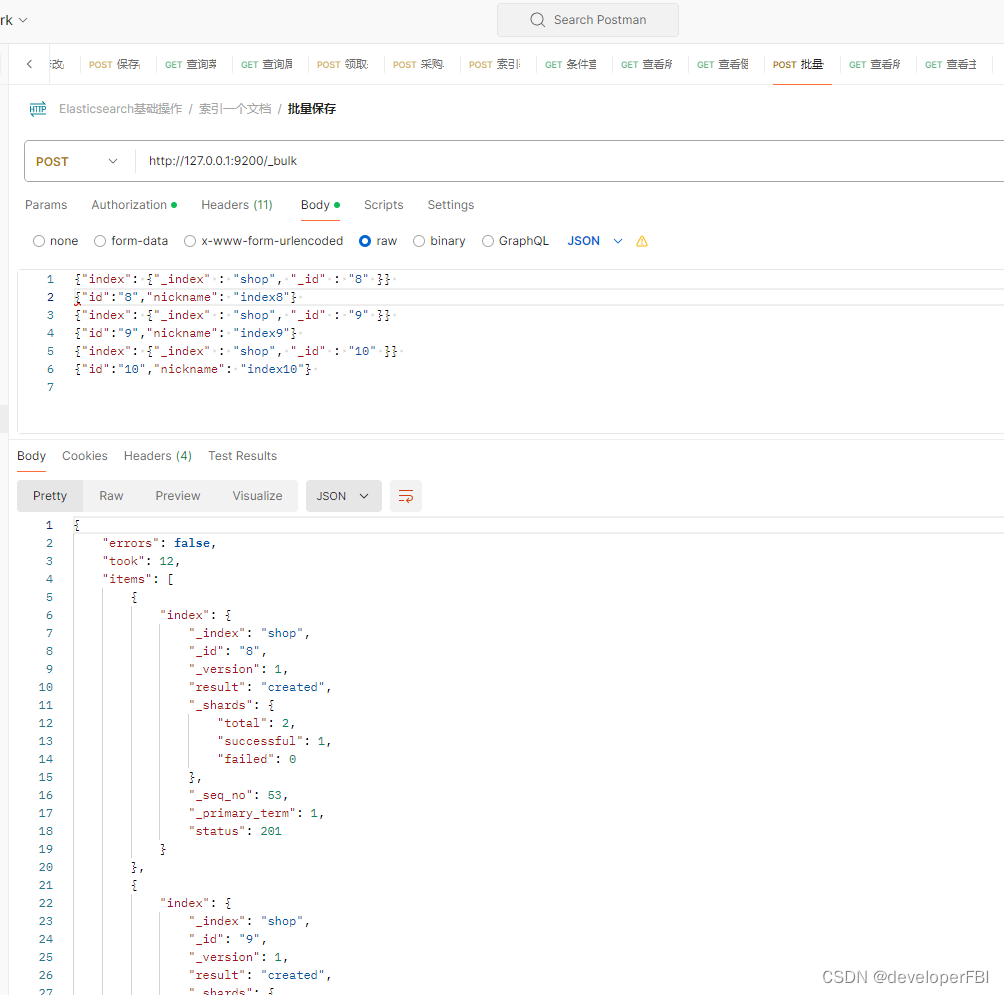
在使用elaticsearch8.13.0使用批量创建索引时,根据谷粒中说的es7.9方法去批量操作请求:
http://127.0.0.1:9200/shop/_doc/_bulk
**注意1:**设置header为Content-Type:application/x-ndjson,否则请求报错:
javascript
{
"error": "Content-Type header [] is not supported",
"status": 406
}body:
javascript
{"index": {"_index":"shop","_type":"_doc","_id": "2004"}}
{"id": "2004", "nickname": "index2004"}
{"index": {"_index":"shop","_type":"_doc","_id": "2007"}}
{"id": "2007", "nickname": "name2007"}
{"index": {"_index":"shop","_type":"_doc","_id": "2008"}}
{"id": "2008", "nickname": "name2008"}报错信息如下:
javascript
{
"error": {
"root_cause": [
{
"type": "illegal_argument_exception",
"reason": "Malformed content, found extra data after parsing: START_OBJECT"
}
],
"type": "illegal_argument_exception",
"reason": "Malformed content, found extra data after parsing: START_OBJECT"
},
"status": 400
}根据报错翻译:内容格式错误,解析后发现额外数据:START_OBJECT。其实说白了就是请求的url不对。大家可以参考elaticsearch官网查看:
Bulk API | Elasticsearch Guide 8.14 | Elastic
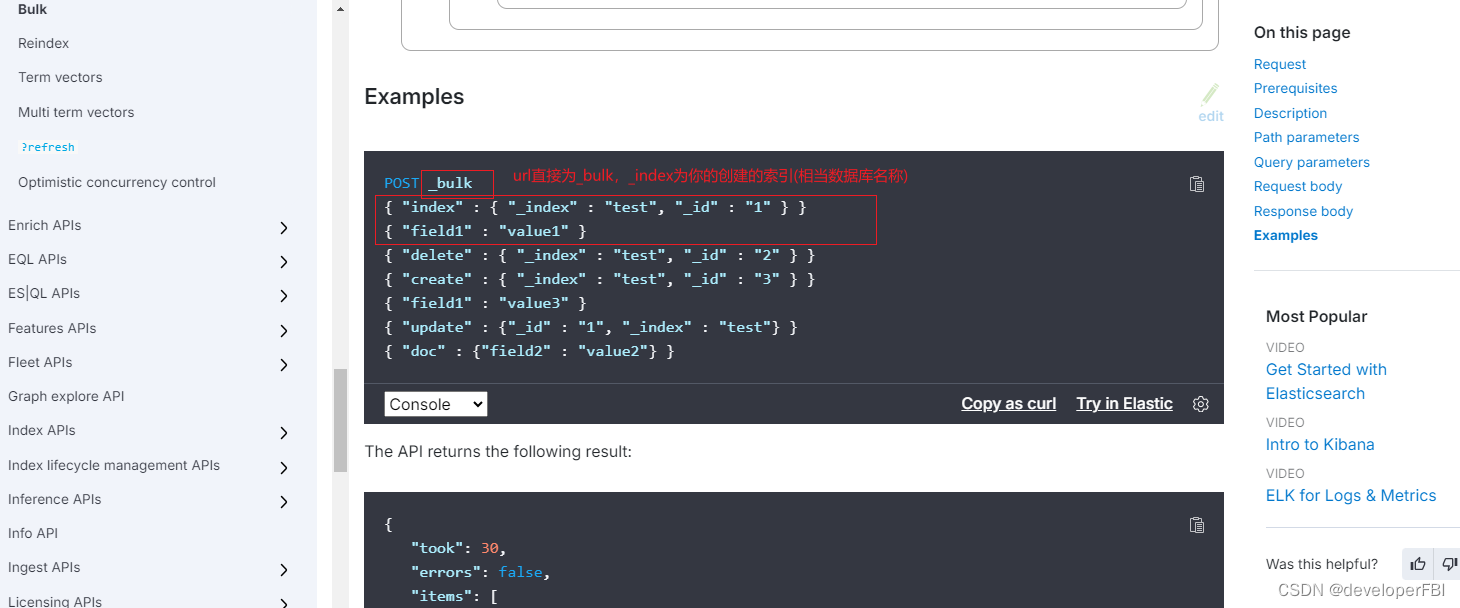
注意2: body里面的Json或text最后要多空一行,如下截图:
否则会报错:
javascript
{
"error": {
"root_cause": [
{
"type": "illegal_argument_exception",
"reason": "The bulk request must be terminated by a newline [\\n]"
}
],
"type": "illegal_argument_exception",
"reason": "The bulk request must be terminated by a newline [\\n]"
},
"status": 400
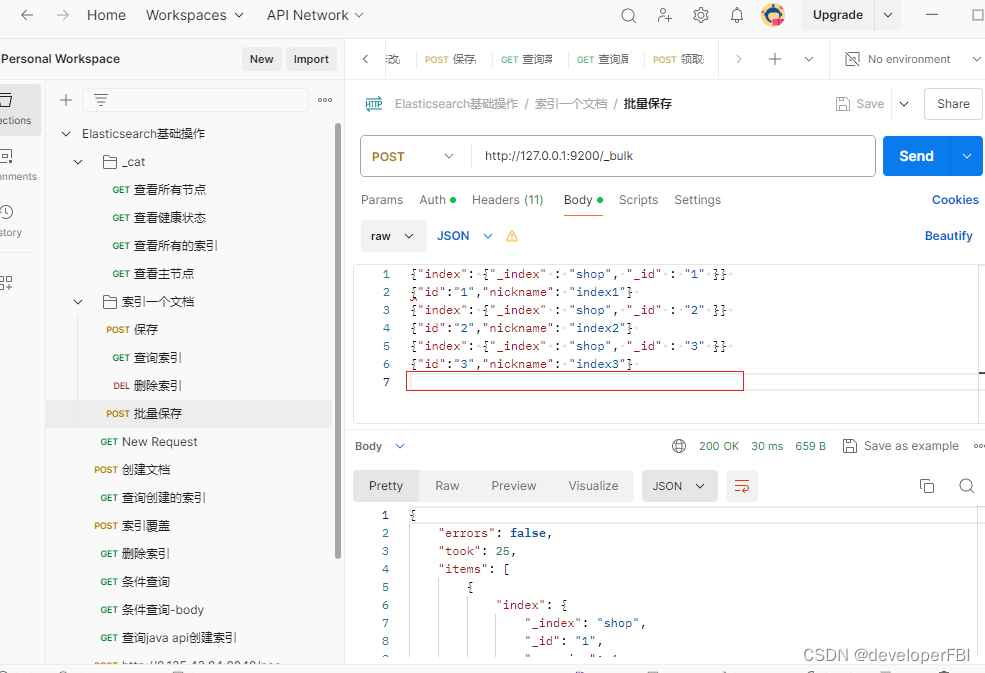
}当你把上面的2个注意项设置后,请求成功界面如下: