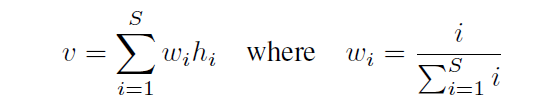- 这是篇想要用GPT来提取sentence embedding的工作,提出了两个框架,一个是SGPT-BE,一个是SGPT-CE,分别代表了Bi-Encoder setting和Cross-Encoder setting。
- CE的意思是在做阅读理解任务时,document和query是一起送进去,中间加个SEP token来做的,典型的是BERT。而GPT一般不是,但作者觉得GPT也可以是。也就是说,如果有k个document和一个新的query,需要把这个query和这k个document分别concate在一起,重新提取信息,走k次。
- 而BE的意思是,document和query单独提取信息。每段document用pooling来提取一个vector即可,query单独提取一个vector,然后算相似度,就能知道document中是否有query要的信息。
- BE的模型提出了新的pooling method,用的是position-weighted mean pooling,还有bias-only fine-tuning。
- position-weighted mean pooling的意思是,前面的token由于mask的存在,注意力的时候看不到后面的token,所以要给低一点的权重,后面的token给高一点的权重,就按1 2 3 4 5这样随位置单调线性递增的权重即可,如下: