者州名的全拼、街道地址、州编码、ZIP+4
(9 位ZIP 编码)、经纬度、多个空格等内容(或者在处理时会失败)。这仅仅意味着使用re.split()
能够实现str.split()不能实现的一个简单的演示实例。
我们刚刚已经证实,读者将从正则表达式split 语句的强大能力中获益;然而,记得一定
在编码过程中选择更合适的工具。如果对字符串使用split 方法已经足够好,就不需要引入额
外复杂并且影响性能的正则表达式。
扩展符号
Python 的正则表达式支持大量的扩展符号。让我们一起查看它们中的一些内容,然后展
示一些有用的示例。
通过使用 (?iLmsux) 系列选项,用户可以直接在正则表达式里面指定一个或者多个标
记,而不是通过compile()或者其他re 模块函数。下面为一些使用re.I/IGNORECASE 的示例,
最后一个示例在re.M/MULTILINE 实现多行混合:
python
>>> re.findall(r'(?i)yes', 'yes? Yes. YES!!')
['yes', 'Yes', 'YES']
>>> re.findall(r'(?i)th\w+', 'The quickest way is through this
tunnel.')
['The', 'through', 'this']
>>> re.findall(r'(?im)(^th[\w ]+)', """
... This line is the first,
... another line,
... that line, it's the best
... """)
[' This line is the first', 'that line']在前两个示例中,显然是不区分大小写的。在最后一个示例中,通过使用"多行",能够
在目标字符串中实现跨行搜索,而不必将整个字符串视为单个实体。注意,此时忽略了实例
"the",因为它们并不出现在各自的行首。
下一组演示使用re.S/DOTALL。该标记表明点号(.)能够用来表示\n 符号(反之其通常
用于表示除了\n 之外的全部字符):
python
>>> re.findall(r'th.+', '''
... The first line
... the second line
... the third line
... ''')
['the second line', 'the third line']
>>> re.findall(r'(?s)th.+', '''
... The first line
... the second line
... the third line
... ''')
[' the second line\nthe third line\n']re.X/VERBOSE 标记非常有趣;该标记允许用户通过抑制在正则表达式中使用空白符(除
了在字符类中或者在反斜线转义中)来创建更易读的正则表达式。此外,散列、注释和井号
也可以用于一个注释的起始,只要它们不在一个用反斜线转义的字符类中。
python
>>> re.search(r'''(?x)
... \((\d{3})\) # 区号
... [ ] # 空白符
... (\d{3}) # 前缀
... - # 横线
... (\d{4}) # 终点数字
... ''', '(800) 555-1212').groups()
(' 800', '555', '1212')(?:...)符号将更流行;通过使用该符号,可以对部分正则表达式进行分组,但是并不会保
存该分组用于后续的检索或者应用。当不想保存今后永远不会使用的多余匹配时,这个符号
就非常有用。
python
>>> re.findall(r'http://(?:\w+\.)*(\w+\.com)',
... 'http://google.com http://www.google.com http://
code.google.com')
['google.com', 'google.com', 'google.com']
>>> re.search(r'\((?P<areacode>\d{3})\) (?P<prefix>\d{3})-(?:\d{4})',
... '(800) 555-1212').groupdict()
{' areacode': '800', 'prefix': '555'}读者可以同时一起使用 (?P) 和 (?P=name)符号。前者通过使用一个名称标
识符而不是使用从1 开始增加到N 的增量数字来保存匹配,如果使用数字来保存匹配结
果,我们就可以通过使用\1,\2 ...,\N \来检索。如下所示,可以使用一个类似风格的\g
来检索它们。
python
>>> re.sub(r'\((?P<areacode>\d{3})\) (?P<prefix>\d{3})-(?:\d{4})',
... '(\g<areacode>) \g<prefix>-xxxx', '(800) 555-1212')
'( 800) 555-xxxx'使用后者,可以在一个相同的正则表达式中重用模式,而不必稍后再次在(相同)
正则表达式中指定相同的模式。例如,在本示例中,假定让读者验证一些电话号码的规
范化。如下所示为一个丑陋并且压缩的版本,后面跟着一个正确使用的 (?x),使代码变
得稍许易读。
python
>>> bool(re.match(r'\((?P<areacode>\d{3})\) (?P<prefix>\d{3})-
(?P<number>\d{4}) (?P=areacode)-(?P=prefix)-(?P=number)
1(?P=areacode)(?P=prefix)(?P=number)',
... '(800) 555-1212 800-555-1212 18005551212'))
True
>>> bool(re.match(r'''(?x)
...
... # match (800) 555-1212, save areacode, prefix, no.
... \((?P<areacode>\d{3})\)[ ](?P<prefix>\d{3})-(?P<number>\d{4})
...
... # space
... [ ]
...
... # match 800-555-1212
... (?P=areacode)-(?P=prefix)-(?P=number)
...
... # space
... [ ]
...
... # match 18005551212
... 1(?P=areacode)(?P=prefix)(?P=number)
...
... ''', '(800) 555-1212 800-555-1212 18005551212'))
Tr ue读者可以使用 (?=...) 和 (?!..)符号在目标字符串中实现一个前视匹配,而不必实际上使
用这些字符串。前者是正向前视断言,后者是负向前视断言。在后面的示例中,我们仅仅对
姓氏为"van Rossum"的人的名字感兴趣,下一个示例中,让我们忽略以"noreply"或者
"postmaster"开头的e-mail 地址。
第三个代码片段用于演示findall()和finditer()的区别;我们使用后者来构建一个使用相同
登录名但不同域名的e-mail 地址列表(在一个更易于记忆的方法中,通过忽略创建用完即丢
弃的中间列表)。
python
>>> re.findall(r'\w+(?= van Rossum)',
... '''
... Guido van Rossum
... Tim Peters
... Alex Martelli
... Just van Rossum
... Raymond Hettinger
... ''')
['Guido', 'Just']
>>> re.findall(r'(?m)^\s+(?!noreply|postmaster)(\w+)',
... '''
... sales@phptr.com
... postmaster@phptr.com
... eng@phptr.com
... noreply@phptr.com
... admin@phptr.com
... ''')
['sales', 'eng', 'admin']
>>> ['%s@aw.com' % e.group(1) for e in \
re.finditer(r'(?m)^\s+(?!noreply|postmaster)(\w+)',
... '''
... sales@phptr.com
... postmaster@phptr.com
... eng@phptr.com
... noreply@phptr.com
... admin@phptr.com
... ''')]
[' sales@aw.com', 'eng@aw.com', 'admin@aw.com']最后一个示例展示了使用条件正则表达式匹配。假定我们拥有另一个特殊字符,它仅
仅包含字母"x"和"y",我们此时仅仅想要这样限定字符串:两字母的字符串必须由一
个字母跟着另一个字母。换句话说,你不能同时拥有两个相同的字母;要么由"x"跟着
"y",要么相反。
>>> bool(re.search(r'(?:(x)|y)(?(1)y|x)', 'xy'))
True
>>> bool(re.search(r'(?:(x)|y)(?(1)y|x)', 'xx'))
False杂项
可能读者会对于正则表达式的特殊字符和特殊ASCII 符号之间的差异感到迷惑。我们
可以使用\n 表示一个换行符,但是我们可以使用\d 在正则表达式中表示匹配单个数字。
如果有符号同时用于ASCII 和正则表达式,就会发生问题,因此在下面的核心提示中,
建议使用Python 的原始字符串来避免产生问题。另一个警告是:\w 和\W 字母数字字符集同
时受re.L/LOCALE 和Unicode(re.U/UNICODE)标记所影响。